



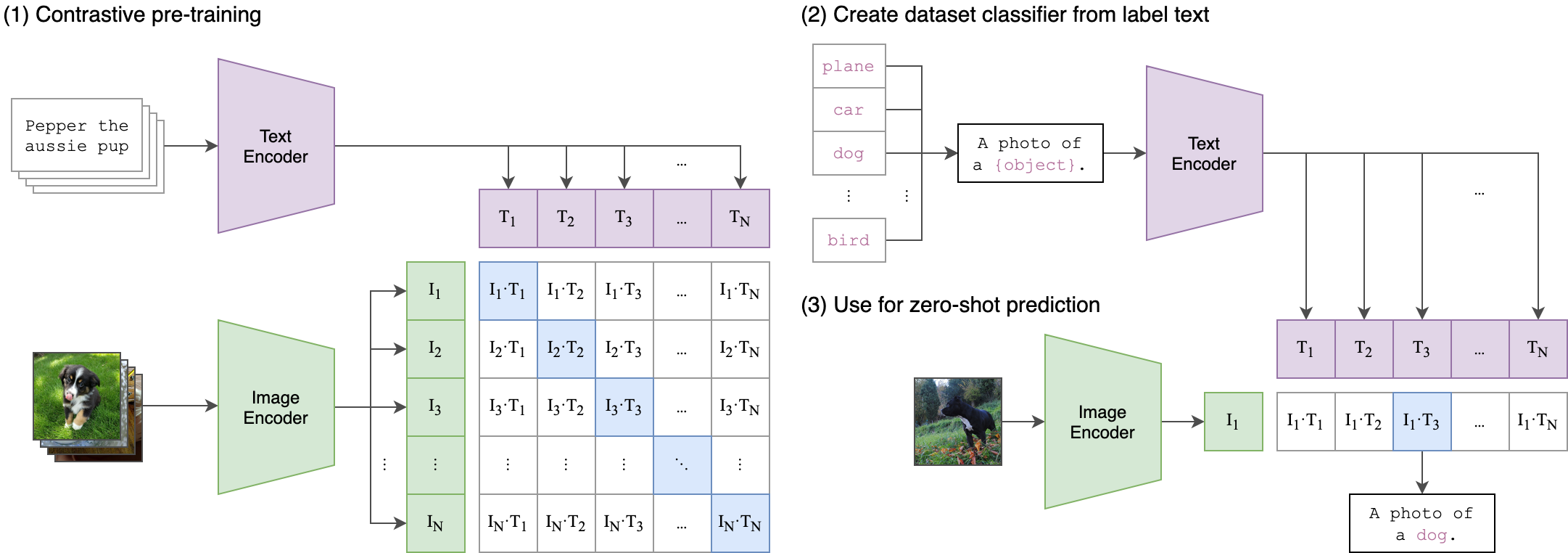
CLIP(对比语言-图像预训练) 是 OpenAI 开发的一种多模态学习架构。它从自然语言监督中学习视觉概念。它通过在包含图像及其相应文本描述的大规模数据集上联合训练模型来弥合文本和视觉数据之间的差距。这类似于 GPT-2 和 GPT-3 的零样本能力。
| 26758 | |
| 3384 |
主要特点
它通过联合训练两个编码器来工作。一个编码器用于图像(Vision Transformer),另一个编码器用于文本(基于 Transformer 的语言模型)。
-
图像编码器:图像编码器从视觉输入中提取显著特征。此编码器将“图像作为输入”并生成高维向量表示。它通常使用 卷积神经网络 (CNN) 架构(如ResNet)来提取图像特征。
-
文本编码器:文本编码器对相应文本描述的语义进行编码。它以“文本标题/标签作为输入”并生成另一个高维向量表示。它通常使用基于 Transformer 的架构(如 Transformer 或 BERT)来处理文本序列。
-
共享嵌入空间:两个编码器在共享向量空间中生成嵌入。这些共享嵌入空间允许 CLIP 比较文本和图像表示并了解它们的底层关系。

















 6413
6413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









