




从容器编排新手到大师
你好,开发者!欢迎来到Docker的世界。你可能已经掌握了docker run命令,能够轻松地启动一个独立的数据库、Web服务器或者你的新API。但当这些服务需要协同工作时,情况就变得复杂了。你可能会发现自己像个杂耍演员,费力地处理着一长串命令、手动创建网络,并努力记住哪个端口映射到了哪里。这不仅混乱,而且极易出错。
是时候认识一下你容器化应用的新指挥家了:Docker Compose。把它想象成你容器乐团的总指挥。Compose让你能够在一个简单的文件中定义整个多容器应用,然后用两三个命令就能管理其完整的生命周期。
本指南将带你走过一段清晰的学习旅程。我们将首先探讨“为什么”需要Compose,然后通过一个Nginx的实战案例让你亲自动手,接着深入剖析其核心概念,并最终构建一个真实的多容器应用。读完本指南,你将不再是容器的“杂耍演员”,而是能够自信地指挥整个应用乐团的“总指挥”。
为什么你需要一位指挥家:Docker Compose的价值所在
为了真正理解Docker Compose的价值,我们首先需要感受一下没有它时的“痛苦”。
手动操作的痛苦:一张命令织成的网
想象一下,你需要启动一个典型的三层应用:一个前端、一个后端API和一个数据库。如果只使用docker run,你的操作流程可能如下所示:
- 手动创建网络:首先,你需要创建一个专用的网络,以便容器之间可以相互通信。
Bash
docker network create my-app-net- 启动数据库容器:将数据库容器连接到这个网络。
Bash
docker run -d --name db --network my-app-net postgres:latest- 启动API容器:将API容器也连接到该网络,并通过环境变量告诉它数据库的主机名。
Bash
docker run -d --name api -p 8080:8080 --network my-app-net -e DATABASE_HOST=db my-api-image- 启动前端容器:最后,启动前端容器并连接到网络。
Bash
docker run -d --name web -p 3000:3000 --network my-app-net my-frontend-image这个过程暴露了几个明显的问题:命令冗长且容易出错;你需要手动管理启动顺序(先启动数据库);网络和端口配置难以记忆;最重要的是,如果你想让团队中的另一位成员搭建同样的环境,你需要把这一堆复杂的指令和注意事项都交给他,这极易导致“在我电脑上明明是好的”这类问题。
应用的蓝图:使用compose.yaml进行声明式配置
Docker Compose通过引入一个名为compose.yaml(或docker-compose.yml)的YAML文件来解决上述所有问题。这个文件是你整个应用的“单一事实来源”。
这种方式引入了一种重要的思维转变:从命令式到声明式的转变。
- 命令式(
docker run):你一步步地告诉Docker“如何”做事。你必须指定网络、链接、顺序等所有细节。 - 声明式(
compose.yaml):你只需“描述”你想要的最终状态——我需要一个Web服务、一个API服务和一个数据库服务,它们之间需要能通信。然后,Compose会负责弄清楚如何达到这个状态。
这种从关注“过程”到关注“状态”的转变,不仅仅是节省了敲键盘的次数,它是一种根本性的思维模型升级。你不再需要思考构建环境的具体步骤,而是开始思考环境的最终定义。正是这种抽象能力,使得环境的一致性、可重复性和可扩展性成为可能。
两种工作流的对比
下面的表格直观地展示了两种工作流之间的天壤之别:
| 特性 | 手动 |
|
| 配置 | 一系列复杂、独立的命令,通常保存在一个脆弱的Shell脚本中。 | 一个单一、人类可读的 |
| 网络 | 手动创建网络 ( | 自动化。Compose为项目创建一个专用网络。 |
| 服务发现 | 需要手动处理主机名或IP地址,通常通过环境变量传递。 | 自动化。服务之间可以使用服务名作为主机名直接通信(例如, |
| 启动 | 运行多个、有顺序的 | 一个命令: |
| 关闭与清理 | 逐个停止和移除容器 ( | 一个命令: |
| 共享与可复用性 | 困难。需要共享复杂的脚本和说明,容易出现环境不一致的问题。 | 简单。将 |
核心工作流:你的第一首Nginx协奏曲
现在,让我们从理论走向实践,亲手指挥你的第一个容器应用。
三步走的节奏
使用Docker Compose的核心工作流非常简单,可以总结为三步走的“节奏”:
- 定义 (Define):创建一个
compose.yaml文件来定义你的应用栈。 - 运行 (Run):在项目目录下,使用
docker compose up来启动所有服务。 - 停止 (Stop):使用
docker compose down来停止并移除所有相关资源。
这个简单的流程是你在日常开发中使用Compose的基础。
你的第一个compose.yaml:一个简单的Web服务器
让我们来创建一个只包含Nginx Web服务器的简单应用。
首先,在你的电脑上创建一个新文件夹,例如 nginx-hello-world,然后在该文件夹中创建一个名为 compose.yaml 的文件。
# compose.yaml
version:'3.8'
services:
webserver:
image:nginx:1-alpine
ports:
-"8080:80"这个文件是我们指挥整个应用的“乐谱”。我们选择将主机端口设置为8080,这是一个很好的实践,可以避免与你本地机器上可能已经在运行的其他服务(它们可能占用了默认的80端口)发生冲突。
剖析Compose文件
让我们逐行解析这个文件的含义:
version: '3.8': 这一行指定了Compose文件的格式版本。不同的版本支持不同的语法和功能。通常,使用较新的版本是推荐的做法。services:: 这是Compose文件的核心部分。你将在这个关键字下定义构成应用的所有独立组件(即容器)。webserver:: 这是我们为服务起的名字。这个名字是你自己选择的,它将成为这个容器在Compose环境中的唯一标识。例如,你可以用docker compose logs webserver来查看它的日志。image: nginx:1-alpine: 这行告诉Compose使用哪个Docker镜像来创建容器。nginx是镜像的名称,1-alpine是它的标签(tag),代表一个特定的版本。使用alpine标签是一个好习惯,因为它基于Alpine Linux,体积非常小,能让你的应用更轻量、更高效。ports:: 这个部分负责将你的本地机器(主机)的端口与容器内的端口进行映射。- "8080:80": 这是具体的端口映射规则。它的意思是:“将我本地机器的8080端口,映射到webserver容器内部的80端口”。冒号右边的80是Nginx服务在容器内默认监听的端口。冒号左边的8080是你将通过浏览器访问的端口。
让它“活”起来:up与down
现在,乐谱已经写好,让我们开始指挥吧。
运行应用
在你的终端中,确保你位于 nginx-hello-world 文件夹下,然后运行以下命令:
Bash
docker compose up -d这里的 -d 标志代表“detached”模式,它会让容器在后台运行,而不会占用你的终端窗口。
当你运行这个命令时,Compose会做几件事:
- 检查本地是否有
nginx:1-alpine镜像,如果没有,就从Docker Hub上拉取它。 - 创建一个专用的网络,名字通常是
nginx-hello-world_default。 - 根据你的定义,创建并启动
webserver容器,并将其连接到上述网络。
验证运行
现在,打开你的网络浏览器,访问 http://localhost:8080。你应该能看到Nginx的欢迎页面:“Welcome to nginx!”。这证明了你的容器正在运行,并且端口映射也成功了。
你还可以运行以下命令来查看你项目中的服务状态:
Bash
docker compose ps这个命令会列出当前项目中的所有容器、它们的状态以及端口映射信息。
停止应用
当你完成实验后,可以用一个简单的命令来清理所有东西:
Bash
docker compose down这个命令会停止并移除 webserver 容器,同时也会移除之前为它创建的网络。这就是Compose强大的地方——一键启动,一键清理。
项目即部署单元
你可能已经注意到,Compose自动创建的网络名称是基于你的项目文件夹名(nginx-hello-world_default)生成的。这并非巧合,而是一个核心设计理念。Compose将位于同一目录下的compose.yaml文件所定义的一组服务视为一个独立的“项目”或“应用”。
所有为该项目创建的资源(容器、网络、卷)都会以项目名作为前缀进行命名空间隔离。这意味着你可以在同一台机器上运行多个完全不同的Compose项目,而它们之间不会相互干扰。project-a中的web服务不会与project-b中的web服务发生冲突。这种内置的隔离机制是Compose能够提供清晰、可并行开发环境的基石。
解锁真正潜力:Compose的核心概念
简单的Nginx示例只是一个开始。要构建真实世界的应用,你需要掌握Compose更强大的功能。
超越官方镜像:构建你自己的服务
在实际开发中,你通常需要运行自己编写的代码。这时,你就需要将Dockerfile与compose.yaml结合起来。
这两者的角色分工非常明确:
Dockerfile:是一份用于构建自定义镜像的“配方”。compose.yaml:是一份用于运行和编排容器的“蓝图”,这些容器可以来自官方镜像,也可以来自你用Dockerfile构建的自定义镜像。
在compose.yaml中,我们使用build关键字来代替image关键字:
services:
my-custom-api:
build:. # 告诉Compose在当前目录下寻找Dockerfile
ports:
- "5000:5000"当Compose看到build:.时,它会自动执行docker build命令,使用当前目录下的Dockerfile来构建一个新镜像,然后从这个新镜像启动一个容器。这是使用Compose开发自定义应用的标准工作流。
别让数据丢失:使用卷(Volumes)实现持久化存储
首先要明白一个关键点:容器的文件系统是临时的(ephemeral)。当你运行docker compose down时,容器被销毁,你在容器内部写入的任何数据(如数据库文件、用户上传的内容)都会随之永久消失。
为了解决这个问题,Docker提供了卷(Volumes)。卷是Docker官方推荐的数据持久化方式。你可以把它想象成一个由Docker管理的、专用于容器的“虚拟硬盘”。它存在于你的主机上,但其生命周期与任何单个容器都相互独立。
命名卷 vs. 绑定挂载
- 绑定挂载 (Bind Mounts):这种方式将主机上的一个明确路径(如
./my-code)直接映射到容器内部。这在开发时非常有用,因为它允许你在本地编辑器中修改代码,并立即在运行的容器中看到变化。 - 命名卷 (Named Volumes):这是持久化应用数据(如数据库文件)的首选方式。它们由Docker完全管理,屏蔽了主机文件系统的具体路径,使得应用更加可移植和健壮。
YAML语法与工作流
在compose.yaml中使用命名卷分为两步:
- 在顶层声明卷:在文件的最外层,使用
volumes关键字声明一个或多个命名卷。
volumes:
database-data:- 将卷挂载到服务:在需要持久化数据的服务(如数据库)下,同样使用
volumes关键字,将声明好的命名卷挂载到容器内的指定路径。
services:
db:
image: postgres:15-alpine
volumes:
# 将名为'database-data'的卷挂载到容器的/var/lib/postgresql/data目录
- database-data:/var/lib/postgresql/data
volumes:
# 这里声明的卷名必须与服务中使用的名称一致
database-data:现在,当你运行docker compose up,写入数据到数据库,然后运行docker compose down时,容器虽然被移除了,但名为database-data的卷依然存在。下次你再运行docker compose up,一个新的Postgres容器会被创建,但它会挂载到这个已存在的卷上,你的所有数据都将完好无损。
如果你确实想要彻底清除所有数据,包括卷,你需要使用一个特殊的标志:docker compose down --volumes。
轻松通信:Compose网络的魔法
服务之间如何相互通信?这背后是Compose最神奇的功能之一:自动化网络。
当你运行docker compose up时,Compose会自动为你的项目创建一个私有的虚拟网络。项目中的所有服务都会被自动连接到这个网络上。
最关键的特性是服务发现:在这个私有网络上,每个服务都会被自动分配一个DNS条目,其主机名就是你在compose.yaml中定义的服务名。
这意味着,如果你的compose.yaml里有一个名为db的服务和一个名为api的服务,那么api容器的代码可以直接通过主机名db来访问数据库服务,完全不需要关心它的IP地址是什么。
例如,在你的应用代码中,数据库连接字符串会是这样:postgres://user:pass@db:5432,而不是postgres://user:pass@172.18.0.5:5432。这种方式让你的应用配置变得干净、可移植,并且与底层基础设施无关。
真实应用栈:Python Web应用 + Redis计数器
现在,让我们把前面学到的所有概念——自定义构建、持久化卷(虽然本例中Redis数据是临时的,但原理相通)和网络——融合到一个完整的、可工作的多容器应用中。
场景:我们将构建一个基于Python Flask框架的简单Web应用。它会连接到一个Redis数据库,用于记录网页被访问的次数。这个例子完美地展示了一个自定义构建的服务(web)如何与一个官方镜像服务(redis)进行通信。
项目搭建
创建一个新文件夹,并在其中创建以下四个文件。
文件 1: app.py (Python应用代码)
import time
import redis
from flask import Flask
app = Flask(__name__)
# 使用服务名'redis'作为主机名连接到Redis
cache = redis.Redis(host='redis', port=6379)
def get_hit_count():
retries = 5
while True:
try:
# 在Redis中对'hits'键执行自增操作
return cache.incr('hits')
except redis.exceptions.ConnectionError as exc:
if retries == 0:
raise exc
retries -= 1
time.sleep(0.5)
@app.route('/')
def hello():
count = get_hit_count()
return f'Hello from Docker! I have been seen {count} times.\n'请特别注意这一行:cache = redis.Redis(host='redis', port=6379)。这正是上一节网络概念的实际应用 。
文件 2: requirements.txt (Python依赖)
flask
redis文件 3: Dockerfile (Web应用的构建配方)
# 使用官方Python镜像作为基础
FROM python:3.10-alpine
# 在容器内设置工作目录
WORKDIR /code
# 复制依赖文件到工作目录
COPY requirements.txt.
# 安装requirements.txt中指定的包
RUN pip install --no-cache-dir -r requirements.txt
# 将当前目录的所有内容复制到容器的/code目录
COPY..
# 声明容器将监听5000端口
EXPOSE 5000
# 容器启动时运行app.py
CMD ["flask", "run", "--host=0.0.0.0"]这个Dockerfile中的每一行都有注释,清晰地说明了其作用。
文件 4: compose.yaml (指挥家的总乐谱)
version: '3.8'
services:
web:
build:.
ports:
- "8000:5000"
redis:
image: "redis:alpine"这个compose.yaml文件将所有部分串联起来 20:
web服务使用build:.指令,根据我们的Dockerfile构建自定义的Flask应用镜像。redis服务则直接使用Docker Hub上的官方redis:alpine镜像。ports将我们主机的8000端口映射到web容器的5000端口。
运行与验证
在项目目录下,运行以下命令:
docker compose up --build--build标志会告诉Compose在启动前先构建web服务的镜像。当你修改了Dockerfile或requirements.txt后,都需要使用这个标志。
启动完成后,访问http://localhost:8000。你应该能看到计数器,并且每次刷新页面,数字都会增加。这证明了你的Python应用成功地通过Compose创建的网络连接到了Redis服务!
开发者的日常工具箱:常用命令参考
为了方便你的日常开发,这里整理了一份最常用的Docker Compose命令速查表。
| 命令 | 描述 | 常用场景 |
|
| 创建并启动 | 启动你的开发环境。 |
|
| 与 | 启动环境,同时保持终端可用。 |
|
| 停止并移除由 | 完全拆除环境,恢复干净状态。 |
|
| 与 | 谨慎使用! 这会清除项目的所有持久化数据。 |
|
| 列出与当前项目关联的所有容器,显示其状态和端口映射。 | 快速检查你的服务是否正常运行。 |
|
| 显示所有服务的日志输出。 | 调试服务问题的主要工具。 |
|
| 实时跟踪特定服务(如 | 在测试API时实时观察错误信息。 |
|
| 为配置了 | 在修改 |
|
| 在一个正在运行的特定容器内执行命令。 | 运行数据库迁移: |
|
| 停止或启动已存在的容器,但不会移除它们。 | 临时暂停环境以释放资源,稍后可以恢复而不会丢失状态(与 |
结语:现在,你就是指挥家
恭喜你!通过本指南,你已经学习了如何使用Docker Compose将管理多个容器的混乱过程,转变为一个简单、可重复的优雅流程。你了解了如何用一个文件定义整个应用,服务之间如何通过网络轻松通信,以及如何用卷来保护关键数据。
你不再是那个手忙脚乱的容器“杂耍演员”,你已经成为了能够从容指挥整个应用乐团的“总指挥”。
这只是一个开始。接下来,你可以继续探索更高级的主题,例如使用.env文件管理环境变量,通过depends_on控制服务启动顺序,以及使用docker compose up --scale来扩展你的服务。Docker Compose的强大功能,将持续为你的开发工作流带来便利和效率。祝你在容器化的世界里一帆风顺!
从开发到生产
本指南旨在成为一份面向开发者的专业级技术手册,深入解析docker-compose.yml文件的核心配置项。为了提供一个连贯且实用的学习体验,我们将贯穿全文使用一个统一的基础场景:一个由Python Flask Web应用(服务名为web-app)和PostgreSQL数据库(服务名为db)组成的典型双容器应用。通过这个例子,我们将逐一剖析从基础定义到生产级实践的各项配置。
第一章 服务基础:定义和管理你的容器
在Docker Compose中,services是配置文件的核心,每个服务(service)都定义了应用中的一个组件,它将以一个或多个容器的形式运行。本章将介绍定义一个服务最基础的三个配置项。
image
image指令用于指定创建服务容器时所使用的Docker镜像。这个镜像可以来自公共仓库(如Docker Hub),也可以是私有仓库中的镜像,或者是本地已经存在的镜像。这是定义一个服务最基本、最核心的配置。
对于我们的数据库服务,我们可以直接使用官方的PostgreSQL镜像。
# docker-compose.yml
version: '3.8'
services:
db:
image: postgres:15-alpinecontainer_name
container_name指令允许你为服务的容器指定一个固定的、静态的名称。
虽然这在开发过程中通过docker exec my-container-name...等命令进行调试时很方便,但它也引入了硬编码的弊端。Docker Compose默认会为容器生成唯一的名称,格式通常为<project_name>-<service_name>-<index>(例如myapp-db-1)。这种自动命名机制可以有效防止命名冲突,并且是服务能够水平扩展(scaling)的前提。如果你为一个服务设置了container_name,那么该服务将无法扩展到多个实例。
最佳实践:在生产环境或需要扩展的服务中,应避免使用container_name。仅在开发环境中,为那些确定为单实例且需要频繁手动访问的服务(如数据库)酌情使用。
services:
db:
image: postgres:15-alpine
container_name: my_project_postgres_dbrestart策略
restart策略是确保应用弹性和高可用性的关键配置。它定义了当一个容器停止或崩溃时,Docker守护进程应如何处理。一个常见的误区是将restart策略与docker compose restart命令混淆。后者是用户手动执行的重启操作,而前者是在YAML文件中声明的、控制容器自动行为的规则。
以下是不同restart策略的详细对比:
| 策略 | 行为描述 | 典型用例 | 关键考量 |
|
| (默认值) 容器在任何情况下都不会自动重启。 | 一次性任务(如数据迁移脚本)、开发环境调试(需要手动控制)。 | 容器退出后将保持 |
|
| 无论退出状态码是什么,容器总会自动重启。即使是手动 | 需要最高可用性的关键服务,如负载均衡器或核心API。 | 如果容器启动后立即失败,可能会导致无限重启循环。手动停止操作在守护进程重启后会被覆盖。 |
|
| 仅当容器以非零状态码退出(即发生错误)时才会重启。 | 批处理作业、数据迁移脚本,或任何可以正常完成并退出的任务。 | 如果容器正常退出(退出码为0),则不会重启。 |
|
| 容器总会自动重启,除非它被用户明确停止(如 | 生产环境中绝大多数长期运行服务的最佳选择,如Web服务器、数据库、API等。 | 提供了 |
对于我们的示例应用,Web服务和数据库都是需要持续运行的核心组件,因此unless-stopped是理想的选择。
services:
web-app:
#... 其他配置
restart: unless-stopped # Web服务的稳健选择
db:
image: postgres:15-alpine
container_name: my_project_postgres_db
restart: unless-stopped # 关键数据库应始终保持运行第二章 从源码到服务:build与image指令
本章将深入探讨服务镜像的两种来源方式:使用image指令拉取预构建的镜像,或使用build指令从源代码构建自定义镜像。这个选择直接关系到你的开发工作流和生产部署策略。
image指令
如前所述,image指令用于拉取一个已经存在于镜像仓库中的镜像。这是使用第三方服务(如数据库、缓存)或部署已通过CI/CD流程构建好的自定义应用镜像的标准方式。
build指令
build指令告诉Docker Compose如何从源代码文件构建一个镜像,这对于自定义应用是必不可少的。
context: 定义构建上下文的路径。这个路径下的所有文件(遵循.dockerignore规则)都会被发送到Docker守护进程用于构建。通常,这是你项目代码和Dockerfile所在的目录。dockerfile: 可选指令,用于指定一个替代默认Dockerfile文件名的文件 9。
services:
web-app:
build:
context:./my-flask-app # Dockerfile在此目录下
dockerfile: Dockerfile.dev # 使用名为Dockerfile.dev的文件深度解析:build vs. image
build和image的选择体现了开发与生产环境的核心差异。build主要服务于开发阶段,此时源代码频繁变动,需要快速重新构建。而image则服务于生产阶段,此时部署的是不可变的、经过版本控制的镜像,以确保环境的一致性和可靠性。一个规范的生产环境docker-compose.yml文件应该只使用image指令,指向在CI/CD流水线中构建并推送到镜像仓库的特定版本镜像。
| 指令 | 镜像来源 | 主要用例 | 工作流影响 | 可移植性 |
|
| 主机上的源代码(通过 | 开发环境、CI环境 | 镜像由 | 低。需要在目标主机上存在源代码。 |
|
| Docker镜像仓库(如Docker Hub)或本地缓存 | 生产、预发、测试环境 | 镜像是预先构建好的、带版本号的制品,将部署与构建过程解耦。 | 高。镜像可以被拉取到任何地方运行。 |
组合使用:连接开发与生产的桥梁
当build和image同时为一个服务指定时,docker compose build会根据build指令构建镜像,然后用image指令提供的值为该镜像打上标签。
这个模式是开发与生产工作流之间的桥梁。它允许开发者在本地构建和测试镜像,并为其打上一个符合生产规范的标签(如my-registry/my-app:1.2.0)。随后,这个带标签的镜像可以通过docker compose push推送到镜像仓库。最终,生产环境的Compose文件只需通过image指令引用这个确切的标签即可。
# 在开发环境的 docker-compose.yml 中
services:
web-app:
build:.
image: my-company/web-app:latest # 构建并标记为这个名称
# 在生产环境的 docker-compose.prod.yml 中
services:
web-app:
image: my-company/web-app:1.2.3 # 拉取一个特定的、不可变的版本第三章 暴露服务:端口映射深度解析
端口映射(Port Mapping)是在主机和容器之间建立一个流量转发规则,使得外部网络可以访问容器内运行的服务。
短语法 ("HOST:CONTAINER")
这是最常用、最简洁的端口映射格式。
"5001:5000": 将主机的5001端口映射到容器的5000端口。"5000": 将容器的5000端口映射到主机上的一个随机可用端口。这在自动化测试中非常有用,可以避免端口冲突。"127.0.0.1:5001:5000": 仅将主机端口绑定到localhost接口,增强了安全性,因为服务不会暴露给外部网络。
services:
web-app:
build:.
ports:
- "5001:5000" # 将应用的5000端口暴露在主机的5001端口长语法
长语法提供了更精细的控制,尤其在Docker Swarm集群或复杂的网络环境中非常有用。
target: 容器内的端口。published: 映射到主机的端口。protocol: 指定协议,tcp或udp。mode:host或ingress。ingress是默认值,用于Swarm集群的路由网格(routing mesh)进行负载均衡。mode: host则会绕过路由网格,直接在运行该容器的节点上发布端口。
对于在单机上进行开发的开发者而言,短语法几乎总是足够的。长语法的重要性在部署到集群环境时才真正体现出来。
services:
web-app:
build:.
ports:
- target: 5000
published: 5001
protocol: tcp
mode: host第四章 动态配置:精通环境变量
环境变量是将运行时配置传递给服务的核心机制,它实现了应用行为与镜像本身的解耦。
environment指令
environment指令可以直接在Compose文件中为服务设置环境变量。
- 字典(Map)语法: 使用
KEY: VALUE的格式,清晰易读。 - 列表(List)语法: 使用
- KEY=VALUE的格式,同样很常见。 - 变量直通(Passthrough): 使用
- VARIABLE的格式。这会将运行docker compose命令的Shell环境中的同名变量值直接传递到容器内。这对于不希望在文件中硬编码的动态配置非常有用。
services:
db:
image: postgres:15-alpine
restart: unless-stopped
environment:
POSTGRES_USER: myuser
POSTGRES_DB: mydatabase
# 从执行命令的Shell环境中获取密码
- POSTGRES_PASSWORDenv_file指令
env_file指令可以指定一个或多个外部文件(如.env),从中加载环境变量。这是将配置与Compose文件分离的最佳实践,尤其便于管理不同环境(开发、测试、生产)的配置。
# 在 docker-compose.yml 中
services:
db:
image: postgres:15-alpine
restart: unless-stopped
env_file:
-./postgres.env
# 在 postgres.env 文件中
POSTGRES_USER=myuser
POSTGRES_DB=mydatabase
POSTGRES_PASSWORD=supersecret优先级层次结构
Docker Compose在确定最终生效的环境变量值时,遵循一个严格的优先级顺序。理解这个顺序对于避免配置错误至关重要。
以下是环境变量来源的优先级排序,从高到低:
- 命令行
docker compose run -e: 通过命令行run子命令的-e或--env标志设置的变量具有最高优先级,会覆盖所有其他来源。 - Compose文件中的
environment指令: 在services下直接通过environment键定义的变量。 - Compose文件中的
env_file指令: 通过env_file引用的文件中的变量。如果指定了多个文件,后一个文件中的定义会覆盖前一个。 - 项目目录下的
.env文件: Compose会自动加载项目根目录下名为.env的文件,这些变量可用于Compose文件内的变量替换,也会作为环境变量注入容器,但优先级较低。 - Dockerfile中的
ENV指令: 在构建镜像时,通过ENV指令在Dockerfile中定义的变量具有最低优先级。
这个层次结构确保了配置的灵活性和可覆盖性,允许在不同阶段(构建、编排、运行)注入和修改配置。
第五章 数据持久化与状态:数据卷与绑定挂载指南
容器的文件系统是临时的。当一个容器被删除时,其内部写入的所有数据都会丢失。数据卷(Volumes)和绑定挂载(Bind Mounts)是解决这个问题的两种核心机制,它们能将数据持久化到容器生命周期之外。
绑定挂载 (Bind Mounts)
绑定挂载直接将主机文件系统上的一个文件或目录映射到容器内。
- 核心用途: 这是开发环境的标准选择。它允许开发者在主机上使用熟悉的IDE编辑代码,所做的更改会立即反映在运行的容器中,从而实现“热重载”开发工作流。
- 风险: 绑定挂载使容器能够直接修改主机文件系统,这带来了安全风险。一个被攻破的容器可能会篡改甚至删除主机上的重要文件。
# 短语法
services:
web-app:
build:.
volumes:
# 将本地的 my-flask-app 目录挂载到容器的 /app 目录
-./my-flask-app:/app数据卷 (Volumes)
数据卷是由Docker管理的一块存储区域。它存在于主机文件系统的特定位置(如/var/lib/docker/volumes),但用户通常通过名称而非具体路径来操作它,实现了与主机环境的解耦。
- 匿名卷 (Anonymous Volumes): 如果在挂载时不指定源名称,Docker会自动创建一个匿名卷。它能持久化数据,但难以被其他服务引用,并且通常在执行
docker compose down -v时被一并删除。 - 命名卷 (Named Volumes): 这是所有持久化应用数据(如数据库文件、用户上传内容)的标准和推荐方式。命名卷在顶层的
volumes键中声明,并通过名称被服务引用。
services:
db:
image: postgres:15-alpine
volumes:
# 将名为 postgres_data 的数据卷挂载到PostgreSQL的数据目录
- postgres_data:/var/lib/postgresql/data
# 在顶层声明命名卷
volumes:
postgres_data: {} # Docker将负责创建和管理这个卷深度解析:命名卷 vs. 绑定挂载
两者最根本的区别在于管理方式:数据卷由Docker引擎管理,而绑定挂载由主机操作系统管理。这一区别决定了它们在可移植性、性能和安全性上的巨大差异。
核心结论:在开发时使用绑定挂载来同步代码,在所有环境(开发、测试、生产)中都使用命名卷来存储应用数据。
| 特性 | 命名卷 (Named Volumes) | 绑定挂载 (Bind Mounts) |
| 管理方 | 由Docker引擎管理 ( | 由用户/主机操作系统管理 |
| 主机依赖 | 无。名称是唯一标识,与主机路径无关。 | 高。强依赖于主机上的特定文件路径。 |
| 可移植性 | 高。Compose文件是自包含的,可在任何Docker主机上运行。 | 低。如果主机上路径不存在,服务将启动失败。 |
| 性能 | 高性能。在Docker Desktop (Mac/Windows)上,性能远超绑定挂载。 | 在Docker Desktop上因文件系统共享开销而较慢。 |
| 安全性 | 更安全。数据被隔离在Docker管理的目录中。 | 风险更高。容器可直接读写主机文件系统。 |
| 典型用例 | 应用数据(数据库、用户上传、状态文件)。 | 开发环境的源代码同步(热重载)。 |
只读模式
在挂载定义的末尾追加:ro(read-only),可以将数据卷或绑定挂载在容器内设置为只读模式。这是一个简单而有效的安全增强措施,可以防止应用意外修改不应更改的数据,如配置文件。
volumes:
-./config.json:/app/config.json:ro第六章 高级概念与生产最佳实践
本章将介绍一些使你的Docker Compose应用更健壮、更安全、更易于维护的高级配置。
使用depends_on和healthcheck控制启动顺序
一个常见的问题是,应用容器(如web-app)的启动速度可能比数据库容器(db)快,导致应用在启动时因无法连接到数据库而崩溃。
- 简单的
depends_on:depends_on: [db]只保证db容器在web-app容器之前启动。它并不等待db容器内的PostgreSQL服务真正准备好接受连接。 healthcheck: 此指令定义了一个命令,Docker会定期在容器内运行该命令以检查其真实健康状况。- 健壮的解决方案:
depends_on与condition: service_healthy结合使用。这会使web-app服务一直等待,直到db服务的healthcheck检查通过,从而确保依赖的服务已完全就绪。这种方式是取代传统wait-for-it.sh等脚本的现代化、声明式方案。
services:
web-app:
build:.
restart: unless-stopped
depends_on:
db:
condition: service_healthy # 等待db服务健康后再启动
db:
image: postgres:15-alpine
restart: unless-stopped
env_file:
-./postgres.env
healthcheck:
# 使用PostgreSQL的工具检查数据库是否准备就绪
test:
interval: 10s
timeout: 5s
retries: 5
volumes:
- postgres_data:/var/lib/postgresql/data
volumes:
postgres_data: {}使用secrets管理敏感数据
将密码、API密钥等敏感信息直接写入环境变量存在安全风险,它们可能通过docker inspect命令或错误日志被泄露。
- 解决方案:Docker Secrets:
secrets是由Docker安全管理的敏感数据。它们被挂载到容器的一个内存文件系统中的临时文件里(路径为/run/secrets/<secret_name>),而不是作为环境变量。 _FILE后缀约定: 许多官方镜像(如postgres)支持通过一个以_FILE结尾的环境变量来读取密钥。例如,设置POSTGRES_PASSWORD_FILE=/run/secrets/db_password,镜像就会从该文件路径读取密码,而不是从POSTGRES_PASSWORD变量中读取。
services:
db:
image: postgres:15-alpine
environment:
POSTGRES_USER: myuser
POSTGRES_DB: mydatabase
# 指示PostgreSQL镜像从指定文件读取密码
POSTGRES_PASSWORD_FILE: /run/secrets/db_password
secrets:
- db_password # 授权此服务访问名为db_password的secret
# 在顶层定义secrets
secrets:
db_password:
file:./db_password.txt # 从本地文件加载secret内容使用deploy.resources进行资源管理
默认情况下,容器可以无限制地使用主机的CPU和内存,这可能导致某个服务的资源滥用拖垮整个系统。
deploy.resources键可以为服务设置资源限制,确保系统稳定性。
reservations: 为容器保留的资源量(软限制)。limits: 容器能够使用的资源量的绝对上限(硬限制)。
尽管deploy键最初是为Docker Swarm模式设计的,但现在它已成为在单机docker compose环境中设置资源限制的标准方法。
services:
web-app:
build:.
deploy:
resources:
reservations:
cpus: '0.25'
memory: 256M
limits:
cpus: '0.5'
memory: 512M使用YAML锚点编写可维护的Compose文件
在复杂的应用中,多个服务(如Web服务器和后台工作进程)可能共享大量配置,导致YAML文件冗长且难以维护。YAML的锚点(&)和别名(*)功能可以解决这个问题。
x-*扩展字段: 一个最佳实践是将共享配置块定义在一个以x-开头的顶层键下(如x-common-config)。Docker Compose会忽略这些键,使其成为理想的模板定义区域。
# 定义一个可复用的配置模板
x-app-template: &app-defaults
build:.
restart: unless-stopped
env_file:.env
depends_on:
db:
condition: service_healthy
services:
web-app:
<<: *app-defaults # 使用 <<: * 来合并模板
ports:
- "5001:5000"
command: ["flask", "run", "--host=0.0.0.0"]
worker:
<<: *app-defaults # 复用同一个模板
command: ["celery", "-A", "my_app.celery", "worker"]理解Compose网络与服务发现
当你运行docker compose up时,Compose会自动为你的应用创建一个专用的桥接网络(bridge network),名称通常为<project_name>_default。
- 内置DNS服务: 在这个网络上的任何容器都可以通过服务名作为主机名来解析并访问其他容器 。例如,
web-app容器可以通过主机名db连接到数据库容器。这是由Docker内置的DNS服务器实现的。 - 工作原理: 这就是为什么我们的数据库连接字符串可以是
postgres://myuser:password@db:5432。db这个服务名被自动解析为数据库容器的内部IP地址。这个内置的服务发现机制是Compose强大功能的核心。
结论:编写可维护Compose文件的最佳实践清单
编写高质量的docker-compose.yml文件是一项结合了技术准确性和架构设计的艺术。以下是一份旨在帮助你构建健壮、安全且可维护的多容器应用的实践清单:
- 使用
unless-stopped重启策略:为所有长期运行的服务(如Web服务器、数据库)设置此策略,以在意外崩溃后自动恢复,同时尊重手动维护操作。 - 分离构建与部署:在开发工作流中使用
build指令,但在生产部署时,应始终使用image指令指向一个来自镜像仓库的、带有特定版本标签的不可变镜像。 - 明确数据类型:使用命名卷(Named Volumes)来持久化所有应用数据(如数据库文件、用户上传)。仅在开发环境中为同步源代码使用绑定挂载(Bind Mounts)。
- 保护敏感信息:绝不将密码、API密钥等敏感信息硬编码或存储在环境变量中。始终使用
secrets来安全地管理它们。 - 确保启动顺序健壮:不要只依赖
depends_on。为其依赖的服务配置healthcheck,并使用condition: service_healthy来确保服务在完全就绪后才被依赖。 - 在生产中限制资源:为所有生产服务设置
deploy.resources中的limits和reservations,以防止资源争用并提高系统稳定性。 - 配置与代码分离:使用
.env文件来管理特定环境的配置,保持docker-compose.yml文件的通用性和清洁性。 - 保持代码简洁(DRY):对于共享大量配置的多个服务,使用YAML锚点和
x-*扩展字段来定义可复用模板,减少重复。 - 信任内置网络:利用Docker Compose自动创建的网络和内置DNS进行服务间通信。避免在容器间使用硬编码的IP地址。
- 保持镜像更新:选择最小化的基础镜像,并定期使用
--no-cache选项重建应用镜像,以获取最新的安全补丁和依赖更新。
DevOps 团队实战
Docker Compose 是定义和运行多容器 Docker 应用程序的核心工具。通过一个compose.yaml 文件,我们可以声明式地管理整个应用的服务、网络和卷。本指南旨在为 DevOps 团队提供一份详尽的 Docker Compose 核心命令参考,不仅涵盖基础功能,更深入剖析常用参数、组合用法及其背后的工作原理,帮助团队成员高效、精确地驾驭容器化应用的整个生命周期。
第一部分 应用生命周期管理
这组命令控制着多容器应用的整个生命周期,从初始创建、状态同步到彻底拆除。熟练掌握它们是高效使用 Docker Compose 的基石。
1.1 up: 通用启动器 - 构建、创建、启动与附加
up 命令是所有 Compose 项目的入口。它能够智能地将应用的运行状态与 compose.yaml 文件中的定义同步,是基础设施即代码(IaC)理念的直接体现。
- 核心功能:
up是一个幂等命令。它会检查compose.yaml中的定义,如果服务所需的镜像不存在,它会先构建镜像;如果容器、网络或卷缺失,它会创建它们;最后,它会启动所有服务。如果再次运行,它会检查配置或镜像是否有变动,并仅重新创建发生变化的组件以匹配所需状态。
参数深度解析: -d (Detached Mode)
- 功能:
-d参数使容器在后台运行,执行命令后终端会立即返回并打印新创建的容器名称。若不使用此参数,Compose 会在前台运行,聚合所有服务的日志输出,此时使用Ctrl+C将会停止所有服务。 - 场景化举例: 当你在本地启动开发环境时,你希望后端服务(如 Web 服务器、数据库、缓存)持续运行,同时解放你的终端以执行其他任务(如运行测试、Git 操作)。
docker compose up -d是实现此目的的标准做法。
# 在后台启动 compose.yaml 中定义的所有服务
docker compose up -d参数深度解析: --build
- 功能: 强制 Compose 在启动容器前,为那些在
compose.yaml中定义了build指令的服务重新构建镜像。 - 场景化举例: 你刚刚修改了应用的
Dockerfile,比如添加了一个新的系统依赖 (RUN apk add...),或者更新了被COPY到镜像中的文件(如requirements.txt)。此时若仅运行docker compose up,由于镜像标签未变,Compose 可能不会自动重新构建。使用docker compose up --build能确保在创建容器前,镜像是基于你的最新代码和配置构建的。
# 当 Dockerfile 或构建上下文中的文件发生变化时,强制重新构建镜像并启动服务
docker compose up --build -d参数深度解析: --force-recreate
- 功能: 强制重新创建所有服务的容器,即使它们的配置和镜像本身没有发生任何变化。这是一个比默认行为更具强制性的操作。
- 场景化举例: 某个容器进入了损坏状态,简单的重启 (
docker compose restart) 无法解决问题。例如,一个在启动时生成的临时文件导致了后续的运行错误。你希望彻底丢弃当前容器,并基于相同的镜像启动一个全新的、干净的实例,但又不想重新构建镜像。docker compose up -d --force-recreate正是用于这种“硬重置”场景的命令。
# 强制重新创建所有容器,以获取一个干净的运行实例
docker compose up -d --force-recreate--build 与 --force-recreate 的意图区分
这两个参数虽然都会触发容器的重新创建,但它们反映了开发者截然不同的意图。--build 关注于更新容器的“蓝图”(即 Docker 镜像),而 --force-recreate 则关注于重置容器的“实例”(即运行状态)。
- 当应用的定义发生变化时(如修改了源代码、
Dockerfile或依赖项),开发者的意图是更新构建产物。此时,正确的操作是使用--build来生成新的镜像,Compose 会基于新镜像重新创建容器。 - 当应用的运行状态出现问题时(如遇到偶发性 bug、需要清理容器内的临时数据),但其定义并未改变。问题的根源在于运行中的实例,而非其蓝图。此时,正确的操作是使用
--force-recreate来丢弃当前实例的全部状态,并从现有镜像创建一个全新的实例。
理解这一区别有助于选择更精确、更高效的命令,避免不必要的镜像构建,从而优化开发工作流。
1.2 down: 彻底拆除环境
down 命令是 up 的逆操作,它会停止并移除由 Compose 管理的整个应用栈。
- 核心功能:
down是清理项目的首选命令。它会停止并移除由up命令创建的容器和网络。默认情况下,它对持久化数据(命名卷)是非破坏性的。 - 参数深度解析:
--volumes(-v):- 功能: 扩展
down的能力,使其在拆除环境的同时,一并删除在compose.yaml的volumes部分声明的命名卷以及附加到容器的匿名卷。 - 场景化举例: 你完成了一项功能的测试,该测试在数据库卷中产生了大量测试数据。现在你需要将环境完全重置到初始状态,包括清空所有数据。
docker compose down -v正是执行这种彻底、破坏性清理的命令。
- 功能: 扩展
# 停止并删除容器、网络和所有卷
docker compose down -v- 参数深度解析:
--rmi <'all'|'local'>:- 功能: 移除服务所使用的镜像。
'local'只移除那些没有自定义标签的本地构建镜像。'all'则会移除服务定义中引用的所有镜像。 - 场景化举例: 在 CI/CD 流水线或资源受限的开发机上,测试运行结束后,你希望不仅清理容器,还要清理为此次测试所拉取或构建的 Docker 镜像,以节省磁盘空间。
docker compose down --rmi all可以自动化完成这一清理过程。
- 功能: 移除服务所使用的镜像。
# 停止并删除容器、网络,并移除所有相关的 Docker 镜像
docker compose down --rmi all表格对比: down vs stop vs rm
这三个命令代表了不同层次的“停止”与“移除”,开发者常常混淆它们。下表清晰地展示了各自的作用域和影响,帮助你做出正确选择。
| 特性 |
|
|
|
| 主要动作 | 停止正在运行的容器。 | 移除已停止的服务容器。 | 停止并移除容器。 |
| 容器状态 | 容器依然存在,但处于停止状态。 | 容器被彻底删除。 | 容器被彻底删除。 |
| 网络 | 不受影响。 | 不受影响。 | 移除在 Compose 文件中定义的网络。 |
| 匿名卷 | 不受影响。 | 不受影响。 | 默认不移除。 |
| 命名卷 | 不受影响。 | 不受影响。 | 默认不移除,需加 |
| 核心用例 | 临时暂停应用以释放 CPU/内存,稍后会恢复。 | 清理由 | 完全移除开发或测试环境,准备重新开始。 |
1.3 细粒度状态控制: start, stop, restart
这些命令提供了对已存在容器状态的精细控制,不涉及 up 和 down 的创建/销毁生命周期。
stop: 温和地停止运行中的容器。它会先发送SIGTERM信号,并等待一个默认10秒的超时。如果容器未在此时间内正常退出,则会发送SIGKILL强制终止。容器本身仍然存在。start: 启动那些已经被创建但处于停止状态的容器。它绝不会创建新容器。restart: 这是一个便捷的快捷方式,它会对指定的服务容器依次执行stop和start操作。
# 仅重启 web 服务,不影响其他服务
docker compose restart webrestart 的配置“陷阱”
一个至关重要且经常被误解的点是:docker compose restart不会应用你在 compose.yaml 文件中所做的任何配置更改(例如,修改了环境变量、端口映射等)。它仅仅是重启现有的容器,该容器启动时依然使用其最初创建时的配置。
要应用配置文件的变更,正确的命令是 docker compose up -d。Compose 会检测到配置差异,并自动重新创建容器,从而使新配置生效。因此,restart 用于“重启服务”(比如服务无响应时),而 up 用于“应用更新”。
1.4 暂停执行: pause 和 unpause
这对命令提供了一种独特的“冻结”容器执行的方式,而无需停止它。
- 核心功能:
pause利用 Linux 内核的 cgroups freezer 功能来挂起一个容器内的所有进程。容器的状态被完整地保留在内存中,但它不会获得任何 CPU 时间。网络连接等资源保持建立状态,但不进行数据传输。
unpause 则用于恢复执行。
pausevs.stop:stop是通过发送信号来终止进程,容器退出后需要重新初始化才能启动。而pause是一种非侵入式的挂起,进程本身对此无感知,恢复后会从中断处继续执行,所有内存状态和文件描述符都保持不变。- 场景化举例: 你正在调试一个复杂的多服务应用中的竞态条件。你可以在某个特定时刻“冻结”数据库容器 (
docker compose pause db),以便从容地检查 Web 应用容器的状态,而不用担心数据库状态在其背后发生变化。检查完毕后,再通过docker compose unpause db让一切恢复正常。
# 暂停 db 服务的所有进程
docker compose pause db
# 恢复 db 服务的执行
docker compose unpause db第二部分 状态监控与交互式调试
当应用运行起来后,这组命令就是你观察其内部行为的窗口,对于日常调试、问题定位和直接交互至关重要。
2.1 ps: 服务状态仪表盘
ps 命令提供了应用栈状态的概览。
- 核心功能: 列出项目中所有服务的容器,并显示它们的名称、所用镜像、状态和端口映射等信息。
# 查看当前项目所有服务的状态
docker compose psps命令输出详解:
| 列名 | 描述 | 示例 |
|
| 容器的唯一名称,格式通常为 |
|
|
| 创建该容器所使用的 Docker 镜像。 |
|
|
| 在容器内部作为 PID 1 运行的命令。 |
|
|
|
|
|
|
| 容器创建至今的时间。 |
|
|
| 容器的当前状态,如 |
|
|
| 端口映射规则,格式为 |
|
2.2 logs: 倾听容器的声音
这是查看服务输出 (STDOUT/STDERR) 的主要工具。
- 核心功能:
logs命令会聚合compose.yaml中定义的所有服务的日志,并在每行日志前加上服务名作为前缀,便于区分。你也可以只查看特定服务的日志。
# 查看 web 和 db 两个服务的日志
docker compose logs web db- 参数深度解析:
-f或--follow:- 功能: 实时跟踪日志输出,类似在 Linux 系统上执行
tail -f。命令会持续运行,不断打印新产生的日志 18。 - 场景化举例: 你正在开发一个新的 API 接口,希望在通过 Postman 或前端应用发送请求时,能立即看到服务器的日志反馈。
docker compose logs -f api提供了这种实时反馈循环,是快速调试的利器。
- 功能: 实时跟踪日志输出,类似在 Linux 系统上执行
# 实时跟踪所有服务的日志输出
docker compose logs -f- 参数深度解析:
--tail <N>:- 功能: 只显示每个服务最近的
N行日志。可以与-f组合使用。 - 场景化举例: 一个服务意外崩溃,你想查看它失败前发生了什么,但不想翻阅海量的启动日志。
docker compose logs --tail 100 my_service将只显示最后的100行日志,其中很可能包含了关键的错误信息和堆栈跟踪。
- 功能: 只显示每个服务最近的
# 查看 web 服务最新的 50 行日志,并持续跟踪新日志
docker compose logs --tail 50 -f web2.3 top: 查看容器内部进程
top 命令可以显示指定服务容器内部正在运行的进程列表。
- 核心功能: 它本质上是在容器的命名空间内执行
top或ps命令,让你能看到该容器内的进程表(PID、USER、CMD 等)。 - 场景化举例: 你的
api服务容器占用了异常高的 CPU。你怀疑是某个工作进程挂起或出现了僵尸进程。通过docker compose top api,你可以直接列出该容器内的所有进程,从而快速定位问题进程,而无需先exec进入容器。
# 显示 api 服务容器内正在运行的进程
docker compose top api2.4 exec: 交互式调试入口
exec 命令允许你在一个正在运行的容器内执行任意命令,这是现代开发中替代 SSH 登录服务器进行调试的关键工具。
- 核心功能: 在一个运行中的服务容器内执行命令。它与
docker compose run有着本质区别,后者是为一次性任务创建并运行一个新容器。 - 获取 Shell: 最常见的用法是获取一个交互式 Shell。
- 场景化举例: 你需要检查
web容器的文件系统,确认环境变量是否正确设置,或者手动运行一个诊断脚本。docker compose exec web bash(如果镜像是精简的,可能需要用sh) 会为你提供一个功能齐全的、位于容器内部的命令行提示符。
- 场景化举例: 你需要检查
# 进入名为 web 的服务容器,并启动一个 bash shell
docker compose exec web bashexec 与 run 的关键区别
选择 exec 还是 run 是使用 Compose 时的基本功。exec 操作的对象是一个已存在的、正在运行的容器;而 run 则是创建一个新的、临时的容器来执行任务。
- 当你需要检查一个正在运行的服务的内部状态时,比如查看实时日志文件、检查进程列表或验证网络连接,你应该使用
exec。你的操作目标是那个特定的、正在提供服务的容器实例。 - 当你需要执行一个一次性的管理或批处理任务时,比如运行数据库迁移、执行数据导入导出脚本或运行测试套件,你应该使用
run。例如,docker compose run --rm web./manage.py migrate。这个命令会使用web服务的配置(镜像、环境变量等)创建一个新容器,在其中运行迁移命令,任务结束后--rm参数会自动删除这个临时容器。这个过程不会干扰到你正在运行的、处理用户请求的那个web容器。
理解这个区别可以防止开发者在处理用户请求的 Web 服务器容器里运行破坏性的数据库迁移,或者试图调试一个已经执行完毕并退出的临时任务容器。
第三部分 镜像与资源管理
这部分涵盖了管理应用构建块的命令:Docker 镜像和已停止的容器。
3.1 build: 镜像工厂
build 命令用于构建或重新构建服务的镜像。
- 核心功能: 虽然
up --build很常用,但docker compose build也可以作为一个独立命令运行。它会遍历compose.yaml中所有带build指令的服务,并为它们依次执行docker build。 - 独立使用场景:
- CI/CD 流程: 在 CI 流水线中,通常会将构建、测试和部署阶段分开。第一阶段可以运行
docker compose build来创建所有服务的镜像。后续阶段则基于这些新构建的镜像运行测试。只有测试通过后,镜像才会被推送并部署。 - 预构建与验证: 当你对多个服务的
Dockerfile做了修改,希望在启动整个应用栈之前,先确认所有镜像都能成功构建。单独运行docker compose build可以在不启动任何容器的情况下,一次性验证所有服务的构建过程。
- CI/CD 流程: 在 CI 流水线中,通常会将构建、测试和部署阶段分开。第一阶段可以运行
# 单独构建在 compose.yaml 中定义的所有服务的镜像
docker compose build3.2 pull: 镜像拉取器
pull 命令用于从镜像仓库拉取服务所需的镜像。
- 核心功能: 对于
compose.yaml中使用image:标签定义的服务,此命令会从 Docker Hub 或配置的私有仓库拉取指定的镜像。它不会启动容器。 - 独立使用场景:
- 优化部署速度与可靠性: 你准备向生产环境部署新版本的应用,其中涉及拉取几个较大的镜像。为了最大限度地减少服务中断时间,你可以在执行
docker compose up -d之前,先在生产主机上运行docker compose pull。这会预先下载好所有新版镜像。当最终执行up命令时,由于镜像已在本地,容器的重新创建过程将几乎是瞬时的,从而大大缩短了更新窗口。
- 优化部署速度与可靠性: 你准备向生产环境部署新版本的应用,其中涉及拉取几个较大的镜像。为了最大限度地减少服务中断时间,你可以在执行
# 预先拉取所有服务所需的镜像,为快速部署做准备
docker compose pull3.3 rm: 容器清理工
rm 命令用于移除已停止的服务容器。
- 核心功能: 这是一个比
down更具针对性的清理命令。它只影响已停止的容器,默认情况下不会触及网络和卷。 rmvs.down:rm的操作是down所执行动作的一个子集。down是一个完整的环境拆除命令,它会停止并移除容器,同时还会移除网络。而rm只是一个清理工具,用于“打扫”那些已停止的容器,它不会影响正在运行的服务或项目的网络配置。- 场景化举例: 你使用
docker compose run运行了一次性的测试,但忘记了添加--rm参数。现在docker ps -a的输出中有一个已停止的容器 (myapp_web_run_1) 占着位置。此时运行docker compose rm会找到并移除这个以及其他所有属于该项目的已停止容器,而不会影响你正在运行的服务。
# 移除当前项目中所有已停止的容器
docker compose rm网络管理
本指南旨在为熟悉 Docker 基础的开发者和运维工程师提供一份关于 Docker Compose 网络管理的全面、深入的专家级技术文档。在容器化的世界中,网络是连接各个独立服务的命脉。理解并精通 Docker Compose 的网络机制,是构建安全、可扩展且易于维护的多容器应用的关键。
本报告将从 Docker Compose 自动创建的默认网络入手,深入剖析其核心——服务发现的工作原理。随后,我们将探讨为何以及如何使用自定义网络来构建更复杂的应用拓扑,实现服务间的安全隔离。最后,报告将涵盖一系列高级网络技术,包括连接外部网络、配置网络别名、分配静态 IP 地址,并对 ports 和 expose 这两个常用但易混淆的指令进行终极澄清。通过本指南,读者将能掌握从简单开发环境到复杂生产部署所需的全部网络知识。
第 1 节: Compose 网络的基础:默认网络
当用户在没有任何特定网络配置的情况下运行 docker-compose up 时,Compose 会在幕后执行一系列智能的网络设置。这个“开箱即用”的功能是 Compose 广受欢迎的重要原因之一,它为开发者提供了无缝的本地开发体验。本节将揭示这一自动化过程的内部工作原理。
1.1 自动网络供给:docker-compose up 的魔法
当一个不包含顶级 networks 配置块的 docker-compose.yml 文件被执行时,Docker Compose 会自动为该应用创建一个专属的默认网络。
- 网络类型与命名: 这个自动创建的网络是一个用户定义的桥接(bridge)网络,而非旧版的 Docker 默认
bridge网络(即docker0接口)。这是一个至关重要的区别,因为它意味着该网络拥有内置的 DNS 服务发现功能。网络的名称遵循一个标准模式:<项目名>_default。其中,“项目名”默认是包含docker-compose.yml文件的目录名。例如,如果项目位于一个名为myapp的目录中,Compose 创建的网络将被命名为myapp_default。这个项目名可以通过命令行参数--project-name或环境变量COMPOSE_PROJECT_NAME进行覆盖。 - 自动服务连接: Compose 文件中定义的所有服务都会被自动连接到这个
myapp_default网络中。
这种默认行为是 Docker Compose 设计哲学的一部分,旨在提供一个“恰好能用”的开发环境。它抽象并解决了 Docker 早期版本中网络通信的痛点。在旧的 Docker bridge 网络中,容器间若要通过名称通信,必须使用现已废弃的 --link 标志,或者硬编码 IP 地址,这使得配置非常繁琐和脆弱。Docker 后来引入了“用户定义网络”来解决此问题,提供了原生的 DNS 解析能力。Docker Compose 的默认行为正是这一最佳实践的自动化实现:为每个应用栈创建一个隔离的、具备服务发现功能的用户定义网络。这种设计极大地简化了开发流程,但也可能让其工作原理显得像一个“黑盒子”。本指南的目的就是揭开这个盒子的面纱,让使用者知其然,更知其所以然。
1.2 核心机制:通过嵌入式 DNS 实现服务发现
Docker Compose 默认网络最强大的特性是其自动化的服务发现机制。这使得一个容器可以像访问普通主机名一样,通过服务名直接访问另一个容器。
- 嵌入式 DNS 服务器: 这一功能由 Docker 引擎内置的 DNS 服务器驱动。在每个容器的网络命名空间内,都有一个 DNS 服务器运行在
$127.0.0.11$这个特殊的 IP 地址上。当容器启动时,Docker 会自动配置其/etc/resolv.conf文件,将nameserver指向$127.0.0.11$8。 - 解析过程: 当一个容器(例如
web服务)尝试解析一个主机名(例如db)时,DNS 查询会首先被发送到这个嵌入式的 DNS 服务器。服务器会检查该名称是否匹配同一网络中的某个服务名。如果匹配,它会将该服务名解析为对应容器的内部 IP 地址(例如$172.x.0.3$) 并返回。如果查询的名称在当前 Docker 网络中不存在,嵌入式 DNS 服务器会将该查询请求转发给 Docker 主机上配置的常规 DNS 服务器(例如公司的 DNS 或公共 DNS 如$8.8.8.8$) 。 - DNS 优先级与隔离: 这个解析流程是分级的,首先查询内部 Docker DNS,然后才查询外部主机 DNS。这意味着在
docker-compose.yml中定义的服务名,其解析优先级高于任何公共或内部 DNS 服务器上的同名记录。这种机制会产生一种“DNS 屏蔽”效应:如果你在 Compose 文件中定义了一个名为api的服务,那么栈内其他容器尝试访问 api.yourcompany.com 的请求可能会失败或被错误地解析到内部的api容器,因为解析器在匹配到api后就会停止,不再向外查询。
这种看似会引发问题的行为,实际上是确保环境可移植性和隔离性的关键特性。它保证了应用内的微服务总是能直接相互通信,而不会受到外部网络环境的干扰,有效防止了例如开发环境的容器意外连接到生产环境数据库这类“环境泄漏”问题。它确保了应用栈的“封闭性”,是实现可靠、可复现部署环境的基石。
1.3 实践案例:一个简单的 Web 和数据库应用
让我们通过一个具体的例子来展示默认网络的工作方式。假设我们有一个包含 Flask Web 应用和 PostgreSQL 数据库的项目。
网络拓扑结构描述:
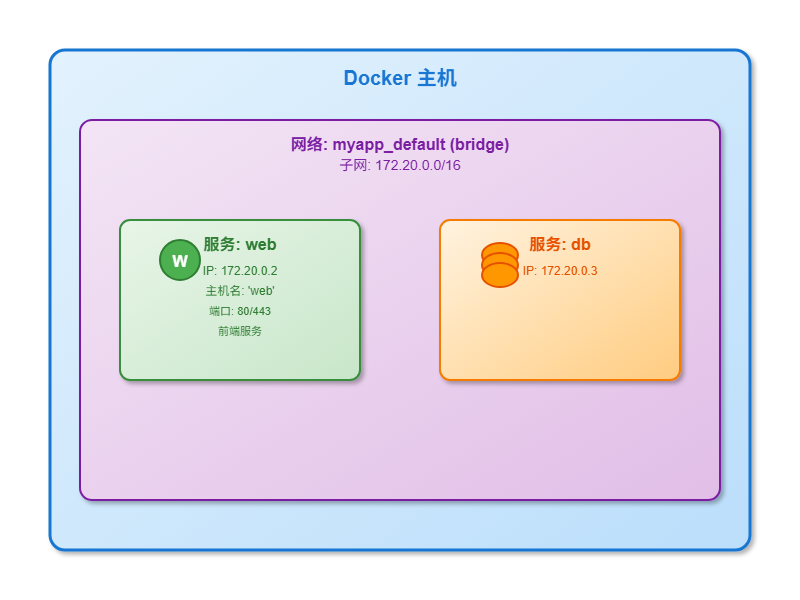
docker-compose.yml 文件示例:
# docker-compose.yml
version: '3.8'
services:
web:
build:./web-app
ports:
- "8000:5000"
environment:
# 主机名 'db' 将由 Docker 的内部 DNS 解析
DATABASE_URL: "postgresql://user:password@db:5432/myapp"
depends_on:
- db
db:
image: postgres:14-alpine
environment:
POSTGRES_USER: user
POSTGRES_PASSWORD: password
POSTGRES_DB: myapp
volumes:
- postgres_data:/var/lib/postgresql/data
volumes:
postgres_data:在这个配置中,web 服务通过连接字符串 postgresql://user:password@db:5432/myapp 来连接数据库。这里的关键点是主机名 db。它不是一个公共 DNS 记录,也不是在 /etc/hosts 文件中定义的条目。它是在 docker-compose.yml 中定义的服务名,由 Docker 的嵌入式 DNS 服务器在运行时动态解析为 db 容器的内部 IP 地址。这完美地展示了 Docker Compose 默认网络所带来的便利性和强大功能。
第 2 节: 使用自定义网络构建安全与可扩展的架构
虽然默认网络对于开发和简单应用非常方便,但随着应用复杂度的增加,我们需要更精细的控制能力。自定义网络允许我们超越默认的“扁平”拓扑,设计出更安全、更模块化的网络架构。
2.1 “为何”需要:超越默认网络的隔离与控制
转向自定义网络主要基于以下三个核心驱动力:
- 通过隔离增强安全性:
默认网络将所有服务连接在一起,形成一个“大杂院”,其中每个容器都可以与任何其他容器通信。这在安全上是不理想的,因为它违背了最小权限原则。在一个典型的三层应用(例如,Nginx 代理、后端 API、数据库)中,代理服务器完全没有必要直接访问数据库。在默认的扁平网络中,这种访问路径是存在的,这无疑增加了攻击面。一旦代理容器被攻破,攻击者就有了通往数据库的直接网络路径。通过创建独立的
frontend 和 backend 网络,我们可以从网络层面强制执行架构边界:将代理只放在 frontend 网络,数据库只放在 backend 网络,而后端 API 服务则同时连接这两个网络,充当一个受控的网关。这种做法将 docker-compose.yml 文件从一个简单的服务启动器,转变为一份声明式的网络安全策略,是实现容器化应用深度防御的有效手段。
- 连接外部或预先存在的资源:
应用常常需要与在当前 Compose 项目生命周期之外管理网络资源进行交互,例如连接到一个由运维团队维护的、为多个项目提供服务的共享反向代理网络。默认网络是项目私有的,无法实现这种跨项目的连接。
- 高级 IP 地址管理 (IPAM):
在复杂的企业环境中,可能需要避免 IP 地址冲突或与现有的网络策略集成。自定义网络允许对 IP 地址进行精细化管理,包括定义特定的子网、网关和 IP 地址范围,这些都是默认网络的自动配置无法提供的。
2.2 “如何”实现:定义和附加自定义网络
在 Docker Compose 中实现自定义网络拓扑遵循一个清晰的两步流程:在顶层定义网络,然后在服务层附加网络。
- 顶层
networks元素: 这是在整个 Compose 项目范围内定义网络的地方。它是一个映射(map),其中每个键都是网络在 Compose 文件内部的逻辑名称。每个网络定义下都可以包含多个配置选项,例如:driver: 指定网络驱动,如bridge(单主机,默认)或overlay(用于多主机 Swarm 集群)。ipam: 用于配置 IP 地址管理。external: 标记此网络为外部网络。name: 为 Docker 网络指定一个自定义的、不受项目名影响的名称。
- 服务级
networks元素: 这个块位于每个服务定义内部,用于将该服务附加到一个或多个已在顶层定义的网络上。它可以是一个简单的网络名称列表,也可以是一个映射,以便进行更高级的配置,如设置网络别名或静态 IP。
这种将网络“定义”与“附加”分离的声明式结构,不仅仅是语法上的要求。它促使开发者将网络视为应用架构的一等公民,与卷(volumes)和配置(configs)同等重要。这种分离使得创建复杂的多对多网络拓扑变得直观且易于理解。一个网络可以被多个服务引用,一个服务也可以连接到多个网络。最终,docker-compose.yml 文件本身就成为了一份自文档化的架构图,任何工程师都可以通过阅读 networks 部分,快速理解应用的数据流和隔离边界 2。
2.3 案例研究:具有隔离前后端网络的多层架构
让我们通过一个案例来展示如何利用自定义网络实现安全隔离。
网络拓扑结构描述:
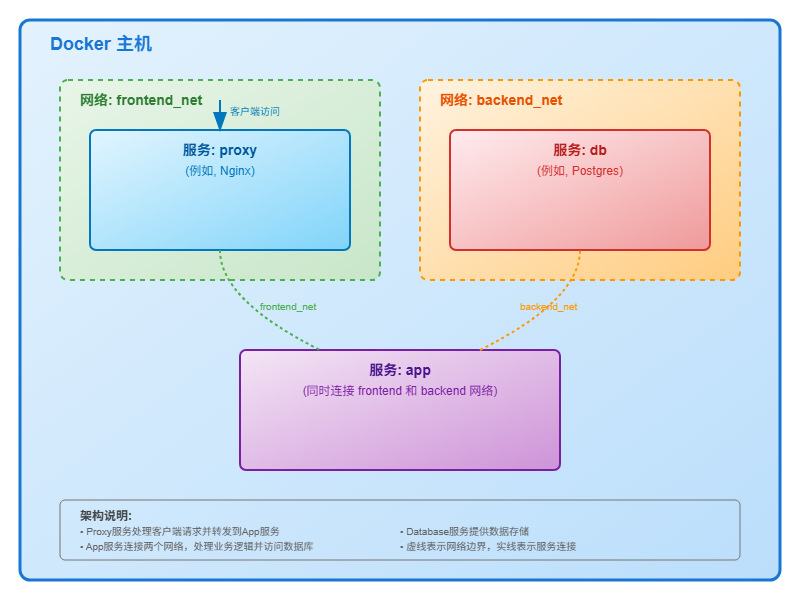
docker-compose.yml 文件示例:
version: '3.8'
services:
proxy:
image: nginx:alpine
ports:
- "80:80"
networks:
- frontend_net # 只连接到前端网络
app:
build:./app
networks:
- frontend_net # 可被 proxy 访问
- backend_net # 可以访问数据库
environment:
DATABASE_HOST: db # 在后端网络中解析 'db'
db:
image: postgres:14-alpine
environment:
#... 环境变量...
networks:
- backend_net # 被隔离在后端网络
networks:
frontend_net:
driver: bridge
backend_net:
driver: bridge
internal: true # 额外安全层:禁止此网络访问外部在这个配置中,我们定义了两个网络:frontend_net 和 backend_net。
proxy服务只连接到frontend_net,因此它只能看到app服务。db服务只连接到backend_net,它对proxy服务完全不可见。app服务是唯一同时连接到两个网络的服务,它充当了前后端之间的桥梁。
此外,我们在 backend_net 的定义中加入了 internal: true。这是一个强大的安全特性,它会阻止该网络内的所有容器发起任何到外部世界的连接(例如,下载软件包或调用外部 API),从而为包含敏感数据(如数据库)的网络增加了一层额外的保护。这个案例清晰地展示了如何通过自定义网络将架构意图转化为具体的、可执行的网络策略。
第 3 节: 高级网络技术与模式
掌握了自定义网络的基础后,我们可以探索一些更高级的模式来解决现实世界中的复杂问题,例如跨项目通信和与外部系统的集成。
3.1 连接栈:接入已存在的外部网络
在微服务架构中,通常会有一些被多个应用栈共享的基础设施,最典型的例子就是一个处理所有入站流量和 TLS 终端的中央反向代理(如 Traefik 或 Nginx)。要让我们的应用服务能够被这个外部代理发现,就需要将其连接到代理所在的网络。
- 实现方式: 要连接到一个并非由当前
docker-compose.yml文件创建的网络,必须在顶层的networks块中定义它,并设置external: true。当设置了此标志后,Compose 不会尝试创建该网络,而是会去查找一个具有指定名称的已存在网络。如果该网络不存在,Compose 将会报错并中止。
代码示例:
# 步骤 1: 在 Docker 主机上手动创建共享网络
# $ docker network create shared_proxy_net
# 步骤 2: 在你的应用的 docker-compose.yml 中引用它
version: '3.8'
services:
my_app:
image: my_app:latest
networks:
- default # 用于应用内部组件间的通信
- proxy_net # 用于连接到外部代理
networks:
default:
# Compose 会创建名为 <project>_default 的网络
proxy_net:
name: shared_proxy_net # 指定要连接的 Docker 网络的确切名称
external: true # 声明这是一个外部网络说明: 这个模式是构建解耦的、可独立部署的微服务系统的基础。在上面的例子中,proxy_net 是在 Compose 文件内部使用的逻辑名称,而 name: shared_proxy_net 则精确地指向了 Docker 主机上实际存在的网络名称。这使得应用栈可以轻松地“挂载”到共享的基础设施上。
3.2 管理身份:使用网络别名实现灵活性
网络别名(Aliases)为服务在特定网络中提供了额外的、可解析的主机名。这是一个非常实用的功能,主要用于以下场景:
- 兼容遗留应用: 遗留应用可能在其配置文件中硬编码了对某个服务的访问主机名(例如,它期望连接到
database,而你的 Compose 服务名是project-db)。 - 避免名称冲突: 当多个不同的 Compose 项目连接到同一个外部网络时,它们可能都包含一个名为
db的服务。别名可以为每个服务在该共享网络中提供一个唯一的、可识别的名称。
- 实现方式: 别名在服务级的
networks映射中为特定网络进行定义。一个服务可以在一个网络上拥有多个别名,也可以在不同的网络上拥有不同的别名。
代码示例:
version: '3.8'
services:
web:
image: my-legacy-webapp
networks:
- app_net
# 此应用的连接字符串可能硬编码为 "database"
db:
image: postgres:14
networks:
app_net:
aliases:
- database # 为遗留应用提供别名
- postgres # 提供另一个通用别名
networks:
app_net:说明: 在这个例子中,web 容器可以通过三个主机名访问数据库服务:db(默认的服务名)、database(别名)和 postgres(另一个别名)。值得注意的是,服务名本身总是会被自动添加为默认的网络别名。
别名机制实际上是一个强大的解耦层。它使得部署配置(docker-compose.yml)能够适应应用代码的期望,而不是反过来要求修改应用代码来适应部署环境。这种解耦极大地提升了应用镜像和 Compose 文件的可移植性与可重用性。你可以在不同的环境中使用不同的服务命名约定来部署同一个应用镜像,只需在相应的 Compose 文件中调整网络别名即可,无需触碰任何应用代码。
3.3 实现可预测性:使用 IPAM 分配静态 IP
虽然服务发现是 Docker 推荐的最佳实践,但在某些特殊场景下,静态 IP 地址仍然是必需的,例如:
- 与只认 IP 地址的外部工具或防火墙规则集成。
- 某些无法与 Docker DNS 良好协作的遗留监控代理。
- 实现方式: 静态 IP 只能在配置了
ipam(IP Address Management)的自定义网络上分配。
ipam 块在顶层网络定义中配置,它需要一个 config 列表,其中可以指定网络的 subnet(子网),以及可选的 gateway(网关)和 ip_range(用于动态分配的 IP 范围)。然后,通过在服务级的
networks 映射中使用 ipv4_address(或 ipv6_address)键来为服务分配静态 IP。
代码示例:
version: '3.8'
services:
monitoring_agent:
image: legacy-agent
networks:
custom_net:
ipv4_address: 10.10.0.10 # 为需要固定 IP 的服务分配静态地址
app:
image: my-app
networks:
- custom_net # 此服务将从 ip_range 中获取一个动态 IP
networks:
custom_net:
driver: bridge
ipam:
config:
- subnet: 10.10.0.0/16
ip_range: 10.10.1.0/24 # 为动态分配的 IP 定义范围
gateway: 10.10.0.1讨论: 必须强调,这是一个高级功能,对于 99% 的用例,依赖服务发现是更优的选择。硬编码 IP 地址会降低应用的可移植性和水平扩展的灵活性。应将其视为一种在外部条件强制要求时才使用的工具,而不是一个默认的设计模式。
第 4 节: 揭秘容器可访问性:ports vs. expose
在 Docker 的世界里,ports 和 expose 是两个最容易引起混淆的概念。本节将提供一个明确、权威且实用的解释,以彻底消除这一困惑。
4.1 ports:打开通往主机的网关
- 目的: 其唯一目的是将 Docker 主机上的一个端口映射到容器内部的一个端口。
- 功能: 它在主机上创建一条端口转发规则(通常通过
iptables实现)。任何发送到主机IP:主机端口的网络流量都会被转发到容器IP:容器端口。 - 可访问性: 它使得容器内的服务可以从 Docker 主机外部被访问,例如从你的浏览器,或局域网内的其他机器。
- 语法:
ports: - "主机端口:容器端口",例如ports: - "8080:80"。
4.2 expose:记录内部端点
- 目的: 其主要目的是声明并记录容器内的应用程序打算监听哪些端口。
- 功能: 它本质上是元数据(metadata)。它不会将端口发布到主机,也不会使其可从外部访问。它的作用是为操作人员或其他工具(例如
docker run -P命令,该命令会自动发布所有被expose的端口到主机的随机端口上)提供信息,告知哪些端口是值得关注的。 - 可访问性: 它本身不启用任何网络通信。
- 语法:
expose: - "容器端口",例如expose: - "3306"36。
4.3 潜规则:在自定义网络上的直接通信
这是最关键、也最常被忽略的一点:在同一个用户定义的桥接网络上,容器之间可以在任何端口上直接通信,无论该端口是否在 ports 或 expose 中列出。
既然容器间通信本来就是通畅的,那么 ports 和 expose 的真正作用就不是启用通信,而是控制和声明可访问性。
- 使用
ports是一个明确的动作,意在打破网络隔离,将服务暴露给主机。这应该只用于应用的入口点,例如主 Web 服务器或反向代理。 - 对内部服务(如数据库、缓存)使用
expose(或者什么都不写),则是一种意图的声明:“此服务仅供内部使用”。
一个架构良好的 docker-compose.yml 文件会非常吝啬地使用 ports。发布到主机的端口越少,应用的攻击面就越小。因此,ports 与 expose 的选择,本质上是一个安全设计决策。最佳实践的规则是:“只为你的对外入口服务使用 ports。对于所有其他后端服务,依赖内部网络进行通信,不要使用 ports。”
表 4.1: ports vs. expose - 对比分析
下表提供了一个快速、权威的参考,以帮助开发者在实际工作中做出正确选择。
| 特性 |
|
|
| 主要目的 | 将服务发布到主机,以供外部访问。 | 记录服务在内部监听的端口。 |
| 可访问性 | 可从主机和外部网络访问。 | 仅可被同一 Docker 网络中的其他服务访问。 |
| 功能 | 在主机上主动创建端口转发规则。 | 充当容器/镜像的元数据,不创建网络规则。 |
| 常见用例 | Web 服务器、反向代理、需要从外部调用的 API。 | 数据库、缓存、内部微服务。 |
| 语法示例 |
|
|
| 容器间通信是否需要它? | 否 | 否(在用户定义网络上) |
第 5 节: 结论与生产最佳实践
本指南系统地探讨了 Docker Compose 的网络管理,从便捷的默认网络到用于构建复杂、安全应用架构的自定义网络,再到一系列高级配置模式。掌握这些知识,是任何希望在生产环境中有效运用容器技术的工程师的必备技能。
为了在实际项目中设计出健壮、安全且可维护的网络配置,以下是一份总结性的最佳实践清单:
- 始终使用自定义网络: 除非是进行最简单的单服务测试,否则应避免使用默认网络。通过在
docker-compose.yml中显式定义网络,可以使你的应用架构更加清晰和自文档化。 - 优先使用服务发现: 尽可能依赖 Docker 内置的 DNS 机制进行服务间通信。只有在与外部系统集成且别无选择时,才考虑使用静态 IP 地址。这能确保你的应用具有更好的可移植性和可扩展性。
- 贯彻最小权限原则: 利用多个网络来隔离服务的不同层次。一个服务应该只被连接到它绝对需要通信的网络上。例如,将前端、后端和数据库分别置于不同的网络中,只在必要时建立连接。
- 最小化攻击面: 仅在应用的入口服务(通常是反向代理或 Web 服务器)上使用
ports指令来发布端口。所有其他的后端服务都不应该将端口发布到主机,以减少潜在的安全风险。 - 使用外部网络共享服务: 对于跨多个应用栈共享的基础设施(如中央反向代理),应将其部署在独立的网络中,并让其他应用通过
external: true的方式连接进来,以实现关注点分离。 - 利用别名增强可移植性: 当应用代码中存在硬编码的主机名时,使用网络别名来适配,而不是修改代码。这可以解耦应用逻辑与部署配置,提高应用的可重用性。
- 选择正确的网络驱动: 对于绝大多数在单台主机上运行的 Docker Compose 应用,
bridge驱动是正确的选择。只有在需要部署到多主机的 Docker Swarm 集群时,才应使用overlay驱动。
遵循这些原则,你将能够自信地为你的容器化应用设计出既高效又安全的网络解决方案,为应用的稳定运行和未来扩展奠定坚实的基础。
数据持久化策略
第一部分:容器化架构中数据持久化的必要性
1.1 容器的短暂性:一项基本原则
要理解数据持久化的必要性,首先必须掌握 Docker 容器的一个核心设计原则:短暂性(Ephemerality)。当一个容器启动时,它基于其镜像的只读层构建文件系统,并在顶部添加一个薄薄的可写层,通常被称为“暂存空间” 。容器内发生的所有文件系统变更,例如创建新文件、修改现有文件或删除文件,都发生在这个可写层中。
这个可写层的生命周期与容器实例的生命周期是严格绑定的。一旦容器被停止并移除,其可写层以及其中包含的所有数据都将永久丢失。我们可以通过一个简单的实验来证明这一点:
- 启动一个 Alpine Linux 容器,并在其中创建一个文件:
docker run --name test-ephemeral -it alpine sh
/ # echo "hello world" > /data.txt
/ # cat /data.txt
hello world
/ # exit- 现在,移除这个容器:
docker rm test-ephemeral- 从同一个
alpine镜像启动一个新容器,并尝试查找之前创建的文件:
docker run --name new-container -it alpine sh
/ # cat /data.txt
cat: can't open '/data.txt': No such file or directory实验结果明确表明,数据随容器的移除而消失。然而,将这种短暂性仅仅视为一个“问题”或“缺陷”是片面的。更深层次的理解是,短暂性是实现不可变基础设施(Immutable Infrastructure)这一强大范式的一个关键特性,而非一个设计缺陷。
这种设计理念将容器视为可任意处置和替换的单元。因为容器本身是无状态的,所以可以轻松地进行水平扩展、实现故障自愈和进行可预测的部署。这种架构的强大之处正在于其无状态性。因此,数据持久化所面临的挑战,并非“修复”容器的短暂性,而是如何在一个无状态的计算环境中,战略性地管理有状态应用的数据。持久化机制(如卷)正是 Docker 官方提供的、用于连接无状态容器世界与有状态数据世界的桥梁。
1.2 数据持久化的业务与技术驱动因素
在理解了容器的短暂性是其核心架构的一部分之后,我们便能更好地认识到为何需要一个明确的数据持久化策略。对于众多关键应用而言,缺乏持久化将使其无法正常运作。
- 有状态应用 (Stateful Applications): 许多核心业务应用本质上是有状态的。例如,数据库(如 PostgreSQL、MySQL)、内容管理系统(CMS)、以及需要维护会话数据的缓存服务。这些应用的功能完全依赖于数据的连续性和一致性。如果数据库在容器重启后数据丢失,整个应用栈将彻底崩溃。
- 可复现性与一致性 (Reproducibility and Consistency): 在开发和测试周期中,能够精确复现一个应用在特定时间点的状态至关重要。如果没有持久化数据,每次启动新容器都会得到一个“干净”但无用的环境,这使得调试和复现生产环境中的问题变得异常困难。
- 可扩展性与高可用性 (Scalability and High Availability): 对于有状态服务,实现高可用性和水平扩展的唯一途径是让多个容器实例能够访问一个共享的、持久化的数据存储。例如,一个Web应用可以轻松地扩展到10个实例,但前提是这10个实例都能读写同一个数据库,而这个数据库的数据必须独立于任何单个容器的生命周期。
- 备份与灾难恢复 (Backup and Disaster Recovery): 这是数据持久化最关键的业务驱动因素之一。只有当数据存储在容器外部时,才能被纳入常规的备份和灾难恢复流程中。存储在容器可写层内的数据无法被可靠地备份,一旦发生主机故障或意外删除,将导致灾难性的数据丢失。
第二部分:核心持久化机制:详细对比分析
Docker Compose 提供了两种核心的数据持久化机制:绑定挂载(Bind Mounts)和命名卷(Named Volumes)。它们在架构、管理方式和适用场景上存在根本性差异。
2.1 绑定挂载:主机与容器的直接链接
定义与机制
绑定挂载是一种将主机文件系统上的一个文件或目录直接映射到容器内指定路径的机制。这种映射是双向且实时的。当使用绑定挂载时,容器内目标路径的原有内容(如果镜像中存在)会被主机上的文件或目录所“遮蔽”(obscure)。这意味着容器内进程看到的、并与之交互的,实际上是主机上的文件系统实体。
语法与配置 (docker-compose.yml)
Docker Compose 提供了两种语法来定义绑定挂载:
- 短语法 (Short Syntax): 这是最常见和简洁的格式,使用冒号分隔的字符串
HOST_PATH:CONTAINER_PATH:ACCESS_MODE。HOST_PATH: 主机上的路径,可以是绝对路径(如/srv/app/config)、相对路径(如./app)或用户主目录路径(如~/logs)。CONTAINER_PATH: 容器内的绝对路径。ACCESS_MODE(可选): 访问模式,最常用的是ro,表示只读(read-only)。
services:
web:
image: nginx:alpine
volumes:
-./nginx.conf:/etc/nginx/nginx.conf:ro # 挂载配置文件(只读)
-./src:/usr/share/nginx/html # 挂载应用代码- 长语法 (Long Syntax): 这种语法更明确,可读性更强,并提供了更多配置选项。通常被认为是更佳实践,因为它能避免短语法的一些歧义。
services:
web:
image: nginx:alpine
volumes:
- type: bind
source:./nginx.conf
target: /etc/nginx/nginx.conf
read_only: true优点
绑定挂载最显著的优点在于其为开发者带来的便利性。主要体现在以下方面:
- 实时代码同步: 在开发环境中,将本地的源代码目录挂载到容器中,可以让开发者在IDE中修改代码后,无需重新构建镜像就能立即在运行的容器中看到效果。这极大地加速了开发和调试的迭代周期。
- 主机文件交互: 方便地将主机上的配置文件注入容器,或将容器产生的日志文件导出到主机上进行分析和归档。
缺点与关键风险
尽管在开发中很方便,但绑定挂载也带来了一系列严重的问题,使其在生产环境中通常被视为不良实践。
- 可移植性差: 绑定挂载在
docker-compose.yml文件中硬编码了主机的目录结构。这意味着同一个配置文件无法在另一台目录结构不同的机器上直接运行,严重破坏了 Docker “构建一次,随处运行”的核心理念。 - 安全风险: 这是最严重的风险。绑定挂载给予容器内的进程直接读写主机文件系统的能力。如果配置不当(例如,挂载了敏感的系统目录),或者容器内的应用存在漏洞,攻击者可能利用这一点来修改甚至删除主机上的关键文件,从而实现容器逃逸,对整个宿主机造成威胁。
- 性能问题: 对于涉及大量小文件读写的I/O密集型应用,绑定挂载可能会引入性能开销。尤其是在 Docker Desktop (Windows/macOS) 环境下,由于文件系统虚拟化的差异,其性能通常劣于命名卷 。
深度解析:权限的泥潭
绑定挂载最棘手、最常见的问题是文件权限冲突。这个问题不仅仅是简单的配置错误,而是暴露了以容器为中心和以主机为中心的安全模型之间的根本性阻抗失配(impedance mismatch)。
这个问题的核心在于用户ID(UID)和组ID(GID)的不匹配。例如,一个在容器内以非root用户(如
node,UID为1000)运行的进程,当它通过绑定挂载写入文件时,在主机上创建的文件的所有者将是UID 1000。如果主机上的开发者用户的UID恰好也是1000,一切似乎正常。但如果开发者的UID是1001,或者容器进程以root(UID 0)身份运行,那么开发者将无法编辑由容器创建的文件,反之亦然。这导致了一个极其脆弱和令人沮丧的开发循环。
这个问题迫使开发者采取一些常见但存在隐患的变通方法:
chmod 777: 在主机上对挂载的目录执行chmod -R 777,给予所有用户读写执行权限。这是一种严重的安全反模式,完全破坏了系统的权限控制体系,绝不应在任何严肃的环境中使用。chown: 在主机上预先chown目录,使其所有者与容器内进程的UID/GID匹配。这种方法很脆弱,因为它要求开发者预先知道容器内部的UID/GID,并且在更换镜像或环境时需要重新配置。- 使用
PUID/PGID环境变量: 一些设计良好的镜像(如linuxserver.io系列)允许通过环境变量PUID和PGID来指定容器内进程运行的UID和GID。这是一个很好的解决方案,但它依赖于镜像的主动支持,并非通用标准。
这个权限问题的深度和复杂性,是为什么即使在开发环境中,对于需要由容器写入的数据(如数据库文件、用户上传内容),也强烈建议避免使用绑定挂载,转而采用命名卷。
2.2 命名卷:Docker 托管的持久化方案
定义与架构
命名卷是 Docker 官方推荐的、用于持久化容器生成数据的首选机制。它是一种由 Docker 引擎完全管理的存储抽象。这意味着 Docker 负责卷的创建、生命周期管理和数据存储,将其与主机的核心功能和目录结构解耦。
在物理上,命名卷的数据存储在主机文件系统的一个特定区域,在典型的 Linux 系统上是 /var/lib/docker/volumes/。这个位置由 Docker 管理,用户通常不应直接操作此目录下的文件。
语法与配置 (docker-compose.yml)
使用命名卷通常需要两步声明:
- 在
docker-compose.yml的顶层volumes块中定义卷的名称。 - 在需要使用该卷的服务的
volumes列表中引用它。
version: '3.8'
services:
database:
image: postgres:15-alpine
volumes:
# 将名为 'db-data' 的卷挂载到容器的 '/var/lib/postgresql/data' 路径
- db-data:/var/lib/postgresql/data
# 在顶层声明命名卷
volumes:
db-data:
driver: local # 指定使用本地驱动,这是默认选项顶层 volumes 块还支持更高级的配置,例如:
driver: 指定卷驱动。除了默认的local驱动,还可以使用第三方插件驱动,如nfs,以将数据存储在网络文件系统上。external: true: 用于连接到一个已经存在、且由外部(非 Compose)管理的卷。
优点
命名卷的设计解决了绑定挂载的几乎所有缺点,使其成为处理持久化数据的理想选择。
- 可移植性与解耦: 这是命名卷最大的优势。由于卷的定义和管理与主机的文件系统路径无关,包含命名卷的
docker-compose.yml文件是完全可移植的,可以在任何安装了 Docker 的机器上无缝运行。 - 简化的管理: 命名卷可以通过 Docker CLI (
docker volume命令) 进行统一、跨平台的管理,如创建、查看、删除和清理,操作非常便捷。 - 更高的安全性: 数据被隔离在 Docker 管理的目录中,与主机的用户目录和核心系统文件分离,有效降低了被非 Docker 进程意外修改或访问的风险,减小了攻击面。
- 更优的性能: 对于数据库等I/O密集型应用,命名卷通常能提供比绑定挂载更好的性能。因为卷的I/O操作可以绕过容器存储驱动的联合文件系统(Union File System),直接写入主机文件系统,减少了抽象层的开销。
- 自动数据填充: 这是一个非常实用的特性。当你将一个空的命名卷挂载到容器内一个非空的目录时(例如,PostgreSQL镜像中包含默认配置文件的
/var/lib/postgresql/data目录),Docker 会自动将该目录中的内容复制到命名卷中。这对于初始化数据库或使用应用的默认配置非常方便。
缺点与局限性
命名卷最常被提及的“缺点”是其数据在主机上不易直接访问。然而,将此视为一个纯粹的缺点是一种误解。
这种“不便”实际上是一种旨在保护数据完整性的刻意设计选择。
通过将数据存储在特定的、非用户常规工作区的目录中,Docker 鼓励开发者和管理员通过应用程序或指定的管理工具来与数据交互,而不是直接在文件系统层面随意修改可能导致数据库损坏的底层文件。这种抽象层是一种重要的安全和完整性保障。
当确实需要与卷内数据进行交互时(例如备份或调试),存在明确且正确的“Docker原生”方法,而不是直接去修改 /var/lib/docker/volumes/ 目录:
- 检查卷的物理位置: 使用
docker volume inspect <volume_name>命令。输出的 JSON 中会包含Mountpoint字段,它显示了该卷在主机上的确切物理路径。这为需要进行底层操作(如系统级备份)的管理员提供了入口。
$ docker volume inspect myapp_db-data- 使用临时工具容器: 这是更推荐、更安全的方法。可以启动一个临时的、轻量级的容器(如
alpine),将目标命名卷挂载到其中,然后在该容器内运行各种工具(如ls,tar,rsync)来检查、备份或迁移数据。
# 运行一个临时容器,挂载 db-data 卷,并列出其内容
docker run --rm -it -v myapp_db-data:/dbdata alpine ls -l /dbdata2.3 对比分析表
为了直观地总结和对比这两种机制,下表从多个维度进行了详细梳理。
| 属性 | 绑定挂载 (Bind Mounts) | 命名卷 (Named Volumes) |
| 定义 | 主机文件/目录到容器的直接映射。 | 由 Docker 引擎管理的存储,与主机文件系统抽象分离。 |
| 管理方 | 由主机用户/系统管理员作为标准文件/目录进行管理。 | 由 Docker 引擎通过 Docker API 和 CLI 进行管理。 |
| 主机位置 | 用户定义的任意路径 (例如 | Docker 管理的特定目录 (例如 |
| 可移植性 | 低。与主机的目录结构紧密耦合,配置文件不可移植。 | 高。独立于主机文件系统,可在任何 Docker 主机间移植。 |
| 性能 | 可能存在开销,尤其是在非原生文件系统(如 Docker Desktop)上处理大量I/O时。 | 针对I/O密集型工作负载进行了优化,性能通常更优。 |
| 安全性 | 较低。将主机文件系统暴露给容器,存在未授权访问和修改的风险。 | 较高。数据与主机进程隔离,减少了攻击面。 |
| 权限处理 | 脆弱。极易在主机和容器之间引发复杂的 UID/GID 不匹配问题。 | 健壮。权限通常由 Docker 引擎无缝处理,问题较少。 |
|
|
|
|
|
|
|
|
| CLI 管理 | 无 (使用标准操作系统命令如 | 完整的 |
| 初始状态处理 | 遮蔽容器目标路径中的任何现有内容。 | 若卷为空,则用容器目标路径中的内容填充卷。 |
| 主要适用场景 | 开发环境:同步源代码、注入配置文件、访问日志。 | 生产环境:持久化所有有状态应用数据(数据库、上传文件等)。 |
第三部分:实践应用与管理
理论知识需要通过实践来巩固。本节将展示一个典型的多服务应用场景,并介绍管理持久化数据的命令行工具。
3.1 场景:采用混合持久化策略的多服务应用
以下是一个常见的Web应用栈的 docker-compose.yml 文件示例,该应用由一个 Python (Flask) Web服务和一个 PostgreSQL 数据库组成。这个配置完美地展示了如何在开发环境中结合使用绑定挂载和命名卷,以发挥各自的优势。
- Web 服务 (
web): 使用绑定挂载来挂载app目录。这使得开发者可以在本地修改 Python 代码,而Flask的开发服务器会自动重新加载,实现了“热重载”,极大地提高了开发效率。 - 数据库服务 (
db): 使用命名卷postgres-data来存储 PostgreSQL 的数据。这确保了即使db容器被删除和重建(例如,在升级镜像版本时),数据库中的所有表和数据都将保持不变。
# 使用现代的 Compose 规范
version: '3.8'
services:
# Web 应用服务
web:
build:./app # 假设在./app 目录下存在一个 Dockerfile
ports:
- "5000:5000" # 暴露 Web 服务的端口
volumes:
# 在开发环境中使用绑定挂载。
# 将本地的 './app' 目录映射到容器内的 '/app' 目录。
# 这使得代码的实时重载成为可能。
- type: bind
source:./app
target: /app
# 依赖于数据库服务,并等待其进入健康状态
depends_on:
db:
condition: service_healthy
environment:
# 通过环境变量将数据库连接信息传递给应用
- DATABASE_URL=postgresql://user:password@db:5432/mydatabase
# 数据库服务
db:
image: postgres:15-alpine
environment:
POSTGRES_USER: user
POSTGRES_PASSWORD: password
POSTGRES_DB: mydatabase
volumes:
# 使用命名卷进行持久化数据库存储。
# 'postgres-data' 是命名卷的名称。
# '/var/lib/postgresql/data' 是 PostgreSQL 在容器内部存储数据的标准路径。
- type: volume
source: postgres-data
target: /var/lib/postgresql/data
healthcheck:
# 定义健康检查,以确保数据库服务已准备好接受连接
test:
interval: 10s
timeout: 5s
retries: 5
# 顶层 volumes 声明块
volumes:
# 定义命名卷。Docker 将会创建并管理它。
postgres-data:
driver: local # 指定使用默认的本地驱动3.2 使用 Docker CLI 管理卷的生命周期
作为系统管理员,掌握 docker volume 系列命令对于管理持久化数据至关重要。这些命令提供了一个完整的工具集来控制命名卷的整个生命周期。
- 创建卷: docker volume create my-volume
虽然 docker-compose up 会自动创建 docker-compose.yml 中定义的卷,但有时需要手动预先创建一个卷,例如,在迁移数据或应用外部管理脚本时。
- 列出卷: docker volume ls
此命令会列出主机上存在的所有 Docker 卷,包括由 Compose 创建的卷(通常以 projectname_volumename 的格式命名)和手动创建的卷。这对于了解磁盘空间占用情况和审计现有卷非常有用。
- 检查卷: docker volume inspect postgres-data
这是一个极其重要的调试和管理命令。它以 JSON 格式返回卷的详细元数据,包括其驱动、标签以及在主机上的物理挂载点 (Mountpoint)。
- 删除卷: docker volume rm my-volume
用于删除一个或多个卷。需要注意的是,如果一个卷当前正被任何容器(即使是已停止的容器)使用,Docker 将拒绝删除该卷,以防止数据丢失。必须先移除使用该卷的容器,才能删除卷。
- 清理卷: docker volume prune
这是一个关键的维护命令。它会扫描并删除所有未被任何容器使用的“悬空”(dangling)卷。定期运行此命令可以回收被废弃卷占用的磁盘空间,保持系统整洁。
第四部分:战略建议与最佳实践
基于以上分析,我们可以为不同的环境制定清晰的数据持久化策略,并遵循一系列通用最佳实践来确保数据的安全性和持久性。
4.1 开发环境策略
核心建议:采用混合持久化策略。
- 代码使用绑定挂载: 将应用程序的源代码目录通过绑定挂载映射到容器中。这是为了利用其快速反馈的特性,实现代码热重载,从而最大化开发效率。
- 数据使用命名卷: 对于所有有状态的后端服务,如数据库、消息队列、缓存等,应始终使用命名卷。这样做有三个主要好处:
- 它能精确模拟生产环境的数据管理方式。
- 确保在开发过程中频繁重建应用容器时,后端服务的数据不会丢失。
- 彻底避免了因容器写入数据而引发的绑定挂载权限问题。
4.2 生产环境策略
核心建议:独占性地使用命名卷。
在生产环境中,绑定挂载应被视为一种不可接受的风险。其缺点——缺乏可移植性、依赖主机环境、存在严重安全隐患——使其完全不适用于要求稳定性、安全性和可重复性的生产部署。
进阶策略:使用卷驱动 (Volume Drivers)
对于成熟的生产环境,尤其是涉及多主机集群(如 Docker Swarm 或 Kubernetes)的场景,应超越默认的 local 卷驱动。通过配置第三方卷驱动,可以将命名卷的数据后端指向共享存储,例如:
- NFS: 将数据存储在网络文件系统上,允许多个主机上的容器共享同一个卷。
- 云存储 (AWS EBS, Azure Disk, GCP Persistent Disk): 将卷数据存储在云提供商的高性能块存储上,这为实现高可用性、跨可用区容灾以及与云平台集成的快照备份功能奠定了基础。
4.3 通用数据持久性与安全最佳实践
无论在哪种环境中,以下原则都应被遵守,以构建一个真正健壮和安全的数据管理体系。
深刻认知:持久化不等于备份
这是一个新手极易陷入的误区:认为使用了卷就等于数据安全了。卷仅仅保证了数据在容器被移除后依然存在于主机上,它不能防止以下情况:
- 应用程序逻辑错误导致的数据损坏。
- 用户或进程在卷内意外执行了
rm -rf /。 - 主机磁盘故障或整个物理机丢失。
因此,必须制定一个独立于持久化机制的、健壮的备份策略。一个常见的模式是:定期运行一个专用的备份容器,该容器以只读方式挂载目标数据卷,同时通过绑定挂载连接到一个用于存放备份文件的临时目录,然后将数据(例如,通过 pg_dump)压缩并推送到远程存储(如 S3、FTP服务器等)。
安全加固
- 以非 Root 用户运行: 在 Dockerfile 中始终使用
USER指令,指定一个非特权用户来运行容器内的应用进程。这是纵深防御的关键一层,即使应用被攻破,也能限制攻击者在容器内的权限。 - 只读根文件系统: 在可能的情况下,将容器的根文件系统设置为只读(在 Compose 中使用
read_only: true),然后仅将需要写入的特定路径挂载为卷。这极大地限制了攻击者的活动空间。
镜像与构建卫生
- 使用多阶段构建 (Multi-stage Builds): 通过多阶段构建,可以生成一个不包含任何编译工具、开发依赖和中间产物的、极其精简的生产镜像。这显著减小了镜像体积和潜在的攻击面。
- 选择最小化基础镜像: 尽可能从一个最小化的基础镜像(如
alpine)开始构建。更少的软件包意味着更少的潜在漏洞。
虽然这些镜像构建的最佳实践不直接作用于卷,但它们创造了一个更安全的容器运行环境,从而间接保护了存储在卷中的宝贵数据的安全。
多环境配置:从开发到生产
第一部分:环境特定配置的必要性
在任何严谨的软件开发生命周期(SDLC)中,试图使用单一的 docker-compose.yml 文件来管理所有环境(开发、测试、生产)是一种典型的反模式。这种做法不仅会导致配置臃肿、难以维护,更会引入严重的安全风险。每个环境都有其独特且常常相互冲突的需求,理解并满足这些需求是构建健壮、可扩展应用的第一步。
开发环境:追求速度与即时反馈
开发环境的核心目标是最大化工程师的生产力。这意味着配置必须围绕快速迭代和高效调试来设计。
- 热重载(Hot-Reloading): 为了实现代码修改后的即时反馈,开发环境必须使用卷(volumes)将本地源代码目录挂载到容器内部。当开发者在本地IDE中保存文件时,容器内的应用程序(如Nodemon、Webpack Dev Server)能够立即检测到变更并自动重启或重新加载,从而避免了耗时的镜像重建过程。这是支撑高效“内部开发循环”(inner development loop)的基石。
- 调试能力: 必须通过
ports映射暴露应用程序的调试端口。例如,为Node.js应用暴露V8 Inspector端口,或为Python应用暴露debugpy端口,使开发者能将IDE的调试器附加到容器进程上,进行断点设置、变量检查等深度调试操作。 - 辅助工具: 开发环境通常包含生产环境绝不需要的服务。这可能是一个Webpack开发服务器,用于提供前端静态资源并支持热模块替换(HMR);也可能是一个数据库管理工具(如Adminer或phpMyAdmin),方便开发者直接查看和操作数据库状态。这些服务应被定义在仅用于开发环境的Compose配置中。
- 日志详细度: 日志级别应设置为最高(如
DEBUG),以便在开发过程中捕捉到尽可能详细的诊断信息,帮助快速定位问题。
测试环境:要求一致性与隔离性
测试环境(尤其是在CI/CD流水线中)的目标是创建一个干净、可复现的平台,以确保自动化测试(单元测试、集成测试、端到端测试)的可靠性。
- 可复现性: 测试必须在每次运行时都基于完全相同的环境。这意味着CI流水线应始终执行
docker compose build命令,从源代码构建一个全新的、干净的镜像。这确保了测试是针对特定代码提交的精确快照进行的,消除了因依赖本地缓存镜像而导致的不确定性。 - 环境隔离: 测试应该是无状态且幂等的。每次测试运行都应在一个隔离的环境中启动,并在结束后彻底销毁。例如,集成测试不应连接一个共享的开发数据库,而应为每次测试运行启动一个专用的、临时的数据库容器。测试结束后,该容器及其所有数据(卷)都应被销毁,以保证下一次测试不受之前状态的影响。
- 服务启动顺序: 复杂的应用通常包含多个相互依赖的服务。测试环境必须精确控制服务的启动顺序。例如,在测试服务启动之前,必须确保其依赖的数据库服务已经不仅启动,而且完全准备好接受连接。这可以通过
depends_on指令结合condition: service_healthy实现,后者依赖于对依赖服务进行健康检查(healthcheck)的配置。 - 专用配置: 测试环境应使用其专有的配置文件,如
docker-compose.test.yml和.env.test,来定义测试专用的数据库名、用户凭据、API端点等。
生产环境:强制要求安全性、性能与弹性
生产环境是直接面向最终用户的,其配置必须以稳定性、安全性和效率为最高准则。任何开发中的便利性都必须让位于生产级的严谨性。
- 不可变性(Immutability): 这是生产环境的黄金法则。绝对禁止在生产环境中使用卷挂载源代码。应用程序代码必须被“烘焙”到一个经过版本控制的、从安全容器镜像仓库(如Docker Hub, GHCR, Artifactory)中拉取的不可变镜像中。这种做法确保了部署的一致性和可追溯性,并从根本上杜绝了在生产容器中进行“热修复”等危险操作。
- 安全性: 遵循最小权限原则。只暴露必要的端口(通常是80/443端口,由一个反向代理如Nginx或Traefik管理)。敏感信息(如数据库密码、API密钥)绝不能通过
.env文件或环境变量硬编码在Compose文件中进行管理。必须使用更安全的机制,如Docker Secrets或由CI/CD平台注入的秘密 。 - 性能优化: 为容器配置明确的资源限制(
deploy.resources.limits),如CPU和内存,以防止单个服务耗尽主机资源,保证多租户环境下的服务质量(QoS)。应选择经过优化的、体积更小的生产级基础镜像(例如,使用node:20-alpine而非node:20),以减少攻击面和部署时间。 - 弹性与韧性: 必须配置重启策略(如
restart: always或unless-stopped),以确保服务在意外崩溃或服务器重启后能够自动恢复,从而最大限度地减少停机时间。
从根本上看,多环境配置的核心挑战在于有效管理“开发便利性”与“生产严谨性”之间的内在张力。一个成功的策略不仅仅是使用不同的文件,而是为每个环境建立一套独特的配置哲学,并选择合适的技术工具来实现这套哲学。测试环境则充当了两者之间的桥梁:它采用与生产相同的构建流程(创建不可变镜像),但在一个类似开发的临时、隔离环境中运行。未能认识到这种哲学层面的差异,是导致配置管理混乱的根本原因。
第二部分:核心技术之多文件管理配置
使用多个Compose文件进行分层和覆盖,是实现多环境配置最基础也是最强大的技术。它允许我们将共享的基础配置与特定于环境的配置分离开来。
-f 标志:显式组合配置文件
docker compose 命令的 -f (或 --file) 标志允许你指定一个或多个Compose文件。Compose会按照命令行中给出的顺序依次读取这些文件,并将它们合并成一个最终的配置模型。
例如,为一个生产环境启动服务,命令可能如下所示:
docker compose -f compose.yaml -f compose.prod.yaml up -d这个命令指示Compose首先加载 compose.yaml 作为基础配置,然后加载 compose.prod.yaml,用其内容覆盖或扩展基础配置。文件的顺序至关重要,因为后加载的文件具有更高的优先级。
compose.override.yml 约定:为本地开发提供自动化便利
Docker Compose有一个内置的约定,极大地简化了本地开发环境的配置。当你运行 docker compose up 时,它会自动在当前目录查找一个名为 compose.yaml(或 docker-compose.yml)的文件,以及一个名为 compose.override.yml(或 docker-compose.override.yml)的文件。如果两个文件都存在,Compose会自动将它们合并,其效果等同于执行
docker compose -f compose.yaml -f compose.override.yml up。
这个约定是为本地开发环境量身定制的最佳实践。compose.yaml 应该包含项目的核心、共享的服务定义,而 compose.override.yml 则用于定义仅适用于开发者本地的、个性化的配置。
至关重要的建议:务必将 compose.override.yml 添加到项目的 .gitignore 文件中。这使得每个开发者都可以根据自己的需求(例如,因为端口冲突而修改主机端口映射、挂载个人工具目录等)自由修改此文件,而不会将其提交到版本控制中,从而避免了不必要的配置冲突和混乱。
深度解析:合并与覆盖规则
要精通多文件策略,必须深入理解Compose的合并规则。这些规则定义了不同类型的配置项在合并过程中的行为。
- 单值键(Single-Value Keys): 对于像
image,command,entrypoint,mem_limit这样的键,其值会被替换。后加载文件中的值会完全覆盖先加载文件中的值。compose.yaml:
services:
web:
image: myapp:1.0
command: start-server-
compose.override.yml:
services:
web:
image: myapp:dev
command: nodemon-
- 合并结果:
image变为myapp:dev,command变为nodemon。
- 合并结果:
- 多值列表(Multi-Value Lists): 对于像
ports,expose,dns,external_links这样的键,其值会被追加合并(Concatenated)。Compose会将所有文件中的列表项合并成一个更长的列表。compose.yaml:
services:
web:
ports:
- "80:80"-
compose.override.yml:
services:
web:
ports:
- "9229:9229" # 调试端口-
- 合并结果:
ports列表将包含"80:80"和"9229:9229"两项。
- 合并结果:
- 字典(Mappings): 对于像
environment,labels,build.args这样的键,其值会以字典的方式合并。如果字典中的某个键(例如,一个环境变量名)在多个文件中都存在,则后加载文件中的值会覆盖前者。新的键值对则会被添加进来。compose.yaml:
services:
web:
environment:
NODE_ENV: production
API_URL: https://api.example.com-
compose.override.yml:
services:
web:
environment:
NODE_ENV: development
DEBUG: "true"-
- 合并结果:
environment将包含NODE_ENV: development(被覆盖),API_URL:https://api.example.com(被保留),以及DEBUG: "true"(被添加)。
- 合并结果:
- 特殊情况 -
volumes:volumes表面上是一个列表,但它的合并行为更像一个字典。合并的唯一键是卷在容器内的挂载路径(targetpath)。如果多个文件中的条目试图挂载到同一个容器路径,后加载的条目会获胜并替换前者 9。compose.yaml:
services:
web:
volumes:
-./config/prod.json:/app/config.json-
compose.override.yml:
services:
web:
volumes:
-./src:/app/src # 新增挂载
-./config/dev.json:/app/config.json # 覆盖挂载-
- 合并结果:
volumes将包含./src:/app/src和./config/dev.json:/app/config.json。原有的prod.json挂载被覆盖。
- 合并结果:
- 路径解析: 这是一个常见的陷阱。所有在Compose文件中使用的相对路径(例如
build的context或volumes的源路径)都是相对于使用-f指定的第一个Compose文件所在的目录进行解析的 9。这意味着,即使你的覆盖文件在不同的子目录中,它里面的相对路径也必须相对于基础文件来写。你可以使用
docker compose config 命令来查看最终合并和解析后的配置,以避免路径相关的问题。
compose.override.yml 的自动加载机制并非偶然,而是Docker Compose设计哲学的一部分,旨在清晰地分离共享的项目级配置 (compose.yaml) 和个性化的开发者环境配置 (compose.override.yml)。前者是团队协作的基石,应保持稳定和一致;后者是个人效率的助推器,应灵活多变且不受版本控制。-f 标志则是为不同环境(如prod, test)定义全局性、结构性差异的正式工具。理解这种“共享 vs. 个性化”和“隐式 vs. 显式”的二元结构,是掌握多文件策略精髓的关键。
第三部分:核心技术之继承与组合 (extends vs. include)
除了文件层面的合并,Docker Compose还提供了服务定义层面的重用机制,以保持配置的“DRY”(Don't Repeat Yourself)原则。这些机制经历了从 extends 到 include 的演进,反映了Compose从简单项目工具到复杂应用编排器的转变。
传统方式:extends
extends 关键字允许一个服务从另一个服务继承配置。这对于在多个服务间共享通用配置块(如日志驱动、环境变量)非常有用。
你可以继承同一文件中的服务,也可以继承另一个文件中的服务。
# common-config.yml
services:
base-service:
image: alpine:latest
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "3"
# compose.yaml
services:
service-a:
extends:
file: common-config.yml
service: base-service
command: echo "I am service A"
service-b:
extends:
service: service-a # 继承同一文件中的 service-a
environment:
- GREETING=hello然而,extends 存在一些非常重要的局限性,这些局限性常常让使用者感到困惑和意外:
- 不被继承的键:
volumes_from,depends_on,links等涉及服务间依赖关系的键不会被继承。这是一个刻意的设计,旨在避免隐式依赖,强制开发者在当前文件中明确声明服务间的关系,从而提高配置的可读性和可维护性。 - 端口映射:
ports也不会被继承,以防止无意的端口冲突。
结论: extends 适用于简单的、位于同一项目中的配置片段共享。但由于其局限性,它不适合用于构建复杂的、跨团队或跨项目的模块化应用。
现代方式:include (Compose v2.20+)
include 是一个在较新版本Compose中引入的顶级关键字,它是解决模块化和配置重用问题的更现代、更强大的方案。
include 与 extends 的根本区别在于其设计理念:
extends是属性级别的继承(白盒继承):它只是将一个服务的部分属性复制到另一个服务中。include是应用级别的组合(黑盒组合):它将一个完整的、独立的Compose文件作为一个“组件”或“黑盒”导入到当前的应用模型中。
#./components/monitoring/compose.yaml
services:
prometheus:
image: prom/prometheus:v2.45.0
volumes:
-./prometheus.yml:/etc/prometheus/prometheus.yml # 相对路径
grafana:
image: grafana/grafana:9.5.3
depends_on:
- prometheus
#./compose.yaml
include:
-./components/monitoring/compose.yaml
services:
my-app:
image: my-app:latest
# my-app 可以通过网络与 prometheus 和 grafana 通信include 的核心优势在于:
- 解决了路径解析问题:
include最重要的特性是,它会在被包含文件自身的目录上下文中解析其内部的相对路径。在上面的例子中,
monitoring/compose.yaml 里的 ./prometheus.yml 会被正确解析为 components/monitoring/prometheus.yml。这使得它成为在大型单体仓库(Monorepo)中组织代码的理想选择,不同团队可以在各自的目录中维护自己的Compose文件,而其他团队可以轻松地将其作为依赖项包含进来,无需担心路径错乱。
- 强制模块化: 默认情况下,如果被包含的文件与主文件定义了同名的服务,Compose会报错。这强制了清晰的模块边界。
- 支持覆盖: 如果确实需要微调被包含的服务,
include提供了两种覆盖机制:一种是在include块内部指定一个本地覆盖文件,另一种是使用全局的compose.override.yml文件对最终合并后的模型进行覆盖。
extends 与 include 的演进,深刻反映了软件架构模式的变迁。在简单的应用中,开发者可能只想让几个服务共享相同的日志配置,extends 足以胜任。但在一个由多个自治团队协作维护的大型单体仓库中,Billing 团队需要依赖 Auth 团队提供的认证服务,但他们不关心也不应该关心 Auth 服务的内部实现细节(如它依赖哪个数据库,构建上下文在哪里)。他们需要的仅仅是“导入一个能工作的认证服务”。extends 和多文件合并都因路径解析问题而难以胜任此场景。include 正是为了这种“将其他应用作为构建块来消费”的用例而生,它尊重组件的封装性和独立性,是实现真正配置即代码(Configuration as Code)模块化的关键。
第四部分:核心技术之环境变量动态配置
将配置值从静态的YAML文件中解耦出来,是实现配置灵活性和安全性的关键一步。环境变量为此提供了强大的机制,但其复杂的优先级规则也常常成为混淆的来源。
.env 文件:你的本地配置中心
Docker Compose会自动加载项目根目录下名为 .env 的文件。这个文件中的变量有两个主要用途:
- 用于Compose文件插值(Interpolation): 在
compose.yaml文件中,你可以使用${VARIABLE}的语法来引用.env文件中定义的变量。 - 直接注入容器: 如果在
environment部分只提供变量名而不提供值,Compose会将.env文件或宿主机shell中的同名变量值传递给容器。
最佳实践: 使用 .env 文件来管理非敏感的、随环境变化的配置。例如,用于本地开发的镜像标签、主机端口、日志级别等。
#.env file
TAG=develop
WEB_PORT=8080
LOG_LEVEL=debug
POSTGRES_USER=myuser
POSTGRES_PASSWORD=mysecretpassword # 警告:仅限本地开发!变量插值:让Compose文件动起来
Compose文件支持变量插值,使得配置可以动态生成。语法主要有两种:
${VARIABLE}: 如果VARIABLE未设置,则替换为空字符串。${VARIABLE:-default}: 如果VARIABLE未设置,则使用default值。
# compose.yaml
services:
web:
image: my-company/webapp:${TAG:-latest} # 使用.env 中的 TAG,如果未设置则默认为 latest
ports:
- "${WEB_PORT:-8000}:80" # 使用.env 中的 WEB_PORT
environment:
- LOG_LEVEL=${LOG_LEVEL}权威的优先级层次结构
环境变量的优先级是Docker Compose中最复杂、最容易出错的部分之一。必须严格区分两种不同的优先级规则:一种是用于Compose文件插值的变量优先级,另一种是最终注入到容器内部的环境变量优先级。
1. 容器内环境变量的最终值优先级
当多个来源都定义了同一个环境变量时,容器内最终生效的值由以下规则决定,优先级从高到低:
| 优先级 | 来源 | 示例 |
| 1 (最高) |
|
|
| 2 |
|
|
| 3 |
|
|
| 4 |
|
|
| 5 (最低) | 镜像的 |
|
2. Compose文件插值变量的来源优先级
决定 ${VARIABLE} 在 compose.yaml 中被替换成何值的优先级规则如下,优先级从高到低:
- 宿主机Shell中设置的环境变量: 在运行
docker compose命令的终端中直接导出的变量。 - 使用
--env-file标志指定的文件:docker compose --env-file.env.prod up - 项目目录下的
.env文件: 默认行为。
这种双重角色的复杂性意味着,一个不清晰的策略很容易导致不可预测的行为。例如,一个开发者在Shell中设置了 TAG=feature-xyz,而项目中的 .env 文件里写的是 TAG=develop。当他运行 docker compose config 时,他会看到镜像是 myapp:feature-xyz,因为Shell变量在插值时有更高的优先级。这可能会让他感到困惑。
因此,必须建立一个清晰的心智模型,将Compose的执行过程分为两个阶段来思考:
- 解析阶段: Compose读取YAML文件,并根据插值优先级规则(Shell >
--env-file>.env)用变量替换所有${...}占位符,生成一个最终的、静态的配置模型。 - 运行阶段: Compose根据这个静态模型创建容器,并根据容器内变量优先级规则(run -e > environment > env_file > Dockerfile ENV)来确定注入到容器中的环境变量。
掌握这个两阶段模型,是调试所有与环境变量相关的配置问题的关键。
第五部分:推荐的综合策略:整合所有技术
理论知识必须转化为可执行的策略。以下是一套经过实战检验的、综合了上述所有技术的推荐工作流,旨在实现开发、测试和生产环境的清晰分离与高效管理。
基础:compose.yaml
这是项目的“单一事实来源”(Single Source of Truth),定义了应用所需的所有服务、网络和命名卷。它应该是环境无关的,所有可能变化的配置项都应使用变量插值(${...})来表示。这个文件被所有环境共享,并提交到版本控制。
# compose.yaml
version: '3.9'
services:
api:
image: my-company/api:${TAG:-latest}
build:
context:./api
dockerfile: Dockerfile
environment:
- DATABASE_URL=postgresql://${POSTGRES_USER}:${POSTGRES_PASSWORD}@db:5432/${POSTGRES_DB}
- LOG_LEVEL=${LOG_LEVEL:-info}
networks:
- app-net
db:
image: postgres:15-alpine
environment:
- POSTGRES_USER=${POSTGRES_USER}
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
- POSTGRES_DB=${POSTGRES_DB}
volumes:
- db-data:/var/lib/postgresql/data
networks:
- app-net
networks:
app-net:
driver: bridge
volumes:
db-data:开发环境:compose.override.yml + .env
此组合旨在提供极致的开发便利性。
compose.override.yml(gitignored): 用于定义结构性和行为性的开发时覆盖。- 挂载源代码以实现热重载。
- 暴露调试和应用端口。
- 覆盖
command以启动开发服务器(如nodemon)。 - 添加开发专用服务(如
adminer)。
# compose.override.yml (添加到.gitignore)
services:
api:
ports:
- "${API_PORT:-3000}:3000"
- "9229:9229" # Node.js 调试端口
volumes:
-./api/src:/app/src # 挂载源代码
command: npm run dev # 使用开发命令
depends_on:
db:
condition: service_healthy # 开发时也最好等待DB就绪
db:
ports:
- "${DB_PORT:-5432}:5432" # 暴露数据库端口以便本地工具连接
healthcheck:
test:
interval: 5s
timeout: 5s
retries: 5.env(提供.env.example并 gitignore.env): 用于定义值的覆盖。
#.env
TAG=latest
API_PORT=3000
DB_PORT=5432
# 数据库凭据 (仅限本地)
POSTGRES_USER=devuser
POSTGRES_PASSWORD=devsecret
POSTGRES_DB=devdb
LOG_LEVEL=debug- 启动命令:
docker compose up --build。简单、直接,Compose会自动处理所有文件的加载和合并。
测试环境 (CI/CD):compose.test.yml + 注入的变量
此环境追求的是自动化和可复现性。
compose.test.yml: 一个由CI脚本显式调用的覆盖文件。- 定义一个
test-runner服务,它依赖于应用服务。 - 可能会覆盖数据库服务的
command或entrypoint,以运行一个初始化脚本来创建测试模式(schema)。 - 不暴露任何端口,因为CI环境是无头(headless)的。
- 定义一个
# compose.test.yml
services:
api:
environment:
- LOG_LEVEL=error # 测试时减少日志噪音
test-runner:
image: my-company/api:${TAG:-latest} # 使用与被测服务相同的镜像
build:
context:./api
command: npm test # 运行测试命令
environment:
- DATABASE_URL=postgresql://${POSTGRES_USER}:${POSTGRES_PASSWORD}@db:5432/${POSTGRES_DB}
networks:
- app-net
depends_on:
api:
condition: service_started # 或 service_healthy
db:
condition: service_healthy- 配置: 所有配置(包括测试数据库凭据)都应由CI平台(如GitHub Actions, GitLab CI)作为环境变量注入到CI Runner中,绝不从
.env文件读取。这确保了配置的集中管理和安全性。 - 启动命令:
docker compose -f compose.yaml -f compose.test.yml run --build -T --rm test-runner2。--build: 确保每次都构建新镜像。--rm: 测试完成后自动删除test-runner容器。-T: 禁用伪TTY分配,适用于非交互式CI环境。
生产环境:CI/CD 流水线 + 安全的秘密管理
生产部署的核心原则是零信任和自动化。不信任部署主机的本地状态,唯一可信的来源是容器镜像仓库和CI/CD平台的秘密存储。
- 工作流:
- CI流水线在代码合并到主分支后触发。
- 流水线构建Docker镜像,用唯一的标识符(如Git Commit SHA)进行标记,并推送到一个私有的、安全的容器镜像仓库。
- 流水线通过SSH或云服务商的API连接到生产服务器,并执行一个部署脚本。
- 配置与部署:
- 部署脚本首先拉取指定标签的镜像:
docker compose pull。 - 然后使用
docker compose -f compose.yaml -f compose.prod.yml up -d启动服务。compose.prod.yml文件用于添加生产专有的配置:
- 部署脚本首先拉取指定标签的镜像:
# compose.prod.yml
services:
api:
restart: always # 确保服务在崩溃后自动重启
deploy:
resources:
limits:
cpus: '1'
memory: '1G'
# 不暴露任何端口,由外部的反向代理处理
db:
restart: always
# 不暴露端口-
- 关键:秘密管理: 这是生产部署中最重要的一环。
- 方法一(推荐):通过CI/CD注入环境变量。部署命令的前缀应包含从CI平台的秘密存储(如GitHub Actions Secrets)中获取的敏感变量。
- 关键:秘密管理: 这是生产部署中最重要的一环。
# 在GitHub Actions工作流中
- name: Deploy to production
run: |
export TAG=${{ github.sha }}
export POSTGRES_USER=${{ secrets.PROD_POSTGRES_USER }}
export POSTGRES_PASSWORD=${{ secrets.PROD_POSTGRES_PASSWORD }}
export POSTGRES_DB=${{ secrets.PROD_POSTGRES_DB }}
docker compose -f compose.yaml -f compose.prod.yml up -d-
-
- 方法二(更安全):使用Docker Secrets。此方法避免将秘密作为环境变量暴露给容器内的所有进程,而是将它们作为只读文件挂载到容器的一个临时文件系统中(通常是
/run/secrets/)。
- 方法二(更安全):使用Docker Secrets。此方法避免将秘密作为环境变量暴露给容器内的所有进程,而是将它们作为只读文件挂载到容器的一个临时文件系统中(通常是
-
首先,修改 compose.yaml 以使用Docker Secrets:
# compose.yaml (修改后)
services:
api:
environment:
# 应用需要被修改为能从文件读取密码
- DATABASE_URL=postgresql://${POSTGRES_USER}@db:5432/${POSTGRES_DB}
secrets:
- db_password # 授权此服务访问该秘密
secrets:
db_password:
file:./db_password.txt # 秘密内容来自这个文件然后,在CI/CD部署脚本中,在启动Compose之前,先从秘密存储中获取秘密并写入到文件中:
# 在部署脚本中
echo "${{ secrets.PROD_POSTGRES_PASSWORD }}" >./db_password.txt
docker compose -f compose.yaml -f compose.prod.yml up -d
rm./db_password.txt # 立即删除临时文件这种方式提供了更强的隔离性,是处理高度敏感数据的首选。
这个从开发到生产的策略,实际上建立了一条“配置提升管道”。配置随着环境的演进,变得越来越严格、安全和不可变。开发环境高度灵活,但安全性低;测试环境半可变,代码被固化,但环境是临时的;生产环境完全不可变,代码和配置都来自受控、可审计的来源。这个流程通过工具强制执行纪律,有效地防止了开发阶段的宽松实践(如弱密码、开放的调试端口)“泄漏”到生产环境中,从而构筑了一道坚实的风险防线。
第六部分:比较分析与总结
为了帮助工程师在不同场景下快速做出明智的技术选型,并向团队或管理者清晰地阐述其决策依据,下表对本指南中讨论的各种配置管理技术进行了总结和比较。
配置管理技术对比
| 技术 | 核心机制 | 主要应用场景 | 复杂度 | 灵活性 | 优点 | 缺点 | |
| 多文件 ( | 合并/覆盖整个文件 | 定义环境间的结构性差异(如添加测试服务、设置重启策略、端口映射)。 | 低 | 中 | 概念简单,易于理解;关注点分离清晰; | 文件过多时可能变得笨重;路径合并规则需要特别注意。 | |
| 继承/组合 ( | 重用/组合服务定义 |
| 中-高 | 高 | 促进配置重用; |
|
|
| 环境变量 ( | 在运行时注入值 | 配置具体的值(端口、标签、凭据、功能开关),避免修改YAML文件。是实现安全秘密管理和动态CI/CD的基础。 | 低 | 高 | 将配置与代码解耦;是安全处理生产秘密的唯一途径(通过注入而非 | 优先级规则复杂,易混淆;滥用会使最终配置模糊不清; |
|
| Docker Secrets ( | 将秘密作为文件挂载到容器 | 在生产环境中处理密码、API密钥等最高级别敏感数据的最安全方法。 | 高 | 低 | 秘密不作为环境变量暴露,安全性高;细粒度的访问控制;使用内存文件系统。 | 需要修改应用以支持从文件读取秘密;设置过程更复杂。 |
最终建议清单
- 基础先行: 使用
compose.yaml作为所有环境共享的基础配置。 - 开发优先: 使用
compose.override.yml(并加入.gitignore) 进行本地开发环境的个性化覆盖。 - 显式覆盖: 使用
-f标志和环境特定的文件(如compose.prod.yml,compose.test.yml)来定义结构性差异。 - 拥抱现代: 优先使用
include而非extends来实现配置的模块化和重用。 .env的边界: 仅将.env文件用于非敏感的本地开发配置。- 生产安全第一: 永远不要在生产环境中使用
.env文件。应通过安全的CI/CD平台注入环境变量,或最好使用原生的Docker Secrets机制。 - 文档化与简化: 清晰地文档化你项目中的变量优先级规则,并尽可能保持配置策略的简单和直观。当出现问题时,
docker compose config是你最好的朋友。
打造专业级 Docker Compose 文件
几乎每一位使用 Docker 的开发者都接触过 Docker Compose。它以其简洁的 docker-compose.yml 文件和 docker compose up 命令,极大地简化了多容器应用的定义和运行。然而,许多开发者对 Compose 的使用仅仅停留在“能用”的层面。一个能够工作的配置和一个专业的、生产级的配置之间,存在着巨大的鸿沟。
专业的 Compose 文件不仅仅是配置的堆砌,它关乎应用的弹性、安全性、CI/CD 流水线的顺畅度以及团队协作的效率。编写这样的文件,意味着你需要超越基础,深入理解其高级特性,并遵循行业沉淀下来的最佳实践。
本指南将带领你完成这一跃迁。我们将深入探讨 Docker Compose v2.x 中几个强大但常被忽视的高级特性:healthcheck、高级 depends_on、deploy.resources 和服务伸缩。更重要的是,我们将剖析每个特性和实践背后的“为什么”,因为理解其价值远比记住语法更重要。最后,我们将总结出一份详尽的最佳实践清单,助你将理论付诸实践。
第一部分:掌握高级 Compose 特性,构建健壮应用
高级特性是解决复杂问题的利器。它们能帮助我们处理服务依赖、资源竞争和启动顺序等在分布式应用中常见且棘手的问题。
超越“运行”:使用 healthcheck 确保服务就绪
一个常见的陷阱是,认为容器处于“running”状态就等同于其内部的应用已经准备好提供服务。事实并非如此。一个 Web 服务器可能仍在初始化,一个数据库可能刚刚启动但其引擎尚未接受连接。这种状态不一致是导致多服务应用启动失败的主要原因。
healthcheck 指令正是 Docker 提供的原生解决方案,它让我们能够向容器内部的应用提出一个关键问题:“你真的准备好工作了吗?”
解构 healthcheck 指令
healthcheck 允许你定义一个命令,Docker 会周期性地在容器内执行该命令来判断其健康状况。
表 1: healthcheck 指令选项
| 选项 | 目的 | 示例值 |
|
| 用于检查健康的命令。如果命令返回退出码 0,则认为容器健康。 | `` |
|
| 运行健康检查的间隔时间。 |
|
|
| 等待 |
|
|
| 将容器标记为 |
|
|
| 容器启动时的宽限期。在此期间,失败的健康检查不会计入重试次数。这给予了应用足够的启动时间。如果在此期间检查成功,容器将立即被标记为 |
|
实践案例:为 PostgreSQL 服务添加健康检查
让我们为一个 postgres 服务添加一个健壮的健康检查:
services:
db:
image: postgres:15-alpine
environment:
- POSTGRES_USER=${POSTGRES_USER}
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
healthcheck:
# 使用 PostgreSQL 官方工具检查服务是否就绪
test:
interval: 10s
timeout: 5s
retries: 5
start_period: 30s这里的 test 命令使用了 pg_isready,这是 PostgreSQL 自带的轻量级工具,专门用于检查数据库服务器是否准备好接受连接。相比于尝试建立一个完整的数据库连接,它非常高效,是健康检查的理想选择。我们使用了
CMD-SHELL 形式,这允许我们在命令中直接使用 ${POSTGRES_USER} 这样的环境变量。
健康检查命令的选择本身就是一种设计权衡。它反映了我们对“健康”的定义,需要在检查的准确性和开销之间找到平衡。
- 低开销,弱信号:像 `` 这样的命令只检查 TCP 端口是否开放。它的开销极低,但信号很弱——端口开放不代表应用进程没有卡死。
- 中等开销,强信号(推荐):应用自带的 ping 命令是最佳选择,如 PostgreSQL 的
pg_isready、MySQL 的mysqladmin ping、Redis 的redis-cli ping,以及 MongoDB 的mongosh --eval "db.adminCommand('ping')"。它们开销适中,且能确认应用进程真实存活并响应。 - 高开销,最强信号:对于 Web 服务,`` 能确认应用可以完整处理一个 HTTP 请求。这是最强的健康信号,但开销也最大。
因此,在设计健康检查时,需要根据服务的关键性和依赖关系,明智地选择最合适的检查命令。
精准编排启动顺序:depends_on 与 service_healthy
depends_on 是一个历史悠久但极易被误解的指令。它的经典用法仅仅控制容器的启动顺序,而不等待依赖的服务内部的应用准备就绪。这正是无数“数据库连接失败”错误的根源。
幸运的是,现代 Docker Compose 提供了扩展语法,彻底解决了这个问题。
services:
api:
build:.
depends_on:
db:
# 魔法在这里:等待 db 服务变为 healthy 状态
condition: service_healthycondition: service_healthy 这行代码将 depends_on 和 healthcheck 的状态联系了起来。现在,Compose 在启动 api 服务之前,会耐心等待,直到 db 服务的健康检查状态变为 healthy。
下面是一个完整的、可靠的示例,展示了 api 服务如何安全地等待 db 服务:
version: "3.9"
services:
api:
build:./api
ports:
- "8080:8080"
environment:
- DB_HOST=db
- DB_USER=${POSTGRES_USER}
- DB_PASSWORD=${POSTGRES_PASSWORD}
depends_on:
db:
condition: service_healthy
db:
image: postgres:15-alpine
volumes:
- postgres_data:/var/lib/postgresql/data
environment:
- POSTGRES_USER=${POSTGRES_USER}
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
healthcheck:
test:
interval: 10s
timeout: 5s
retries: 5
volumes:
postgres_data:这个模式不仅限于等待服务健康。depends_on 还支持 condition: service_completed_successfully,这使得在 Compose 中实现“初始化容器”(Init Container)模式成为可能——这在 Kubernetes 中是一种常见且强大的模式。
想象一个场景:在 Web 应用启动前,你需要运行数据库迁移。我们可以为此创建一个专门的服务:
services:
api:
#...
depends_on:
db:
condition: service_healthy
# 等待迁移任务成功完成后再启动
migrator:
condition: service_completed_successfully
migrator:
build:./migrator
# 确保它依赖于健康的数据库
depends_on:
db:
condition: service_healthy
# 迁移任务是一次性的,完成后应退出
command: ["./run-migrations.sh"]
db:
#... (与上例相同,包含 healthcheck)这个配置建立了一个清晰、声明式的执行流程:
- 启动
db服务。 - 等待
db的健康检查通过。 - 当
db健康后,同时启动api和migrator服务。 migrator服务依赖于健康的db,它会执行迁移脚本,成功后退出(退出码为 0)。api服务则会等待db健康 并且migrator成功完成。
通过这种方式,复杂的初始化逻辑(如数据库迁移、数据填充、配置检查)被封装在独立的、一次性的容器中,确保主应用在启动时拥有一个完全就绪的环境。这标志着 Compose 从一个简单的容器启动器,演变成一个能够编排简单、有状态工作流的强大工具。
驯服资源消耗:deploy.resources
在过去,为非 Swarm 模式下的容器设置资源限制是一个令人困惑的问题。旧版的 Compose 文件(v2.x)使用 mem_limit 等键,而 v3 文件格式将其替换为 deploy 键下的 resources,但最初的文档明确指出这只对 Docker Swarm 集群生效,docker-compose up 会忽略它。
这一历史遗留问题已经成为过去。在现代的 Docker Compose(即 docker compose CLI,而非旧的 docker-compose)中,deploy.resources 键已完全支持常规的、非 Swarm 的部署。
为什么这很重要? 在开发环境中设置资源限制,可以:
- 更精确地模拟生产环境的资源约束。
- 在开发早期就发现内存泄漏或低效的 CPU 使用。
- 确保应用在资源受限时能正常工作,避免“在我的机器上能跑”的典型问题。
如何实现?
你可以同时设置 reservations(为容器保留的最小资源)和 limits(容器能使用的最大资源)。
services:
api:
image: my-api:1.0
deploy:
resources:
# 保证至少有 0.25 个 CPU核心 和 256MB 内存
reservations:
cpus: '0.25'
memory: 256M
# 限制最多使用 0.5 个 CPU核心 和 512MB 内存
limits:
cpus: '0.5'
memory: 512Mdeploy.resources 在 docker compose up 中的普及,标志着 Compose 设计理念的一次重要转变。它不再仅仅是一个方便开发者的工具,而是演变为一个能够定义具有生产意图的应用栈的核心组件,有力地推动了开发与生产环境之间的一致性。过去,开发者需要为本地开发维护一套 docker-compose.yml,为生产环境维护另一套完全不同的配置(如 Kubernetes YAML),这极易导致配置漂移。现在,一个 compose.yml 文件就能定义应用的核心资源画像,使其在从开发到部署的整个生命周期中保持一致,极大地降低了维护成本,并赋予了开发者更强的生产环境意识。
横向扩展:伸缩无状态服务
在将应用部署到真正的集群(如 Kubernetes)之前,你可能想在本地测试其横向扩展能力。例如,验证负载均衡器能否正确发现所有新实例,或者确认你的应用是否真正无状态。
伸缩命令
使用现代的 docker compose 命令进行伸缩:
# 将 web 服务扩展到 3 个实例
docker compose up -d --scale web=3请注意,旧的 docker-compose scale 命令已被废弃。
关键前提
这是一个巨大的“陷阱”,必须注意。为了让服务能够被成功扩展,其在 docker-compose.yml 中的定义绝不能包含:
- 静态的
container_name:多个容器不能重名。 - 固定的主机端口映射(如
ports: - "8080:80"):多个容器不能绑定到同一个主机端口。
可伸缩服务的正确配置
你应该只暴露容器端口,让 Docker 自动为每个实例分配一个随机的主机端口。
services:
web:
image: nginx:1.21
# 只暴露容器端口 80,Docker 会将其映射到宿主机的随机端口
ports:
- "80"你可以通过 docker compose ps 查看每个实例被映射到了哪个主机端口。
Compose 中的伸缩功能,其核心价值并非用于生产环境的高可用部署(这应由 Kubernetes 等编排器负责),而是作为开发阶段的一个强大的
架构验证工具。它像一张石蕊试纸,能快速检验你的应用架构是否为分布式环境做好了准备。
- 检验无状态性:如果你将一个 API 服务从 1 个实例扩展到 3 个,用户的会话突然中断,这立刻就能证明该服务不是无状态的,它可能错误地将 session 数据存储在了容器本地。
- 验证服务发现与负载均衡:通过扩展,你可以验证前端的反向代理(如 HAProxy 或 Nginx)是否能通过 Docker 的内部 DNS 发现所有后端实例,并正确地分发流量。
- 测试连接鲁棒性:它能确保应用间的通信使用的是服务名(如 http://web),而不是硬编码的容器 IP,因为服务名会被 Docker 的 DNS 自动解析并负载均衡到所有可用实例上。
因此,应将 Compose 的伸缩功能视为开发流程中的一个重要环节,用以在代码进入 CI/CD 管道之前,提前发现和修复架构层面的问题。
第二部分:专业人士的 Docker Compose 最佳实践清单
遵循最佳实践是编写高质量、可维护、安全配置的关键。以下清单可作为你日常工作的参考。
[ ] 保持镜像精简:使用多阶段构建
- 为什么重要:更小的镜像意味着更快的拉取、推送速度,更少的存储占用,以及更小的安全攻击面(因为包含了更少的软件包和库)。多阶段构建(Multi-stage builds)允许你将构建环境(包含编译器、SDK、开发依赖)与最终的运行时环境(只包含运行应用所必需的文件)彻底分离。
- 如何实现:在你的
Dockerfile中使用多个FROM指令来定义不同的阶段。
# ---- 构建阶段 (Builder Stage) ----
# 使用包含完整 Go 工具链的镜像
FROM golang:1.20-alpine AS builder
WORKDIR /app
COPY..
# 编译应用,生成一个静态链接的二进制文件
RUN CGO_ENABLED=0 GOOS=linux go build -o /app/main.
# ---- 运行阶段 (Final Stage) ----
# 使用一个极简的、不包含任何内容的 scratch 镜像
FROM scratch
WORKDIR /
# 从构建阶段复制编译好的二进制文件
COPY --from=builder /app/main /main
# 设置容器启动时执行的命令
ENTRYPOINT ["/main"]这个例子中,最终镜像只包含一个单独的二进制文件,体积可能只有十几兆,而不是几百兆的 Go SDK。
[ ] 明确镜像版本:避免使用 latest 标签
- 为什么重要:使用
image: postgres:latest会导致构建的不可预测性。今天latest指向版本 15,明天可能就指向版本 16,这可能引入不兼容的变更。在团队协作中,不同成员本地的latest镜像也可能不同,从而引发经典的“在我机器上能跑”问题。明确版本号可以保证构建的确定性和可重复性。 - 如何实现:始终指定一个明确的版本标签。
# 糟糕的实践
image: postgres:latest
# 良好的实践
image: postgres:15.2-alpine一个更专业的建议是,固定到主版本或次版本,如 postgres:15-alpine。这样既能防止破坏性的主版本升级,又能自动获取该版本线上的安全补丁和次要更新,在稳定性和安全性之间取得了良好平衡。
[ ] 使用 .dockerignore:保持构建上下文干净
- 为什么重要:在执行
docker build时,Docker 客户端会将构建上下文(通常是.目录)中的所有文件发送给 Docker 守护进程。一个干净的上下文可以显著加快构建速度。更重要的是,.dockerignore可以防止敏感文件(如.git目录、.env文件、云服务凭证)被意外地复制到镜像中,从而避免严重的安全漏洞。 - 如何实现:在项目的根目录(与
docker-compose.yml同级)创建一个.dockerignore文件,其语法类似.gitignore。
# Git 目录
.git
.gitignore
# 依赖目录,应在容器内安装
node_modules
venv
vendor
# 本地配置文件和敏感信息
.env
*.env
.vscode
# 日志和临时文件
*.log
npm-debug.log*
# Docker 相关文件
Dockerfile
docker-compose.yml
```
**关键警告**:卷挂载(bind mounts)会绕过 `.dockerignore`。如果在 `docker-compose.yml` 中使用了 `volumes: -.:/app`,那么在容器运行时,你的整个本地目录都会被挂载进去,包括那些本应被忽略的文件。这是开发中热重载的常用技巧,但也非常容易引起混淆,务必确保在构建生产镜像时移除此类挂载 [30, 31]。[ ] 配置与代码分离:使用环境变量
- 为什么重要:将配置(如数据库密码、API 密钥、环境特定参数)硬编码到镜像中是严重的安全风险和反模式。外部化配置使得同一个镜像可以无缝地部署到开发、测试、生产等不同环境中,只需提供不同的配置即可。
- 如何实现:使用
.env文件和变量替换是最佳实践。Docker Compose 会自动加载项目根目录下的.env文件。
.env 文件 (此文件绝不应提交到 Git)
DB_HOST=db
DB_USER=myuser
DB_PASSWORD=supersecretdocker-compose.yml 文件
services:
api:
build:.
environment:
# 从.env 文件或 shell 环境变量中读取值
DATABASE_URL=postgres://${DB_USER}:${DB_PASSWORD}@${DB_HOST}:5432/mydb[ ] 为服务定义用户:不要以 root 用户运行
- 为什么重要:这是容器安全的基本原则。默认情况下,容器内的进程以
root用户身份运行。一旦应用被攻破,攻击者就获得了容器内的root权限,这大大增加了他们尝试攻击宿主机或其他容器的风险。以一个低权限的非root用户运行进程,是纵深防御策略中至关重要的一环。 - 如何实现:在
Dockerfile中创建专用的用户和组,并在最后使用USER指令切换过去。
# 创建一个系统用户和组,不创建家目录,禁止登录
RUN addgroup -S appgroup && adduser -S appuser -G appgroup
WORKDIR /app
COPY --chown=appuser:appgroup..
#... 其他指令...
# 切换到非 root 用户
USER appuser
CMD ["./my-application"]为确保安全,创建的用户 UID 最好大于 10000,以避免与宿主机上某些系统用户的 UID 冲突。
[ ] 编写清晰的注释:解释“为什么”
- 为什么重要:随着应用的复杂化,
docker-compose.yml文件也会变得越来越长,越来越难懂。注释是向你的团队成员(以及未来的你)解释配置背后意图的最佳方式。为什么要暴露这个端口?这个环境变量的作用是什么?这个卷挂载的目的是什么?清晰的注释能极大地提升配置的可维护性。 - 如何实现:使用标准的 YAML 注释符
#来添加有意义的说明。
services:
# Nginx 作为反向代理和静态文件服务器
proxy:
image: nginx:1.21-alpine
ports:
# 将宿主机的 80 端口映射到容器的 80 端口
# 在生产环境中,这通常是唯一需要对外暴露的端口
- "80:80"
volumes:
# 挂载自定义的 Nginx 配置
-./nginx.conf:/etc/nginx/nginx.conf:ro
# 挂载静态资源,供 Nginx 直接提供服务
- static_content:/var/www/static
# 依赖于后端 API 服务,并等待其健康
depends_on:
api:
condition: service_healthy结论
从一个简单的 docker-compose.yml 文件起步,到打造一个专业的、生产级的配置,这不仅仅是技术的堆砌,更是一种工程思维的体现。我们探讨的高级特性——healthcheck、depends_on 的高级用法、deploy.resources 和服务伸缩——它们共同的目标是构建出更具弹性、更安全、更高效且更易于维护的应用系统。
而最佳实践清单则为我们提供了一张清晰的路线图,指引我们持续改进。这些实践并非繁琐的规则,而是前人经验的结晶,遵循它们能帮助我们从一开始就避免许多常见的陷阱。
现在,不妨花些时间审视一下你现有的 docker-compose.yml 文件。尝试应用本文中的一两个技巧,比如为关键服务添加一个 healthcheck,或者将镜像版本从 latest 切换为一个具体的标签。持续的、迭代式的改进,正是专业工程的精髓所在。当你将这些强大的工具和理念内化于心,你会发现 Docker Compose 不再只是一个启动容器的脚本,而是贯穿整个软件开发生命周期的、强大而优雅的声明式工具。
实战:Docker Compose部署投票应用教程
第一部分:蓝图 - 设计我们的多容器应用
在编写任何代码之前,清晰地规划应用架构和项目结构至关重要。这能帮助我们理解各个组件如何协同工作,并为后续的开发奠定坚实的基础。
应用架构
我们的“Voter App”将由五个核心服务和一个后台工作进程组成,每个服务都扮演着独特的角色:
- 投票前端 (Vote Frontend): 一个基于 Vue.js 的单页面应用,提供用户投票的界面。为了高效地提供静态文件,我们将使用 Nginx 作为 Web 服务器来部署它。
- 后端接口 (Backend API): 一个使用 Python 和 Flask 框架构建的轻量级 API。它负责接收来自前端的投票请求,然后将投票任务快速推送到消息队列中。
- 后台工作者 (Worker): 一个独立的 Python 脚本。它会持续监听消息队列,一旦有新的投票任务,它就会取出任务,处理投票逻辑,并将最终结果存入数据库。
- 缓存/队列 (Cache/Queue): 一个 Redis 实例。在这里,它主要作为连接 API 和 Worker 的“消息总线”(Message Broker),确保投票请求不会丢失,并实现应用间的解耦。
- 数据库 (Database): 一个 PostgreSQL 数据库,用于永久存储投票的最终统计结果。
- 结果展示 (Result Viewer): 一个基于 Node.js、Express 和 WebSockets 的简单网页,它会连接到数据库,并向所有客户端实时推送最新的投票结果。
下表清晰地总结了我们的应用架构,这将是我们贯穿整个教程的路线图。
| 服务名称 | 技术栈 | 在应用中的角色 | 暴露端口 |
|
| Vue.js + Nginx | 提供用户投票界面 |
|
|
| Python + Flask | 通过 HTTP POST 接收投票,并将其放入 Redis 队列 |
|
|
| Python + RQ | 从 Redis 队列中取出投票,并将其持久化到 PostgreSQL | (无) |
|
| Redis | 作为投票的消息代理/队列 |
|
|
| PostgreSQL | 持久化存储最终的投票计数 |
|
|
| Node.js + Express + WebSockets | 查询数据库并通过 WebSocket 实时推送结果给客户端 |
|
项目目录结构
一个清晰的目录结构对于管理多服务项目至关重要。在开始之前,请在你的工作区创建如下的目录和文件结构。这能确保我们的教程具有完全的可复现性。
voter-app/
├── api/
│ ├── app.py
│ ├── requirements.txt
│ └── Dockerfile
├── vote/
│ ├── public/
│ │ └── index.html
│ ├── src/
│ │ └── App.vue
│ │ └── main.js
│ ├── package.json
│ └── Dockerfile
├── result/
│ ├── public/
│ │ └── index.html
│ ├── server.js
│ ├── package.json
│ └── Dockerfile
├── worker/
│ ├── worker.py
│ ├── requirements.txt
│ └── Dockerfile
├──.env
├──.gitignore
└── docker-compose.yml现在,蓝图已经绘制完成,让我们开始逐一构建每个部分。
第二部分:地基 - 组合 API 和数据库
我们将遵循渐进式教学的原则,从最简单的功能单元开始:一个可以接收数据的 API 和一个用于存储数据的数据库。
开发后端 API (Python/Flask)
首先,我们来构建接收投票的后端 API。
在 api/requirements.txt 文件中,添加我们的依赖:
# api/requirements.txt
flask
redis接下来,在 api/app.py 中编写核心代码:
# api/app.py
import os
import redis
from flask import Flask, request, jsonify
app = Flask(__name__)
# 连接到 Redis 服务
# 'redis' 是我们在 docker-compose.yml 中定义的服务名
redis_host = os.environ.get('REDIS_HOST', 'localhost')
r = redis.Redis(host=redis_host, port=6379, db=0, decode_responses=True)
@app.route('/vote', methods=)
def vote():
data = request.get_json()
if not data or 'vote' not in data:
return jsonify({'error': 'Invalid vote data'}), 400
vote_option = data['vote']
if vote_option not in ['a', 'b']:
return jsonify({'error': 'Invalid vote option'}), 400
# 将投票任务推入 Redis 队列
try:
r.lpush('votes', vote_option)
return jsonify({'message': 'Vote received'}), 202
except redis.exceptions.ConnectionError as e:
return jsonify({'error': f'Could not connect to Redis: {e}'}), 500
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)架构决策:为什么使用 Redis 队列?
你可能注意到,API 端点并没有直接将投票写入数据库,而是将其推入了一个 Redis 队列。这是一个关键的架构决策,它极大地提升了我们应用的性能和健壮性。
- 响应速度: 数据库写入是一个相对较慢的 I/O 操作,尤其是在高负载下。如果 API 等待数据库写入完成再响应用户,会导致延迟,影响用户体验。而 Redis 是一个基于内存的数据存储,
lpush(列表推入) 操作几乎是瞬时的。API 可以快速地将任务放入队列,并立即返回一个
202 (Accepted) 状态码,告诉客户端“我们已经收到你的请求,正在处理中”。
- 解耦与韧性: 这种模式将 API(请求接收者)与 Worker(请求处理者)解耦。如果数据库暂时不可用,API 仍然可以正常接收投票并存入 Redis 队列。等数据库恢复后,Worker 会继续处理队列中积压的投票,从而避免了数据丢失。这正是微服务架构中弹性和可伸缩性的核心体现。
API 的 Dockerfile
现在,我们为 API 服务创建一个 Dockerfile,它定义了如何构建这个服务的镜像。
在 api/Dockerfile 中添加以下内容:
# api/Dockerfile
# 使用一个官方的、轻量级的 Python 镜像作为基础
# 'slim' 版本在保证功能的同时,体积更小,更安全 [3, 4]
FROM python:3.9-slim
# 设置容器内的工作目录
WORKDIR /app
# 优化 Docker 缓存:先复制依赖文件并安装
# 只有当 requirements.txt 变化时,这一层才会重新构建 [5]
COPY requirements.txt.
RUN pip install --no-cache-dir -r requirements.txt
# 复制应用代码到工作目录
COPY..
# 暴露 Flask 应用运行的端口
EXPOSE 5000
# 容器启动时运行的命令
# 使用 "0.0.0.0" 使服务可以从容器外部访问 [6]
CMD ["flask", "run", "--host=0.0.0.0"]创建初始的 docker-compose.yml
现在是时候引入 Docker Compose 了。在项目根目录下创建 docker-compose.yml 文件,并定义我们的前两个服务:api 和 db。
# docker-compose.yml
version: '3.9'
services:
api:
build:./api
ports:
- "5000:5000"
db:
image: postgres:15-alpine
volumes:
- db_data:/var/lib/postgresql/data
volumes:
db_data:这里我们定义了几个关键指令:
version: 指定我们使用的 Compose 文件格式版本。推荐使用较新的稳定版本,如 '3.9' 。services: 这是核心部分,用于定义应用中的各个容器服务。api: 我们的第一个服务。build:./api: 指示 Compose 使用api目录下的Dockerfile来构建镜像。ports: - "5000:5000": 将主机的 5000 端口映射到容器的 5000 端口,这样我们就可以从本地访问 API 了。
db: 我们的数据库服务。image: postgres:15-alpine: 直接使用 Docker Hub 上的官方 PostgreSQL 镜像。alpine版本非常小巧。volumes: 定义数据卷,用于数据持久化。
volumes: 顶层volumes键用于声明所有命名的卷。
使用命名卷实现数据持久化
对于像数据库这样的有状态服务(Stateful Service),数据持久化是至关重要的。
- 容器的短暂性: 标准 Docker 容器的文件系统是临时的。如果我们执行
docker compose down,db容器会被删除,其中存储的所有数据都将丢失。 - 数据与容器生命周期解耦: 为了解决这个问题,我们使用 Docker 的“卷”(Volumes)功能,将数据存储在主机文件系统上,从而将数据的生命周期与容器的生命周期分离开来。
- 命名卷(Named Volumes): 我们在这里使用了“命名卷” (
db_data)。这是一种由 Docker 管理的持久化存储方式,也是官方推荐的最佳实践。我们只需声明一个卷名,Docker 会负责在主机上创建和管理它。 - 挂载点: 我们将这个名为
db_data的卷挂载到容器内 PostgreSQL 存储数据的默认路径/var/lib/postgresql/data。 - 效果: 现在,当 PostgreSQL 容器写入数据时,它实际上是写入到了主机上的
db_data卷中。即使我们销毁并重建容器,新的容器也会重新挂载到这个已存在的卷上,所有历史数据都完好无损。这确保了我们应用数据的持久性和安全性。
第三部分:引擎室 - 添加 Worker 和 Redis 队列
现在,我们的应用有了接收请求的入口和存储数据的仓库。接下来,我们需要添加处理核心业务逻辑的“引擎”——Worker,以及连接 API 和 Worker 的“传送带”——Redis。
开发 Python Worker
Worker 是一个后台进程,它的任务是从 Redis 队列中取出投票,然后存入 PostgreSQL 数据库。
首先,在 worker/requirements.txt 中定义依赖:
# worker/requirements.txt
psycopg2-binary
redispsycopg2-binary: 用于连接 PostgreSQL 的流行 Python 库。redis: 用于连接 Redis 的库。
然后,编写 worker/worker.py 的代码:
# worker/worker.py
import os
import redis
import psycopg2
import time
import json
# --- 配置 ---
REDIS_HOST = os.environ.get('REDIS_HOST', 'localhost')
DB_HOST = os.environ.get('DB_HOST', 'localhost')
DB_USER = os.environ.get('POSTGRES_USER', 'postgres')
DB_PASSWORD = os.environ.get('POSTGRES_PASSWORD', 'supersecret')
DB_NAME = 'postgres'
# --- 数据库连接与初始化 ---
def get_db_connection():
while True:
try:
conn = psycopg2.connect(
host=DB_HOST,
database=DB_NAME,
user=DB_USER,
password=DB_PASSWORD
)
return conn
except psycopg2.OperationalError as e:
print(f"Database connection failed: {e}. Retrying in 5 seconds...")
time.sleep(5)
def initialize_db(conn):
with conn.cursor() as cur:
cur.execute("""
CREATE TABLE IF NOT EXISTS votes (
id SERIAL PRIMARY KEY,
vote_option VARCHAR(1) NOT NULL,
count INTEGER NOT NULL
);
""")
cur.execute("SELECT * FROM votes WHERE vote_option = 'a'")
if cur.fetchone() is None:
cur.execute("INSERT INTO votes (vote_option, count) VALUES ('a', 0)")
cur.execute("SELECT * FROM votes WHERE vote_option = 'b'")
if cur.fetchone() is None:
cur.execute("INSERT INTO votes (vote_option, count) VALUES ('b', 0)")
conn.commit()
print("Database initialized.")
# --- Redis 连接 ---
def get_redis_connection():
while True:
try:
r = redis.Redis(host=REDIS_HOST, port=6379, db=0, decode_responses=True)
r.ping()
print("Connected to Redis.")
return r
except redis.exceptions.ConnectionError as e:
print(f"Redis connection failed: {e}. Retrying in 5 seconds...")
time.sleep(5)
# --- 主逻辑 ---
if __name__ == '__main__':
db_conn = get_db_connection()
initialize_db(db_conn)
redis_conn = get_redis_connection()
print("Worker started. Waiting for votes...")
while True:
try:
# BLPOP 是一个阻塞操作,它会等待直到'votes'列表有元素可取 [2, 13]
# 这比循环查询(轮询)效率高得多
item = redis_conn.blpop('votes', timeout=0)
if item:
vote = item # blpop returns (list_name, value)
print(f"Processing vote for '{vote}'")
with db_conn.cursor() as cur:
# 更新投票计数 [12]
cur.execute("UPDATE votes SET count = count + 1 WHERE vote_option = %s", (vote,))
db_conn.commit()
except redis.exceptions.ConnectionError:
print("Reconnecting to Redis...")
redis_conn = get_redis_connection()
except psycopg2.Error as e:
print(f"Database error: {e}. Reconnecting...")
db_conn.close()
db_conn = get_db_connection()
except Exception as e:
print(f"An unexpected error occurred: {e}")
time.sleep(5)最后,为 Worker 创建一个 worker/Dockerfile,它和 API 的 Dockerfile 非常相似:
# worker/Dockerfile
FROM python:3.9-slim
WORKDIR /app
COPY requirements.txt.
RUN pip install --no-cache-dir -r requirements.txt
COPY..
CMD ["python", "worker.py"]扩展 docker-compose.yml
现在,我们将 worker 和 redis 服务添加到 docker-compose.yml 中,并引入几个至关重要的概念:networks、depends_on 和 environment。
# docker-compose.yml (updated)
version: '3.9'
services:
api:
build:./api
ports:
- "5000:5000"
environment:
- REDIS_HOST=redis
networks:
- voter_network
depends_on:
- redis
worker:
build:./worker
environment:
- REDIS_HOST=redis
- DB_HOST=db
- POSTGRES_USER=${POSTGRES_USER}
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
networks:
- voter_network
depends_on:
- db
- redis
redis:
image: redis:7-alpine
networks:
- voter_network
db:
image: postgres:15-alpine
environment:
- POSTGRES_USER=${POSTGRES_USER}
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
volumes:
- db_data:/var/lib/postgresql/data
networks:
- voter_network
volumes:
db_data:
networks:
voter_network:使用自定义网络进行服务通信
核心知识点:基于 DNS 的服务发现
我们引入了一个名为 voter_network 的自定义网络,并将所有服务都连接到这个网络上。这是一个关键的最佳实践。
- 内置 DNS: 当容器加入同一个自定义网络时,Docker 会提供一个内置的 DNS 服务器。
- 服务名即主机名: 这意味着,任何容器都可以通过其在
docker-compose.yml中定义的服务名来访问网络上的其他容器。例如,我们的 API 和 Worker 代码中,连接 Redis 时使用的主机名是redis,连接数据库时使用的主机名是db。Docker 的 DNS 会自动将这些服务名解析为相应容器的内部 IP 地址。 - 稳定性和抽象: 这种机制非常强大,因为它将我们从不稳定的、动态分配的容器 IP 地址中解放出来。无论容器重启多少次,IP 地址如何变化,服务名始终是稳定的通信地址。
- 网络隔离: 自定义网络还提供了网络隔离。只有在同一个网络内的容器才能相互通信,这增强了应用的安全性。
使用 depends_on 管理启动顺序
核心知识点:理解容器依赖的真正含义
api 和 worker 服务都依赖于 redis 和 db。depends_on 指令确保了 Docker Compose 会按照依赖顺序启动容器,即先启动 redis 和 db,再启动 api 和 worker。
然而,这里有一个非常重要的细节需要理解:depends_on只等待依赖的容器启动 (start),而不保证容器内的应用程序已经准备好接收连接 (ready)。
例如,PostgreSQL 容器启动后,其内部的数据库服务可能还需要几秒钟进行初始化。如果 worker 容器在这期间启动并立即尝试连接数据库,就会失败并崩溃。这就是所谓的“启动时序竞争”(Race Condition)。
专业的解决方案是在 db 服务中定义 healthcheck,并在 worker 的 depends_on 中使用 condition: service_healthy。但在开发环境中,一个更简单且非常常见的模式是在应用代码层面实现一个
重试循环。
我们在 worker.py 的 get_db_connection() 函数中正是这样做的。如果连接失败,它会打印一条消息,等待 5 秒,然后重试。这个简单的模式大大增强了我们应用的鲁棒性,也是 Docker 官方入门指南中推荐的做法。
使用 .env 文件保护敏感信息
我们不应将数据库密码等敏感信息硬编码在 docker-compose.yml 文件中。最佳实践是使用 .env 文件。
在项目根目录创建 .env 文件:
代码段
#.env
POSTGRES_USER=postgres
POSTGRES_PASSWORD=supersecretDocker Compose 在启动时会自动加载当前目录下的 .env 文件,并将其中的变量注入到环境中。然后,我们可以在 docker-compose.yml 中通过 ${VARIABLE_NAME} 的语法来引用这些变量,例如 ${POSTGRES_PASSWORD}。
至关重要的一步: 务必将 .env 文件添加到你的 .gitignore 文件中,以防止将机密信息提交到版本控制系统(如 Git)中。
#.gitignore
.env
node_modules/第四部分:门面 - 构建投票前端
现在,应用的后端逻辑已经就绪,是时候为用户创建一个交互界面了。
开发 Vue.js 前端
我们将创建一个简单的 Vue.js 应用。首先,确保你已经安装了 Node.js 和 Vue CLI。
在 vote/ 目录下,初始化项目并编写代码。
vote/package.json:
{
"name": "vote",
"version": "0.1.0",
"private": true,
"scripts": {
"serve": "vue-cli-service serve",
"build": "vue-cli-service build"
},
"dependencies": {
"vue": "^3.2.13"
},
"devDependencies": {
"@vue/cli-service": "~5.0.0"
}
}vote/src/main.js:
import { createApp } from 'vue'
import App from './App.vue'
createApp(App).mount('#app')vote/public/index.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width,initial-scale=1.0">
<title>Voter App</title>
</head>
<body>
<noscript>
<strong>We're sorry but this app doesn't work properly without JavaScript enabled. Please enable it to continue.</strong>
</noscript>
<div id="app"></div>
</body>
</html>vote/src/App.vue (核心交互逻辑):
<template>
<div id="app-container">
<h1>Which do you prefer?</h1>
<div class="vote-buttons">
<button @click="vote('a')">Cats 😺</button>
<button @click="vote('b')">Dogs 🐶</button>
</div>
<p v-if="message">{{ message }}</p>
</div>
</template>
<script>
export default {
name: 'App',
data() {
return {
message: ''
};
},
methods: {
async vote(option) {
this.message = 'Sending your vote...';
try {
const response = await fetch('/api/vote', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({ vote: option })
});
if (response.status === 202) {
this.message = 'Thank you for voting!';
} else {
const data = await response.json();
this.message = `Error: ${data.error |
| 'Something went wrong.'}`;
}
} catch (error) {
this.message = `Network Error: Could not connect to the API.`;
console.error('Fetch error:', error);
}
}
}
}
</script>
<style>
/* Add some basic styling */
#app-container {
font-family: Avenir, Helvetica, Arial, sans-serif;
text-align: center;
color: #2c3e50;
margin-top: 60px;
}
.vote-buttons button {
font-size: 2rem;
padding: 20px 40px;
margin: 20px;
cursor: pointer;
}
</style>注意 fetch('/api/vote',...): 我们使用了相对路径 /api/vote。在生产环境中,这需要一个反向代理来将 /api 的请求转发到后端 API 服务。为了简化本教程,我们将在后面的 docker-compose.yml 中直接将 API 暴露在 localhost:5000,前端通过 http://localhost:5000/vote 访问。在更复杂的设置中,通常会用 Nginx 作为所有服务的统一入口。
使用多阶段构建优化前端镜像
核心知识点:为生产环境构建小而安全的镜像
对于前端应用,直接将包含 node_modules 和源代码的开发环境打包成镜像是非常低效和不安全的。最佳实践是使用多阶段构建 (Multi-stage builds)。
在 vote/Dockerfile 中添加以下内容:
# vote/Dockerfile
# --- STAGE 1: Build ---
# 使用 Node 镜像作为“构建器”
FROM node:18-alpine AS builder
WORKDIR /app
# 复制 package.json 和 package-lock.json
COPY package*.json./
# 安装依赖
RUN npm install
# 复制所有源代码
COPY..
# 构建生产版本的静态文件
RUN npm run build
# --- STAGE 2: Production ---
# 使用一个非常轻量的 Nginx 镜像作为最终镜像
FROM nginx:1.25-alpine
# 将构建器阶段生成的静态文件复制到 Nginx 的 web 根目录
COPY --from=builder /app/dist /usr/share/nginx/html
# 暴露 Nginx 的默认端口
EXPOSE 80
# Nginx 默认的启动命令会处理好一切
CMD ["nginx", "-g", "daemon off;"]这个 Dockerfile 的精妙之处在于:
- 构建阶段 (builder): 我们使用一个完整的 Node.js 环境来执行
npm install和npm run build。这个阶段会生成最终的、优化的静态文件(HTML, CSS, JS),通常位于dist目录。 - 生产阶段 (production): 我们切换到一个全新的、极其轻量的
nginx:alpine镜像。然后,使用COPY --from=builder命令,只从第一阶段(构建器)中复制出dist目录的内容。 - 最终结果: 最终生成的镜像是小巧的 Nginx 加上一些静态文件。它不包含任何 Node.js、
node_modules、源代码或开发依赖。这使得镜像体积大大减小,并且由于移除了所有不必要的工具和代码,其攻击面也显著降低,从而更加安全。
更新 docker-compose.yml
现在,将 vote 服务添加到我们的 docker-compose.yml 文件中。
# docker-compose.yml (updated)
version: '3.9'
services:
vote:
build:./vote
ports:
- "8080:80" # 将主机的 8080 端口映射到 Nginx 容器的 80 端口
networks:
- voter_network
api:
#... (rest of the services remain the same)我们将主机的 8080 端口映射到 vote 容器的 80 端口,因为 Nginx 默认在容器内监听 80 端口。
第五部分:计分板 - 实时结果查看器
我们的应用现在可以投票了,但如果不能实时看到结果,那就太无趣了。最后一步,我们来构建一个使用 WebSockets 的实时结果展示服务。这也将展示我们架构的多语言特性。
开发结果服务 (Node.js/Express/WebSockets)
这个服务将使用 Node.js 和 Express 来提供一个简单的 HTML 页面,并使用 ws 库建立 WebSocket 连接,实时推送数据。
在 result/ 目录下,首先创建 package.json:
{
"name": "result",
"version": "1.0.0",
"description": "Real-time result viewer",
"main": "server.js",
"scripts": {
"start": "node server.js"
},
"dependencies": {
"express": "^4.18.2",
"pg": "^8.11.3",
"redis": "^4.6.10",
"ws": "^8.14.2"
}
}然后,创建 result/public/index.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Live Vote Results</title>
<style>
/* Basic styling */
body { font-family: sans-serif; padding: 0 20px; }
.results { display: flex; gap: 40px; }
.result-block { padding: 20px; border: 1px solid #ccc; border-radius: 8px; text-align: center; }
.count { font-size: 4rem; font-weight: bold; }
.label { font-size: 1.5rem; }
</style>
</head>
<body>
<h1>Live Results</h1>
<div class="results">
<div class="result-block">
<div id="a-count" class="count">0</div>
<div class="label">Cats 😺</div>
</div>
<div class="result-block">
<div id="b-count" class="count">0</div>
<div class="label">Dogs 🐶</div>
</div>
</div>
<script>
const aCount = document.getElementById('a-count');
const bCount = document.getElementById('b-count');
const ws = new WebSocket(`ws://${window.location.host}`);
ws.onopen = () => {
console.log('Connected to WebSocket server');
};
ws.onmessage = (event) => {
const data = JSON.parse(event.data);
console.log('Received results:', data);
aCount.textContent = data.a |
| 0;
bCount.textContent = data.b |
| 0;
};
ws.onclose = () => {
console.log('Disconnected from WebSocket server');
};
</script>
</body>
</html>最后,是核心的服务器逻辑 result/server.js:
// result/server.js
const express = require('express');
const http = require('http');
const { WebSocketServer } = require('ws');
const { Pool } = require('pg');
const redis = require('redis');
const path = require('path');
// --- 配置 ---
const PORT = process.env.PORT |
| 5001;
const DB_HOST = process.env.DB_HOST |
| 'localhost';
const DB_USER = process.env.POSTGRES_USER |
| 'postgres';
const DB_PASSWORD = process.env.POSTGRES_PASSWORD |
| 'supersecret';
const REDIS_HOST = process.env.REDIS_HOST |
| 'localhost';
// --- Express 服务器设置 ---
const app = express();
app.use(express.static(path.join(__dirname, 'public')));
const server = http.createServer(app);
// --- PostgreSQL 连接池 ---
const pgPool = new Pool({
host: DB_HOST,
user: DB_USER,
password: DB_PASSWORD,
database: 'postgres',
});
// --- WebSocket 服务器设置 ---
const wss = new WebSocketServer({ server });
async function getResults() {
const client = await pgPool.connect();
try {
const res = await client.query('SELECT vote_option, count FROM votes');
const results = { a: 0, b: 0 };
res.rows.forEach(row => {
results[row.vote_option] = row.count;
});
return results;
} finally {
client.release();
}
}
function broadcastResults(results) {
const data = JSON.stringify(results);
wss.clients.forEach(client => {
if (client.readyState === client.OPEN) {
client.send(data);
}
});
}
wss.on('connection', async (ws) => {
console.log('Client connected');
// 新客户端连接时,立即发送一次当前结果
try {
const results = await getResults();
ws.send(JSON.stringify(results));
} catch (err) {
console.error('Error fetching initial results:', err);
}
ws.on('close', () => console.log('Client disconnected'));
});
// --- Redis Pub/Sub 实现高效实时更新 ---
async function setupRedisListener() {
const redisClient = redis.createClient({ url: `redis://${REDIS_HOST}:6379` });
await redisClient.connect();
// 订阅 'votes_updated' 频道
await redisClient.subscribe('votes_updated', async (message) => {
console.log(`Received message from Redis: ${message}`);
// 收到通知后,才去查询数据库并广播结果
const results = await getResults();
broadcastResults(results);
});
console.log('Subscribed to Redis channel: votes_updated');
}
// --- 启动服务器 ---
server.listen(PORT, () => {
console.log(`Result server running on http://localhost:${PORT}`);
setupRedisListener().catch(console.error);
});
// 为了让 worker 发布消息,我们需要修改 worker.py
// 在 worker.py 的主循环中,当数据库更新成功后,添加:
// redis_conn.publish('votes_updated', 'new_vote')架构升级:使用 Redis Pub/Sub 实现高效实时更新
一个简单的实时应用可能会让结果服务器每秒轮询一次数据库。但这非常低效,会给数据库带来不必要的压力。我们可以利用 Redis 的发布/订阅(Pub/Sub)功能来构建一个更优雅、高效的事件驱动系统。
- 修改 Worker (发布者): 我们需要对
worker/worker.py做一个小小的修改。在while True:循环中,当数据库更新成功提交后,添加一行代码来发布一个消息:
# 在 worker.py 的 db_conn.commit() 之后
redis_conn.publish('votes_updated', 'new_vote')现在,每当一个投票被成功记录,Worker 就会向 votes_updated 频道发送一条通知。
- 结果服务 (订阅者): 如
result/server.js中所示,结果服务会订阅同一个votes_updated频道。 - 事件驱动流程: 只有当结果服务从 Redis 收到通知时,它才知道数据发生了变化。然后,也只有在那时, 它才会去查询数据库获取最新的计票结果,并将其通过 WebSocket 广播给所有连接的客户端。
这个模式展示了一个松耦合、高性能的实时架构,并再次体现了 Redis 的多功能性——它在我们的应用中既是任务队列,又是发布/订阅消息系统。
最后,创建 result/Dockerfile:
# result/Dockerfile
FROM node:18-alpine
WORKDIR /app
COPY package*.json./
RUN npm install --omit=dev
COPY..
EXPOSE 5001
CMD ["node", "server.js"]最终的 docker-compose.yml
现在,将 result 服务添加到 docker-compose.yml 中,我们的整个应用栈就完成了!
# docker-compose.yml (final)
version: '3.9'
services:
vote:
build:./vote
ports:
- "8080:80"
networks:
- voter_network
result:
build:./result
ports:
- "5001:5001"
environment:
- REDIS_HOST=redis
- DB_HOST=db
- POSTGRES_USER=${POSTGRES_USER}
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
networks:
- voter_network
depends_on:
- db
- redis
api:
build:./api
ports:
- "5000:5000"
environment:
- REDIS_HOST=redis
networks:
- voter_network
depends_on:
- redis
worker:
build:./worker
environment:
- REDIS_HOST=redis
- DB_HOST=db
- POSTGRES_USER=${POSTGRES_USER}
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
networks:
- voter_network
depends_on:
- db
- redis
redis:
image: redis:7-alpine
networks:
- voter_network
db:
image: postgres:15-alpine
environment:
- POSTGRES_USER=${POSTGRES_USER}
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
volumes:
- db_data:/var/lib/postgresql/data
networks:
- voter_network
volumes:
db_data:
networks:
voter_network:第六部分:指挥与控制 - 运行和调试你的应用栈
现在所有的组件都已就位,是时候启动并驾驭我们的多容器应用了。
运行应用
得益于 Docker Compose,启动整个复杂的应用栈只需要一条命令。在项目根目录下运行:
docker compose up --build -d--build: 强制重新构建在docker-compose.yml中定义了build指令的服务的镜像。-d(detached): 在后台运行容器,这样你的终端就不会被日志占满。
核心 docker compose 命令
掌握以下命令是管理和调试 Compose 应用的关键:
- 查看服务状态:
docker compose ps这个命令会列出所有服务及其当前状态(如 running, exited)和端口映射 22。
- 查看日志: 这是你进行调试时最重要的工具。
# 查看特定服务的日志
docker compose logs api
# 持续跟踪日志 (类似 tail -f)
docker compose logs -f worker通过查看 api, worker, result 的日志,你可以清晰地看到一个投票请求是如何在系统内流转的。
- 在容器内执行命令:
docker compose exec <service_name> <command>这个命令允许你在一个正在运行的容器内部执行任意命令。这对于交互式调试非常有用。例如,获取一个进入数据库容器的 psql shell:
docker compose exec db psql -U postgres或者获取一个进入 API 容器的 shell:
docker compose exec api sh- 停止并移除所有资源:
docker compose down这个命令会停止并删除所有相关的容器和网络。如果你想同时删除 db_data 这个命名卷(警告:这将删除所有数据库数据!),可以添加 --volumes 标志:docker compose down --volumes。
验证整个系统
现在,让我们来验证整个系统是否按预期工作:
- 打开投票页面: 在浏览器中访问 http://localhost:8080。
- 打开结果页面: 在另一个浏览器标签页中访问 http://localhost:5001。
- 投票: 在投票页面上,点击“Cats”或“Dogs”按钮。
- 观察结果: 你应该能立即看到结果页面上的计票数实时增加,而无需刷新页面。
- 检查日志: 运行
docker compose logs -f api和docker compose logs -f worker,你可以看到 API 接收到请求并将其放入队列,然后 Worker 从队列中取出并处理它的日志记录。
Docker Compose 关键指令速查表
下表总结了我们在本教程中使用的核心 docker-compose.yml 指令,可作为你未来项目的快速参考。
| 指令 | 示例用法 | 解释 |
|
|
| 指定包含 Dockerfile 的目录,用于构建服务镜像。 |
|
|
| 指定要从镜像仓库(如 Docker Hub)拉取的镜像。 |
|
|
| 将主机的端口映射到容器的端口(格式: |
|
|
| 挂载命名卷或主机目录到容器内,用于数据持久化。 |
|
|
| 将服务连接到一个或多个自定义网络,实现服务间通信。 |
|
|
| 在容器内设置环境变量,用于配置应用。 |
|
|
| (未在最终版使用,但常用) 从文件加载环境变量。 |
|
|
| 定义服务间的启动顺序依赖关系。 |
结论:超越教程
恭喜你!你已经成功地构建、部署并管理了一个包含五个服务、使用三种不同编程语言和多种技术的全栈 Web 应用。你不仅学习了 Docker Compose 的语法,更重要的是,你掌握了如何运用它来解决真实世界中的开发挑战:
- 服务编排: 通过一个文件管理整个应用栈。
- 服务发现: 利用自定义网络实现服务间的无缝通信。
- 数据持久化: 使用命名卷保护关键数据。
- 配置管理: 通过环境变量和
.env文件安全地配置你的应用。 - 构建优化: 采用多阶段构建来创建更小、更安全的生产镜像。
- 异步处理: 利用消息队列构建响应迅速、高可用的系统。
这只是你 Docker 之旅的开始。基于今天所学,你可以探索更多高级主题:
- 生产级编排: 学习 Docker Swarm 或 Kubernetes,它们提供了更强大的功能,如自动扩缩容和自愈能力 23。
- 健康检查: 在
docker-compose.yml中实现healthcheck,以创建更可靠的服务依赖关系。 - 持续集成/持续部署 (CI/CD): 将你的 Docker 构建流程集成到 Jenkins、GitHub Actions 或 GitLab CI 等工具中,实现自动化测试和部署。
- 安全加固: 使用 Docker Secrets 替代环境变量来管理最敏感的信息,如生产环境的密码和 API 密钥。
希望本教程能为你打开一扇通往高效、现代化的云原生开发的大门。继续探索,不断构建!



















 42
42

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









