




 本文介绍了神经网络的基本构成,包括层间连接、激活函数及其选择,并解释了前向传播、反向传播的过程,还讨论了参数初始化的重要性。
本文介绍了神经网络的基本构成,包括层间连接、激活函数及其选择,并解释了前向传播、反向传播的过程,还讨论了参数初始化的重要性。
神经网络的表示
一般计算神经网络层数时不算输入层,所以下图是二层的神经网络

每个结点包含两个过程,一个是z=wT x+b,另一个是激活函数。
隐藏层和输出层都有参数w和b,第一层的w是4×3的矩阵,b是4×1的矩阵;第二层的w是1×4的矩阵,b是1×1的矩阵。
计算
单样本的
先计算第一层的z和a:

将上述过程向量化:
z看成4×1的矩阵,W看成4×3的矩阵,b看成4×1的矩阵。

多样本的
非向量化的实现:
循环遍历m个样本,对于第i个样本:


向量化的实现:
横向方向对应各个样本,纵向对应神经网络中的不同结点
X矩阵:
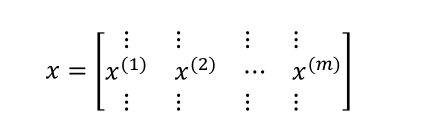
Z[1]:

A[1] :

所以:
Z[1] =W[1] X + b[1]

激活函数
sigmoid激活函数:值域范围[0,1]


仅用于二分类
tanh激活函数:值域范围[-1,1]

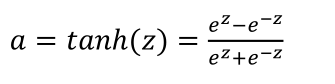
除非是二分类应用,否则选用tanh,因为tanh比sigmoid更优越。在训练一个算法模型时,如果使用 tanh 函数代替
sigmoid 函数中心化数据,使得数据的平均值更接近 0 而不是 0.5.
注意:在不同的神经网络层中,激活函数可以不同。
以上二种激活函数的缺点是当z很大或者很小时,梯度会非常小,参数更新就比较慢。
ReLu激活函数:


Leaky ReLu激活函数:

如果不确定选哪种激活函数时,优先考虑ReLu激活函数。
为什么需要非线性激活函数
事实证明:要让你的神经网络能够计算出有趣的函数,你必须使用非线性激活函数。
如果你使用线性激活函数或者没有使用一个激活函数,那么无论你的神经网络有多少层一直在做的只是
计算线性函数,所以不如直接去掉全部隐藏层。
总而言之,不能在隐藏层用线性激活函数,可以用 ReLU 或者 tanh 或者 leaky ReLU 或者其他的非线性激活函数,唯一可以用线性激活函数的通常就是输出层。
激活函数的导数
sigmoid:

tanh:

ReLu:

Leaky ReLu:

神经网络的梯度下降公式
假设输出层的激活函数是sigmoid
正向传播方程:

反向传播方程:


“*”表示对应位置元素相乘


np.sum(keepdims=True)
keepdims=True:确保矩阵的维度为n^[1]×1
随机初始化参数
为什么需要随机初始化?
如果按参数都初始化为0,则同一层的各个结点其实都在计算同一个东西,也就没必要设置多个结点,因此需要随机初始化参数,各个结点都在计算不同的东西。

比如上图这个神经网络,w[1] 是2×2的矩阵,b[1] 是2×1的矩阵,w[2] 是1×2的矩阵,b[2] 是1×1的矩阵,可以通过如下代码随机初始化
w_1 = np.random.randn(2, 2) * 0.01
b_1 = np.zeros((2, 1))
为什么要乘0.01?
我们通常倾向于初始化为很小的随机数。如果要用tanh或者sigmoid激活函数,可能会使得梯度下降得很慢。
代码笔记
- 如果有一个矩阵X,要求X中的元素如果大于0.5,则将它赋值为1,否则赋值为0
可以循环遍历,也可以使用如下的语句
X=(X>0.5)
此时X中元素的数据类型是bool类型
- range
range(start, stop, step)
tart: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
- np.linspace
numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0)
Return evenly spaced numbers over a specified interval.
(在start和stop之间返回均匀间隔的数据)
Returns num evenly spaced samples, calculated over the interval [start, stop].
(返回的是 [start, stop]之间的均匀分布)
The endpoint of the interval can optionally be excluded.
Changed in version 1.16.0: Non-scalar start and stop are now supported.
(可以选择是否排除间隔的终点)
start:返回样本数据开始点
stop:返回样本数据结束点
num:生成的样本数据量,默认为50
endpoint:True则包含stop;False则不包含stop
retstep:If True, return (samples, step), where step is the spacing between samples.(即如果为True则结果会给出数据间隔)
dtype:输出数组类型
axis:0(默认)或-1
- np.c_
np.c_[a,b]
将a和b结合,要求a和b的行数一致
-
ravle()
ravel函数将多维数组降为一维,仍返回array数组
x = np.array([[1, 2], [3, 4]]) print(x) >>>array([[1, 2], [3, 4]]) x.ravel() >>>array([1, 2, 3, 4]) -
np.divide()
numpy.divide(x1, x2, /, out=None, *, where=True, casting=‘same_kind’, order=‘K’, dtype=None, subok=True[, signature, extobj]) = <ufunc ‘true_divide’>)
功能:
数组对应位置元素做除法。
这里的除法结果和Python传统的地板除不同,这里得到的是真实值。numpy.divide的计算结果适应于输出值的数值类型,与输入值的数值类型无关。
参数:
x1 数组型变量 充当被除数的数组
x2 数组型变量 充当除数的数组
out n维数组,None,n维数组组成的元组,可选参数,计算结果的存放位置。若提供此参数,它的维度必须和输入数组扩维后的维度保持一致。若不提供此参数或该值为None,返回新开辟的数组。若此值为元组类型,其长度必须和返回值的个数保持一致。
where 数组型变量,可选参数 用默认值即可
返回值:
out n维数组或标量 如果x1和x2均为标量,那么返回值也为标量
深层神经网络
流程图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EJqM88yO-1665366027660)(https://cdn.jsdelivr.net/gh/DaoChenLiu/images/learning_report3/202210080950989.png)]
前向传播

A[0] =X
反向传播

*是对应元素相乘

参数
W[1] b[1] ,W[2] b[2] ……
超参数
控制参数的参数
学习率,迭代次数,隐层数,隐层单元的个数……
如何寻找最优的超参数?
不断尝试
具体流程
- 初始化参数
- 实现各种函数,包括线性函数,激活函数…
- 正向传播
- 计算损失
- 反向传播
- 更新参数
在具体实现时,需要保存每一层的参数,例如A,W,b,Z

















 6592
6592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









