



使用Kettle同步MongoDB数据到关系型数据库
最近工作时,要同步一个业务系统的数据到Oracle数据库。给账号信息过来的时候,布豪,是非关系型数据库MongoDB。MongoDB是Json文档型的数据库,与传统的关系型数据库到关系型数据库同步方式不同,本文将讲解如何处理上述业务场景。
流程和组件介绍
整体流程也容易理解
这边主要介绍2个不常用的组件
① MongoDB input:里面可以配置MongoDB数据连接、读取的库和文档以及查询条件和筛选字段。

Configure connection中配置数据库信息;Input Option主要是选择你要读哪个库,哪个文档的信息;Query中配置你的查询过滤条件,你也可以做聚合管道操作,完成一些复杂查询或者排序啥的;Fields中可以选你只看哪些字段信息。
② Json input:通过此组件将输入的Json字符串解析出来,解析字段过程如下:

第一层的就是$.字段,如果是包了一层的,就可以像riskLevel一样点多一层,也可以用在线Json路径解析工具去解析。
全量同步
基本按照上面的组件和流程介绍内容,按照下面的组件流把数据同步到目标表即可。

注意表输出中裁剪表要勾选上,字段对应好即可。

增量同步
增量同步数据时,我们要确定同步时间范围,即增量时间;先在DB中删除在这个时间后的数据,然后将时间作为参数值传入到MongoDB input的Query块中,筛选出符合条件的数据,同步到数据库表中。流程图如下:
上面流程比全量同步多2个步骤

注意:这是一个JOB(作业),我将上面的四个步骤拆到2个转换中。
有同学可能会好奇为什么要这样处理?放在一个转换中不是更好吗?
这里有一个隐藏的坑,如果将设置变量放在一个转换里,这个设置变量会不起作用。参考博客。
下面贴一下详细过程
设置变量:

这里定义好参数名称
getTime转换中,获取最近时间戳,然后将获取的值设置回变量中


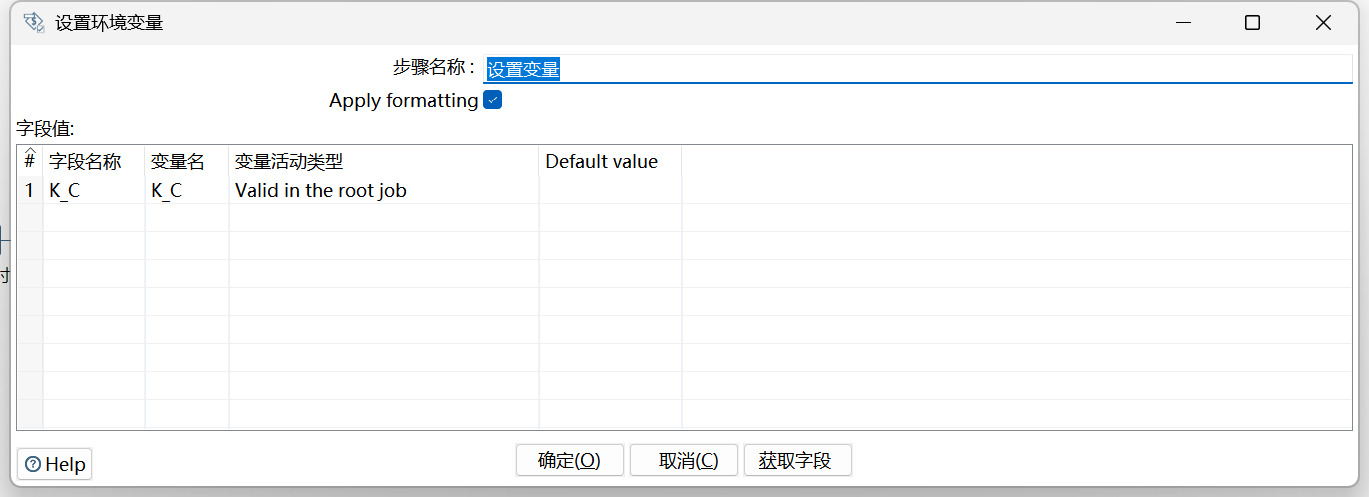
getData转换中,主要是获取参数值、删除DB数据(此脚本中未添加)、获取数据、解析和存储。流程图和详细过程如下:


MongoDB input组件其它设置如上,需要在Query选项卡中设置参数过滤条件(如上表示为:只获取K_C时间戳后面的数据)。
Json input组件设置类比上文设置,此处无需修改。
表输出时,不要勾选裁剪表。

注意:上面脚本中没有先删除数据,规范做法是删数后增数,这样才能避免数据的重复。


















 4897
4897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











