




 本文详细介绍了如何安装Scrapy爬虫框架,包括命令行和Pycharm中的安装方法,并通过一个案例展示了如何创建Scrapy项目,定义爬虫、数据项、解析规则以及运行爬虫并保存结果。案例中,爬取了百度首页的导航链接,涉及items.py、pipelines.py、middlewares.py、settings.py和spiders目录中的文件配置。
本文详细介绍了如何安装Scrapy爬虫框架,包括命令行和Pycharm中的安装方法,并通过一个案例展示了如何创建Scrapy项目,定义爬虫、数据项、解析规则以及运行爬虫并保存结果。案例中,爬取了百度首页的导航链接,涉及items.py、pipelines.py、middlewares.py、settings.py和spiders目录中的文件配置。
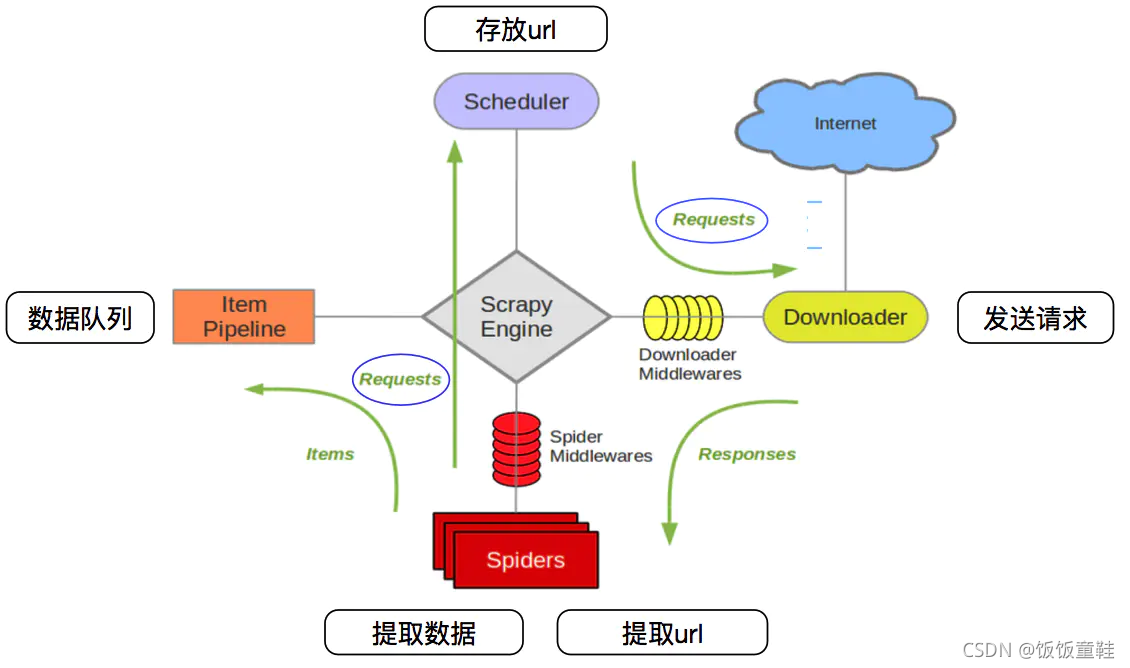
一、Scrapy安装
1、命令行安装
可以直接在命令行输入以下命令
pip install scrapy
由于 pip 安装会自动安装 scrapy 爬虫框架依赖的各种包,安装速度较慢,出错概率较 大,建议增加-i 参数,使用清华镜像安装。
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple/
安装成功后在命令行输入scrapy,出现下图中的提示则代表Scrapy安装成功了
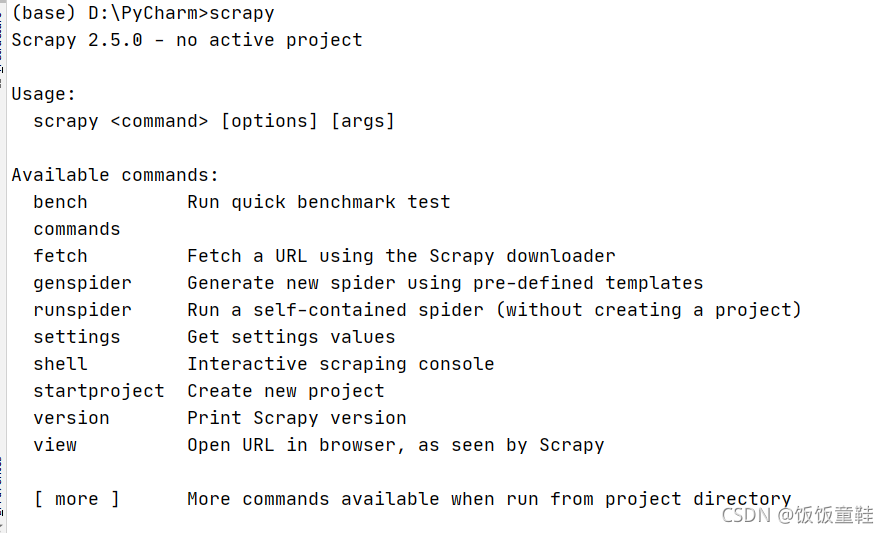
2.Pycharm下安装
打开pycharm,在菜单栏选择“file->settings”,在页面中找到“Python Interpreter”。
鼠标点击加号“+”,点击“Manage Repositories”修改镜像源为 清华镜像。修改“https://pypi.python.org/simple”为“https://pypi.tuna.tsinghua.edu.cn /simple”。
保存后,在“Available Packages”中输入 Scrapy。点击“Install Package” 进行安装。安装完成后会出现“Package Scrapy installed successfully”的提示。
注意:Pycharm 下的 Scrapy 的安装,是将 Scrapy 安装在独立的虚拟环境中,每次创建项目后都需要再次安装。
二、案例
以爬取百度首页的导航链接为例
1.创建爬虫项目
打开 pycharm,在底部状态栏中点击“Terminal”,输入“scrapy startproject baiduSpider”,其中 baiduspier 为 Scrapy 项目名称。
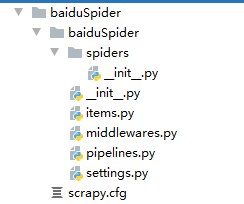
1.scrapy.cfg 是项目的配置文件,一般不用配置。scrapy.cfg 所在的目录就是项目 的根目录。
2.Items.py 文件是保存爬取到的数据容器,定义爬取数据项的名称。
3.piplines.py 文件处理已经爬取到的数据。如要把爬取的 item 去重或者保存到数据库,就需要在这个文件中进行定义。
4.middlewares.py 是中间件文件,主要用来对所有发出的请求、收到的响应或者spider 做全局性的自定义设置。
5.settings.py 是当前 Scrapy 爬虫项目的配置文件。
6.spiders文件夹用于存放爬虫文件,可以存在多个爬虫文件。爬虫主要逻辑就在里面义,如后面创建的爬虫文件就是放到此文件夹下。
2.创建爬虫文件
爬虫项目和爬虫的关系为1对多的关系,首先使用“cd baiduspider”命令进入目录baiduspider,然后使用命令“scrapy genspider baidu baidu.com” 生成爬虫文件。其中参数“baidu”为爬虫名称,需要注意 的是爬虫文件的名称不能和爬虫项目 baiduspider 重复。参数“baidu.com”为域名。
在 baiduspider/baiduspider/spiders 目录下找到 baidu.py 文件。内容如下:
import scrapy
class BaiduSpider(scrapy.Spider):
name = 'baidu' #爬虫的名字
allowed_domains = ['baidu.com'] #域名,约定爬取的范围
start_urls = ['http://baidu.com/'] #爬虫启动时默认爬取的地址
def parse(self, response): #解析爬取到页面的方法
pass
3.定义爬取数据项
在 baiduspider/baiduspider 文件夹下找到 items.py 文件。代码如下
import scrapy
class BaiduspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
类 BaiduspiderItem 继承自 scrapy.Item。注释的内容约定了定义数据项的使用方式。 只需要定义数据项的名称即可。数据项的值都是 scrapy.Field()。
import scrapy
class BaiduspiderItem(scrapy.Item):
title=scrapy.Field() #导航a标签的中文名称
url=scrapy.Field() #导航链接地址
4.定义爬虫解析
打开“baiduspider/baiduspider/spiders”目录下找到 baidu.py 文件,修改解析方 法 parse
import scrapy
from baiduSpider.items import BaiduspiderItem
class BaiduSpider(scrapy.Spider):
name = 'baidu' #爬虫的名字
allowed_domains = ['baidu.com'] #域名,约定爬取的范围
start_urls = ['https://www.baidu.com/'] #爬虫启动时默认爬取的地址
def parse(self, response): #解析爬取到页面的方法
for row in response.xpath("//div[@id='u1']/a"): #循环逐行从列表中获取每个链接
item=BaiduspiderItem() #实例化
item['title']=row.xpath("text()").get()
item['url']=row.xpath("@href").get()
yield item
5.运行爬虫
运行前还是要进入爬虫项目所在的目录,否则无法运行,执行命令“scrapy crawl baidu”,但是运行后会打印输出非常多的日志信息,是因为缺省情况下日志等级为info,在 配置文件“baiduspider/baiduspider/settings.py”文件中进行调整
ROBOTSTXT_OBEY = False #关闭robots协议,否则很多页面都无法爬取
LOG_LEVEL="WARNING" #日志为警告以上才显示
调整后程序重新运行,发现没有任何提示,是因为 parse 函数中没有任何输出。增加-o
参数,将爬取的结果输出为文件。命令为“scrapy crawl baidu -o baidu.csv”。运行后 在 baiduspider 目录下查看 baidu.csv 文件。
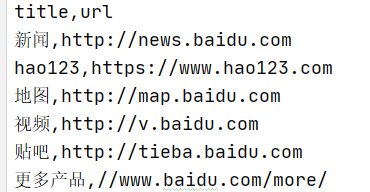
结果如下:

















 8970
8970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









