



元素定位
无论你后面想做什么样的测试,你都需要先找到界面中的某个元素。比如我想测试下图中百度一下这个按钮的功能,那我就需要先找到web界面中百度一下这个按钮对应的前端代码
那如何去定位web界面中的某个元素呢?常见的元素定位方式非常多,如id,classname,tagname,xpath,cssSelector。我们常用主要就是cssSelector和xpath,下面我们就来一一介绍
通过cssSelector进行元素定位
选择器介绍
cssSelector就是我们常说的选择器。在 CSS 中,选择器用于指定样式应用的 HTML 元素,根据功能和组合方式可分为基础选择器和复合选择器:
1. 基础选择器(单个选择器)
基础选择器是最基本的选择方式,直接匹配 HTML 元素,包括以下几种:
-
元素选择器:直接匹配 HTML 标签名,如
p匹配所有<p>标签。p { color: red; } /* 所有段落文字变红 */ -
类选择器:以
.开头,匹配带有指定 class 属性的元素,如.active匹配所有class="active"的元素。.active { background: blue; } /* 所有class为active的元素背景变蓝 */ -
ID 选择器:以
#开头,匹配带有指定 id 属性的元素(id 在页面中唯一),如#logo匹配<div id="logo">。#logo { font-size: 20px; } /* id为logo的元素字体变大 */ -
通配符选择器:以
*表示,匹配页面中所有元素。* { margin: 0; padding: 0; } /* 清除所有元素的默认边距 */
2. 复合选择器(组合选择器)
复合选择器由多个基础选择器组合而成,用于更精确地定位元素,常见的有:
-
后代选择器:用空格分隔两个选择器,匹配前者包含的所有后者元素(无论嵌套层级)。
.nav li { color: green; } // 匹配class为nav的元素内所有li -
子类选择器(子选择器):用
>分隔,仅匹配前者的直接子元素(不包含嵌套更深的后代)。.nav > li { border: 1px solid; } // 仅匹配nav的直接子元素li -
相邻兄弟选择器:用
+分隔,匹配前者后面紧邻的同级元素。h2 + p { margin-top: 10px; } /* 匹配h2后面紧邻的p元素 */ -
群组选择器:用
,分隔多个选择器,为多个元素统一设置样式。h1, h2, h3 { font-weight: normal; } // h1、h2、h3都取消粗体
总结:
- 基础选择器是单一功能的选择器(如 ID 选择器
#id),直接作用于元素。 - 复合选择器是多个选择器的组合(如子类选择器
父 > 子),用于更精准地定位元素关系。 - 在实际操作的过程中,我们经常会用到的就是基础选择器中的ID选择器,以及复合选择器中的子类选择器
下面我们举个例子
#s-hotsearch-wrapper > div
这就是一个 CSS 子选择器(也叫子类选择器),表示:
- 先通过
#shotsearch-wrapper匹配页面中 id 为 “shotsearch-wrapper” 的元素(基础选择器中的 ID 选择器)。 - 再通过
> div匹配这个元素的 直接子元素中所有<div>标签(>符号表示只匹配直接子元素,不包含嵌套更深的后代)
总结来说,这个选择器的作用就是:精准选中 id 为 “shotsearch-wrapper” 的元素内部第一层的所有 div 标签。
使用方法
下面我们就做个实验加深一下理解。下图是我当前百度的首页,我想通过脚本获取百度热搜榜单,然后打印到我的终端屏幕上,请问我该怎么做呢?
首先我们要找到热搜榜的选择器id(注意,要找开头是ul的标签)
为啥要找ul开头的标签呢?因为<ul>这个标签的全称是 Unordered List(无序列表),用于定义一个没有特定顺序的列表。既然你要打印热搜榜,那这个热搜榜一定就在一个<ul>标签下
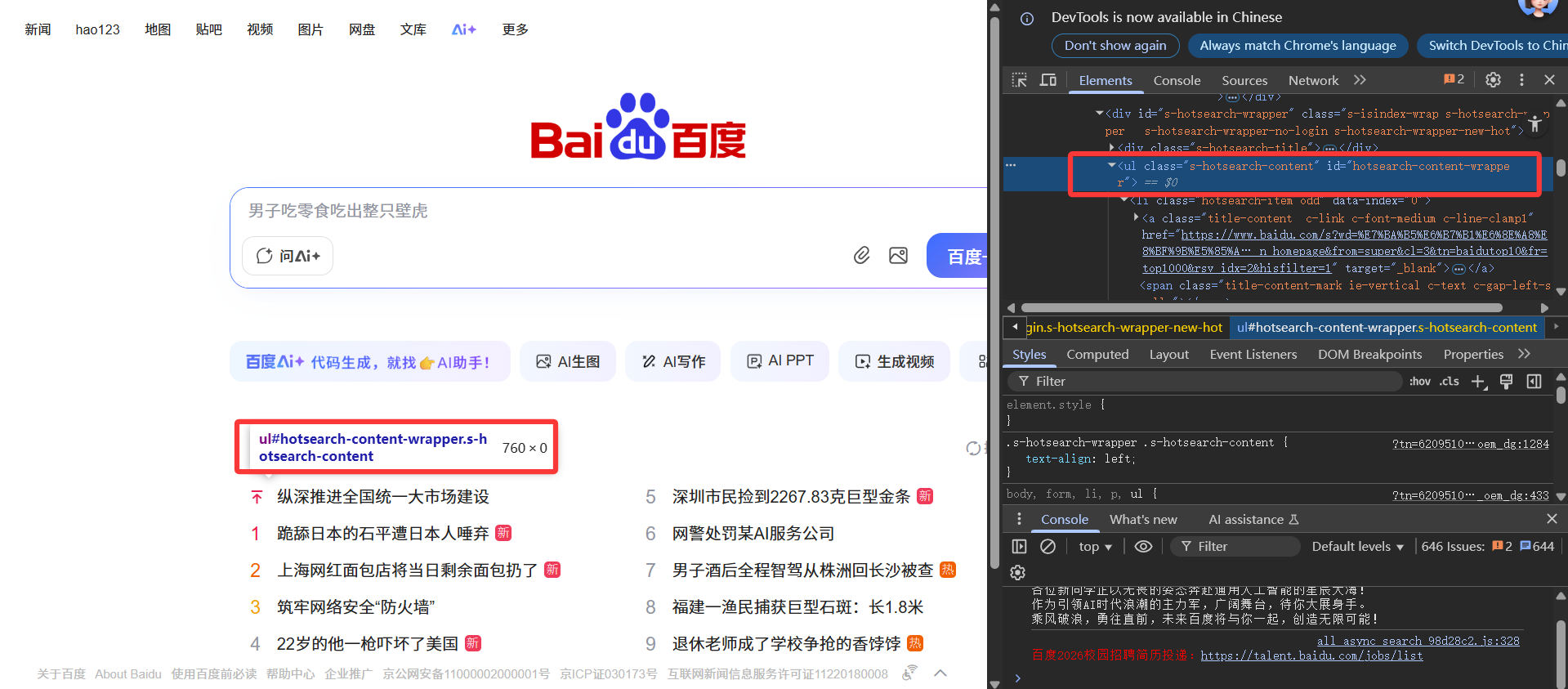
然后咱们复制一下这个列表的选择器id
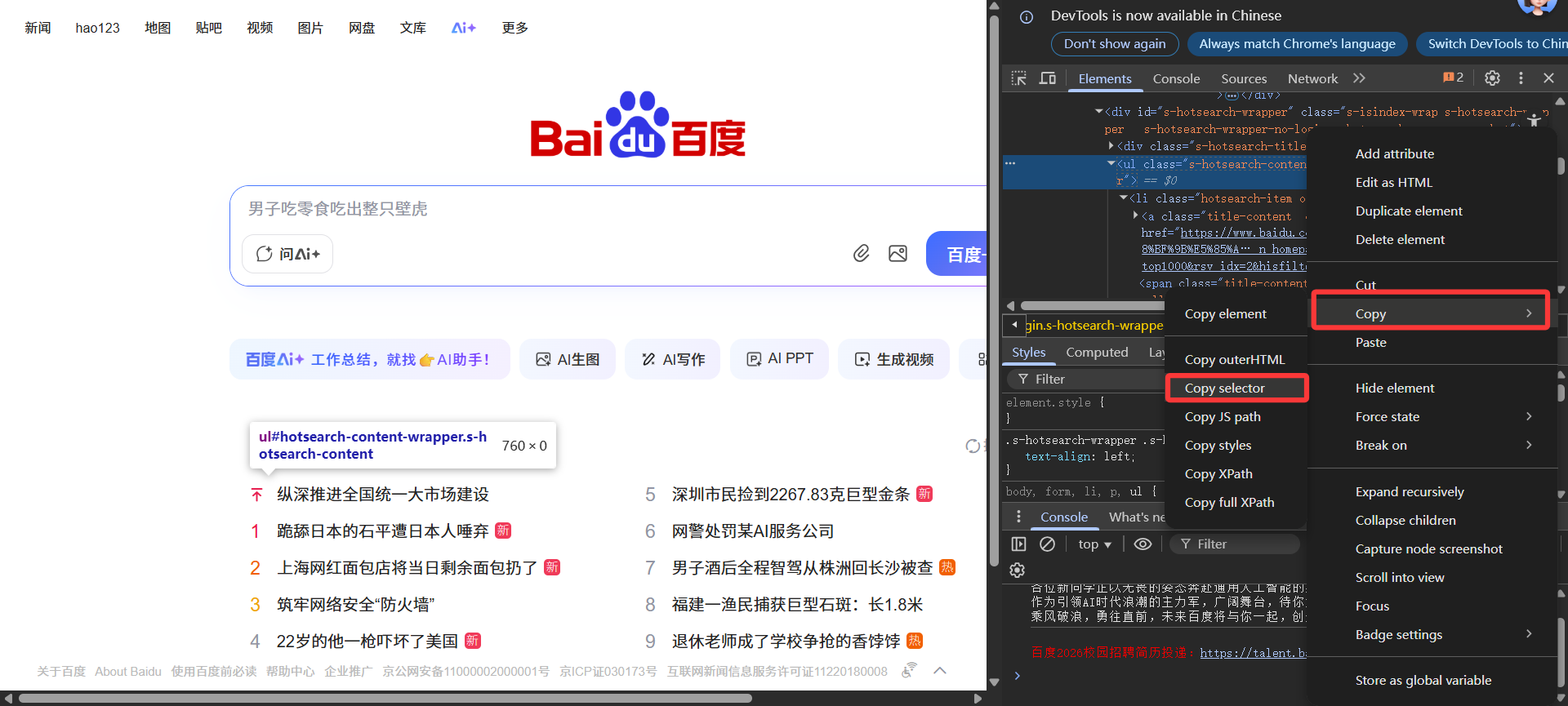
这样你find_elements的目标元素就有了,接下来你只需要创建一个py文件,写入下面的代码,然后运行即可
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器---驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
ret=driver.find_elements(By.CSS_SELECTOR,"#hotsearch-content-wrapper > li")
for i in ret:
print(i.text)#获取每个元素对应的文本信息
driver.quit()
运行之后,我的终端打印结果如下
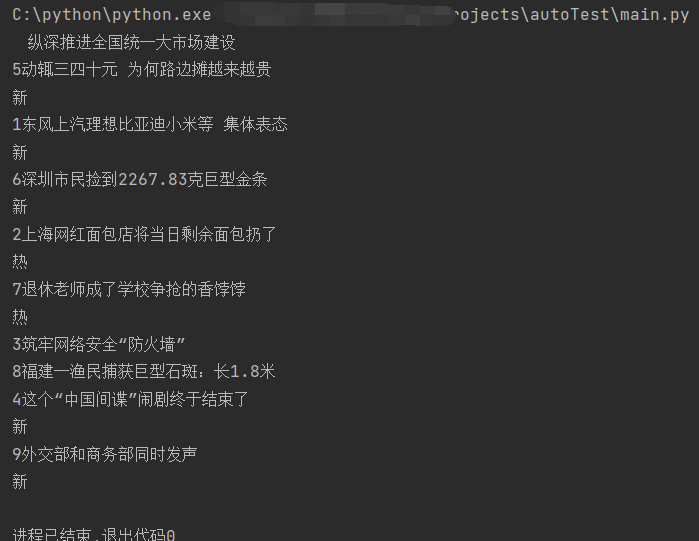
那现在如果我就想打印第5条热搜的信息,我该怎么做呢?
非常简单,首先我们先复制第五条热搜信息对应的选择器id
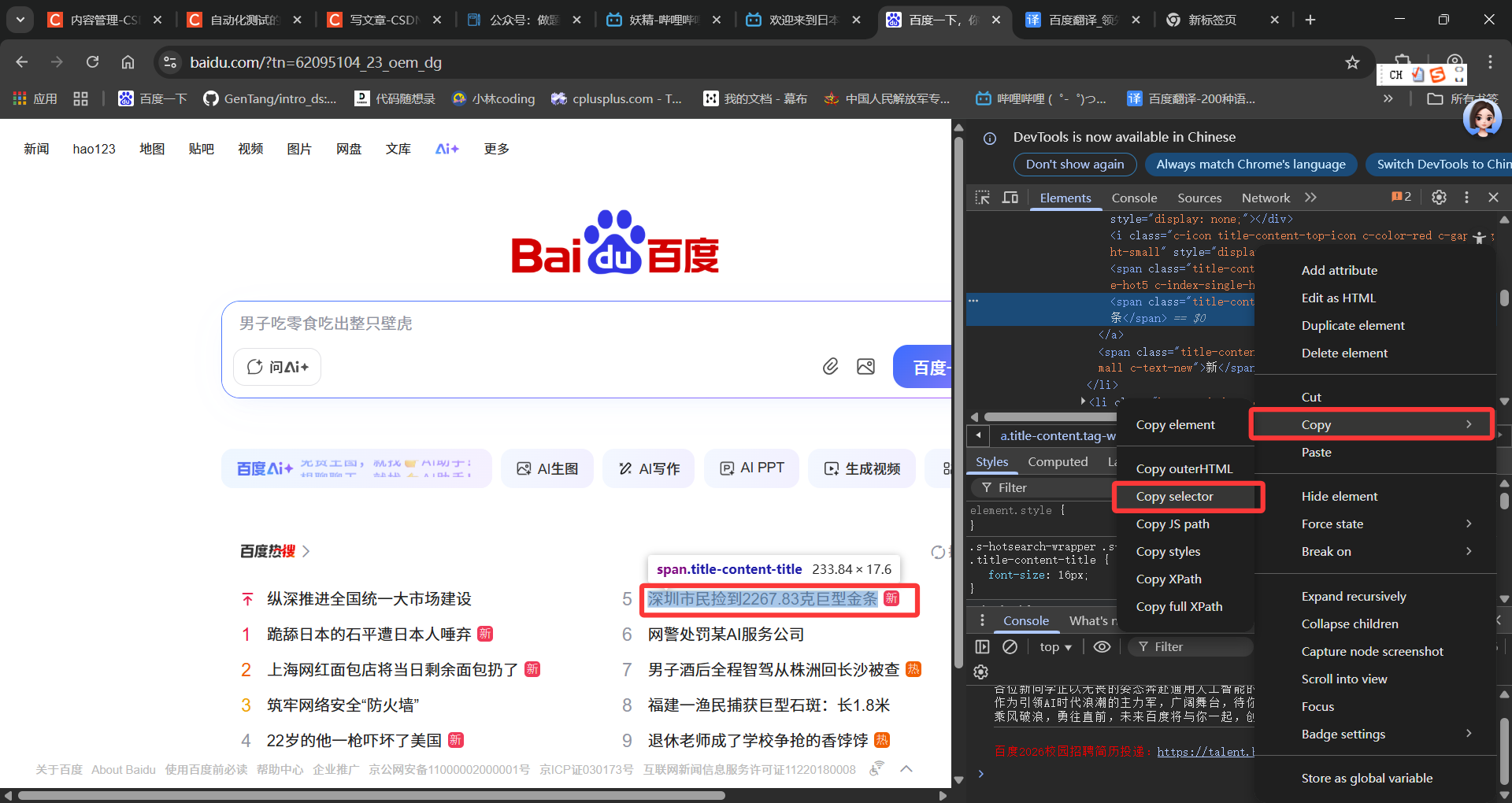
然后在脚本中通过find_element找出,最后打印即可
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器---驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
ret=driver.find_element(By.CSS_SELECTOR,"#hotsearch-content-wrapper > li:nth-child(4) > a > span.title-content-title")
print(ret.text)#获取每个元素对应的文本信息
driver.quit()
运行结果如下

通过xpath进行元素定位
xpath介绍
XML路径语言,不仅可以在XML文件中查找信息,还可以在HTML中选取节点。xpath使用路径表达式来选择xml文档中的节点
xpath语法:
-
获取HTML页面所有的节点
//* -
获取HTML页面指定的节点
// [指定节点]//ul:获取HTML页面所有的ul节点//input:获取HTML页面所有的input节点
-
获取一个节点中的直接子节点:
///span/input
-
获取一个节点的父节点:
..//input/..获取input节点的父节点
-
实现节点属性的匹配:
[@...]//*[@id='kw']匹配HTML页面中id属性为kw的节点
-
使用指定索引的方式获取对应的节点内容
- 注意:xpath的索引是从1开始的。
- 百度首页通过:
//div/ul/li[3]定位到第三个百度热搜标签
使用方法
这个其实使用方法和前面差不多的,我们具体来演示一下
首先通过控制台复制我们想要定位的元素的xpath
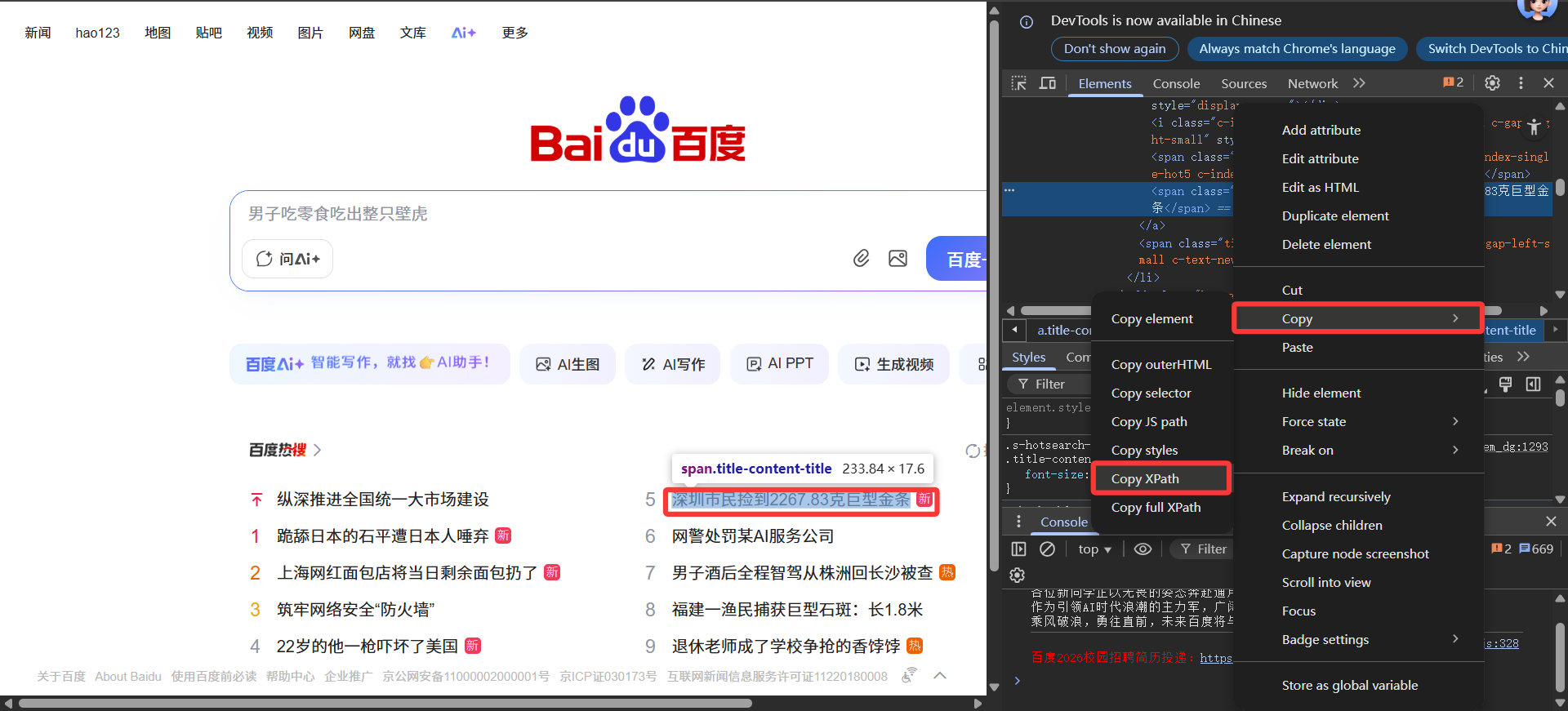
复制完之后,我们就可以构建完整的find_element语句了
ret = driver.find_element(By.XPATH, "//*[@id='hotsearch-content-wrapper']/li[2]/a/span[2]")
完整的python脚本如下
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器---驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
ret = driver.find_element(By.XPATH, "//*[@id='hotsearch-content-wrapper']/li[2]/a/span[2]")
print(ret.text)#获取每个元素对应的文本信息
driver.quit()
运行的结果如下

有人可能会比较奇怪,明明我复制的xpath不属于这条热搜呀,我复制的是“深圳…”那条热搜啊,为啥最后查出来的和我复制的不一样呢
答案很简单,因为榜单在我们复制之后更新了,更新之后,“上海网红面包店…”这条热搜就是榜单的第五名
问题:既然可以手动复制selector/xpath的方式,为什么还要了解语法?
手动复制的selector/xpath表达式并不一定满足上面的唯一性的要求,有时候也需要手动的进行修改表达式
案例:百度首页(需要登陆百度账号)右侧的热搜,复制li标签下的a标签,复制好的的selector为:#title-content,xpath为://*[@id="title-content"],xdm可以手动操作一下,手动复制的表达式是否唯一呢?
操作测试对象
获取到测试的元素之后,接下来我们就可以对其进行操作了。那我们能做哪些操作呢?下面我们就来一一介绍
1. 点击/提交对象:click()
举例:找到百度一下按钮并点击
driver.find_element(By.CSS_SELECTOR, "#su").click()
我们也可以将操作拆成两步
ele = driver.find_element(By.CSS_SELECTOR, "#su")
ele.click()
注意:页面上任意位置/元素都可以实现点击操作,即使它没有对应的点击事件,也能点,执行click()不会报错
2. 模拟按键输入:send_keys(“xxx”)
driver.find_element(By.CSS_SELECTOR, "#kw").send_keys("迪丽热巴")
3. 清除文本内容:clear()
连续的send_keys会讲多次输入的内容拼接在一起,若想重新输入,需要使用清除方法 clear(),先清除上一次的输入结果
driver.find_element(By.CSS_SELECTOR, "#kw").send_keys("迪丽热巴")
time.sleep(1)
driver.find_element(By.CSS_SELECTOR,"#kw").clear()
time.sleep(1)
driver.find_element(By.CSS_SELECTOR, "#kw").send_keys("古力娜扎")
4. 获取文本信息:text
如果判断获取到的元素对应的文本是否符合预期呢?我们可以先获取元素对应的文本,然后通过断言的方式判断是否出错
text = driver.find_element(By.XPATH,'//*[@id="hotsearch-content-wrapper"]/li[1]/a/span[2]').text
# print(f"text:{text}")
assert text == "基尼太美"
问题:是否可以通过 text 获取到 “百度一下按钮” 上的文字 “百度一下” 呢?尝试一下
我们运行下面的代码
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器---驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
# 获取百度一下按钮上的文字
text = driver.find_element(By.CSS_SELECTOR, "#su").text
print(text)
assert text == "百度一下"
# time.sleep(2)
driver.quit()
结果如下
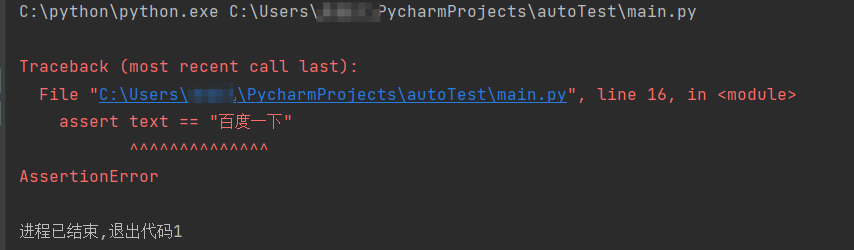
然后我们稍作修改,运行下面的代码
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器---驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
# 获取百度一下按钮上的文字
text = driver.find_element(By.CSS_SELECTOR, "#su").get_attribute('value')
print(text)
assert text == "百度一下"
# time.sleep(2)
driver.quit()
结果如下

请问这是为什么呢?
就是因为在24年的版本中,“百度一下”这四个字并不是text文本信息,而是属性信息

获取属性值需要使用方法 get_attribute("属性名称"),所以我们用了它之后,就能打印出来了
在25年的新版本中,百度一下按钮的前端代码又改成了

这样我们就又可以打印出来了,不过这时候id就变了
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器---驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
# 获取百度一下按钮上的文字
# text = driver.find_element(By.CSS_SELECTOR, "#su").get_attribute('value')
text = driver.find_element(By.ID, "chat-submit-button").text
print(text)
assert text == "百度一下"
# time.sleep(2)
driver.quit()
运行结果如下

5. 获取当前页面标题:title
title = driver.title
6. 获取当前页面URL:current_url
url = driver.current_url
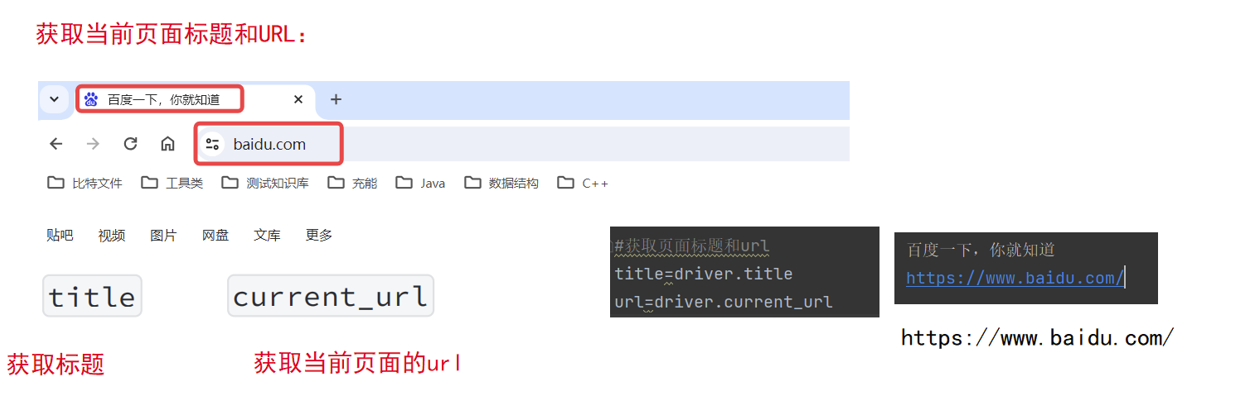
页面元素可点击跳转的情况下,title和current_url通常用来检测跳转的结果是否正确
比如我现在自动化脚本需要在百度一下主页运行,我就可以在脚本的最前面加上下面的代码
# 获取页面标题和url
title = driver.title
url = driver.current_url
print(title)
print(url)
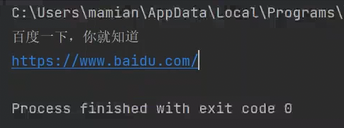
如果打印出来的结果是这样的,说明脚本就是按照我们的预期执行的
窗口
切换窗口
举例引入
运行下面的代码,看看他干的是啥事情?
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# 编写自动化脚本,具体步骤
# 1. 打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com")
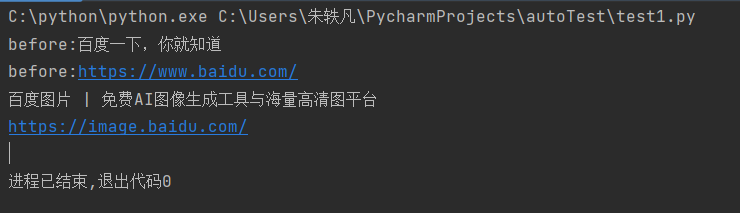
print("before:"+driver.title)
print("before:"+driver.current_url)
time.sleep(1)
driver.find_element(By.XPATH,"//*[@id='s-top-left']/a[6]").click()
time.sleep(3)
print("after:"+driver.title)
print("after:"+driver.current_url)
driver.quit()
#s-top-left > a:nth-child(6)
这段脚本的功能就是打开浏览器,进入百度一下网页,点击左上角的图片按钮
运行结果如下
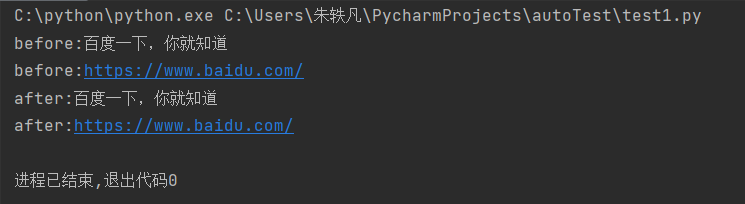
现在我有一个问题,请问为什么点击图片按钮之前和之后,分别打印当前页面的标题和url,都是百度一下页面的标题和url,按理说我点进另一个页面之后,我当前页面不就会变了吗?
原因就是因为在自动化脚本中,当前页面是需要手动执行语句来切换的,不能像我们用鼠标点击那样,一点就自动切换
当我们手工测试的时候,我们可以通过眼睛来判断当前的窗口是什么,但对于程序来说它是不知道当前最新的窗口应该是哪一个。对于程序来说它怎么来识别每一个窗口呢?每个浏览器窗口都有一个唯一的属性句柄(handle)来表示,我们就可以通过句柄来切换,下面我们来看这段代码
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# 编写自动化脚本,具体步骤
# 1. 打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com")
print("before:"+driver.title)
print("before:"+driver.current_url)
time.sleep(1)
driver.find_element(By.XPATH,"//*[@id='s-top-left']/a[6]").click()
# driver.find_element(By.CSS_SELECTOR,"#s-top-left > a:nth-child(6)").click()
#获取当前页面的句柄---第一个标签页
curHandle = driver.current_window_handle
#获取所有句柄
allHandle = driver.window_handles
#遍历所有的句柄,切换到新的页面
for handle in allHandle:
if handle != curHandle:
# 切换句柄
driver.switch_to.window(handle)
#测试跳转结果
print(driver.title)
print(driver.current_url)
driver.quit()
这段代码运行之后,就可以得到我们想要的结果
那这段代码与我们前面说的代码有啥区别呢?主要就多了几句句柄切换相关的语句
#获取当前页面的句柄---第一个标签页
curHandle = driver.current_window_handle
#获取所有句柄
allHandle = driver.window_handles
#遍历所有的句柄,切换到新的页面
for handle in allHandle:
if handle != curHandle:
# 切换句柄
driver.switch_to.window(handle)
在测试中打开了多个标签页,切换到某一个标签页的场景是否常见?
这种场景在测试中不常见
- 通常情况下一般会打开两个标签页,实现标签页的切换测试
- 更多时候,直接输入对应页面的链接在当前标签页下进行测试
切换窗口的语句
1)获取当前页面句柄:
driver.current_window_handle
3)获取所有页面句柄:
driver.window_handles
3)切换当前句柄为最新页面:
1 curWindow = driver.current_window_handle
2 allWindows = driver.window_handles
3
4 for window in allWindows:
5 if window != curWindow:
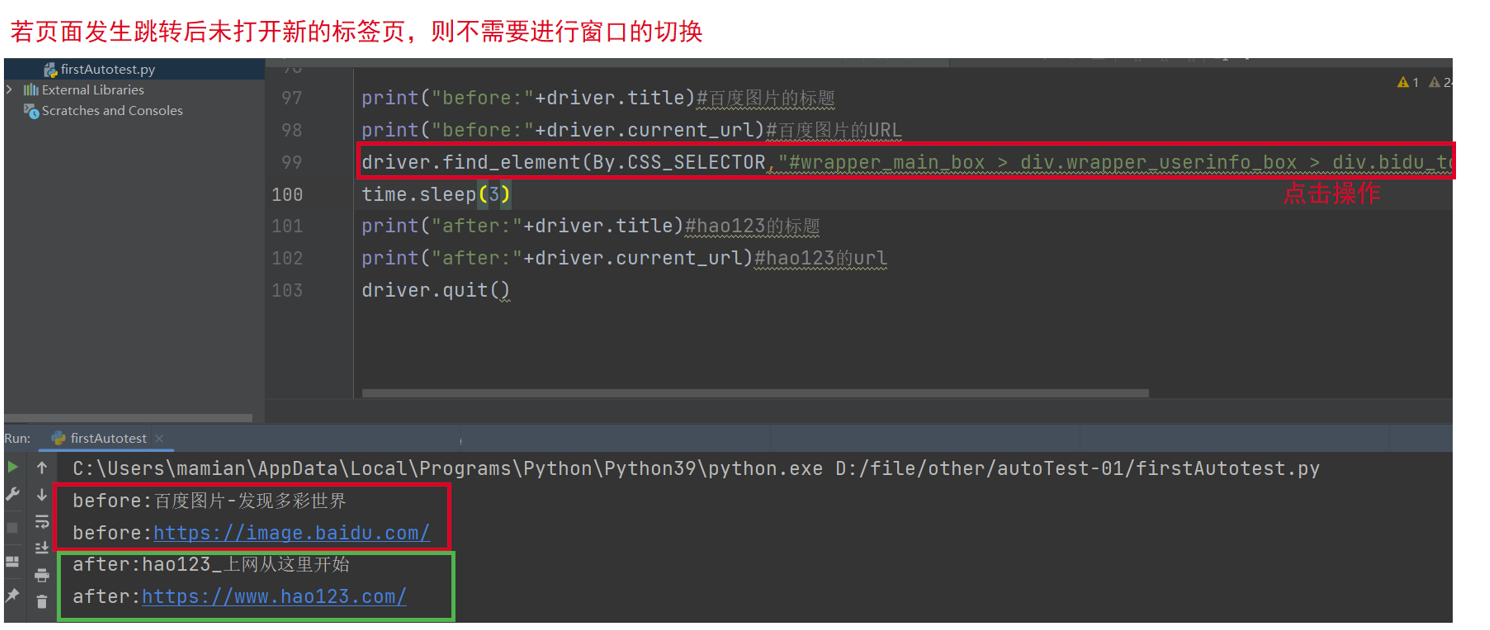
值得注意的是,如果若页面发生跳转后未打开新的标签页,则不需要进行窗口的切换
上面这句话啥意思?看下面的例子
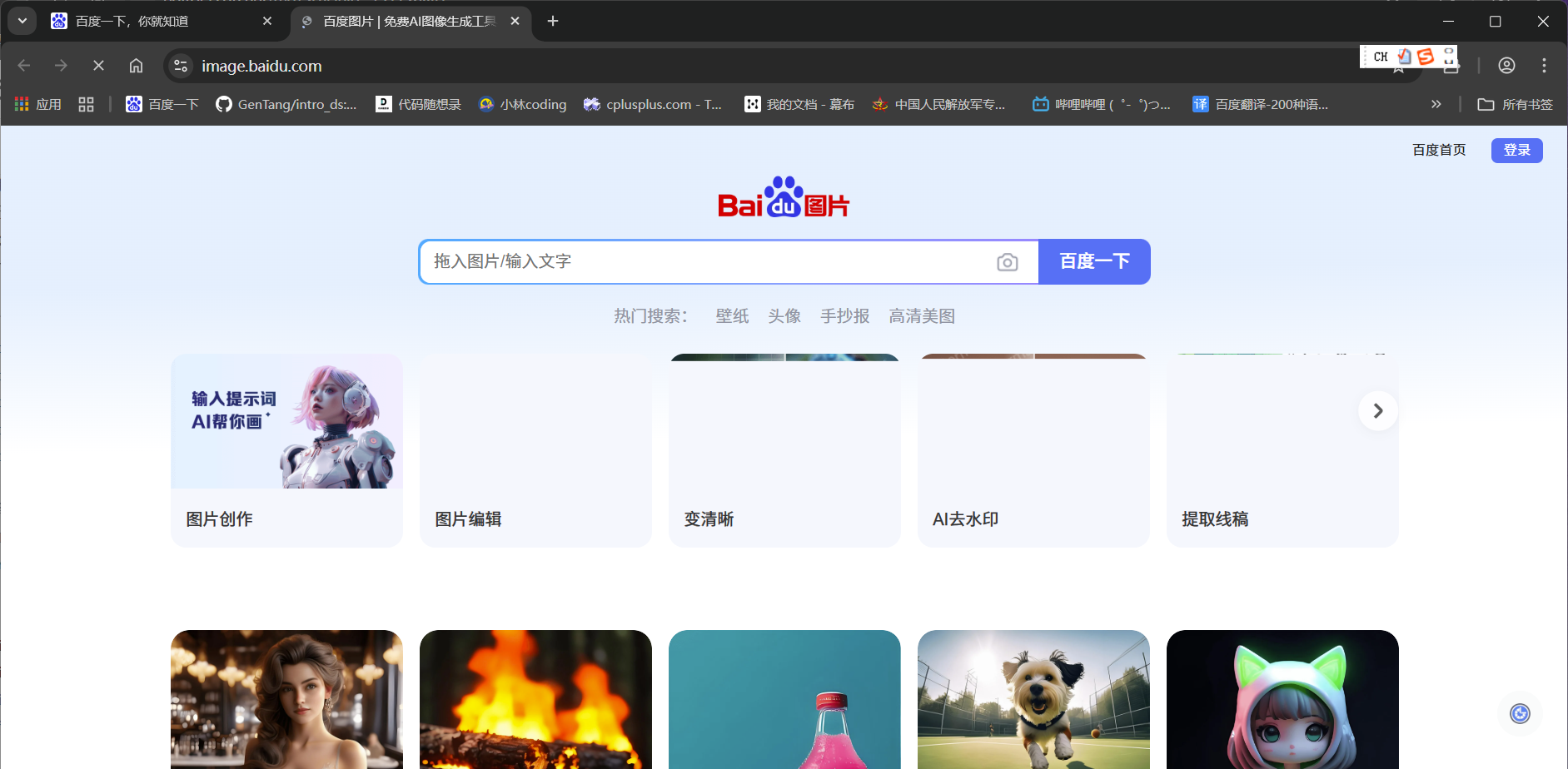
这是百度一下的页面

现在我点击左上角的图片,点完之后,右上角的窗口变成了两个,这就叫页面跳转后打开了新的标签页
然后再看下面这个例子,我点击横栏中的b站按钮
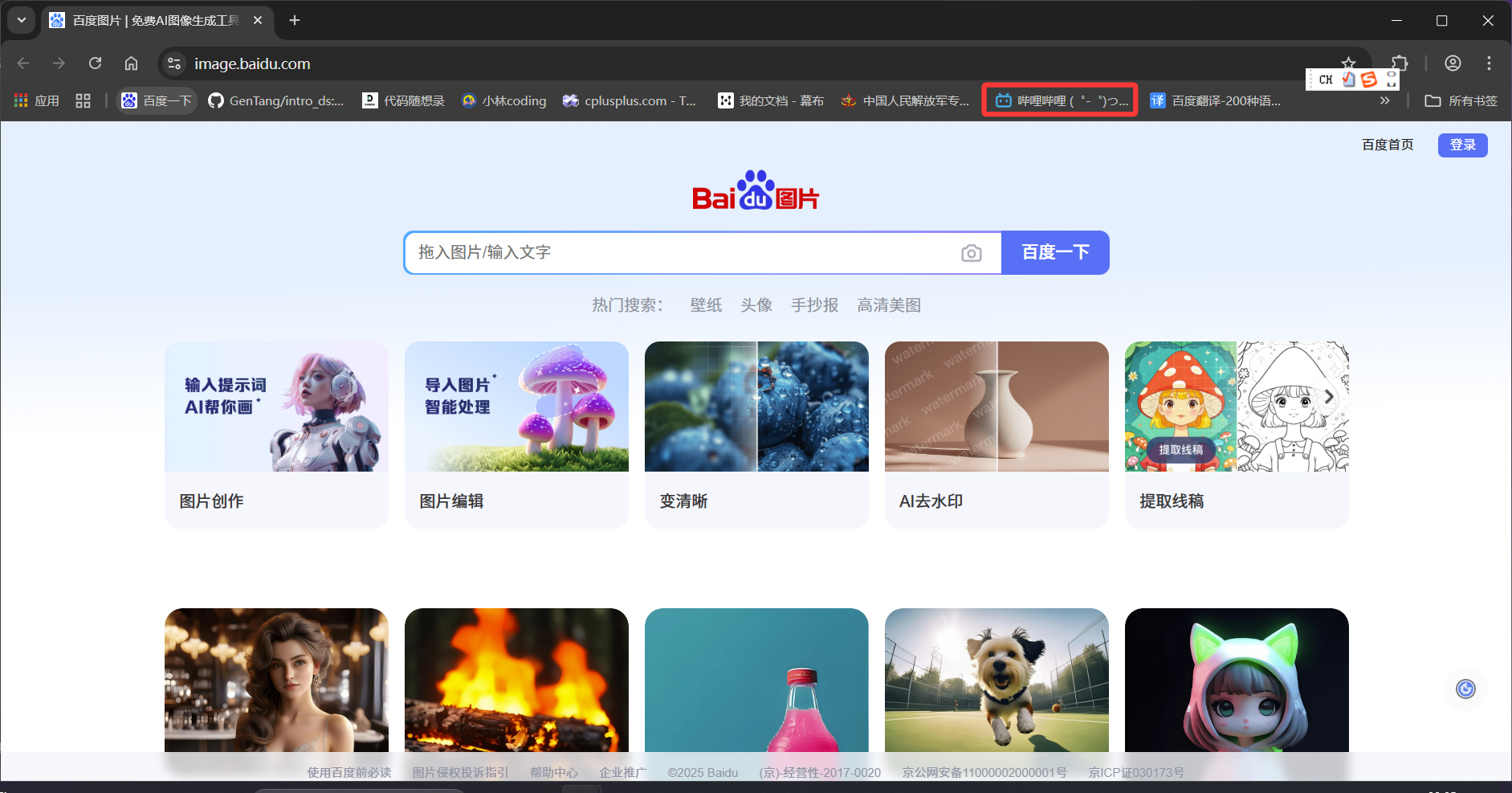
之后页面就跳转到了b站,但是当前仍然是一个标签页,这就叫页面跳转后没有打开新的标签页
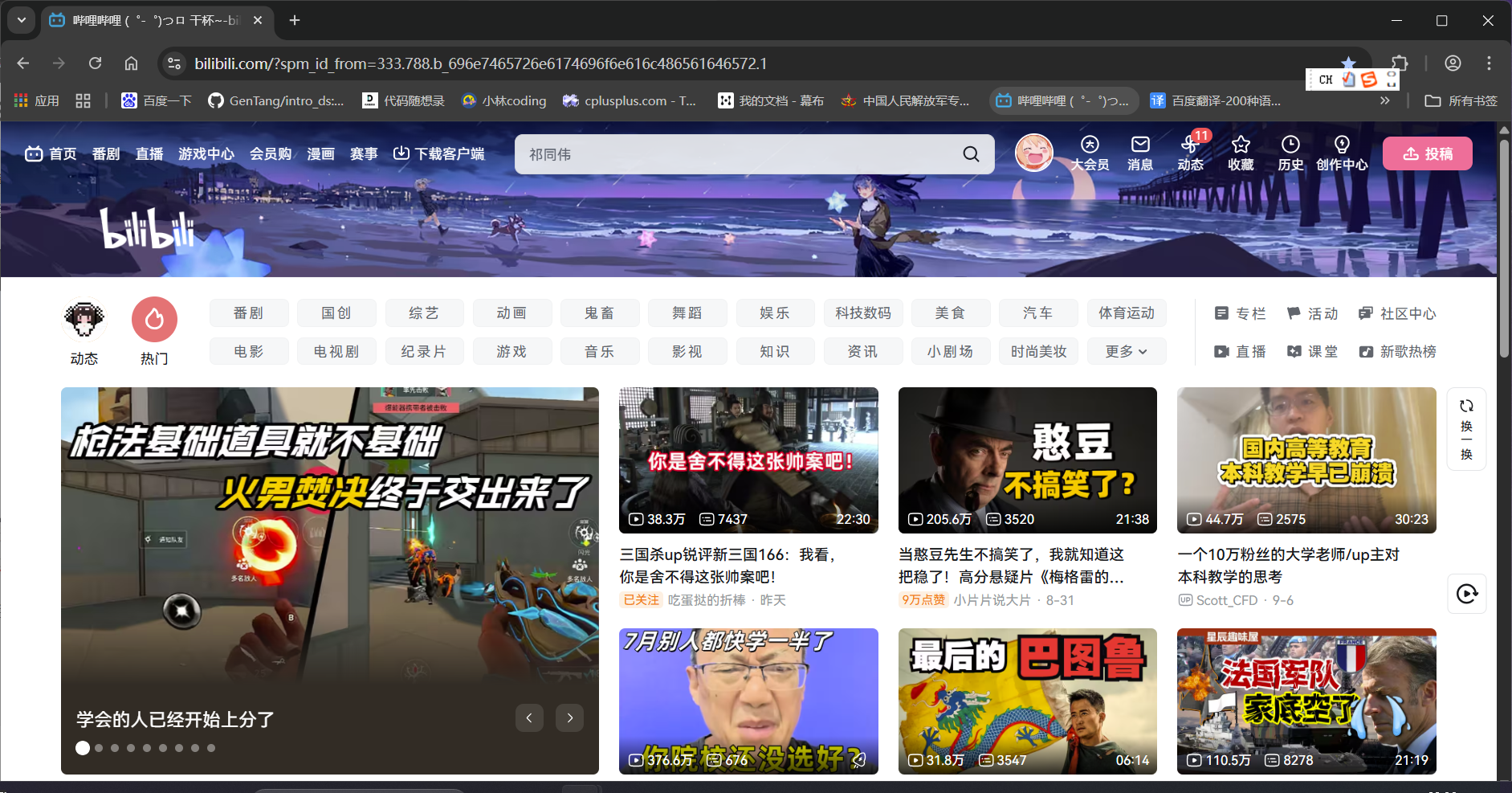
对于这样的情况,click语句执行之后,我们不用添加相应的句柄切换语句,直接调用操作语句访问新页面中的元素就行(下面这张图就对这个结论做了一个简单的验证)
窗口大小设置
1 #窗口最大化
2 driver.maximize_window()
3 #窗口最小化
4 driver.minimize_window()
5 #窗口全屏
6 driver.fullscreen_window()
7 #手动设置窗口大小
8 driver.set_window_size(1024,768)
对于窗口大小的设置操作,我们仅做了解即可,因为在自动化脚本执行过程中通常测试人员不关注页面的变化
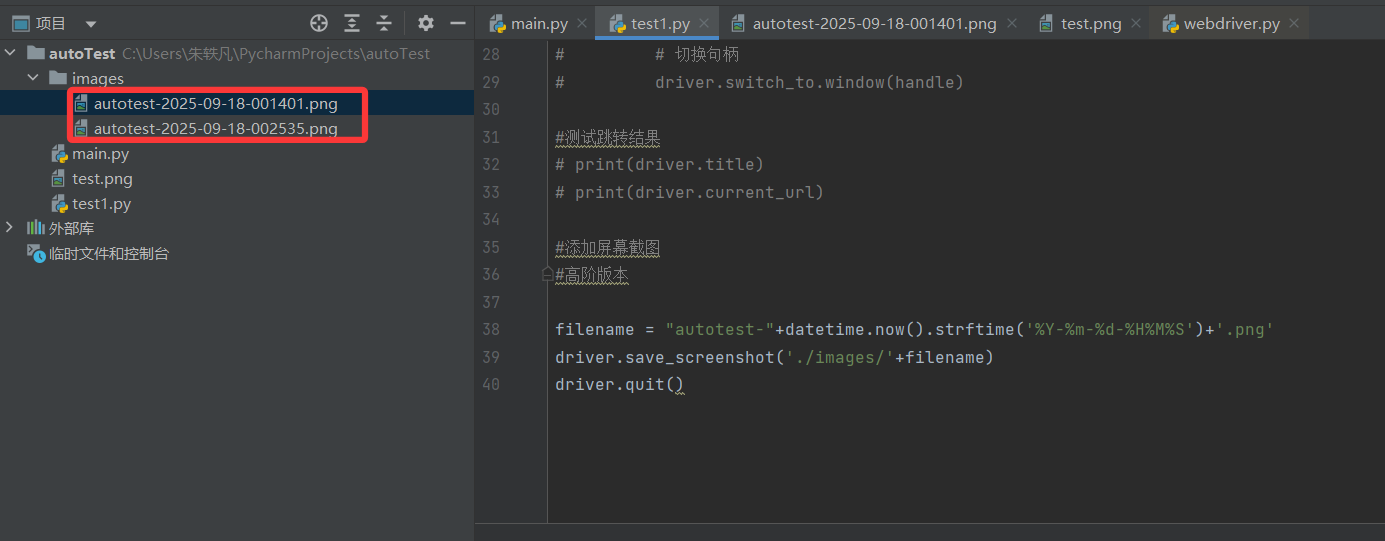
屏幕截图
当自动化运行报错时,仅仅通过终端的错误提示给到的有用信息是一定的,若能将当时的页面变化截图拍下来,能更好的定位问题并解决问题
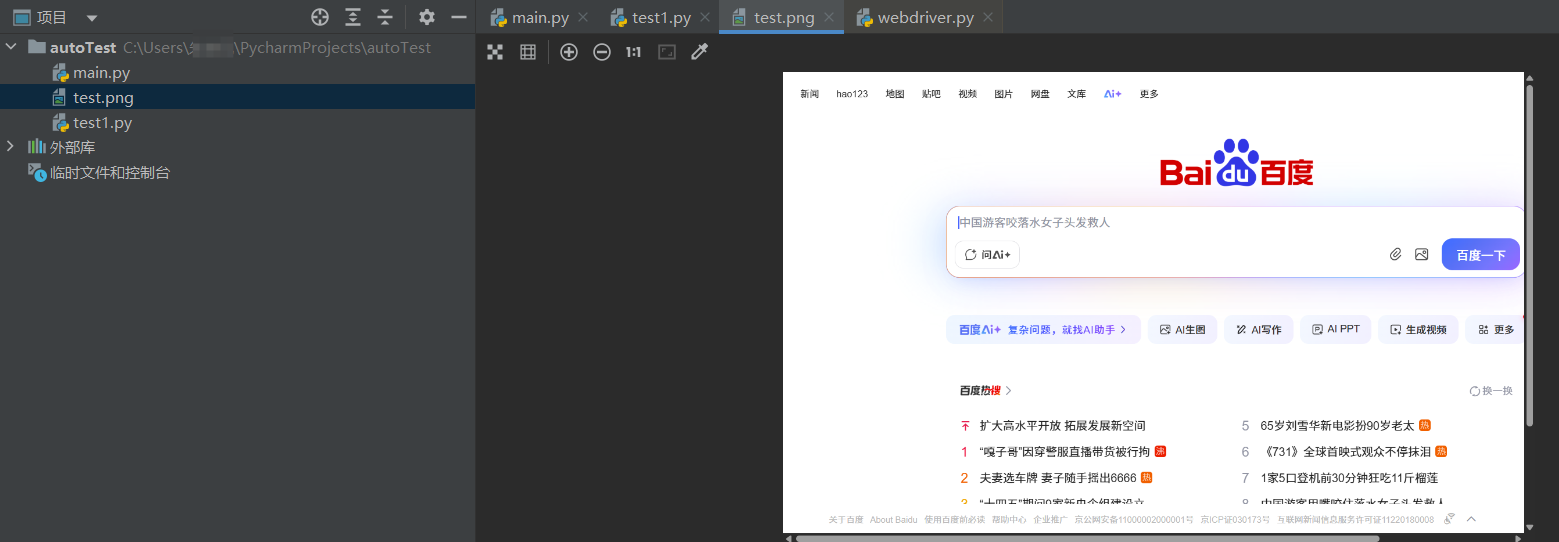
driver.save_screenshot('../images/image.png')
这句话能将image.png图片放到images文件夹中,save_screenshot函数的参数用来传递屏幕截图保存的路径+名称。比如../images/image.png表示的含义就是,截图存放的位置在当前python脚本所在路径的上一级目录中的images子目录下
代码演示
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# 编写自动化脚本,具体步骤
# 1. 打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com")
#添加屏幕截图
filename="./test.png"
driver.save_screenshot(filename)
driver.quit()
执行完毕之后,我们就在当前的项目目录下生成了一个名为test.png的图片
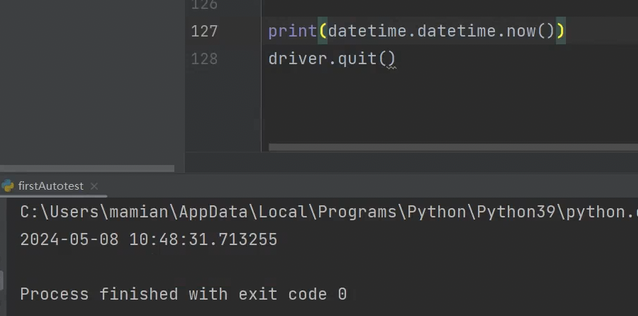
由于图片给定的名称是固定的,当我们多次运行自动化脚本时,历史的图片将被覆盖。那如何将历史的图片文件全部保存下来呢?
主要思路就是让每次生成的图片文件名称都不一样,那怎么能保证不一样呢?用时间戳肯定是最合适的。但是python的时间戳有点问题,那就是打印出来有空格!
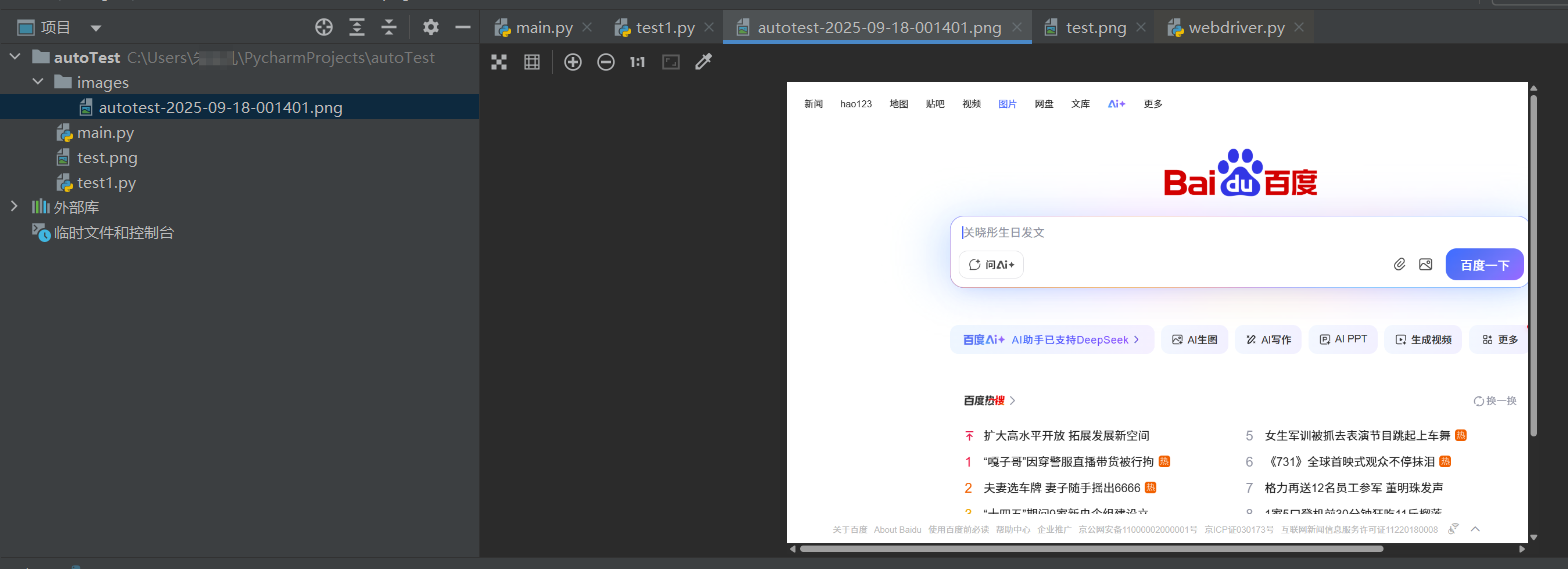
由于文件名不能有空格,所以我们必须要将时间戳格式化之后再作为文件名,相关的python代码如下
#高阶版本
filename = "autotest-"+datetime.datetime.now().strftime('%Y-%m-%d-%H%M%S')+'.png'
driver.save_screenshot('./images/'+filename)
运行的完整代码
import time
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# 编写自动化脚本,具体步骤
ChromeIns=ChromeDriverManager().install()
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com")
filename = "autotest-"+datetime.now().strftime('%Y-%m-%d-%H%M%S')+'.png'
driver.save_screenshot('./images/'+filename)
driver.quit()
运行之后,我们再次查看当前项目路径下的images文件夹,可以看到已经有一个以时间戳命名的文件已经躺在里面了
再运行一次,就又创建一个
关闭窗口
关闭窗口的方法是driver.close()
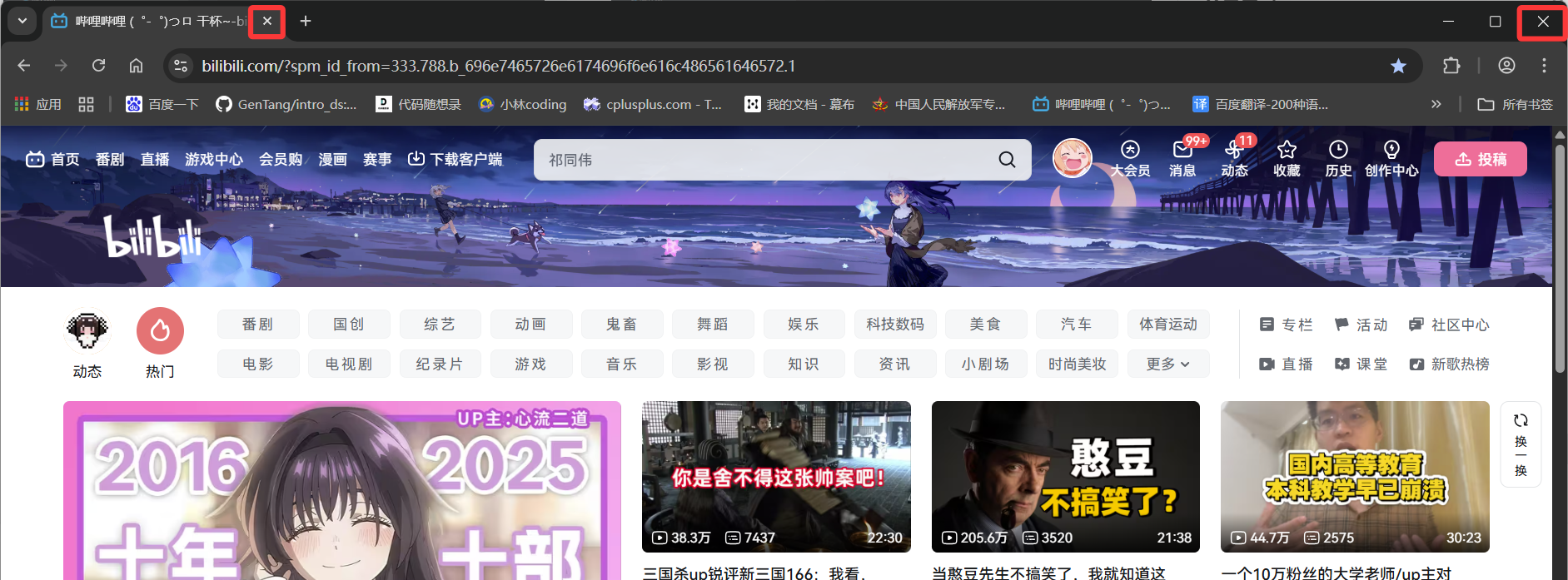
driver.close()与driver.quit()有什么区别?
driver.close()只会关闭一个窗口- 而
driver.quit()会关闭整个浏览器
更形象一些,我们可以理解为:driver.close()相当于你点下图中左边的叉号,driver.quit()相当于你点下图中右边的叉
下面我们就再做个实验验证一下
import time
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
ChromeIns=ChromeDriverManager().install()
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com")
driver.find_element(By.XPATH,"//*[@id='s-top-left']/a[6]").click()
time.sleep(3)
driver.close()
time.sleep(3)
driver.quit()
运行程序我们就能观察到,首先打开百度一下窗口之后,紧接着就会打开一个百度图片的新窗口。此时浏览器就有两个窗口
过了一会,百度一下的窗口会被关闭(因为没有切换句柄,所以当前页面始终是百度一下的界面,因此close关的也是百度一下的界面)
又过了一会浏览器会被关闭(driver.quit()发力了)
注意:关闭窗口!=关闭浏览器,因此在执行driver.closeO之后仍然还需要调用driver.quit(),driver.quit()就相当于是driver这个对象的析构函数,你不调用,这个对象就不会被真正释放
弹窗
由于弹窗不属于当前页面,我们没法通过下图中的选择器来定位弹窗中的元素
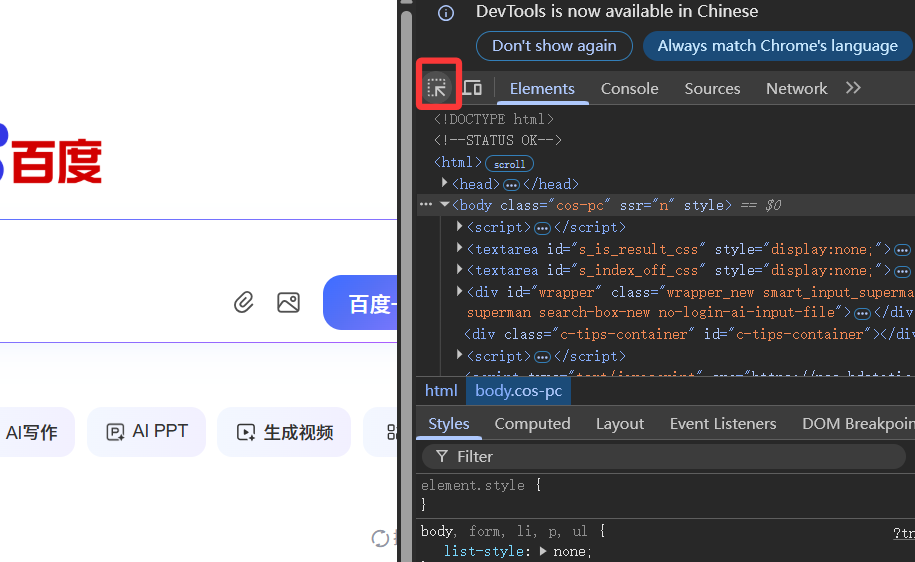
那我们要是想定位弹窗中的元素,应该怎么做呢?
- 我们的答案是使用selenium提供的alert接口
注意:
1)页面上定位不到弹窗元素(无法通过driver.find_element来定位弹窗元素)
2)出现了弹窗之后,无法再通过driver.find_element来定位当前页面中的其他元素,比如先对弹窗进行确认或者取消,等弹窗处理完之后才能定位到页面中的其他元素
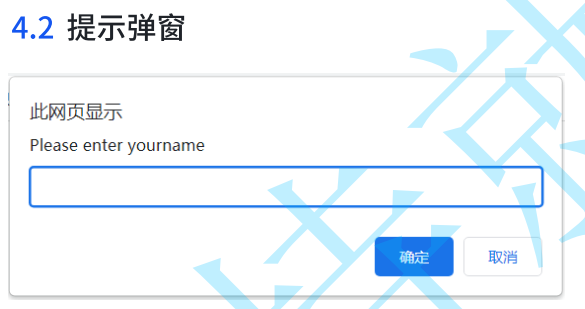
弹窗的种类
弹窗的种类有三种,分别是警告弹窗、确认弹窗和提示弹窗

对弹窗的操作
在对弹窗做任何操作之前,我们都要先创建一个弹窗对象
// 切换到弹窗,alert就代表着一个弹窗对象
1 alert = driver.switchTo.alert
对于警告弹窗和确认弹窗,我们要做的事情只有一件事,那就是点击弹窗中的确认按钮或者取消按钮
// 切换到弹窗,alert就代表着一个弹窗对象
1 alert = driver.switchTo.alert
2 //确认
3 alert.accept()
4 //取消
5 alert.dismiss()
对于提示弹窗,我们要做的事情只有一件事,那就是点击弹窗中的确认按钮或者取消按钮
// 切换到弹窗,alert就代表着一个弹窗对象
1 alert = driver.switchTo.alert
// 向弹窗中输入信息
2 alert.send_keys("hello")
// 点击弹窗中的确认按钮
3 alert.accept()
// 点击弹窗中的取消按钮
4 alert.dismiss()
等待
举例引入:为什么要等待
请看下面的代码
import time
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# 编写自动化脚本,具体步骤
# 1. 打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com")
driver.find_element(By.CSS_SELECTOR, "#chat-textarea").send_keys("初音未来")
driver.find_element(By.CSS_SELECTOR, "#chat-submit-button").click()
# time.sleep(3)
driver.find_element(By.CSS_SELECTOR, "#\\31 > div > div._content-border_1ml43_4.content-border_r0TOp.cu-border.sc-aladdin.sc-cover-card > div > div:nth-child(1) > div > div.list-scroll_7E1go.pc-list-scroll_1uC2y > div > div:nth-child(4) > a > div > div > div.cos-image-content").click()
driver.quit()
直接运行会报错

如果你将导数第三行的注释去掉,即加一句time.sleep(3),他就不会报错。
import time
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# 编写自动化脚本,具体步骤
# 1. 打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com")
driver.find_element(By.CSS_SELECTOR, "#chat-textarea").send_keys("初音未来")
driver.find_element(By.CSS_SELECTOR, "#chat-submit-button").click()
time.sleep(3)
driver.find_element(By.CSS_SELECTOR, "#\\31 > div > div._content-border_1ml43_4.content-border_r0TOp.cu-border.sc-aladdin.sc-cover-card > div > div:nth-child(1) > div > div.list-scroll_7E1go.pc-list-scroll_1uC2y > div > div:nth-child(4) > a > div > div > div.cos-image-content").click()
driver.quit()
为什么前面第一个脚本会报错呢?为什么加了一句话之后就不会报错了呢?
这主要是因为脚本执行的速度非常快,而页面要加载的资源比较多,因此当脚本执行到改行代码时页面还没有渲染完成,因此找不到该元素,当添加了time.sleep(3)之后,页面已经在3秒内加载完成,此时再去查找该元素就可以找到
强制等待
time.sleep()
当调用该方法时,程序会直接阻塞,等待指定秒数后继续执行后面的代码
- 优点:使用简单,调试的时候比较有效
- 缺点:影响运行效率,浪费大量的时间
对于1个或数量较少的测试脚本,添加强制等待消耗的时间不过数秒。但是实际在工作中,业务场景比较复杂时,要添加的自动化脚本非常多,通常来说自动化测试脚本数量可达到上百。
假如说有200个脚本,每个脚本添加若干个等待时间,假设平均等待时间为6秒。那测试程序的总等待事件,就是200 * 6 = 1200s 大约20min,这个时间在程序运行时间里算是非常久的!而实际可接受的自动化运行时间为几秒或者几分钟之内。因此在实际测试脚本中,我们要非常慎用time.sleep()
隐式等待
implicitly_wait() 参数:秒
隐式等待作用域是整个脚本的所有元素。即只要driver对象没有被释放掉driver·quit(),隐式等待就一直生效。
看完上面一句话,初学者可能还是不太明白,啥叫作用域是整个脚本的所有元素呢?请看下面的例子
在下面的脚本中,我们在driver.get("https://www.baidu.com")语句的前面加了一句driver.implicitly_wait(3),这有啥效果呢?
import time
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
# 编写自动化脚本,具体步骤
# 1. 打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
driver=webdriver.Chrome(service=Service(ChromeIns))
#添加隐式等待
driver.implicitly_wait(3)
driver.get("https://www.baidu.com")
driver.find_element(By.CSS_SELECTOR, "#chat-textarea").send_keys("初音未来")
driver.find_element(By.CSS_SELECTOR, "#chat-submit-button").click()
# time.sleep(3)
driver.find_element(By.CSS_SELECTOR, "#\\31 > div > div._content-border_1ml43_4.content-border_r0TOp.cu-border.sc-aladdin.sc-cover-card > div > div:nth-child(1) > div > div.list-scroll_7E1go.pc-list-scroll_1uC2y > div > div:nth-child(4) > a > div > div > div.cos-image-content").click()
driver.quit()
这个效果就是,从此以后,我脚本每次通过find_element访问页面中的元素时,都会先等3秒,等网页渲染好之后,再执行find_element语句
看完上面的话,可能有人还会有疑问,假如你这个implicitly_wait等待结束的时间设置的是3s,然后我执行find_element语句的时候,2s就渲染好了,那我implicitly_wait是等2s还是等3s呢?
答案是等2s,详细解释如下
driver.implicitly_wait(3) 的作用是设置一个全局隐式等待时间,其执行逻辑是:
当执行 find_element 等元素查找操作时,会先检查目标元素是否已存在于 DOM 中:
- 如果立即找到元素,会立即执行后续操作,不会等待3秒;
- 如果未立即找到,会进入等待状态,最多等待3秒:
- 若在3秒内元素出现,则立即停止等待并执行操作;
- 若超过3秒元素仍未出现,则抛出
NoSuchElementException异常。
简单说:3s之内元素什么时候渲染好出现了,什么时候等待结束,3s一到如果还没出现,那等待也会结束
这种机制避免了不必要的固定等待,比 time.sleep(3) 更高效,所以我们将其称之为作用于全局的智能等待
显示等待
显示等待的应用场景
走到这有人就说了,我感觉前面的等待机制已经很智能很完善了啊,为啥还要引入显示等待呢?
引入显示等待的目的肯定是为了解决前两种等待不好解决的问题。那啥问题前面两种等待都不好解决呢?请看下面的几个场景
场景1:登录页面 - 等登录按钮能点击再点击
问题:刚打开登录页时,登录按钮可能是灰色的(不可点击),要等输入账号密码后才变可点击。
对应条件:EC.element_to_be_clickable((By.ID, "login-btn"))
作用:直到按钮“既可见又能点击”才执行点击,避免点了没反应。
场景2:搜索页面 - 等搜索结果加载出来再操作
问题:输入关键词后,结果列表需要加载1-3秒,直接去定位结果会失败。
对应条件:EC.presence_of_element_located((By.CLASS_NAME, "result-item"))
作用:只要第一个结果“出现在页面结构里”(不管是否完全显示),就可以开始后续操作。
场景3:弹窗关闭 - 等弹窗消失再继续
问题:提交表单后会弹出“成功提示”弹窗,3秒后自动消失,没消失前点其他按钮会被遮挡。
对应条件:EC.invisibility_of_element_located((By.ID, "success-popup"))
作用:等待弹窗“完全消失”(不在页面上显示),再进行下一步。
场景4:购物车 - 等商品数量更新后再确认
问题:点击“+”号增加商品数量,数字会从“2”变成“3”,但可能有延迟。
对应条件:EC.text_to_be_present_in_element((By.CLASS_NAME, "count"), "3")
作用:直到数量显示“3”,才确认操作成功,避免提前截图或判断出错。
场景5:页面跳转 - 等新页面加载完成
问题:点击“个人中心”后,URL从/home变成/user,但页面内容可能还在加载。
对应条件:EC.url_contains("/user")
作用:确认URL包含/user(说明跳转到了目标页),再去定位个人信息元素。
场景6:处理弹窗提示 - 等弹窗出现再关闭
问题:删除内容时会弹出“确认删除?”的系统弹窗,直接调用关闭方法会失败(因为弹窗还没出来)。
对应条件:EC.alert_is_present()
作用:等弹窗“弹出来”,再执行driver.switch_to.alert.accept()确认删除。
前面列举的这些场景,都有一个核心特点,那就是——等待的时间不固定,等待的事件是确定的”。
-
对于这样的场景,如果你用前面俩等待,如果你等待事件设置的太长,这就很浪费,如果你设置太短,很有可能等不到,这就非常不精准。
-
这时候如果有一种基于事件的等待机制,那我们就不用
time.sleep(5)硬等5秒,而是根据元素实际状态动态等待,既快又稳。
显示等待的特点
显示等待就是我们前面说的,一种基于事件的等待机制,它是智能等待,可以自定义显示等待的条件,操作灵活,但是写法最复杂
显示等待与隐式等待的区别是什么?
这俩最大的区别就在于:隐式等待的等待事件就只是:指定元素在页面中出现 | 等待时间超时,而显示等待能够支持各种各样的等待条件
| 维度 | 显示等待(Explicit Wait) | 隐式等待(Implicit Wait) |
|---|---|---|
| 作用范围 | 针对单个元素或条件,仅对当前等待语句生效 | 针对整个driver实例,对所有元素定位操作全局生效 |
| 等待条件 | 可自定义复杂条件(元素可见、可点击、文本包含等) | 仅等待元素出现在DOM中(不管是否可见、可点击) |
| 灵活性 | 支持自定义超时时间和条件,颗粒度细、场景适配强 | 全局统一超时,无法针对不同元素设置差异化条件 |
| 底层逻辑 | 主动轮询检查条件是否满足,满足则立即执行后续代码 | 被动等待,在元素定位时轮询DOM直到超时 |
| 使用场景 | 复杂交互(如弹窗出现、元素加载完成后点击) | 简单页面,希望所有元素定位默认有基础等待 |
举个例子理解:
- 隐式等待:你设置了
driver.implicitly_wait(10),那么在接下来所有find_element操作中,若元素没找到,driver会自动轮询DOM最多10秒,直到找到元素或超时。但它只保证元素“存在于DOM”,不关心元素是否可见、可点击。 - 显示等待:你想等某个按钮可见后点击,就用
WebDriverWait(driver, 5).until(EC.visibility_of_element_located((By.ID, "btn"))).click()。这里只针对btn元素,等待“可见”这个明确条件,超时时间5秒,满足后立即执行点击。
补充:元素在DOM中与元素可见的关系
一句话总结:元素在DOM中是元素可见的必要不充分条件
-
元素在DOM中,元素不一定可见
-
元素可见,元素肯定要先在DOM中
-
元素在DOM中:
- 元素已经被浏览器解析并添加到文档树中
- 但它可能被CSS隐藏(display:none、visibility:hidden等)
- 或者被其他元素遮挡
- 或者在视口外
- 此时元素存在但用户看不到,可能无法交互
-
元素可见:
- 元素不仅存在于DOM中
- 还满足可见性条件:宽高>0、不透明、不在视口外
- 通常可以被用户看到并交互(如点击)
举个例子
<!-- 这个元素在DOM中但不可见 -->
<div id="hidden" style="display:none;">内容</div>
<!-- 这个元素在DOM中且可见 -->
<div id="visible">内容</div>
总结:
- 隐式等待是全局兜底的“基础等待”,适合简单场景;
- 显示等待是针对特定元素的“精准等待”,适合复杂交互,也是企业级自动化测试的推荐方式(能避免很多因元素状态不足导致的失败)。
显示等待使用方法介绍
WebDriverWait(driver, sec).until(functions) 是 Selenium 中实现显示等待(Explicit Wait)的核心方法,用于在自动化测试中智能等待页面元素达到预期状态后再执行后续操作,避免因页面加载速度慢导致的元素定位失败。其参数解释如下:
-
WebDriverWait:这是 Selenium 提供的等待类,需要传入两个关键参数:driver:浏览器驱动实例(如 ChromeDriver、FirefoxDriver 等),用于控制浏览器。sec:最长等待时间(单位:秒)。如果超过这个时间,等待的条件仍未满足,会抛出TimeoutException异常。
-
.until(functions):这是WebDriverWait类的核心方法,用于指定等待的条件。
functions:是一个条件判断函数(或匿名函数),用于描述“元素需要满足什么状态”。通常使用selenium.webdriver.support.expected_conditions模块(简称EC)中预定义的条件,例如:EC.presence_of_element_located():等待元素出现在 DOM 中EC.visibility_of_element_located():等待元素可见(不仅存在于 DOM,还需可见)EC.element_to_be_clickable():等待元素可点击
一些常见的ExpectedConditions 预定义方法
| 方法 | 说明 |
|---|---|
title_is(title) | 检查页面标题的期望值 |
title_contains(title) | 检查标题是否包含区分大小写的子字符串的期望值 |
visibility_of_element_located(locator, str]) | 检查元素是否存在于页面的DOM上并且可见的期望值。 |
presence_of_element_located (locator, str]) | 用于检查元素是否存在于页面的DOM上的期望值 |
visibility_of (element) | 检查已知存在于页面DOM上的元素是否可见的期望 |
alert_is_present () | 检查是否出现弹窗 |
注意:这只是显示等待中常用的一些等待方法,如果没找到你想要的,你可以自定义等待方法,然后将方法的函数名作为参数functions传入WebDriverWait(driver, sec).until(functions) 中就行
示例:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 等待10秒,直到ID为"username"的元素可见
element = WebDriverWait(driver, 10).until(
EC.visibility_of_element_located(("id", "username"))
)
显示等待、隐式等待与强制等待可以一起用吗?
强制等待可以和其他等待随便搭配使用,但是不建议显示等待、隐式等待一起用,因为二者混合使用会导致设定的超时时间变成一个随机值
比如下面这个例子,我设置隐式等待时间为10s,显示等待时间为15s,然后再当前页面定位一个不存在的元素,你觉得代码的超时时间会是多少呢?是10s,还是15s,还是10+15s?
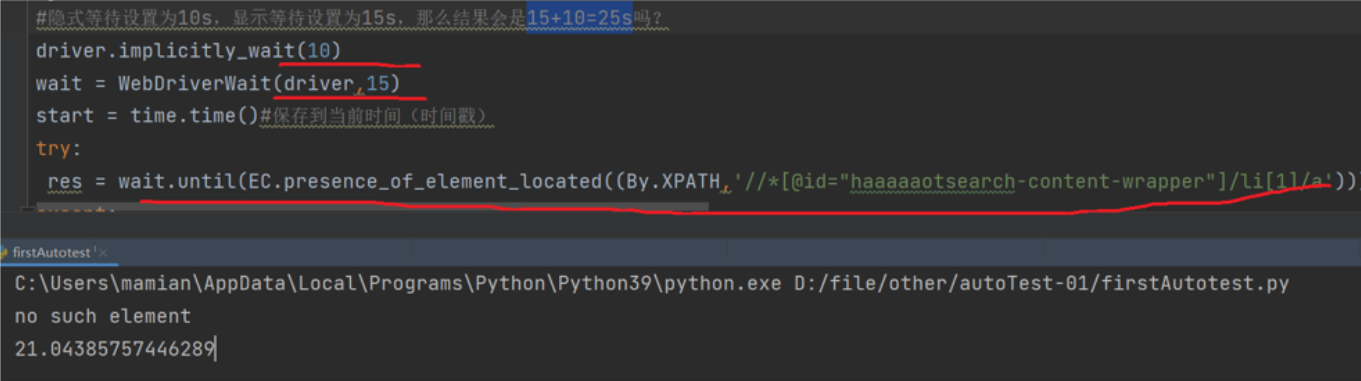
结果和我们想的都不一样,答案是21s。也就是说这个超时时间你无法预测到,所以我们不建议使用
浏览器导航
常见操作:
1)打开网站
driver.get("https://tool.lu/")
2)浏览器的前进、后退、刷新
driver.back()
driver.forward()
driver.refresh()
driver.forward()执行之后,当前页面的句柄会不会改变?
答案是不会,因为一个页面句柄对应的就是下图中浏览器左上角画圈的一个窗口
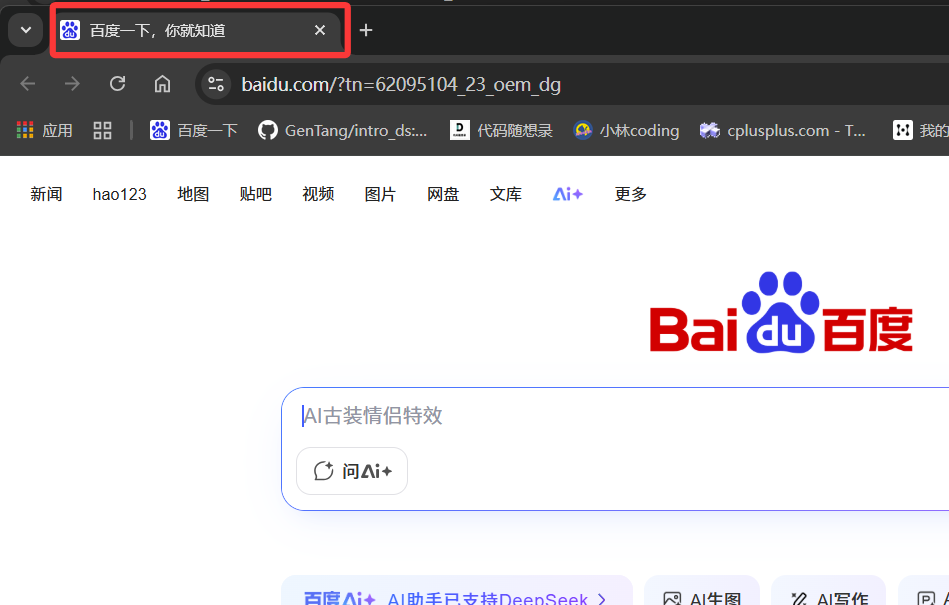
只有切换窗口,才需要对应地切换句柄
文件上传
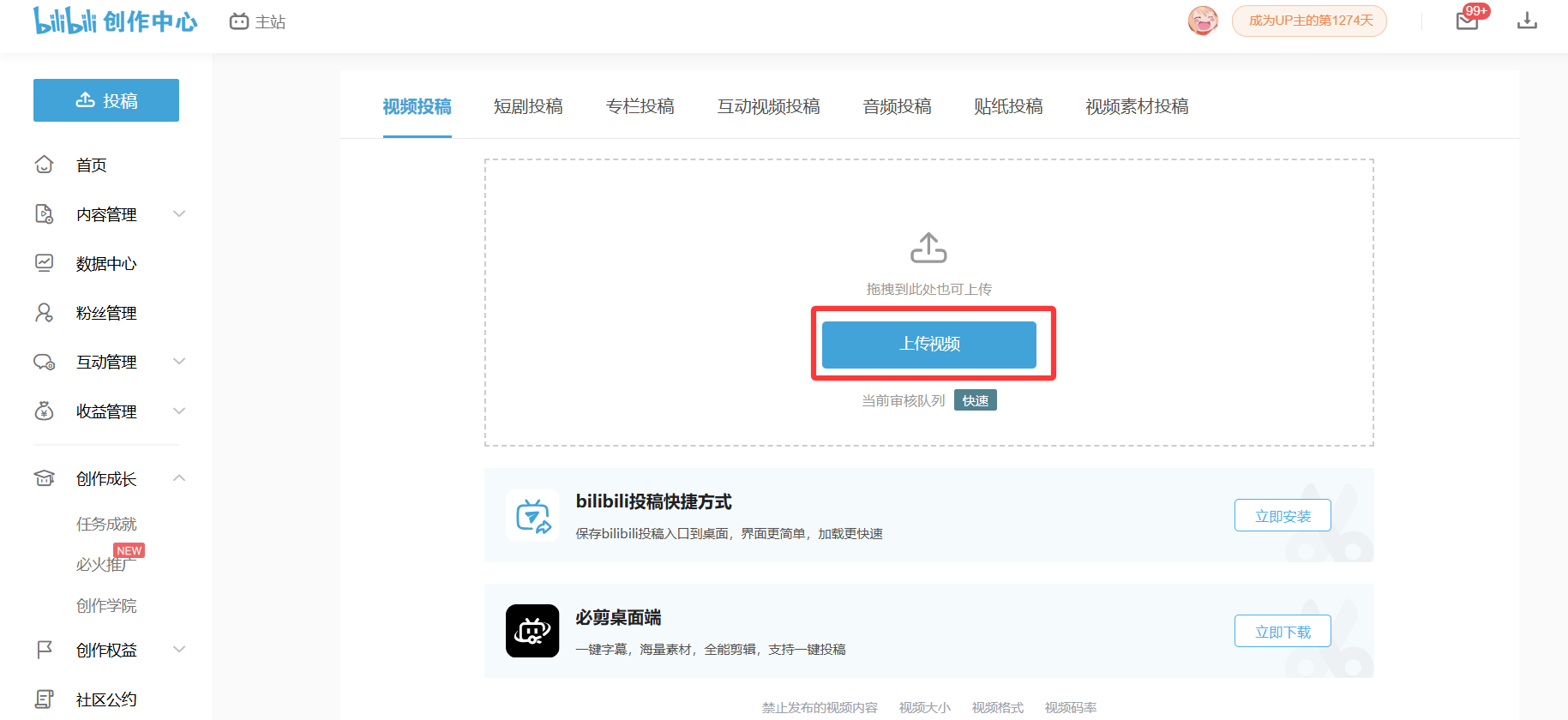
考虑下面的场景,你是一个b站的up主,你想将你本地做好的视频上传到b站中。如果是手动操作,你会怎么做呢?
- 你需要先点击网站中的上传文件按钮
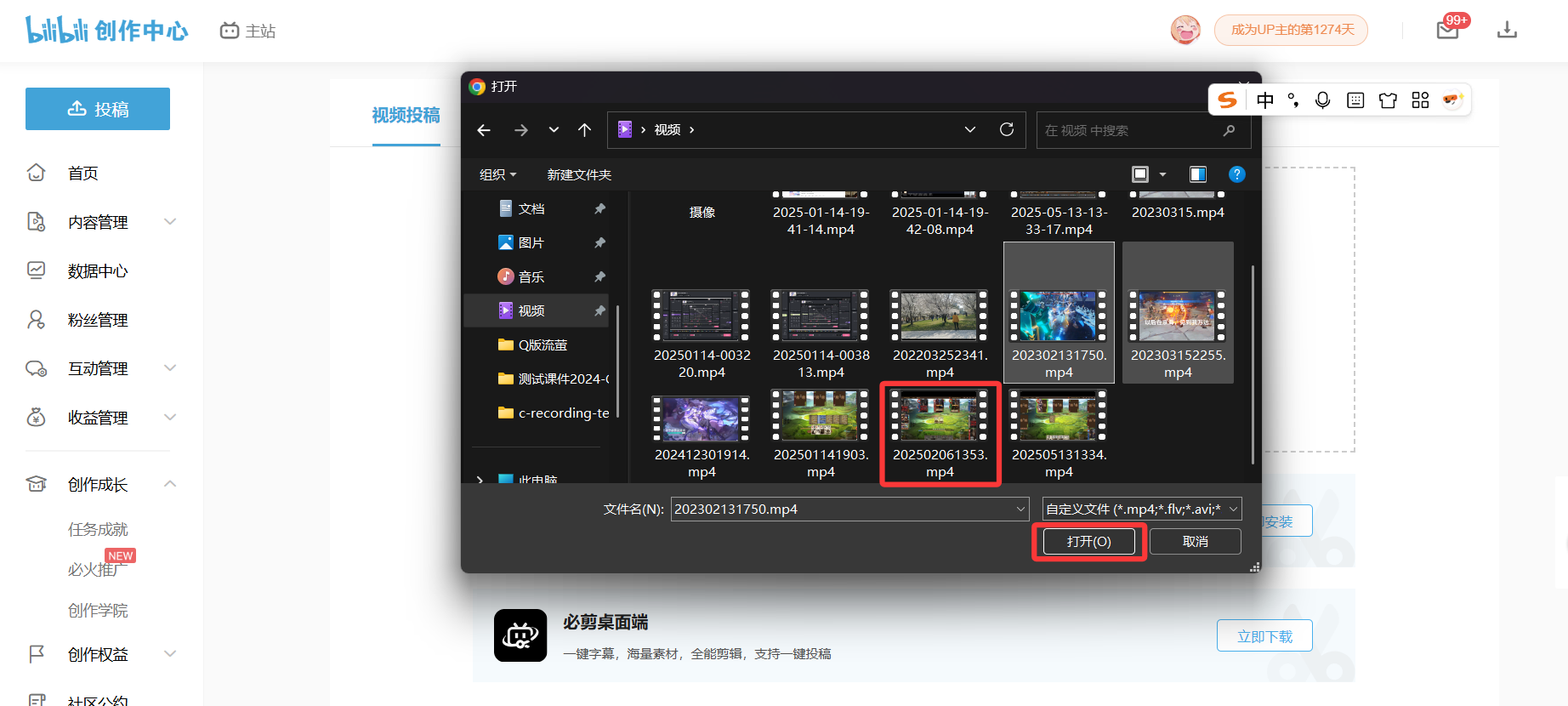
- 然后在弹出的系统文件管理器中选择你要上传的文件,最后点击确定
现在你要自动化实现这一过程,你该怎么做呢?
由于b站要登录,登录之后才能上传数据,我目前的水平还没法做很好的配置,所以我们就来一个最简单的示例
注:这个代码没法运行,因为牵扯到登录的问题,相关代码没写,但是如果不需要登录,代码流程就应该如下图所示
import time
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support import expected_conditions as EC
# 编写自动化脚本,具体步骤
# 1. 打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://member.bilibili.com/platform/upload/video/frame?spm_id_from=333.1007.top_bar.upload")
time.sleep(10)
driver.find_element(By.CSS_SELECTOR, "#video-up-app > div.video-entrance > div.upload-body > div > div.upload-wrp > div > div > div").send_keys("C:\\Users\朱轶凡\\Videos")
driver.quit()
其中我们通过send_keys()方法,可以实现将本地文件夹中的文件上传上来(注意要写完整的文件路径+文件名)
浏览器参数设置
无头模式
什么是无头模式?
指浏览器在运行时不显示图形界面(GUI)的工作方式。简单来说,就是用户看不到浏览器窗口中自动化操作的过程,浏览器,浏览器中所有的网页加载、JavaScript 执行、网络请求等功能都在后台默默运行
如何设置无头模式呢?
自动化打开浏览器默认情况下为有头模式,因为我们想设置无头模式,就必须执行下面的代码
1 options = webdriver.ChromeOptions()
2 options.add_argument("--headless") # 设置参数 --headless:无头模式
3 driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
举个例子,运行下面的脚本,观察这次执行过程中会不会打开crome浏览器?
import time
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support import expected_conditions as EC
ChromeIns=ChromeDriverManager().install()
#浏览器参数配置
options = webdriver.ChromeOptions()
#添加无头模式
options.add_argument("-headless")
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns),options=options)
driver.get("https://www.baidu.com")
print(driver.title)
driver.quit()
运行后我们观察得知,直到程序退出,始终没有打开crome浏览器,

页面加载策略
什么是页面加载策略?页面加载策略有哪些?
我们就通过下面的例子来理解什么是加载策略
页面加载方式主要有三种类型:
| 策略 | 说明 |
|---|---|
| normal | 默认值,等待所有资源下载 |
| eager | DOM 访问已准备就绪,但诸如图像的其他资源可能仍在加载 |
| none | 完全不会阻塞WebDriver |
当你在自动化测试脚本中使用driver.get("https://www.baidu.com")时,如果页面加载策略就是normal(默认就是normal),那就意味着只有页面资源全部加载结束之后,才允许操作页面元素
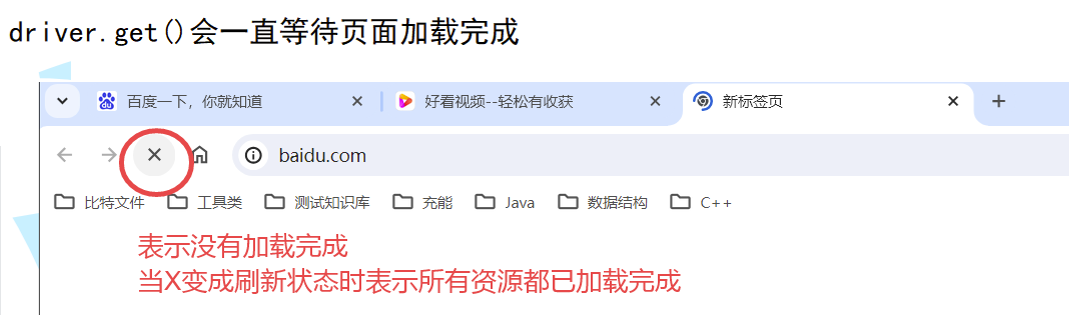
再看下面这个例子,当前页面的框架已经加载完成,但是很多图像还没有加载完毕,此时如果我们的页面加载策略是eager,那driver.get("xxx")语句执行的过程中,不用等图片、CSS 这些非必要资源加载完毕,只需要等待 DOM 结构加载完成,就能点击其中某个视频,进入具体的视频观看网页

如果你的页面加载策略是none,那也不用等等待 DOM 结构加载完成,发送导航请求后立即执行后续代码。当然这样显然是不负责任的,因为很有可能数据还没收到,就执行了后续操作,导致访问失败
为了兼顾稳定性和速度,我们经常喜欢使用eager的页面访问策略
设置页面加载策略
接着上面的例子,如何将当前页面加载策略设置为eager呢?其实很简单,请看下面的代码
import time
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support import expected_conditions as EC
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
options = webdriver.ChromeOptions()
#添加无头模式
# options.add_argument("--headless")
options.page_load_strategy = 'eager'
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns),options=options)
driver.get("https://www.baidu.com")
print(driver.title)
driver.quit()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









