




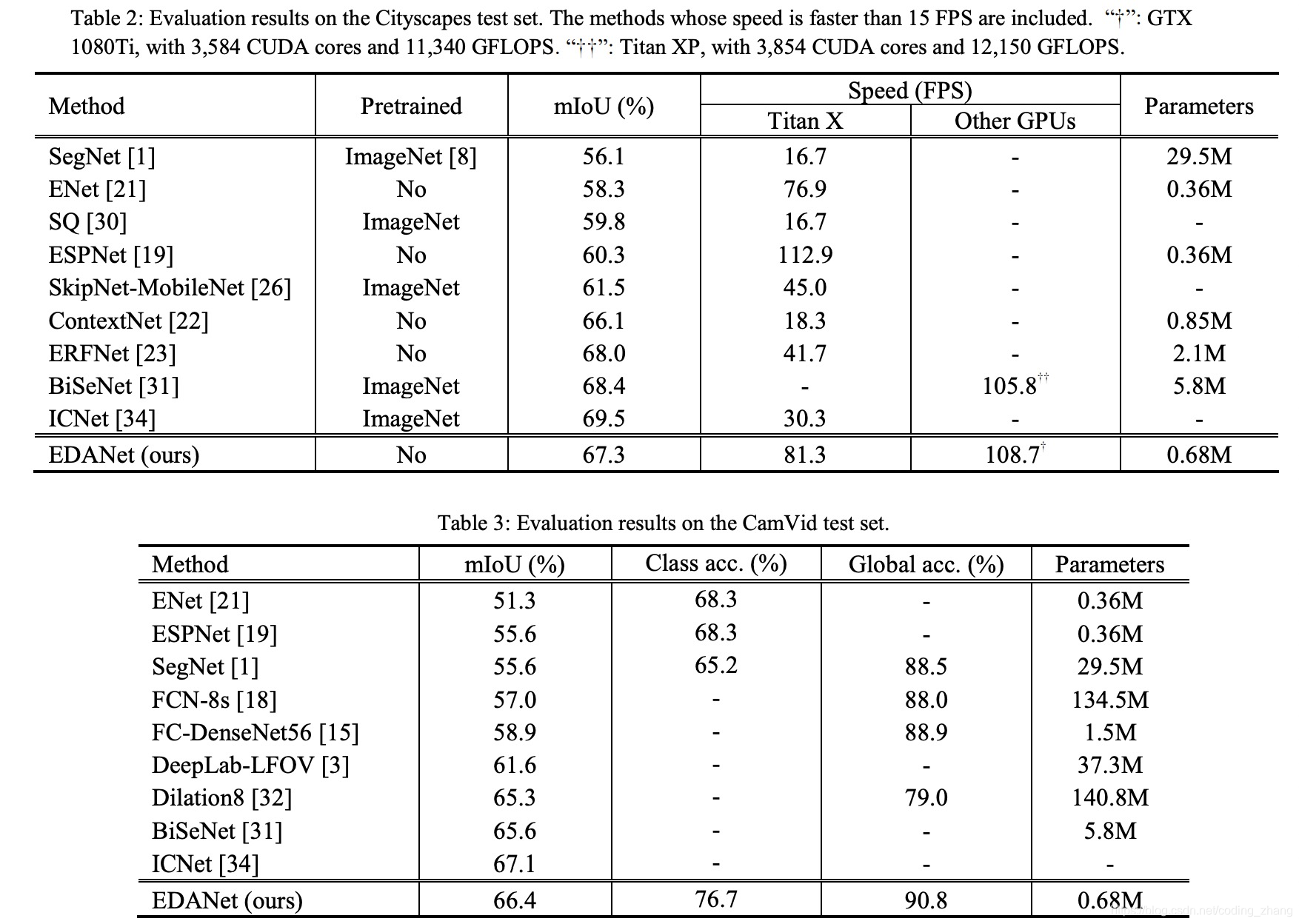
 EDAnet是一种高效的实时语义分割网络,利用不对称卷积、空洞卷积和密集连接,实现了速度与精度的良好平衡。在GTX1080Ti上达到108FPS,精度与ICNet相当但速度快两倍。未使用预训练模型和额外上下文模块,展现了强大的独立性能。
EDAnet是一种高效的实时语义分割网络,利用不对称卷积、空洞卷积和密集连接,实现了速度与精度的良好平衡。在GTX1080Ti上达到108FPS,精度与ICNet相当但速度快两倍。未使用预训练模型和额外上下文模块,展现了强大的独立性能。
论文地址:https://arxiv.org/pdf/1809.06323.pdf
作者:Shao-Yuan Lo1 Hsueh-Ming Hang1 Sheng-Wei Chan2 Jing-Jhih Lin2 1 National Chiao Tung University 2 Industrial Technology Research Institute sylo95.eecs02@g2.nctu.edu.tw, hmhang@nctu.edu.tw, {ShengWeiChan, jeromelin}@itri.org.tw
1. 首先看一张论文里的贴图:
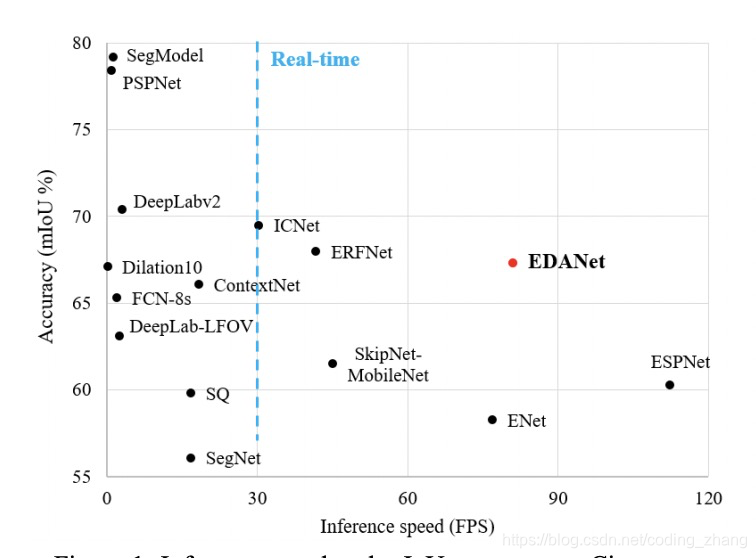
该方法EDAnet比enet更快,而且accuracy也更高。
EDAnet采用了Asymmetric convolution,加上空洞卷积和dense connectivity,在速度和准确度上做到了一定的平衡。比icnet快2倍,但是精确度和icnet差不多。而且EDAnet没有采用预训练模型,也没有加入后处理策略,也没有加入额外的context module。所以效果还是非常客观的。在GTX 1080Ti上也能到达108FPS。其中Asymmetric convolution就是想二维的卷积分离成多个一维卷积的组合。譬如原先是n*n的,转换成n*1和1*n.这样子做可以极大的减少参数数量,但是精确率可以降低的比较少。EDAnet也融入了densenet的结构 。dense connect能够很好的提取不同layer的特征并聚合muti scale信息,这对分割任务是非常有帮助的。dense connect也能减少参数量,原因在于由于dense connect的存在,我们每一层layer需要的channel就会变少。空洞卷积则是在保证不损失空间信息的情况下,保证图像的分辨率。
2. 以下是几种网络:
高准确率:
unet ---对称结构的encoder,decoder
DeconvNet ---非对称结构测encoder,decoder
Dilation10 ---context module by dilated convolution 提取muti scale信息
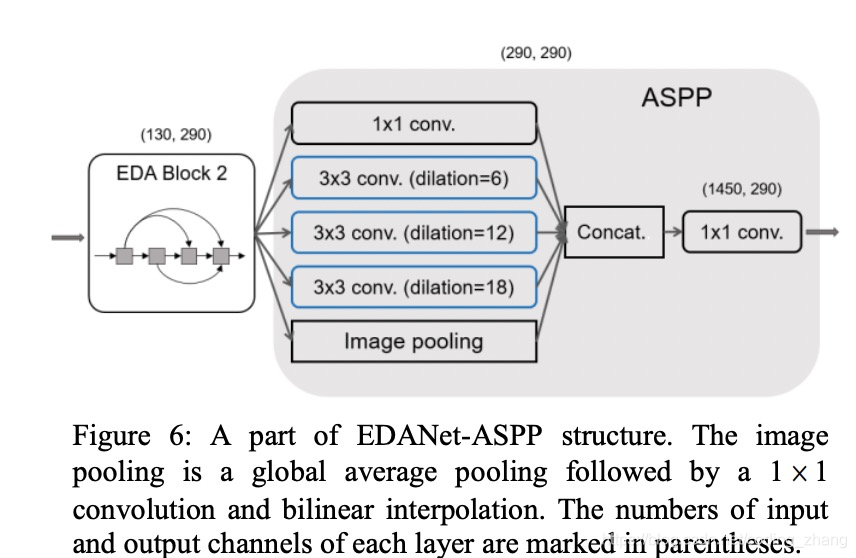
DeepLab --- 提出atrous spatial pyramid pooling (ASPP),采用并行filter 和different dilation rates 来获取muti scale 的信息表达
实时网络:
enet --- 采用了残差链接,通过所见卷积filter来减少计算量
espnet ---采用了efficient spatial pyramid (ESP)模块,在spatial pyramids之前采用point-wise convolution 减少计算消耗。(xception)
icnet 和bisenet
密集连接的网络:
FC-DenseNet ---encoder是densenet。decoder采用了传统的skip connections
SDN --- backbone采用的densenet加上堆叠的deconvolution
3. 网络结构:
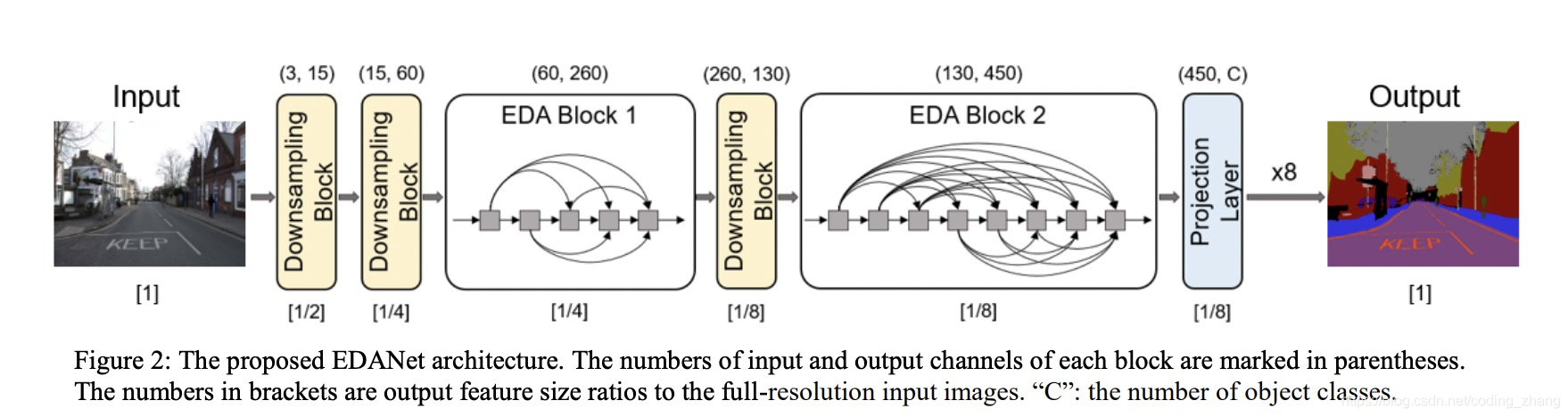
EDAnet 没有decoder部分。个人觉得没有decoder是网络采用了dense connect,计算量总体来说已经有一定量了,如果再加decoder的话,计算量就会更大。
EDAmodule结构图如下:
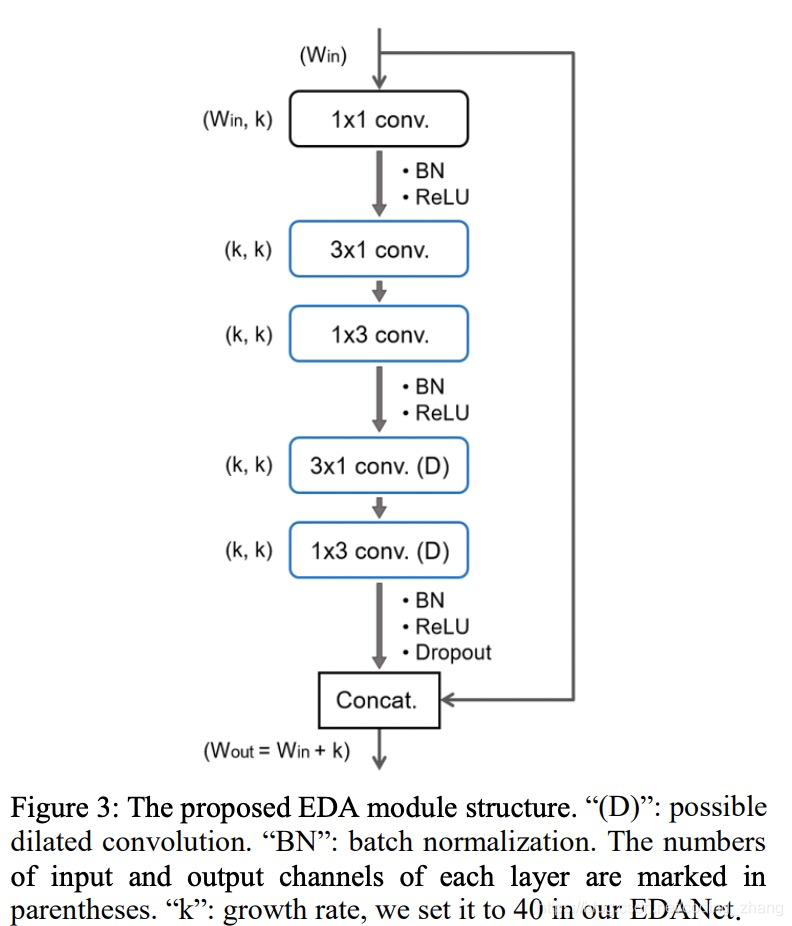
EDA module 由一个point wise convolution layer和一对Asymmetric convolution组成。
Point-wise convolution layer:1*1 的convolution先把通道数降下来。减少参数和计算量
Dense connectivity:
每个EDA block中的EDA module会采用dense net的连接方式。多个EDA module连接相当于多个3*3连接,感受视野会变大,不同的感受视野和dense connet相当于mutil scale的信息有所融合。
4. 网络设计考虑
- downsampling 策略:
采用了enet中initial block,并对其做了扩展。
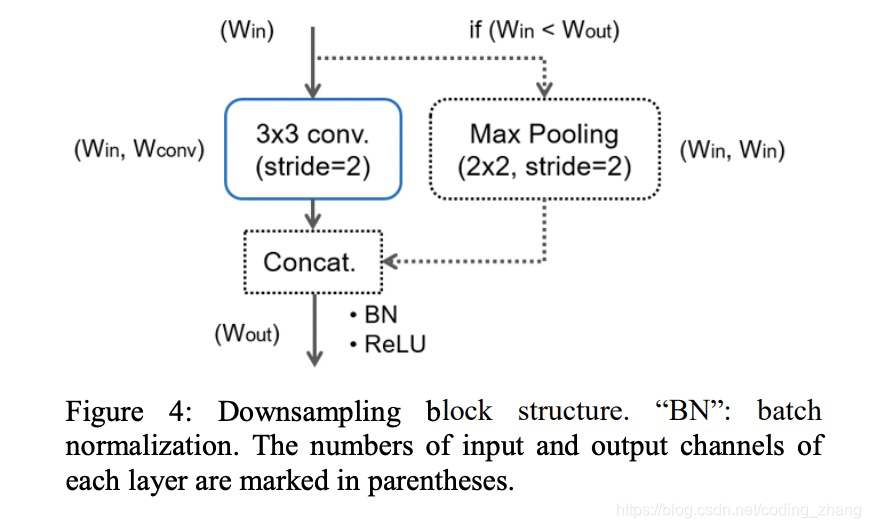
if Wout<Win then 采用3*3 conv s =2 and Wconv = Wout
if Wout>Win then 采用 2*2 maxpooling s =2 并且输入的feature和输出feature 加在一起,Wconv = Wout -WinEDAnet最后的特征图downsampling到1/8大小,这样保留的信息更充分。
- Decoding策略:
经过1*1的卷积获取output channel =classes num 数的feature map(应该是包含背景类,还需代码确认)。直接经过一个factor = 8 的bilinear interpolation upsampling 到原图大小。
- Composite function
采用后置激活函数的方式。参考(Deep residual learning for image recognition CVPR, 2016)这样做,BN可以merge 之前conv的信息,加快inference速度。并在relu和concatenation操作之间采用了dropout。rate =0.02
5. 实验和训练
采用Adam optimization,lr =0.0001,bs =10
学习率策略:poly learning rate policy
(1 − ????/max _????)????? (power为上标)with power 0.9 and initial learning rate
0.0005
class weight策略:采用enet中的策略:
?????? = 1⁄???(?????? + ?), where weset k to 1.12
数据增强:random horizontal flip, the translation of 0~2 pixels on both axes作者网络feature map数量比借鉴了erfnet网络。
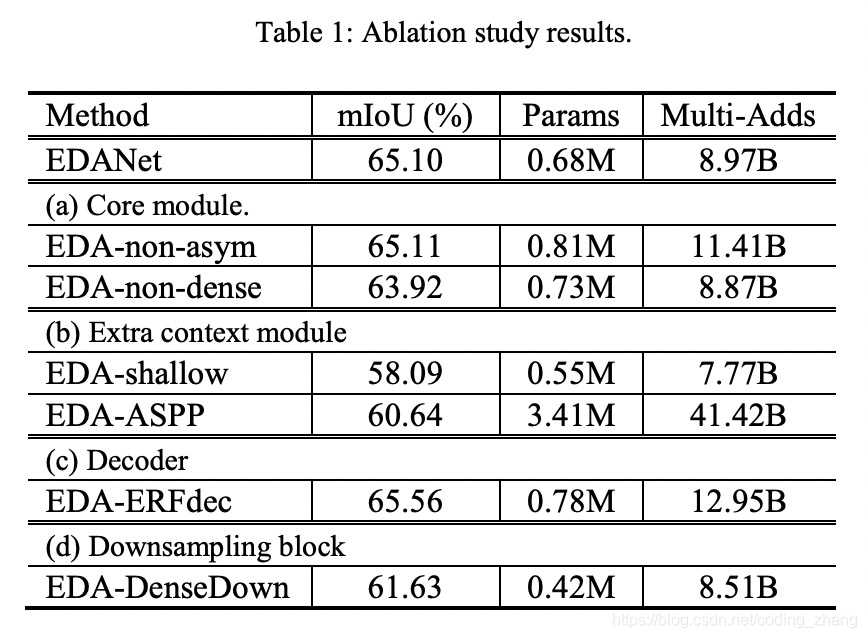
- 对比asymmetric convolution对网络计算量上的影响
没有采用asymmetric convolution的网络,实验结果表明采用asymmetric convolution的网络和不采用asymmetric convolution的网络准确率差不多的情况下,不采用asymmetric convolution的网络多了27%的计算量。
- 对比dense connet对于模型准确率上的影响
没有dense connet的网络会比有dense connet的网络准确率低1.18%
- 对比了dense connet 和ASPP模块在muti scale上的性能
- 对比了不同的downsampling策略
结果如下:
- 对比其他网络性能

















 333
333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









