






 本文深入介绍了MySQL从8.0版本开始引入的窗口函数,包括其使用场景、基本语法、与GROUP BY的区别以及功能。通过示例展示了如何在组内排名、TopN问题中应用窗口函数,并对比了使用窗口函数与普通方法的优劣。同时,提供了用户登录记录查询的实战案例,解释了RANK(), DENSE_RANK()和ROW_NUMBER()函数的差异,并给出了两种实现方法。
本文深入介绍了MySQL从8.0版本开始引入的窗口函数,包括其使用场景、基本语法、与GROUP BY的区别以及功能。通过示例展示了如何在组内排名、TopN问题中应用窗口函数,并对比了使用窗口函数与普通方法的优劣。同时,提供了用户登录记录查询的实战案例,解释了RANK(), DENSE_RANK()和ROW_NUMBER()函数的差异,并给出了两种实现方法。
1.版本介绍:mysql的窗口函数从8.0版本开始使用,之前的版本都不支持窗口函数
2.使用场景:需要组内排名时使用
例如:
a.排名问题:每个部门按业绩来排名
b.topN问题:找出不同部门排名前N的员工进行奖励
3.窗口函数使用的基本语法:
<窗口函数> over (partition by <用于分组的列名>order by <用于排序的列名>)
1). 专用窗口函数:包括后面要讲到的 rank, dense_rank, row_number等专用窗口函数;
2).聚合函数:如sum. avg, count, max, min等
4.partition by和group by区别:
1). partition by用来对表分组;
2).order by子句的功能是对分组后的结果进行排序(组内排序),默认是按照升序(asc)排列,(desc)降序排列;
3).group by :分组后会改变行数;partition by:分组汇总行数不变。
5.窗口函数的功能:
1)同时具有分组和排序的功能
2)不减少原表的行数
6.窗口函数使用示例:
select *,
rank() over (order by 成绩 desc) as ranking,
dense_rank() over (order by 成绩 desc) as dese_rank,
row_number() over (order by 成绩 desc) as row_num
from 班级表
7.示例结果展示:
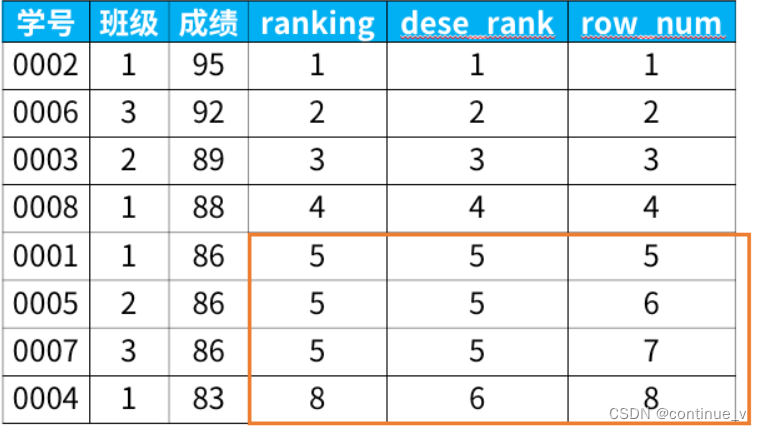
8.总结:
rank函数:会根据分组字段相同的数据排名,相同数据排名相同,不同数据会自动顺延排名数;
dense函数:会根据字段相同的数据排名,相同数据排名相同,不同数据依次递增排名;
row_number函数:根据字段数据的行数依次递增排名,不受数据的影响
9.案例分析:
create table userlog
(
id int ,
name varchar(10),
EmailAddress varchar(50),
lastlogon varchar(50)
);
insert into userlog values(100,'test4','test4@yahoo.cn','2007-11-25 16:31:26');
insert into userlog values(13,'test1','test4@yahoo.cn','2007-3-22 16:27:07');
insert into userlog values(19,'test1','test4@yahoo.cn','2007-10-25 14:13:46');
insert into userlog values(42,'test1','test4@yahoo.cn','2007-10-25 14:20:10');
insert into userlog values(45,'test2','test4@yahoo.cn','2007-4-25 14:17:39');
insert into userlog values(49,'test2','test4@yahoo.cn','2007-5-25 14:22:36');
-- 1.查询出每个用户最近一次登录的记录(每个用户只显示一条最近登录的记录)及给出每个用户的登录总次数(同一天多次登录认为是一次)
select `name`,EmailAddress,date_format(lastlogon,'%Y-%m-%d %H:%m:%s') time1,date_format(substring_index(lastlogon,' ',1),'%Y-%m-%d') day1 from userlog;
select a.`name`,max(a.time1) 最近登录详细时间,max(a.day1) 最近登陆时间,count(distinct a.day1) 总次数
from (select `name`,EmailAddress,date_format(lastlogon,'%Y-%m-%d %H:%m:%s') time1,date_format(substring_index(lastlogon,' ',1),'%Y-%m-%d') day1 from userlog)a
group by a.`name`;
-- 2.生成一张临时表,表名自定,四列数据,分别提是:Name, Last Logon,Num_logontime(要求:按时间给出每个人的登录次数,登录时间最早的为1,之后分别为2, 3,4等), Num_logonday(要求:按天给出每个人的登录次数,同一天多次登录认为是同一次,最早的一次标记为1,之后的依次类推)
select id,`name`, date_format(lastlogon,'%Y-%m-%d %H:%m:%s') time2 ,date_format(substring_index(lastlogon,' ',1),'%Y-%m-%d') day2,count(id) 次数 from userlog group by day2;
# 方法一:窗口函数添加排序列
select b.`name`,b.time2,
row_number() over(partition by b.`name` order by b.day2 ) Num_logontime,
rank() over(partition by b.`name` order by b.day2 ) Num_logonday,
dense_rank() over(partition by b.`name` order by b.day2 ) dense_logonday
from (select `name`, date_format(lastlogon,'%Y-%m-%d %H:%m:%s') time2 ,date_format(substring_index(lastlogon,' ',1),'%Y-%m-%d') day2 from userlog)b;
# 方法二:创建变量添加辅助列添加排序列
DROP TABLE IF EXISTS tmp_table;
CREATE TEMPORARY TABLE tmp_table
select
user2.name as Name ,user2.time1 as lastlogon ,user2.rank1 as num_logontime,user2.rank2 as num_logonday
from
(select * ,
@rank:=if(@nam=user1.name,@rank+1,1) rank1,
@rank1:=if(@nam=user1.name,if(@da=user1.day1,@rank1,@rank1+1),1) rank2,
@nam:=user1.name,
@da:=user1.day1
from (select name,EmailAddress,date_format(lastlogon, '%Y-%m-%d %H:%i:%s') as time1,date_format(substring_index(lastlogon,' ',1),'%Y-%m-%d') as day1 from userlog order by name asc ,time1 asc)as user1 ,(select @rank:=0,@rank1:=0,@nam:=null,@da:=null) temp order by user1.name,user1.time1) as user2;select * from tmp_table ;
案例总结:通过上述mysql查询案例,明显发现,使用窗口函数比普通添加辅助列的方法更容易理解、更容易添加辅助列,代码量少,不易出错。

















 765
765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









