




 本文探讨缓存技术的重要性,对比Memcache和Redis的优缺点,介绍缓存代理的作用以及一致性解决方案。针对数据一致性,讨论了Cache aside模型、多级缓存策略和缓存击穿的应对方法。最后分享了缓存的最佳实践,包括优化缓存设计、处理热点数据和防止不一致性的方法。
本文探讨缓存技术的重要性,对比Memcache和Redis的优缺点,介绍缓存代理的作用以及一致性解决方案。针对数据一致性,讨论了Cache aside模型、多级缓存策略和缓存击穿的应对方法。最后分享了缓存的最佳实践,包括优化缓存设计、处理热点数据和防止不一致性的方法。
缓存是架构当中非常重要的部分,高性能场景绕不开的话题
缓存的底层几个思想:空间换时间,局部性原理
缓存选型
技术选型标准,永远是最适合的是最好的,要实事求是,作为一个架构师最核心的还是tradeoff,永远不存在最优解,你是架构师就告别了酷炫都是柴米油盐的权衡。简单展开一下,不感兴趣的直接跳过
-
选择你最熟悉,你无法驾驭啥都白扯,技术收益=技术天花板*适合程度*熟悉程度
-
社区是否活跃,不要陷入
alone in the dark,可以去StackOverFlow等搜下内容量和新来判断 -
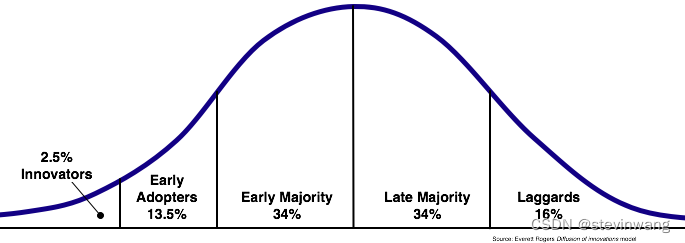
技术是否还在持续成长,好的技术永远跑在业务前面,技术的生命周期必须显著长于项目的生命周期,意味着项目还可以持续吸收技术红利,如BigTable、MapReduce、GFS。这是一个大topic,你是否还记得下图
-
结合业务思考,时间是检验真理的唯一标准,在公司这个商业机构里面,最最底层永远是ROI、人效、利润等概念。距离这些越近对他们影响越大你的项目就越有价值
-
一定要验证再试用,小范围验证,从业务范围和团队梯队角度等考虑。要重视经验类的东西,注意是重视而不是拘泥于。经验的关键是要扩大输入,多交流,别人家是怎么做的
-
要多学习,掌握各不同开源方案的优缺点,这样在你需要做决策的时候才能提升正确的概率,这是根本
Memcache

-
是非常非常不错的方案之一,性能
-
全内存不支持持久化
-
value默认大小不超过1m,可以通过参数调,只能存储kv没有其他数据结构
-
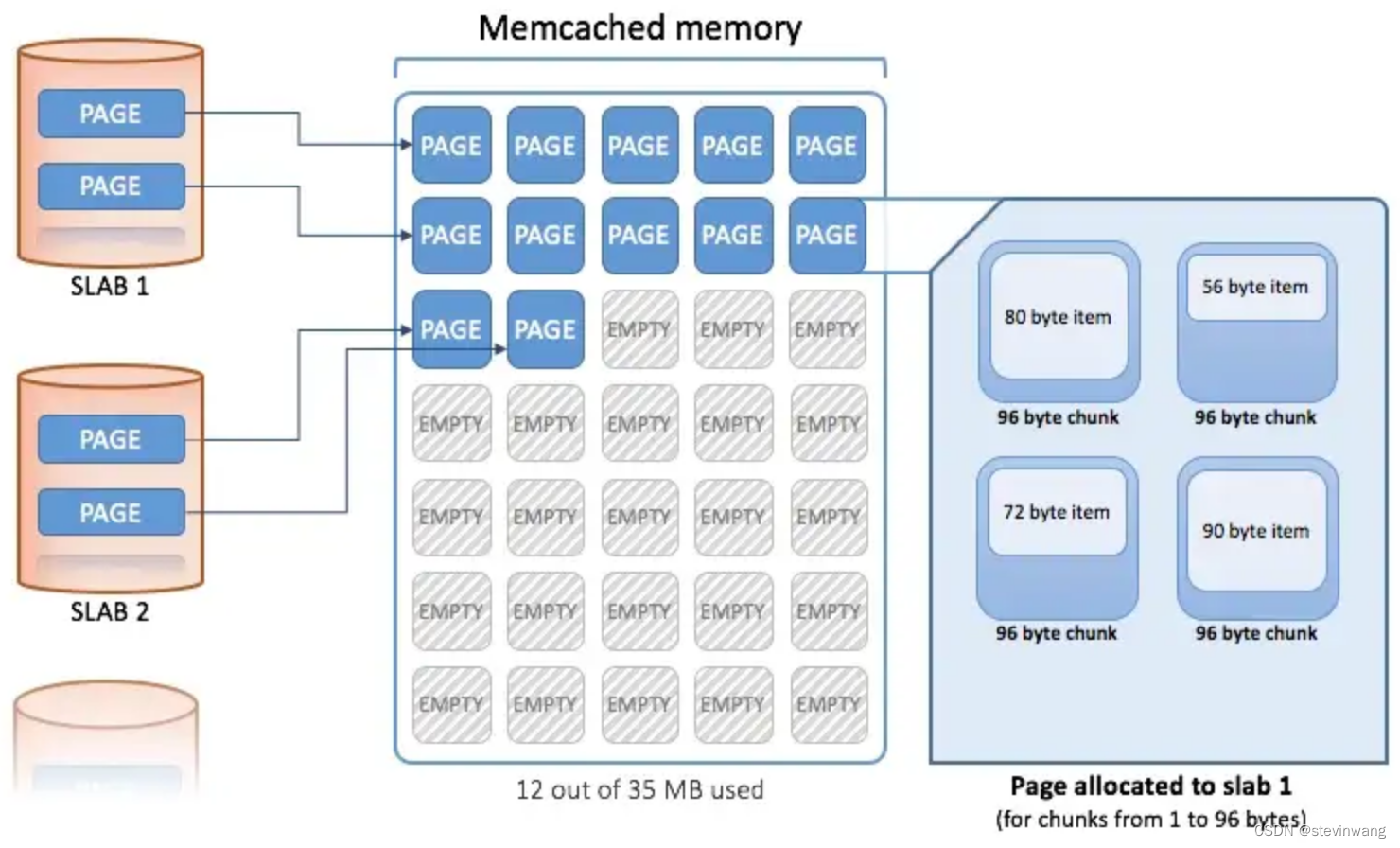
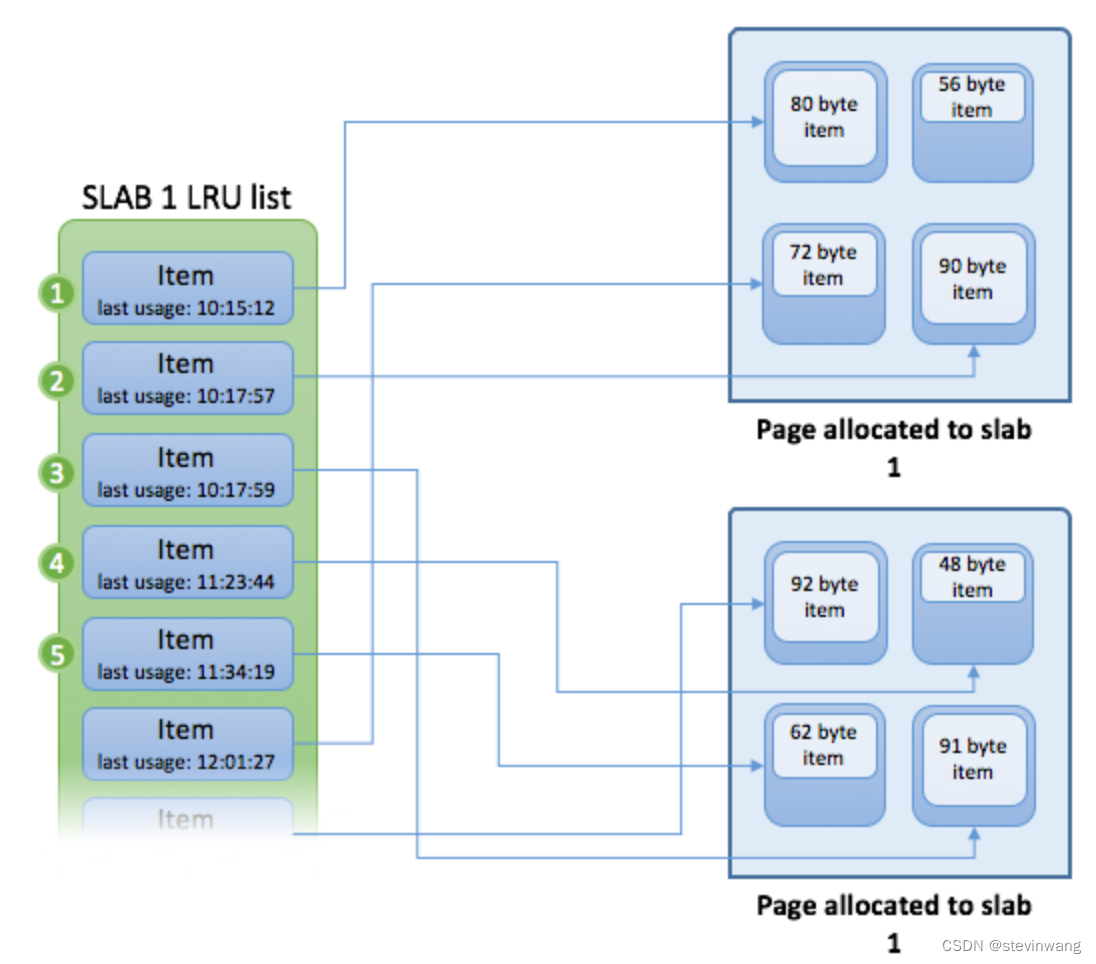
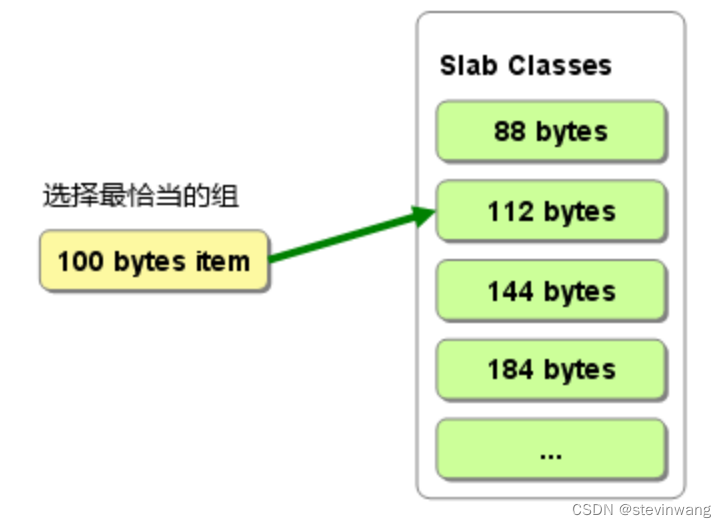
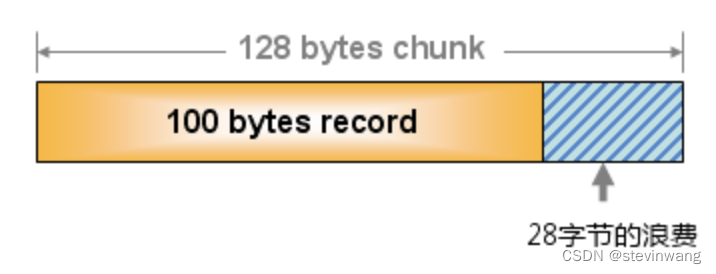
memcache比较经典的内存池方式slabs管理(图1/2/4)如果插入item的时候先选择刚刚大于自己size的slab class(图3),这就存在了浪费(图5)的可能性这个依赖于数据分布,解法就是优化合理的增长因子
-
Page:实际物理空间,默认1m的固定大小,这是为何只能默认最大为1m的item
-
Chunk->Slab :同样大小的chunk称之为slab(图4)
-
-
也可以手动移除slab,方式热点导致内存不足做出不符合预期的LRU动作,推荐一篇说的不错 Journey to the centre of memcached

Redis
有丰富的数据结构可以用,好处是有较丰富的数据结构 list set等,但是没有内存池会存在碎片,可以用jemalloc编译的时候来优化一下
提供了持久化的方案,但其实并不完美
缓存代理
解决分片、负载均衡、扩容等问题如codis、mcrouter
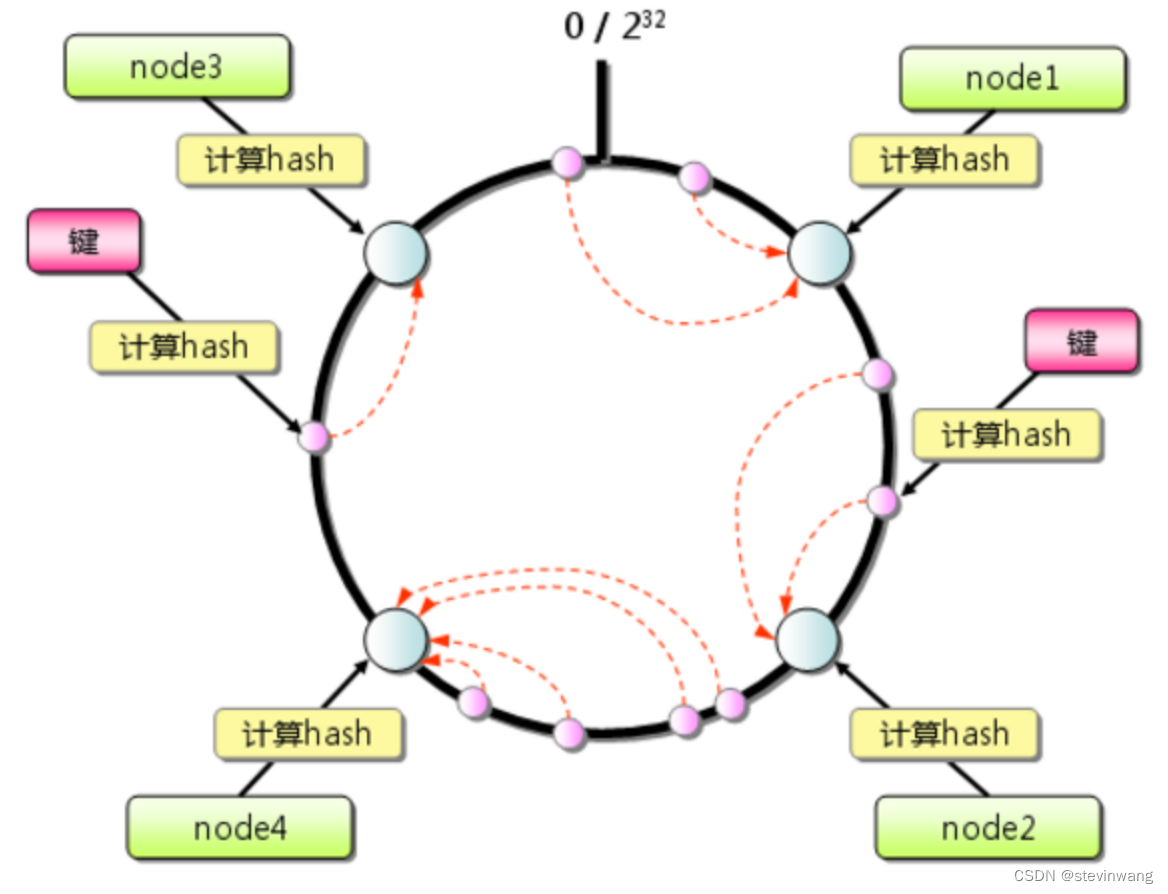
一致性哈希算法就很好地解决了分布式系统在扩容或者缩容时,发生过多的数据迁移的问题。一致性哈希-Wikipedia
比较
纯kv的用mc是合适的,稍复杂结构可以redis
也可以混合使用双缓存架构
数据一致性
storage层和cache层的不一致问题是缓存技术永恒的话题,本质是去更新两个异构存储一定会存在的问题。
cache的一致性需要的权衡:一致性、读效率、实时性
要达到一致性常见的手段是分布式事务,可惜通常这种会牺牲吞吐为代价。缓存的大部分场景都是需要高吞吐的,因此这里存在着根本性矛盾。这里建议适当牺牲一致性,或者降低一致性级别大部分能接受最终一致性,确保高效。毕竟这里的主要功能是cache而不是db,cache的设计底限是数据可丢的,应该允许一定程度的失效、invalid发生。
追求一致性的成本是很高昂的,在cache大部分追求的是最终一致性,工程很多场合通过一些迂回手段就可以极大提升一致性。如
通过binlog延迟2s不去和应用层的多个写操作竞争能保证最终一致
通过set nx/ex就可以避免写和读的冲突
通过版本号丢弃过期的写
通过下游cache生效一定时间之后再回填上游,降低脏数据概率
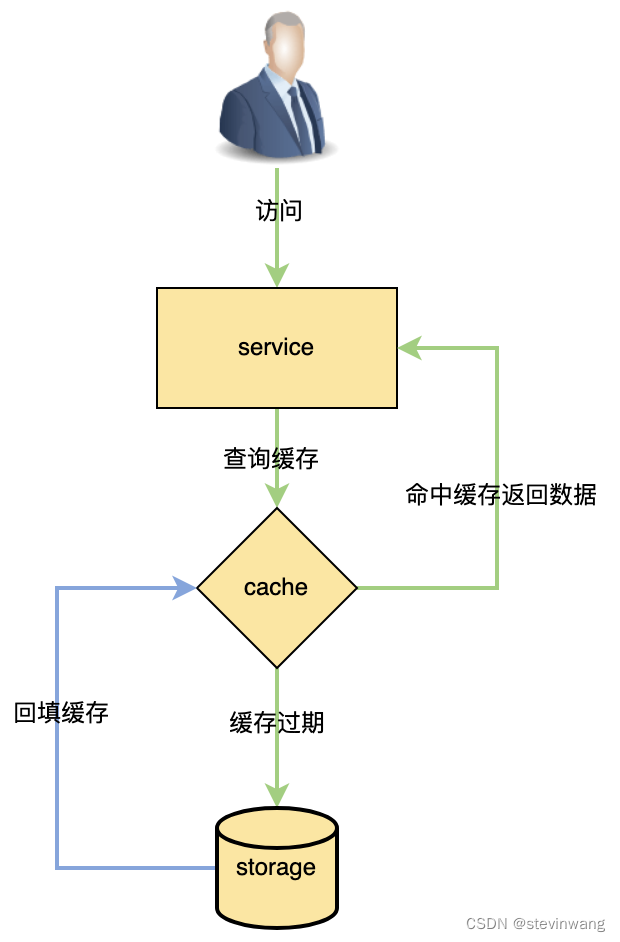
先同步操作去更新db,然后异步操作更新cache,常见架构如下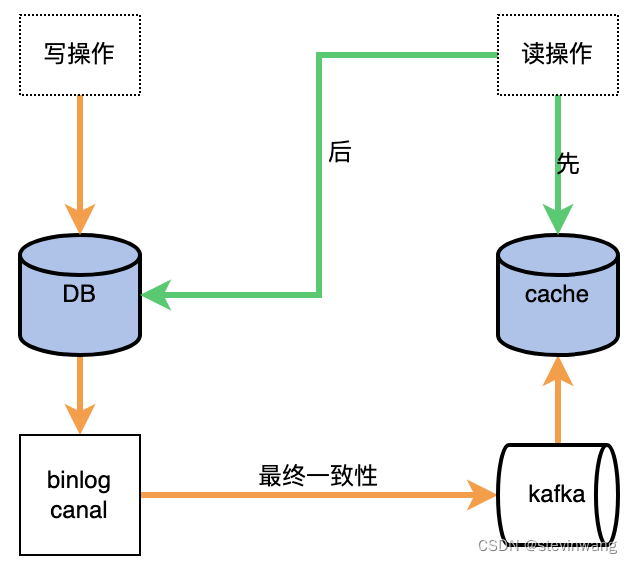
Cache aside 模型
aside模型就是Read cache miss的情况下回填操作,这里存在一定的问题
概念:happens before
happens-before 指的是Java 内存模型中两项操作的顺序关系。 例如说操作A 先于操作B,也就是说操作A 发生在操作B 之前,操作A 产生的影响能够被操作B 观察到。
注意到如下情况
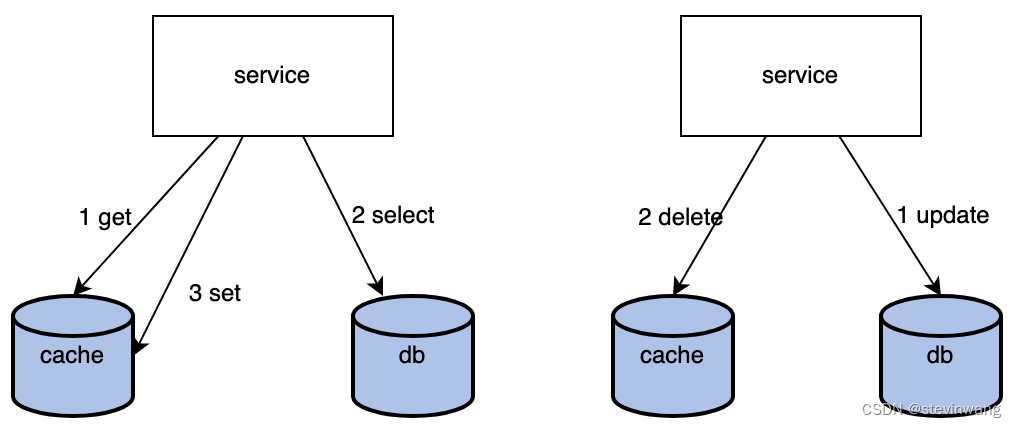
左图
读cache失败
读db
然后set cache
右图
更新db
删除cache
回填操作是无法确保如上五个动作的绝对先后顺序的就会造成不一致的基础,举个例子,预期的顺序是
a-b-c-d-e,如果因为c卡了一下造成了a-b-d-e-c那么就不一致了,预期key被删除,实际还存在
做set cache就是会增加不一致的风险,如果都是delete就不存在,但是缺点是热点穿透,就是热点数据大量更新的情况如一个大V上线
这里的优化点,就是delete不立刻失效但是缩短key的失效周期防止热点穿透,但是做一个标记告诉业务层这个数据可能被更新了(可能是脏数据)让业务层基于自己一致性要求决策读cache还是直接读db
Set ex/nx 就会很大程度避免读写操作之间的问题,但是无法避免写写之间的不一致问题
 |
多级缓存
如下总api提供了完整的功能,是通过内部三个service完成的,每个微服务都有自己的cache,涉及到你怎么更新的顺序问题。如何保证多级缓存的一致性。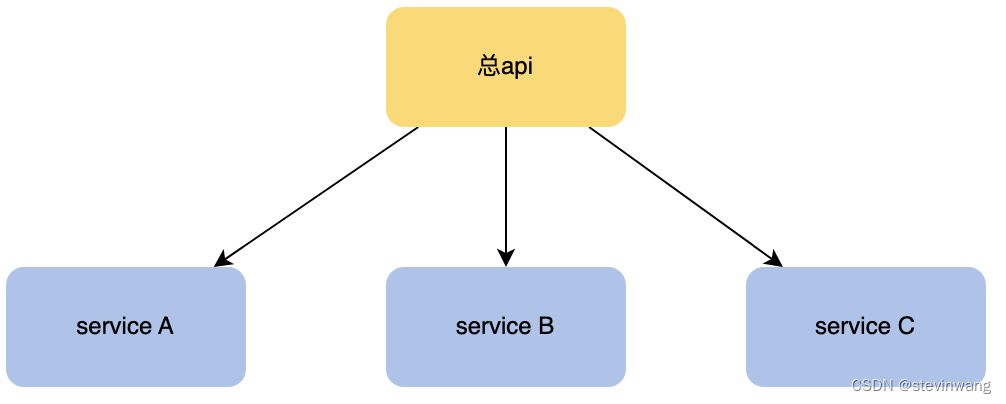
先清理下游的数据再清理上游的
下游缓存过期时间要大于上游,兜底的避免都击穿,越上游的缓存时间越少,命中率是降低的
概念介绍:领域驱动设计DDD思想(也是我个人很认同的工程师之间的协同方法)
领域驱动设计是一种解决业务复杂性的设计思想,通过将实现连接到持续进化来满足复杂需求的软件开发方法。领域驱动设计的前提是:
把项目的主要重点放在核心领域(core domain)和域逻辑
把复杂的设计放在有界域(bounded context)的模型上
发起一个创造性的合作之间的技术和域界专家以迭代地完善的概念模式,解决特定领域的问题
热点缓存
关于热点缓存k按照如下思路去解决。
-
如果数据很小的话,从远程缓存提升为本地缓存,定时同步db刷新
-
主动监控防御预热,主动防御去刷数据,通过滑动窗口+堆统计频次
-
基础库框架支持热点发现自动短时的 没有short-live-cache
-
多集群支持来,对key的设计来降低集中的问题,请求分散避免单点过热
缓存击穿
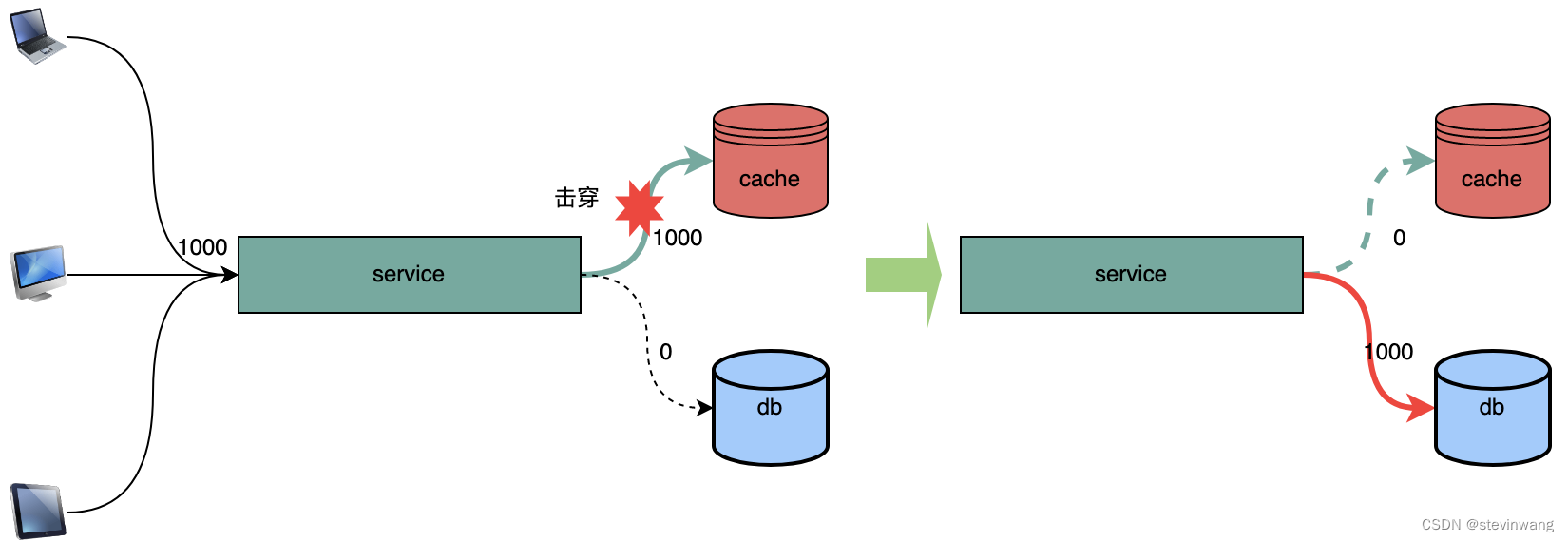
大量的数据直击db,比如热点数据失效短期导致大量请求直接访问存储层造成巨大压力,系统崩溃
先定义一下问题。比如有1000个繁重的操作请求过来。直接请求缓存的话是没什么问题的。如果当热点数据失效或者缓存服务抖动导致这1000个请求会直接查询数据库。就会造成服务抖动。
但是这个方案存在很大的问题,逻辑复杂、操作比较重、加锁需要等待。在缓存场景,这个是不可容忍的,因为失去了缓存性能的优势。请看singleflight
-
Distributed lock
通过分布式锁来降低访问数据库的次数。设置一个锁键值,有且只有一个人成功,并且返回交由这个人来执行回填操作。其他候选者人群缓存。
-
Singleflight
singleflight就是解决这个问题的go语言有实验,golang.org/x/sync/singleflight
这个库的代码只有一百多行写的非常好建议大家读一读, 解决的问题就是将上述1000个请求只有一个会去访问数据库,极大的降低了存储层的压力。
代码Demo https://github.com/go-demo/singleflight-demo
-
Queue
如果缓存失效,交给队列聚合一个键值。来加载数据回写缓存。对于当前失效请求可以使用single fly保证回源,如评论架构实现适合回源加载数据重的任务,比如评论失效。只返回first page,但是需要构建完成评论数据index。
-
Lease
通过加入租约机制,可以很好的避免这两个问题,租约是一个64位的token。与客户端请求的key绑定,对于过时设置在写入时验证租约。可以解决这个问题。
实践方案singleflight+queue
数据失效我们回填缓存的时候,往往不仅仅回填读取的目标本身还有可能多加载一部分数据。比如第一页数据失效,我们回填可能是三页。根据局部性原理。通过single fly解决多个失效请求,只让一个请求去访问数据库来降低数据库的压力。这个请求访问完了,数据库会回填缓存,再通过给队列发一个消息,下游设计另一个任务消费这个信号之后,回填更多页的数据。这样的设计会极大提升命中率,且复杂度可控。
缓存最佳实践
-
在可读的前提下,key尽可能设计的短,减少资源占用。Redis的value如果能用整形就不要用字符串。
-
拆分key,避免过于集中的问题。
-
布隆过滤器解决大量缺失不存在的值
-
空value设置,对于部分数据,可能数据库始终为空。这个时候应该设置空缓存,避免每次都造成缓存失效。
-
读失败后的写缓存策略,降级后一般读失败不回填缓存
-
序列化pb比thrift size小
-
工具化一些胶水代码提升工作效率
-
Memcache udp读取,tcp更新
-
Redis
-
增量更新的一致性保证:先调用expire延时过期,在ZADD、HSET等操作就会保证一定存在的前提下增量操作
-
解决大value,可以设计两个cache,一个专门负责大value操作,或者直接用memcache
-
参考文章:

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









