




String的字符串是不可变的,StringBuffer和StringBuilder是可变的
String:是字符常量,适用于少量的字符串操作的情况。Java中所有的双引号字面量代表字符串都是String这个类实现的。String一旦创建就不能更改
StringBuilder:适用于单线程下在字符缓冲区进行大量操作的情况 。线程不安全的,速度快
StringBuffer:适用多线程下在字符缓冲区进行大量操作的情况。synchronized修饰,是线程安全的,效率慢
StringBuffer中,有大量的synchronized修饰
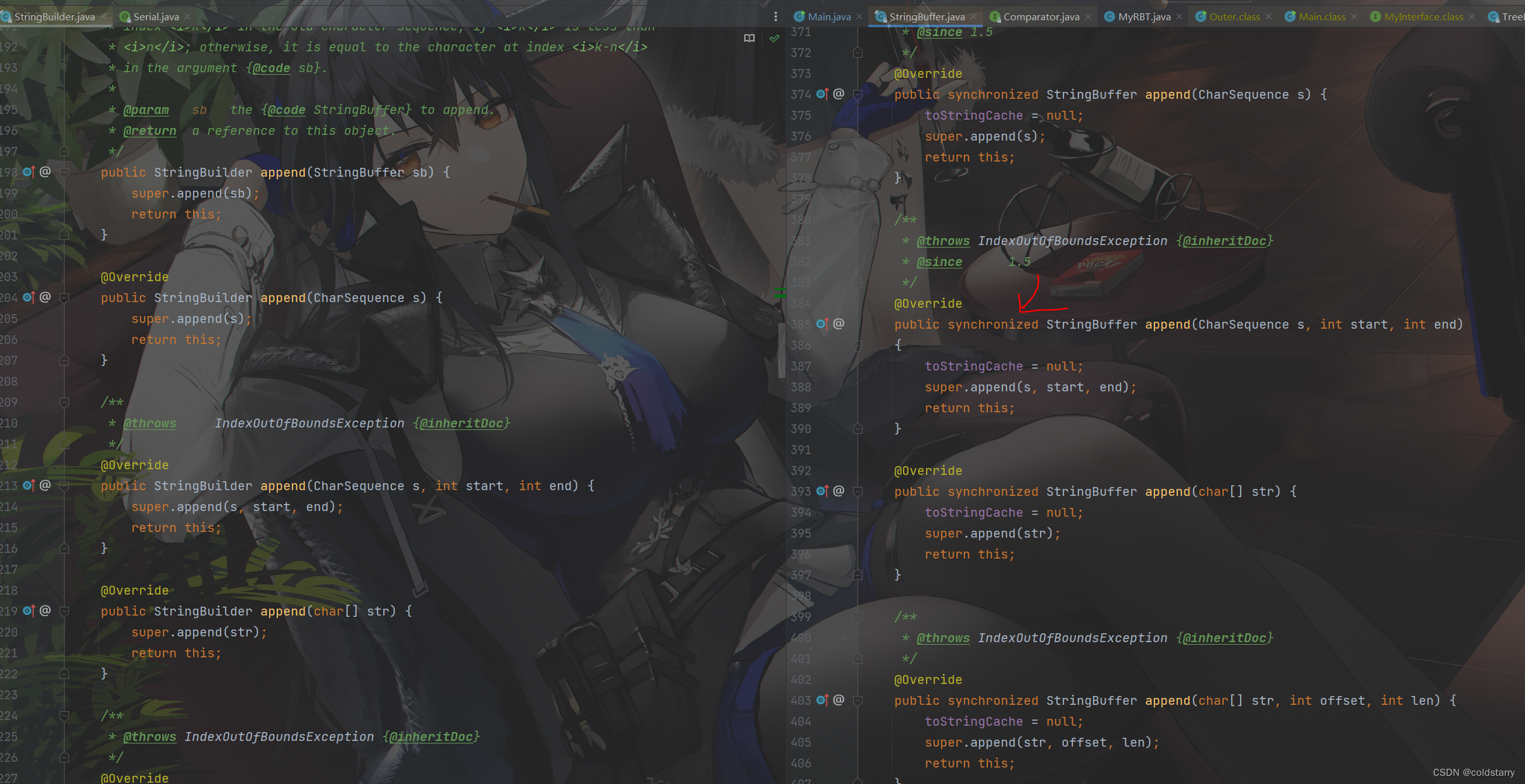
而且这俩都继承于AbstractStringBuilder实现的

看看为啥StringBuffer和StringBuilder都可以修改字符串,因为这俩继承于AbstractStringBuilder,然后这货里面存放的,是个可变的数组,String中存个final类型的数组
另外String中的value,弄个@Stable注解,这个注解只有用在被根加载器加载的类中才有作用,否则加载器会忽略它。它用在这里的目的表示当前value中的值是可信任的,Stable用在这里很安全,因为value的值不会为null,对于被这个注解修饰的变量或者数组,值或其中所有只能被修改一次。引用类型初始为null,原生类型初始为0,他们能被修改为非null或者非0只能修改一次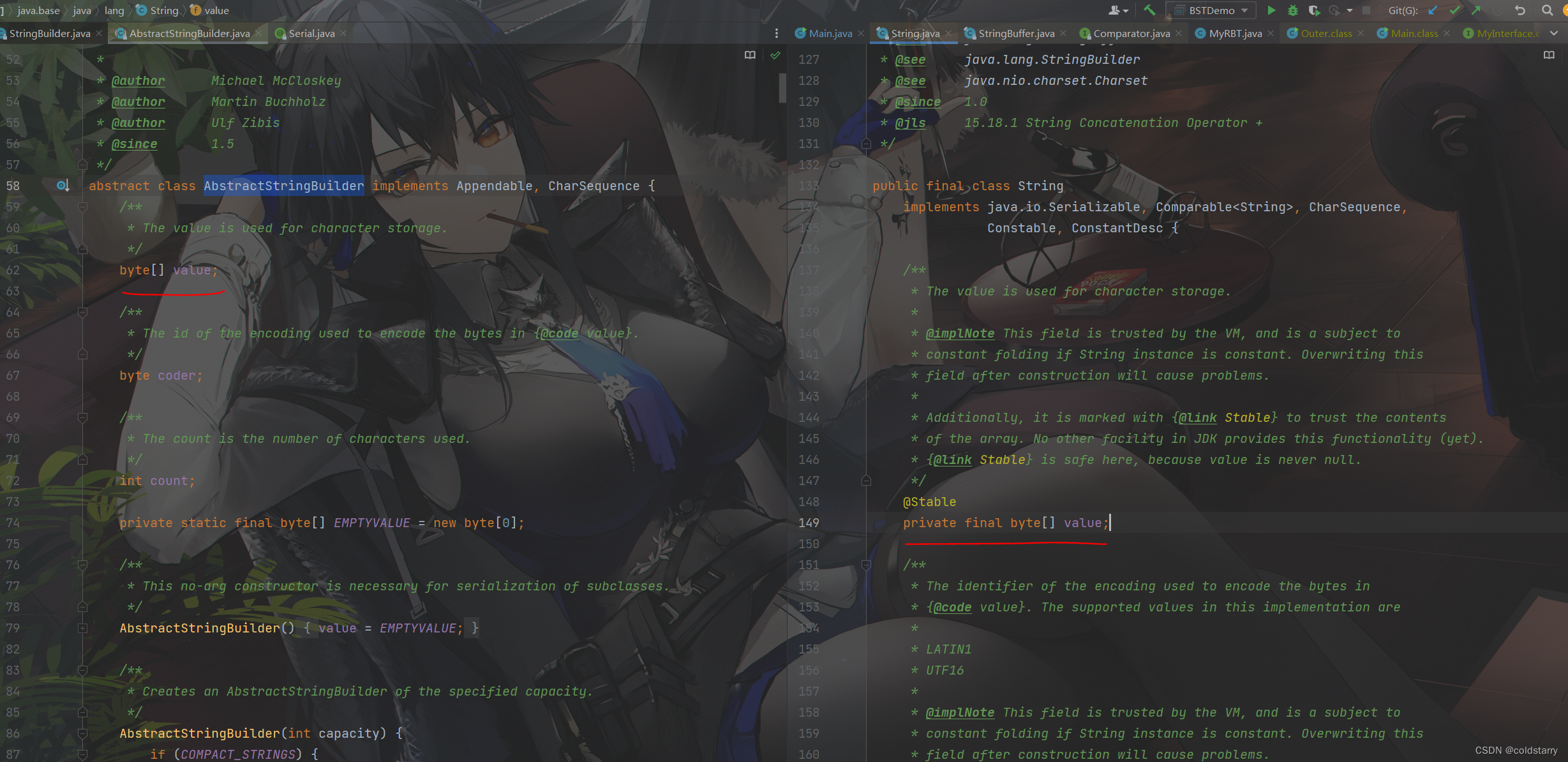
String存储字符(双字节和单字节)
在JDK1.8中,采用了char数组来存储字符串,和C语言一样。Java的char默认是UTF16编码的,即无论是什么字符,都用两个字节表示。但是对于字符串中所有字符编码都在0xff(例如只包含ASCII编码的字符)之内的字符,相当于多耗费了一倍的空间。针对这个问题JDK9将字符串的底层存储由char数组改成了byte数组。并检查如果字符串中有没有大于0xff的字符,如果没有就用一个字节存储字符串,如果有,则所有字符用两个字节存储(这个是可以通过COMPACT_STRINGS配置的)。
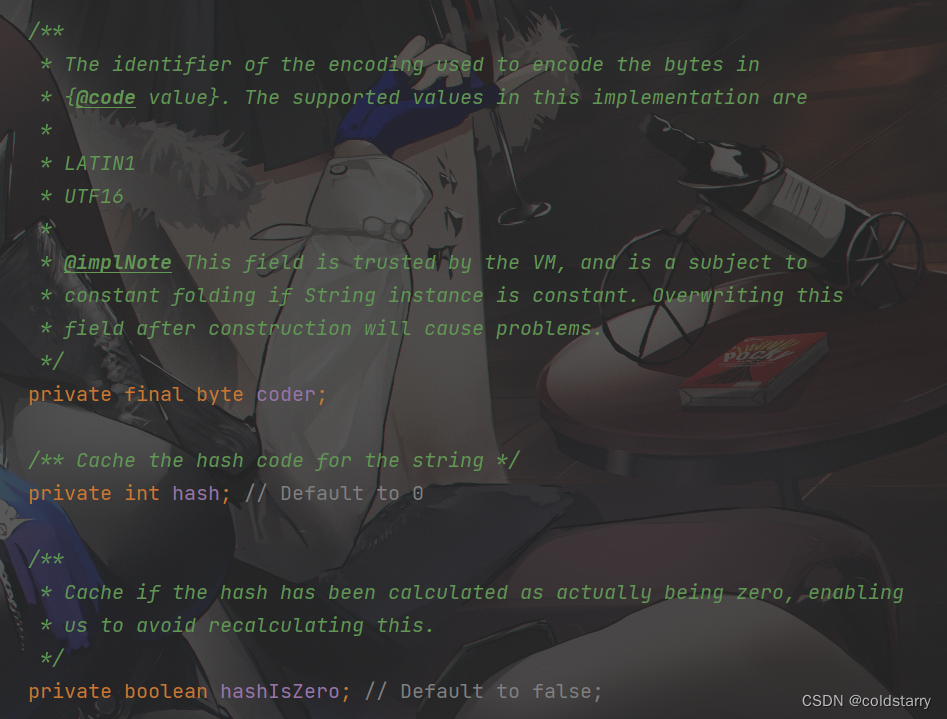
coder一般只有两个值:

Latin1是ISO-8859-1的别名,有些环境下写作Latin-1。ISO-8859-1编码是单字节编码,向下兼容ASCII,其编码范围是0x00-0xFF,0x00-0x7F之间完全和ASCII一致。 UTF16就是两字节编码。
很多方法需要区分是单字节编码还是双字节编码,一般通过isLatin1来区分:

COMPACT_STRINGS为是否启用之前提到了byte数组压缩,代码中可以看出,默认就是启用。实际上这个是JVM注入的(布尔变量COMPACT_STRINGS是由命令行参数XX:-CompactStrings定义的,并且也能用该参数禁用掉)
初始化
StringBuilder和StringBuffer初始化
StringBuilder和StringBuffer差不多,分为三种:
- StringBuffer stringBuffer = new StringBuffer();没有给传入参数,默认的是一个数组长度为16的字符串
- StringBuffer stringBuffer = new StringBuffer(5);直接给定要创建的字符长度
- StringBuffer stringBuffer = new StringBuffer(“Xin”);在创建的时候,初始给定初始化的一个字符串,默认初始长度就是字符串的长度加16
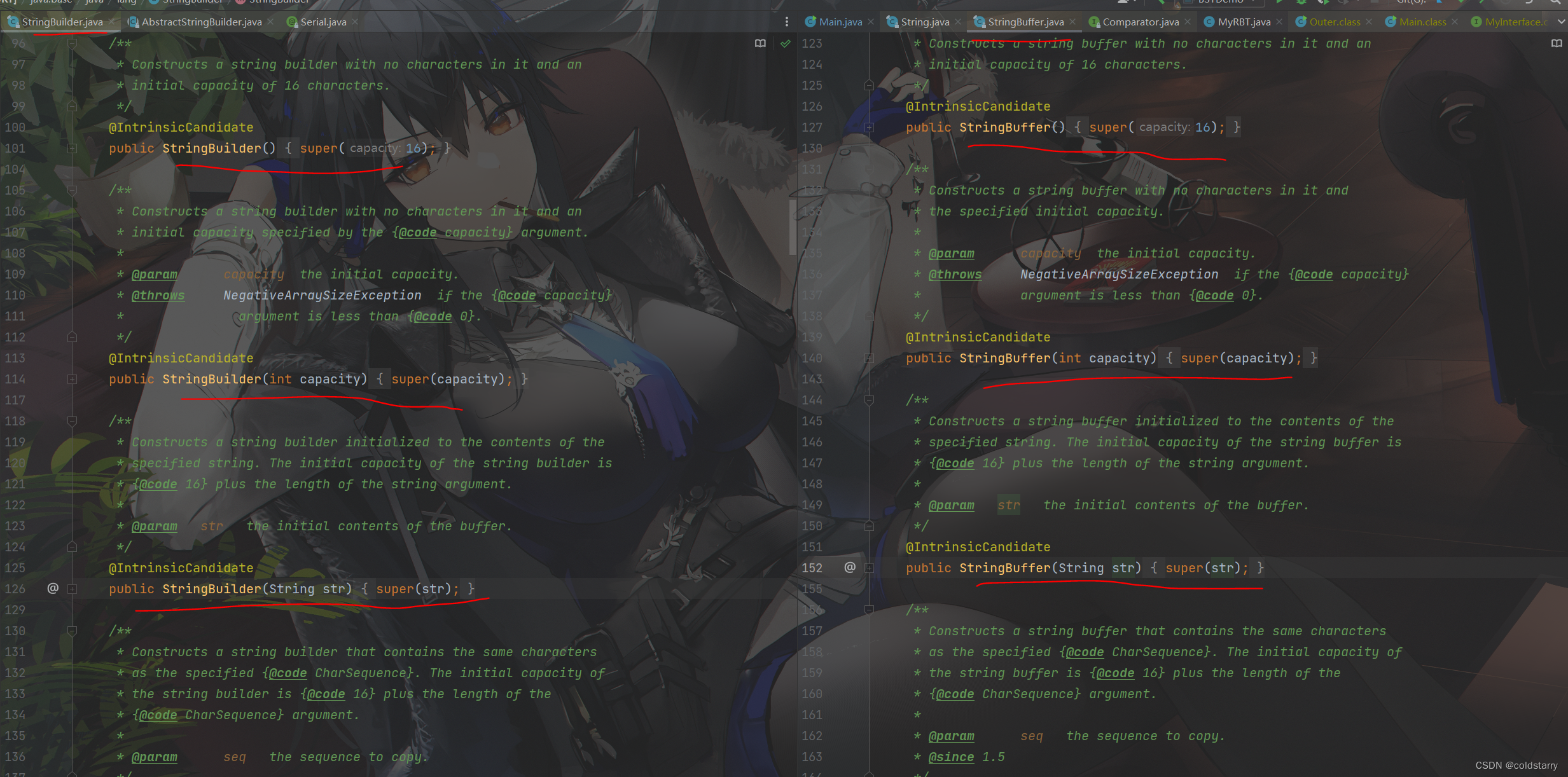
再看看他俩的父类初始化
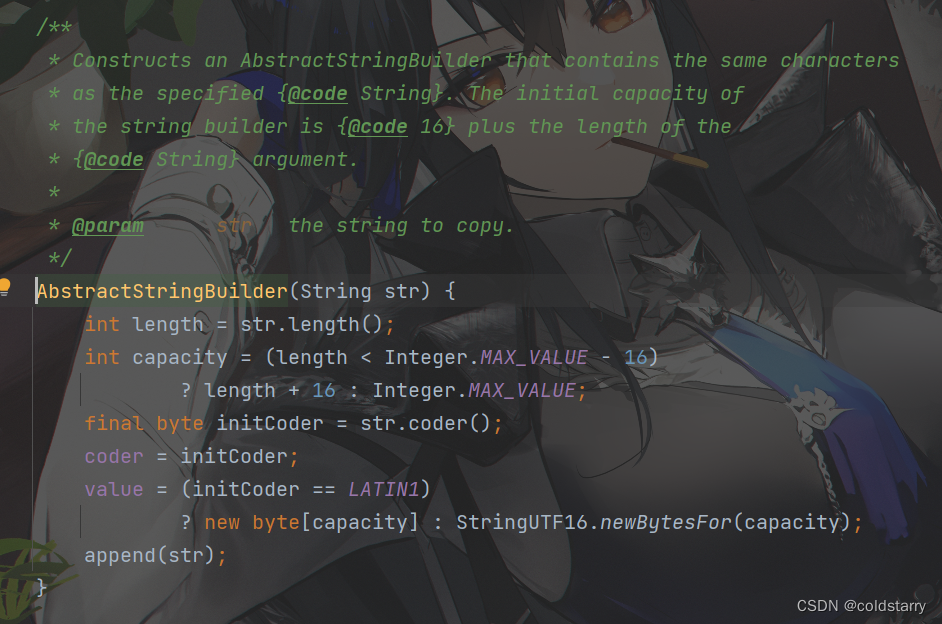
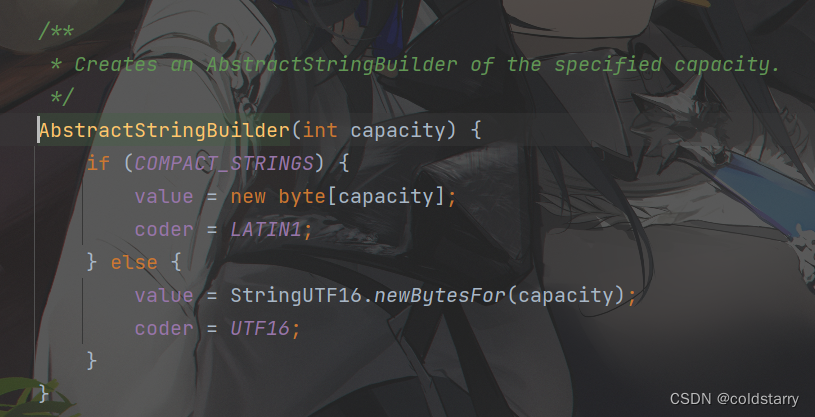
String初始化
无参构造
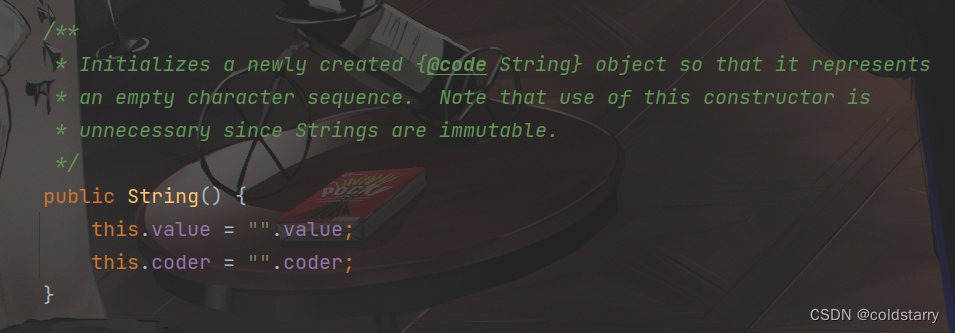
在我们new String()的时候,如果没有传入参数,那么就会调用这个构造方法,这里它的value并不会直接赋值为null,而是采用空字符串的value值,这样保证了value的值永远不会为null,value的长度可以为0,同样coder也是如此,正好符合前面所说的value字段上面添加的Stable注解的作用。
String(String original)
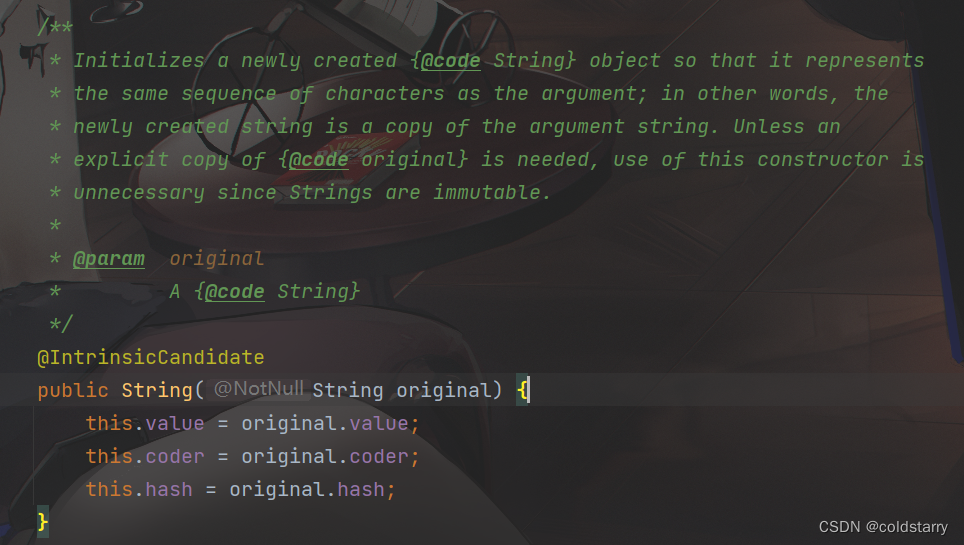
这个构造函数其实是一种拷贝,因为前面说过,String对象一旦创建,它是不可变的,所以它创建的String对象是基于源字符串的一份拷贝,所以如果需要对字符串进行拷贝,可以考虑使用该构造函数。
另外,它使用了HotSpotIntrinsicCandidate注解,这个注解是HotSpot虚拟机特有的注解,使用了该注解的方法,它表示该方法在HotSpot虚拟机内部可能会自己来编写内部实现,用以提高性能,但是它并不是必须要自己实现的,它只是表示了一种可能。这个一般开发中用不到,只有特别场景下,对于性能要求比较苛刻的情况下,才需要对底部的代码重写。
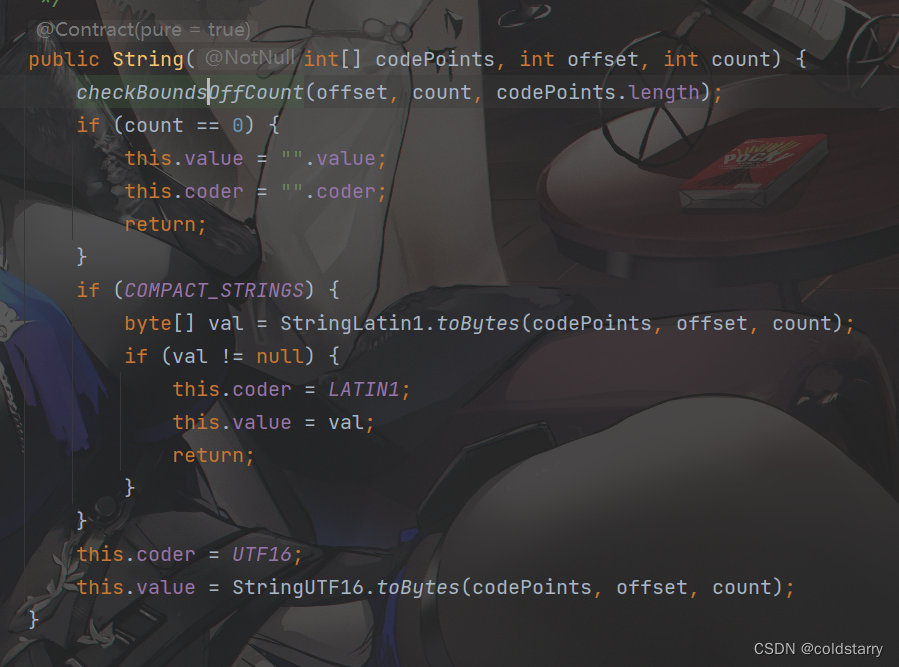
String(int[] codePoints, int offset, int count)
第一个参数是一个int数组,它里面的内容其实是存储Unicode的code point值,该方法的作用就是从codePints数组中截取一定长度的子数组构造字符串对象
- 先判断是否越界,
- 判断是不是为空,空的话走空构造逻辑
- COMPACT_STRINGS判断是否走压缩逻辑(单字节编码),会将int数组中的每一个int元素强制转换成byte类型。不过这里面的int值不是普通的值,它必须是Unicode的code point值
- 最后走UTF16编码,UTF16就是两字节编码
String查找
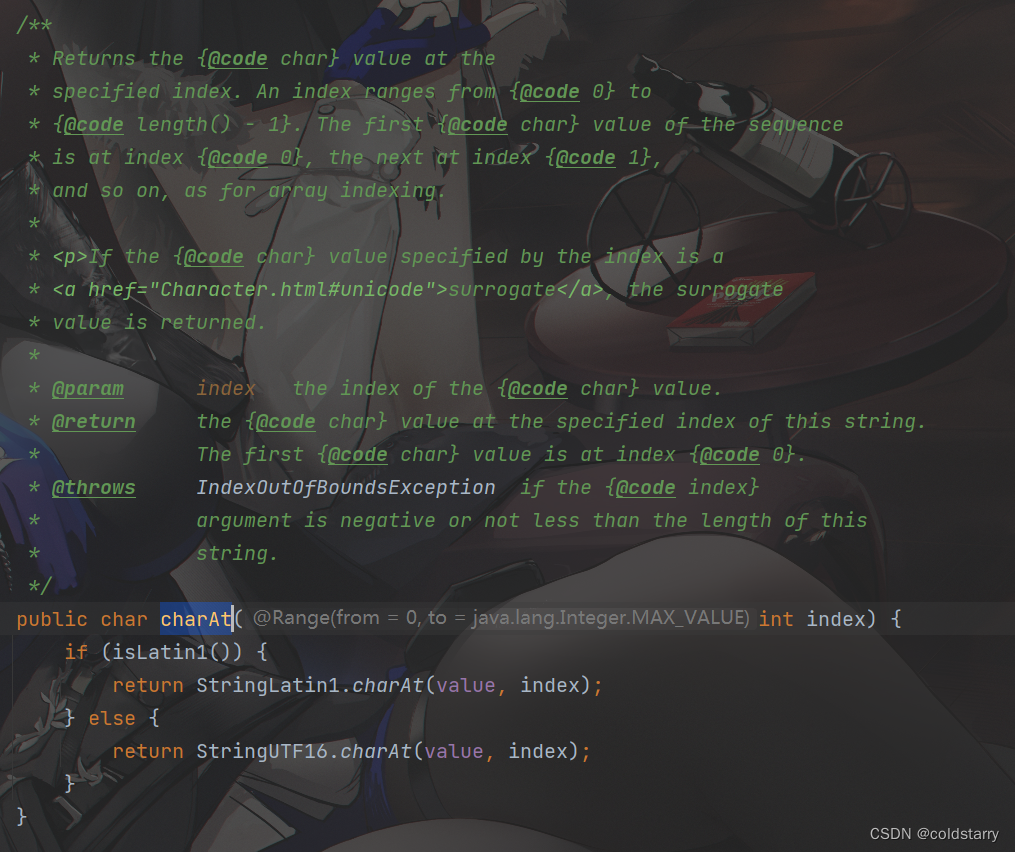
String charAt
根据索引查找,就是在value(数组)中找到对应的元素
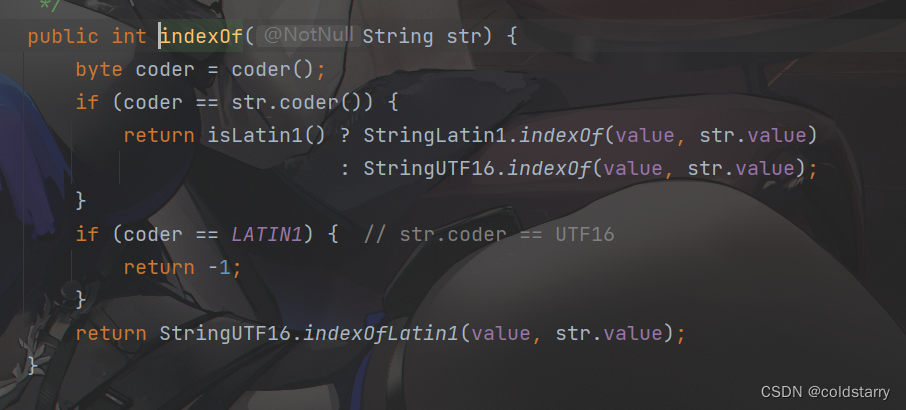
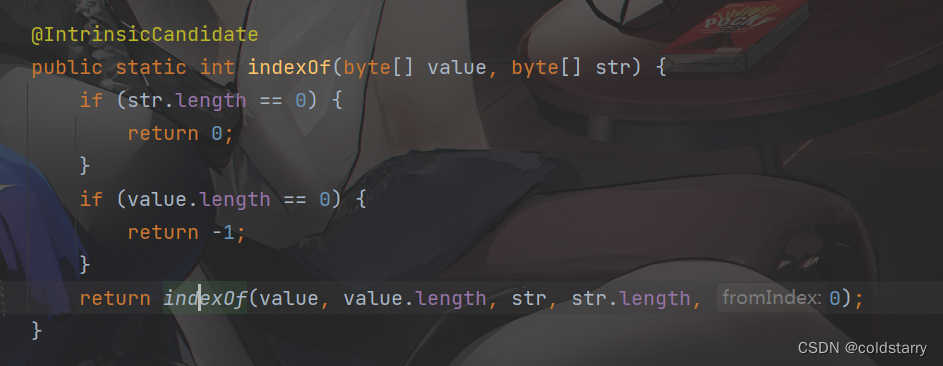
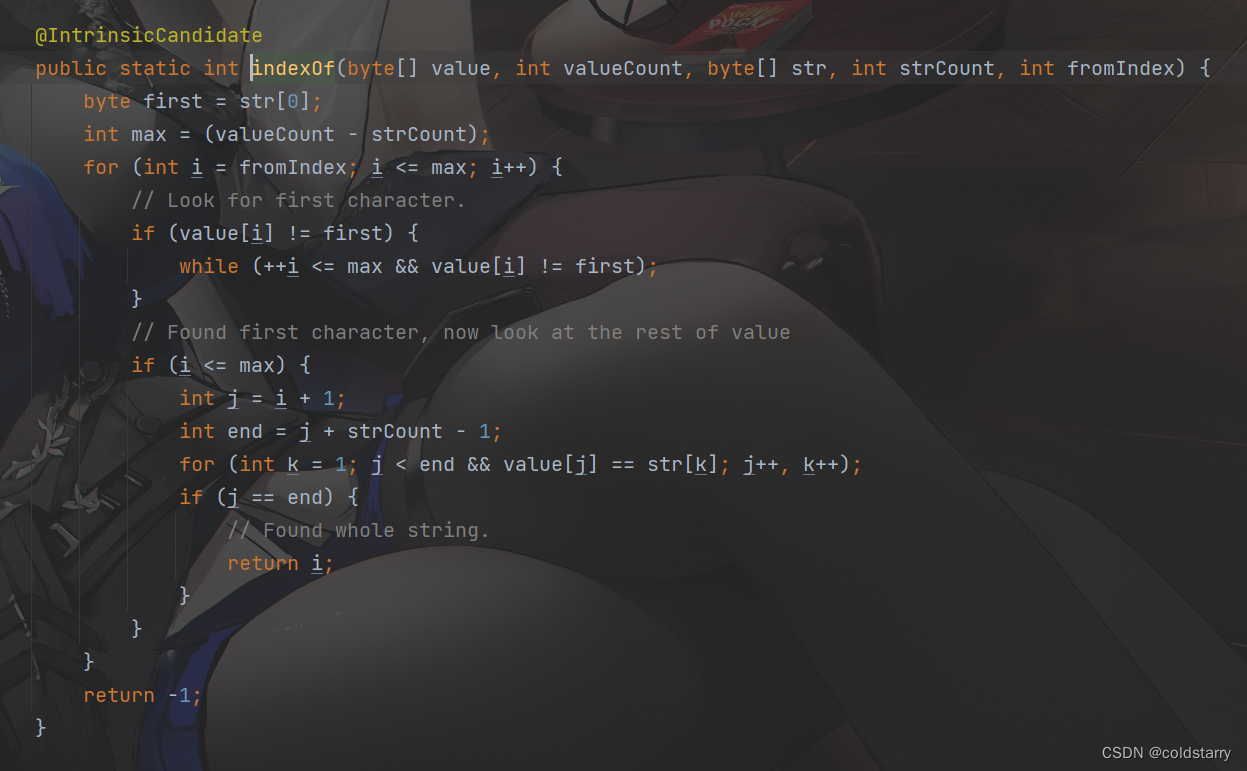
String indexOf
在value数组中查找,先找目标字符串的第一个元素,找到位置index以后,看index之后的K个长度(目标字符串的长度)是否都跟value数组一样,每确定一个元素往后索引+1,发现索引等于结束位置,认为查找了整个目标字符串(都一样)
这段代码看起来挺酷炫
equals
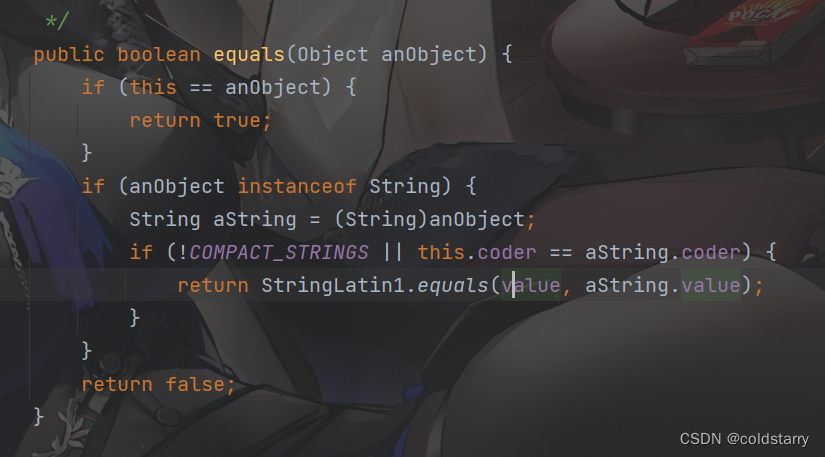
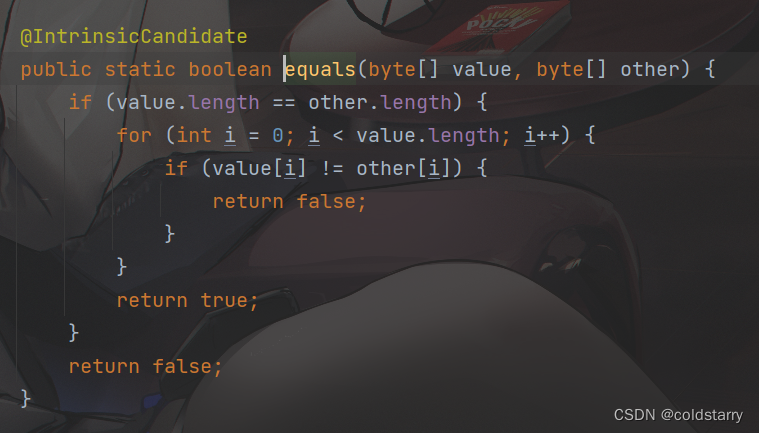
String equals
对比的是value数组中的值是不是一样
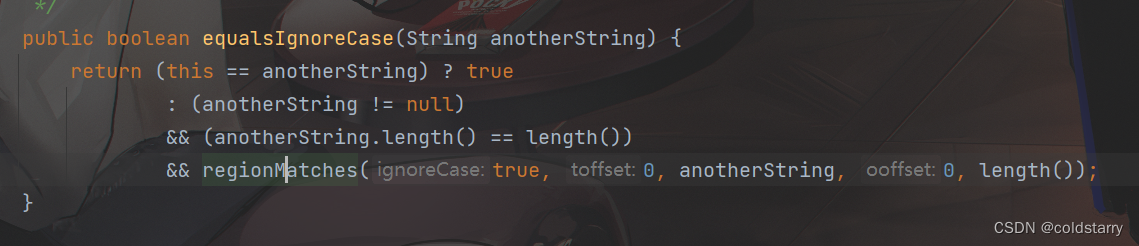
String equalsIgnoreCase
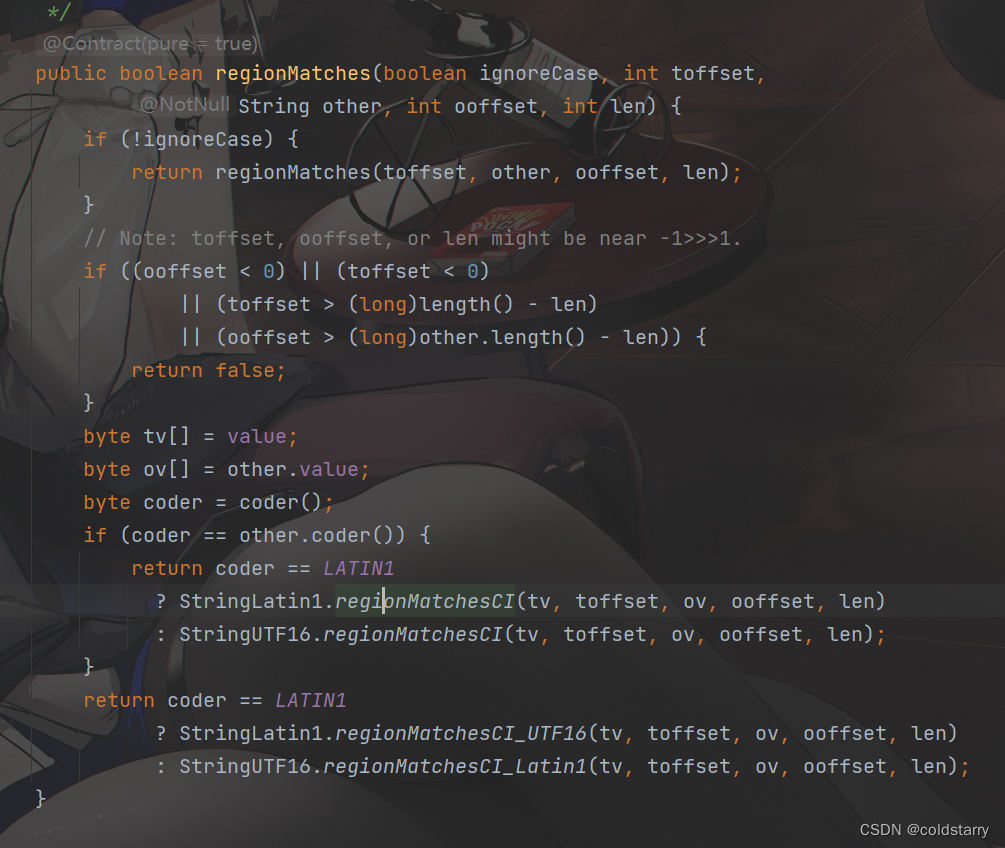
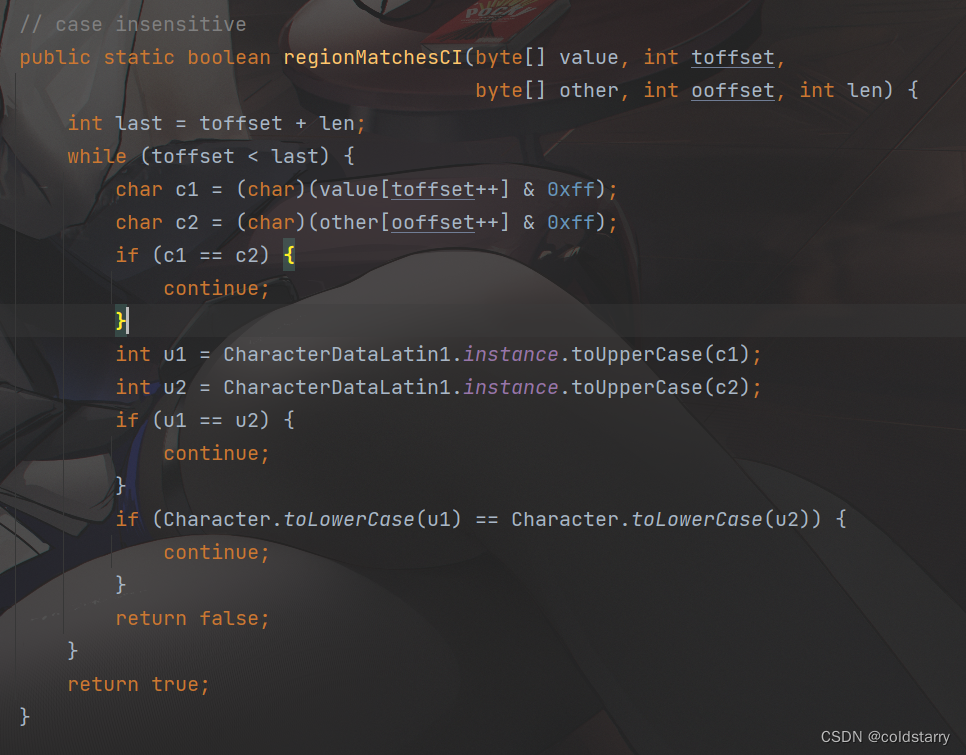
忽略大小写判断是否相等,实际上就是每个字符,忽略大小写比较,忽略的时候都变成大写或者都变成小写进行比较,不过 做的时候会根据 单/双字符集 来处理
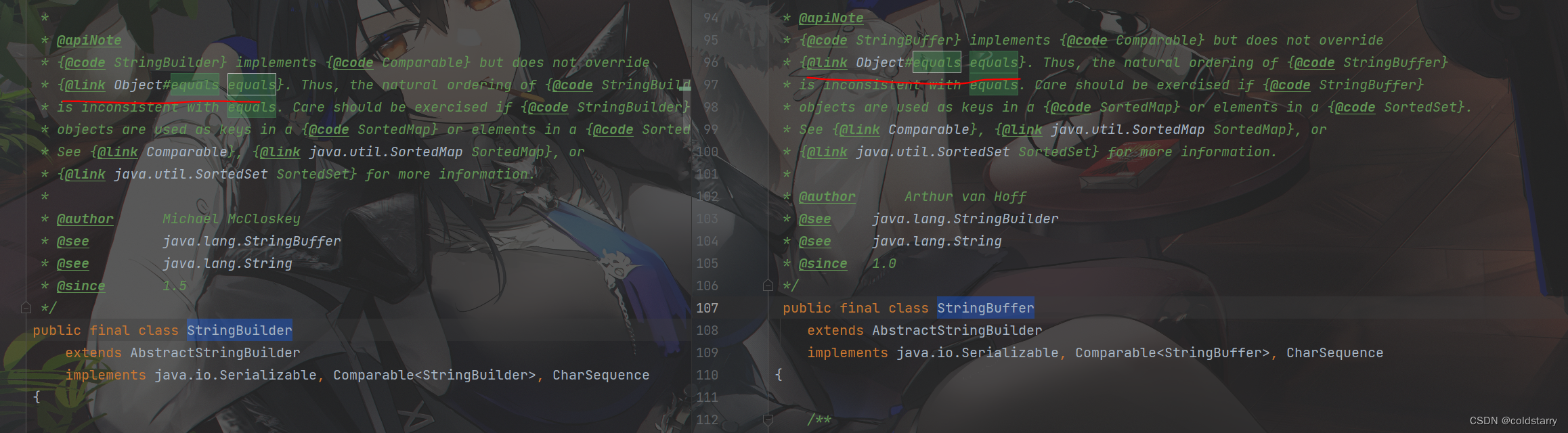
StringBuilder和StringBuffer equals
这俩货没自己写equals,用的是object的
compareTo
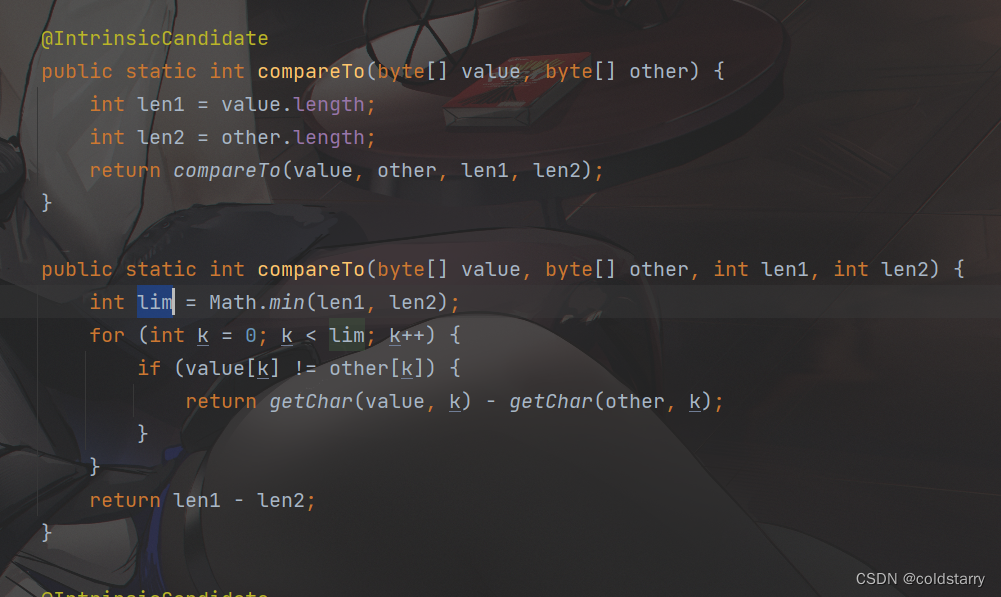
String compareTo
- 根据两个字符串的长度,先找到长度最小的那个
- 看在最小长度中谁的字符在字符码中最小,返回的是两个字符串的第一个不相等的字符的字符码的差
- 如果长度最小的字符串和另一个字符串的前部分完全一样(即一个字符串包含另一个字符串),返回的是两个字符串长度的差
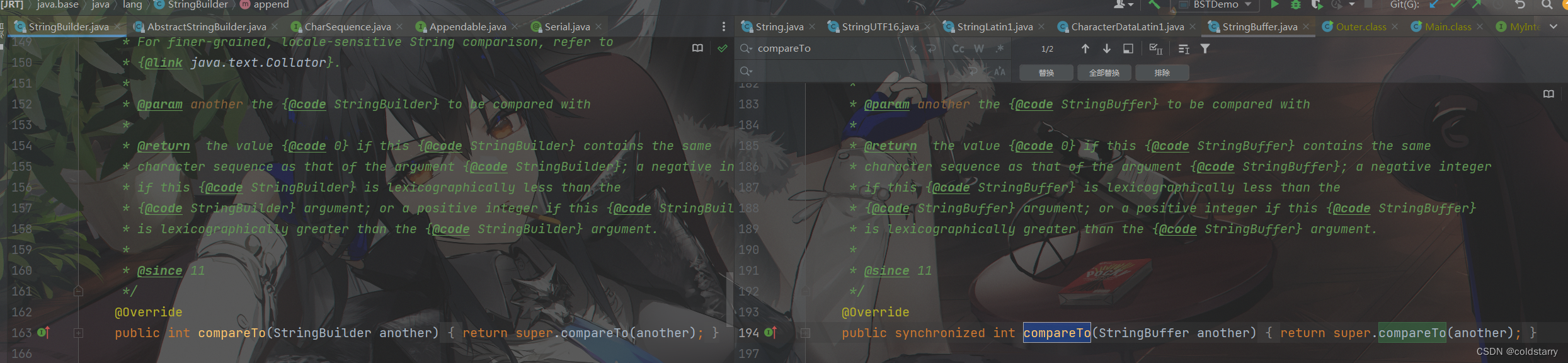
StringBuilder和StringBuffer compareTo
这俩货用的都是父类的compareTo
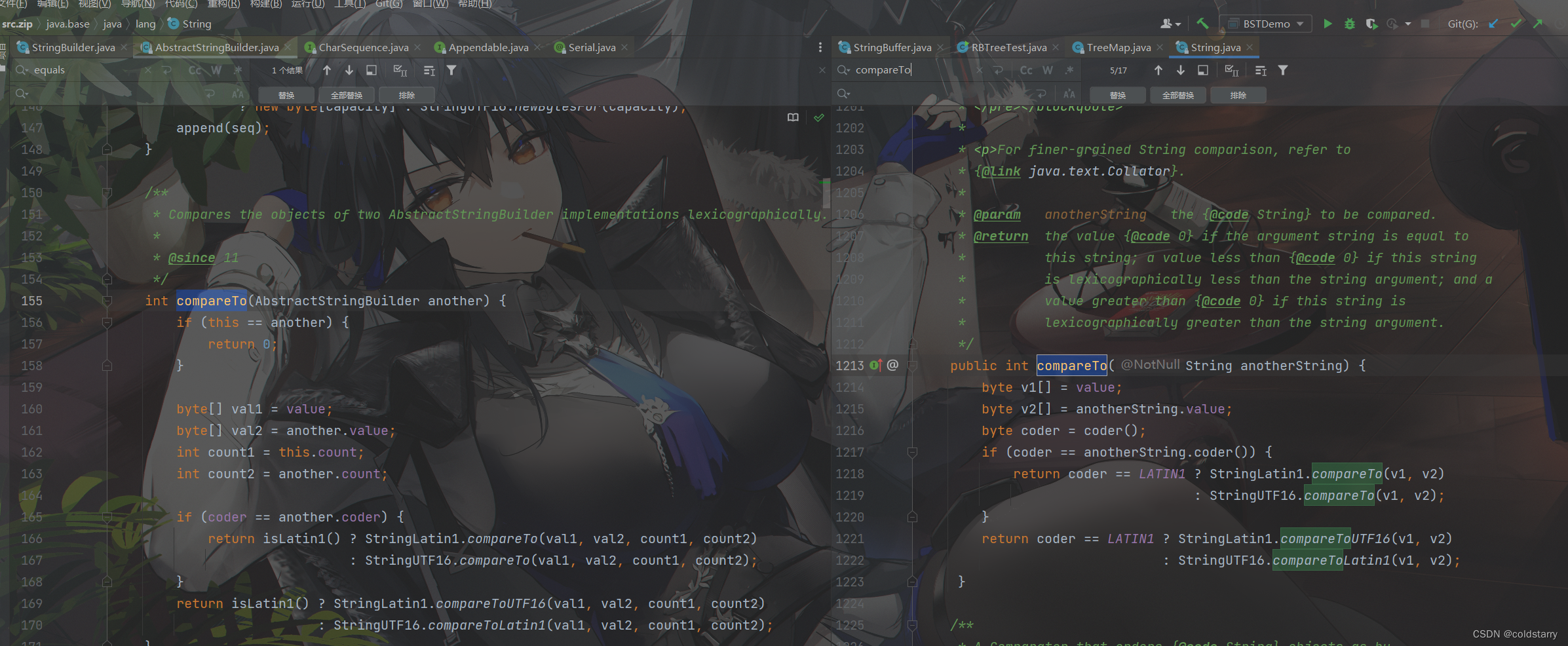
这俩父类AbstractStringBuilder的compareTo,跟String的一个路子
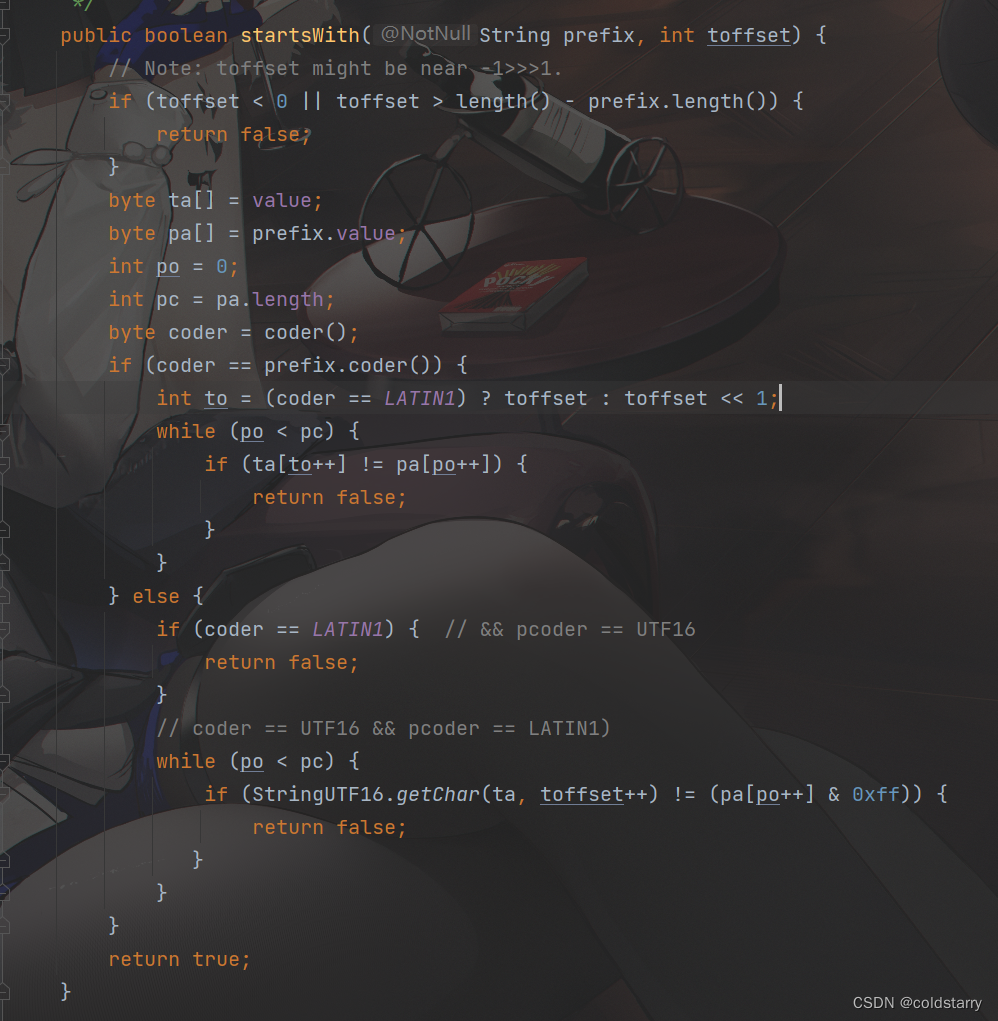
String startWith
判断编码,然后数组一个个元素对比,判断指定区间的每个元素是不是都相等
注意,那个toffset是开始对比的位置,值是0

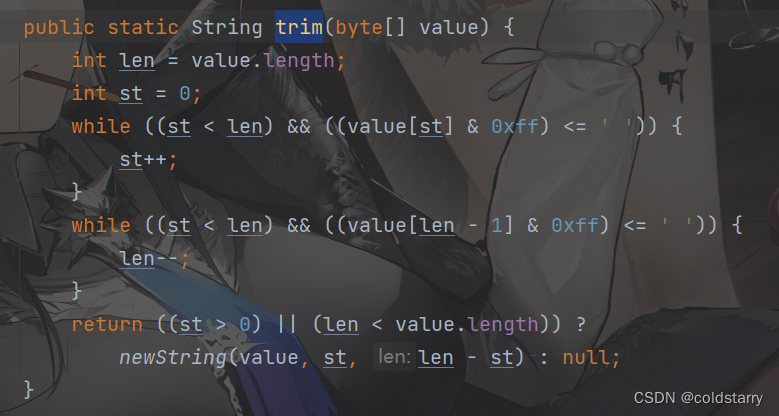
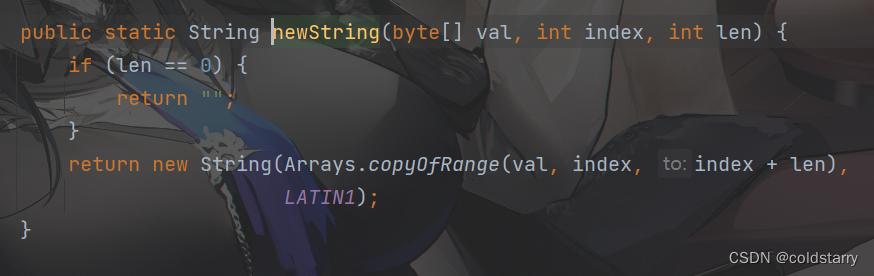
String trim
从前往后找到第一个非空的,从后往前找到第一个非空的,然后将非空的起止重新NEW 一个新的字符串并返回
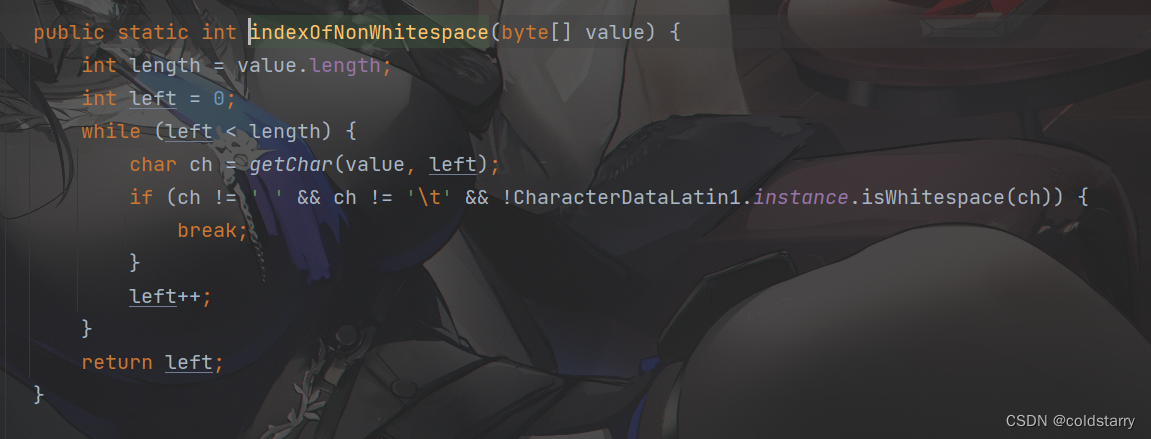
String isBlank
在String的value数组中,找到第一个非空的元素索引,如果全是空就一直往后找,直到数组长度,找到元素索引后,看是不是是等于数组长度,如果数组长度内全都是空,代表字符串就是个空的

append
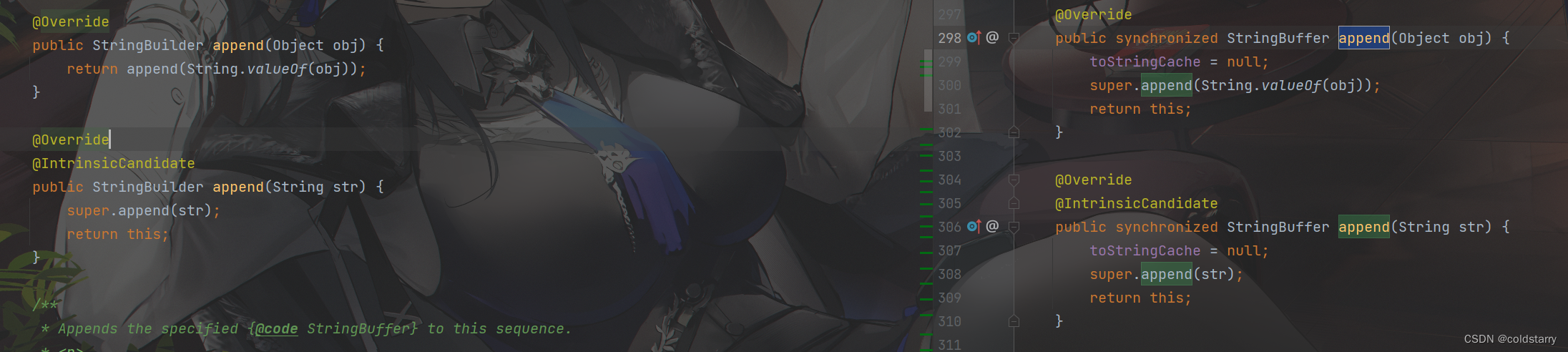
这俩的append都是使用的父类AbstractStringBuilder方法:
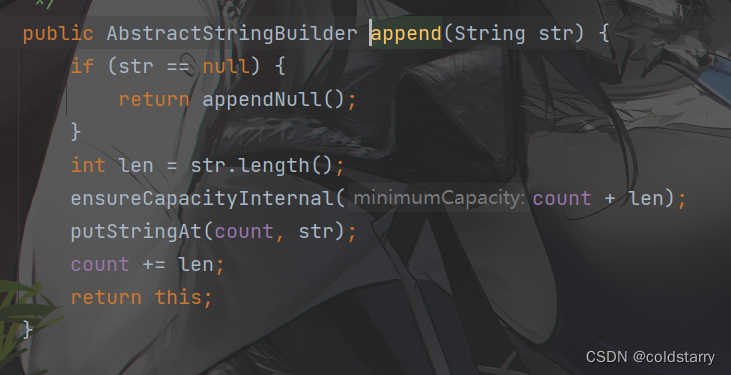
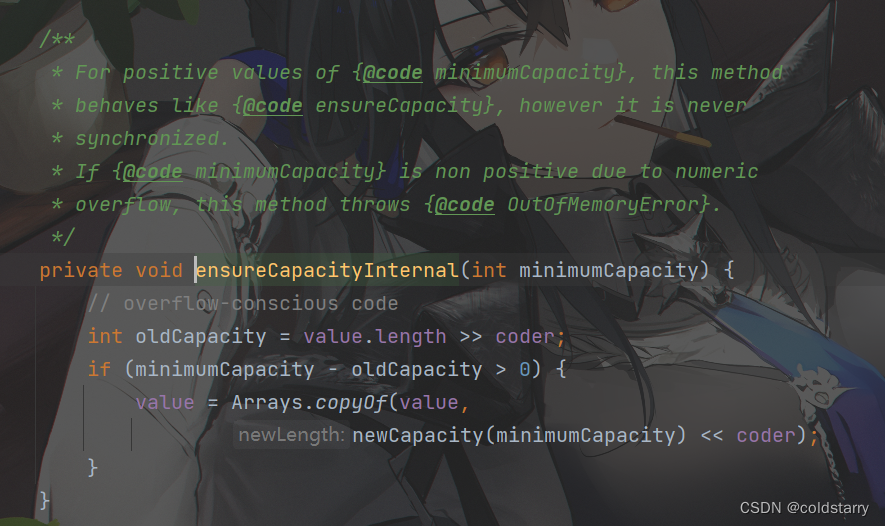
ensureCapacityInternal先判断是否小于阈值,如果小于,扩容
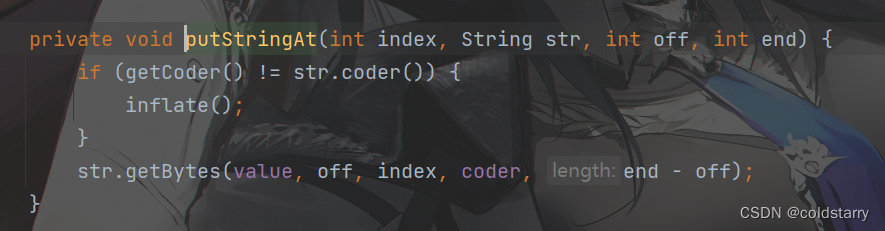
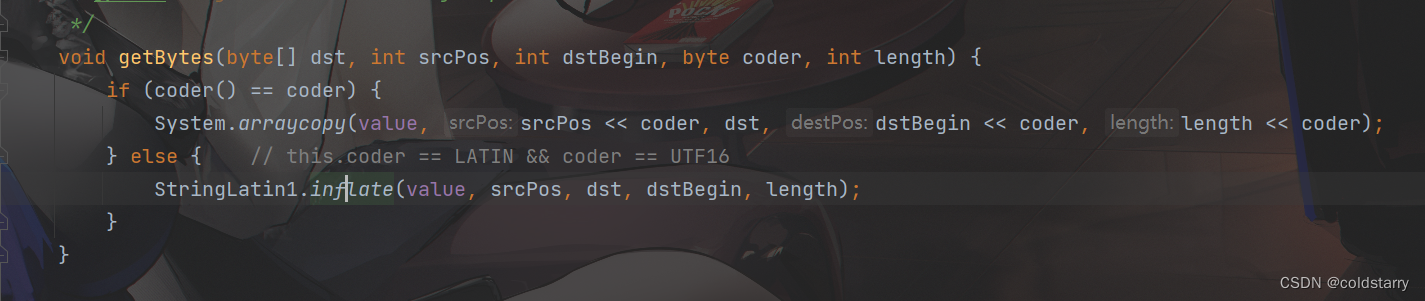
 在原有字符串结尾追加新的字符串,本质是对数组value的结尾进行内存拷贝
在原有字符串结尾追加新的字符串,本质是对数组value的结尾进行内存拷贝 
字符串相加
String sub1 = "123";
String sub2 = "456";
String string1 = "123" + "456";
String string2 = "123456";
String string3 = new String(string1);
String string4 = string3.intern();
String string5 = sub1 + sub2;
String string6 = sub1 + sub2 + sub1 + sub2;其中string1==string2返回true, string1==string3返回false, string1==string4返回true, string1==string5返回false
其中的原因,我们可以通过字节码解释:
0 ldc #2 <123> //从常量池中取出"123"的引用,在编译启动过程中,字符串字面量就会被存入常量池
2 astore_1 //保存到第一个变量,就是sub1
3 ldc #3 <456> //从常量池中取出"456"的引用
5 astore_2 //保存到第二个变量,就是sub2
6 ldc #4 <123456> //从常量池中取出"123456"的引用
8 astore_3 //保存到第三个变量,就是string1
9 ldc #4 <123456> //从常量池中取出"123456"的引用
11 astore 4 //保存到第四个变量,就是string2,由此,我们可以看出为啥string1==string2
13 new #5 <java/lang/String> //新建String对象,返回引用
16 dup //再次将上一个返回复制压入栈,一般创建新对象后都要这样
17 aload_3 //读取本地第三个变量,就是string1
18 invokespecial #6 <java/lang/String.<init>> //调用String构造器
21 astore 5 //保存到第五个变量,就是string3
23 aload 5 //读取本地第五个变量,就是string3
25 invokevirtual #7 <java/lang/String.intern> //调用原生intern方法
28 astore 6 //保存到第六个变量,就是string4
30 new #8 <java/lang/StringBuilder> //对于字符串+运算,创建一个StringBuilder
33 dup
34 invokespecial #9 <java/lang/StringBuilder.<init>>
37 aload_1
38 invokevirtual #10 <java/lang/StringBuilder.append> //调用append方法,相当于append(string1)
41 aload_2
42 invokevirtual #10 <java/lang/StringBuilder.append> //调用append方法,相当于append(string2)
45 invokevirtual #11 <java/lang/StringBuilder.toString>
48 astore 7
50 new #8 <java/lang/StringBuilder>
53 dup
54 invokespecial #9 <java/lang/StringBuilder.<init>>
57 aload_1
58 invokevirtual #10 <java/lang/StringBuilder.append>
61 aload_2
62 invokevirtual #10 <java/lang/StringBuilder.append>
65 aload_1
66 invokevirtual #10 <java/lang/StringBuilder.append>
69 aload_2
70 invokevirtual #10 <java/lang/StringBuilder.append>
73 invokevirtual #11 <java/lang/StringBuilder.toString>
76 astore 8在当前JDK版本的环境下,字符串相加运算已经被编译器优化成为StringBuilder. 之前因为一个相加就生成一个String,导致效率很低。当前已经优化。但是注意,在循环调用中,还是得用StringBuilder。如果像下面那么写的话,每次循环生成一个StringBuilder还有String,效率更低的。
String str = "";
for(int i=0;i<10;i++) {
str = str + "1";
}toString
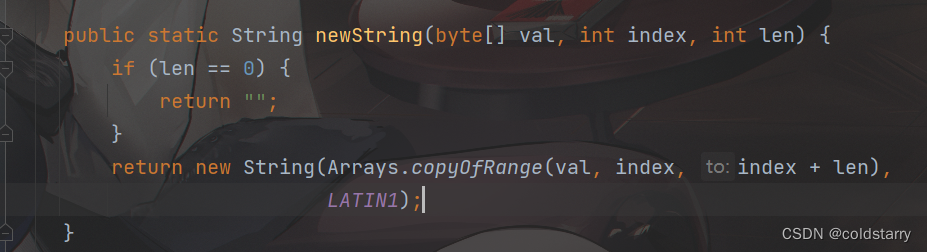
StringBuilder的toString方法,就是根据value重新生成一个新的String
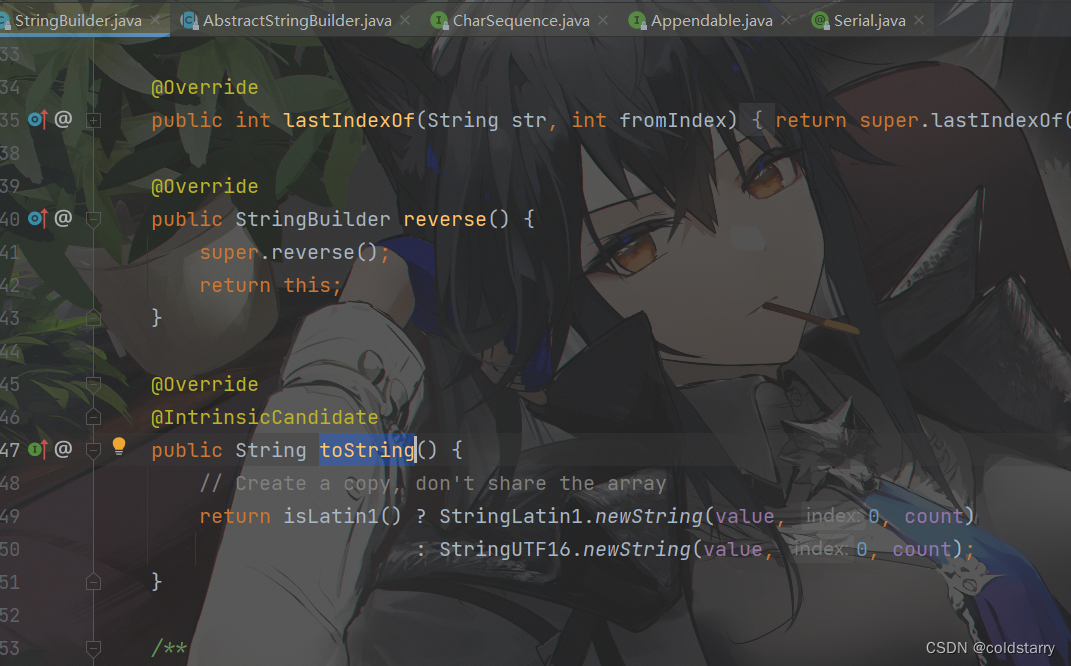
insert
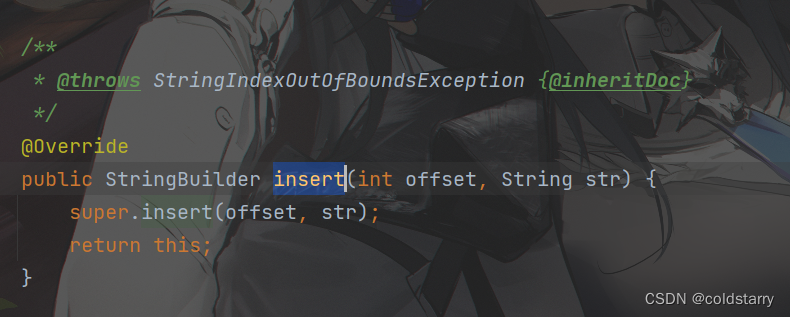
- ensureCapacityInternal判断扩容
- shift把数据往后移动一下,为新增的数据留个空间
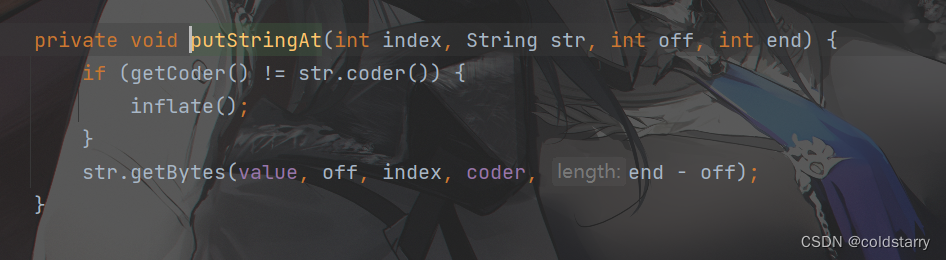
- putStringAt上面已经看过源代码了,内存拷贝,把新增的数据挪到第二步预留的地方中
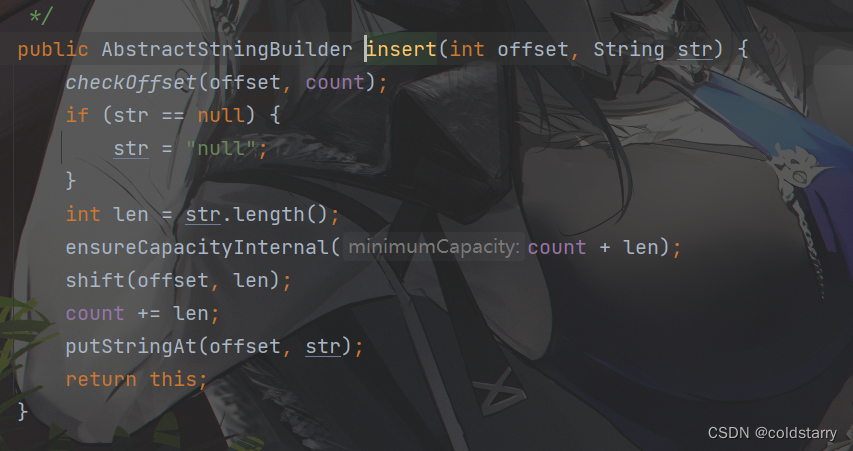


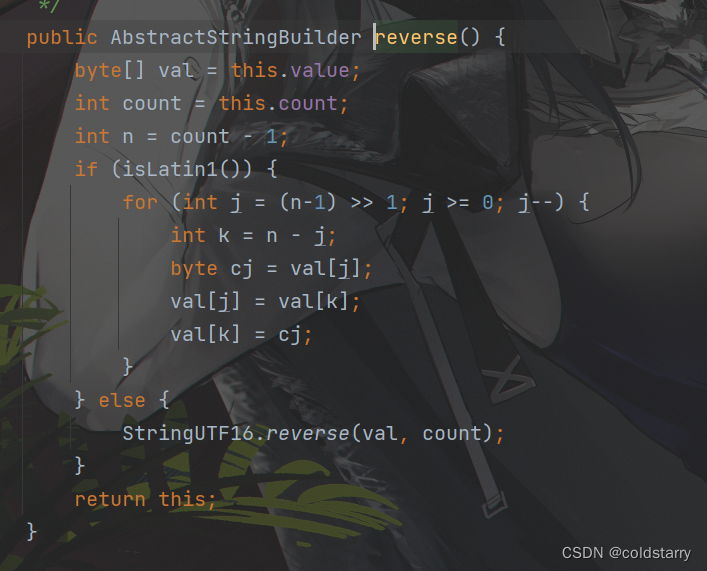
reverse
用的父类的reverse方法

找到数组的中间位置j,然后j--,用n-j的方式找到j关于中间值的对称值,并用第三个变量做两个元素的替换,达到反转的目的
参考文档:
String、StringBuffer、StringBuilder从源码分析不同_星辰与晨曦的博客-优快云博客_stringbuffer和stringbuilder的源码区别

















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









