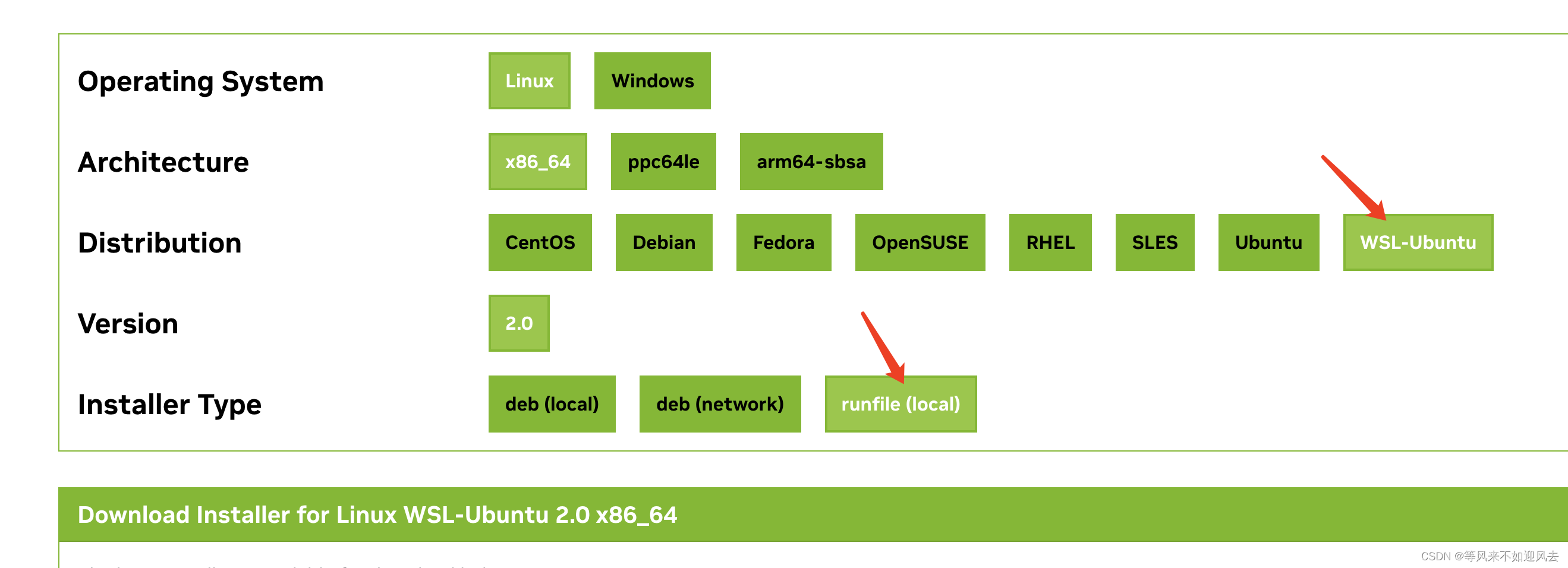
参考大神: wsl2-ubuntu版本 cuda 下周cuda11.3 wget https://developer.download.nvidia.com/compute/cuda/11.3.0/local_installers/cuda_11.3.0_465.19.01_linux.run sudo sh cuda_11.3.0_465.19.01_linux.run








 超级会员免费看
超级会员免费看

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1807
1807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








