



 该文提出了一种名为show-and-fool的算法,专门针对CNN+RNN结构的神经图像字幕系统进行攻击。通过三种损失函数(targeted caption method, targeted keyword method, untargeted method),作者展示了如何生成错误字幕,其中targeted keyword method考虑了关键词出现的位置。实验表明,这种方法能够有效地创建对抗性例子,且其损失函数取得良好效果,为对抗性学习在图像字幕系统的应用提供了新思路。
该文提出了一种名为show-and-fool的算法,专门针对CNN+RNN结构的神经图像字幕系统进行攻击。通过三种损失函数(targeted caption method, targeted keyword method, untargeted method),作者展示了如何生成错误字幕,其中targeted keyword method考虑了关键词出现的位置。实验表明,这种方法能够有效地创建对抗性例子,且其损失函数取得良好效果,为对抗性学习在图像字幕系统的应用提供了新思路。
文章简介:文章主要提出了show-and-fool算法,对现代神经图像字幕系统进行攻击。并为此提出了三种loss函数的实现方法,这三种方法是由难到易的(主观判断)。该方法的主要面向对象是CNN+RNN的结构的现代神经图像字幕系统。
1.targeted caption method; show-and-tell会生成确定的错误的字幕,这个字幕是给出的目标。
2.targeted keyword method;show-and-tell会生成错误的字幕,这个字幕中包含了一些的关键词。
3.untargeted method. show-and-tell会生成错误的字幕。
主要贡献:提出了show-and-full的算法,一种基于优化的方法制作图像对抗例子。给出了三种方法的loss函数,用于评估对抗例子的稳定性。
理论分析:
1、targeted caption method
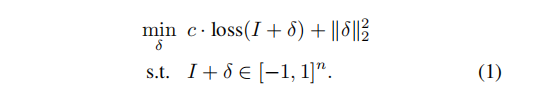
c为超参数,I+δ表示更改过后的图片(已被攻击)I为原始图片。
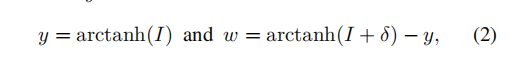
引入中间变量w,y将约束项消去
从(2)反推tanh(w+y)=I+δ因此属于[-1,1]
消去约束条件得到(3)
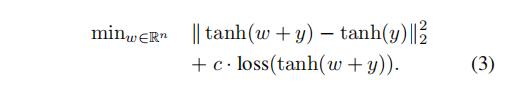
要保证在所有词汇集Ω中,s(目标词汇)是最大概率
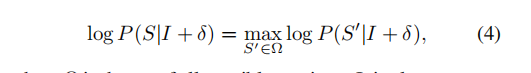
根据RNN,下一个词汇的输出由图像与前面所有词汇决定。
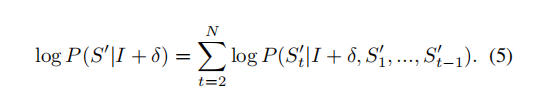
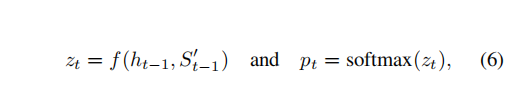
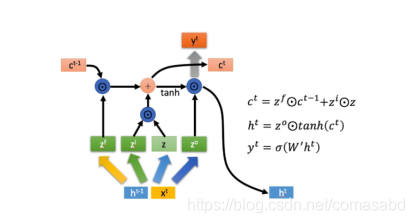
(图片来源:B站许志钦老师的课程)
根据softmax函数的特点,直接使用负对数作为loss函数,衡量攻击图像的损失
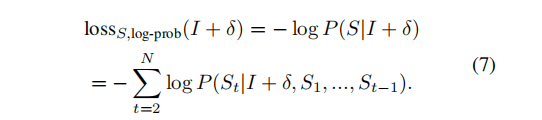
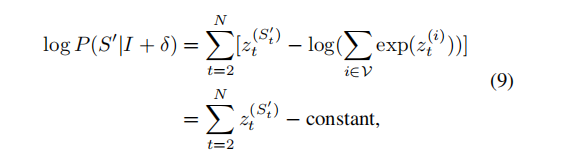
由于对于词汇来说,不需要构造概型使得某一个目标词汇概率为1,只需要让它可能性最大就行,引入这个参数的含义是目标词语与第二大可能的目标词语的差距,当该差距大于某一值时,认为在这个词汇上的参数已经优化完毕。
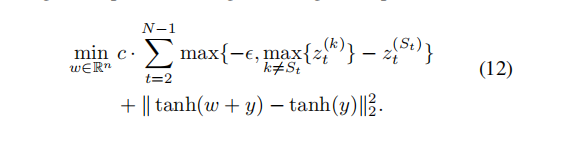
2、untargeted method
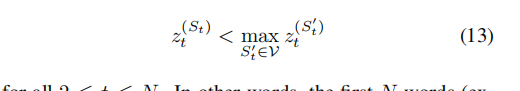
与有目标的方法不同,无目标方法只需要将原来的词汇St变得比任意词汇小就可以了。与有目标的方法类似,需要最可能词汇的概率减去原始词汇概率大过参数。
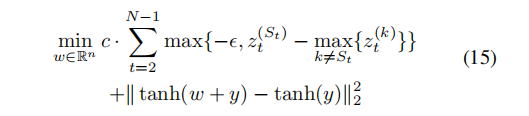
3.targeted keyword method
由于不希望关键词汇出现在某个特定的位置(否则这就和方法1一样了)。因此使用min,寻找在所有位置上t=1---N关键词与出现在该位置可能性最大,并且只优化最大位置的可能性(与第二可能的词汇概率差距大于参数e)。
这里的求和是指所有的关键词概率(假设有M个关键词)。
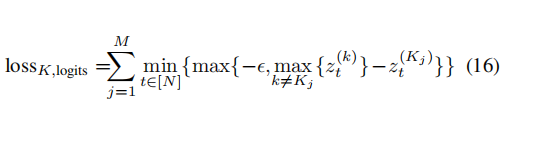
当有两个关键词在同一位置的概率都很大时,上述的系统可能会同时对两个关键词进行优化,但不同的词不能出现在相同的位置,因此当某一词汇在该位置成为最大可能时,会屏蔽其他词汇的干扰。
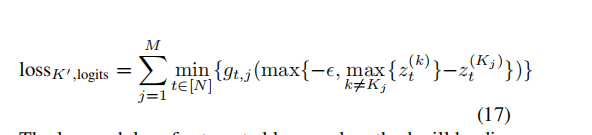
这个方法的攻击不像前两个方法一样拥有确定以及固定的输入(有目标法输入为目标,无目标法输入为原始句子S0)。因此这个方法首先将S0作为输入,这里的S0指的是无干扰下生成的字幕或者正确的字幕。经过T次迭代之后,将训练结果给字幕生成系统再生成一次字幕,记为S1作为新的输入。
- 实验
- 总结
这篇文章首次对CNN+RNN的架构的字幕生成系统进行对抗,并且与以往其他的对抗算法不同,这个对抗算法的分类结果是接近无穷的。这个算法(损失函数)取得了比较好的实验结果,并且该成果很容易拓展到别的地方去。

















 762
762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









