



昨天看到一个文章,说是一个用来托管Wiki、论坛的网络基础设施似乎受到了攻击,运行速度和峰值负载都出了问题。
负责人丹尼斯·舒伯特赶紧去查看流量日志,发现在过去的60天内,收到了1130 万个请求,平均每秒2.19个,这并不多。
但是一看这些请求的User Agent,丹尼斯气得鼻子都歪了。
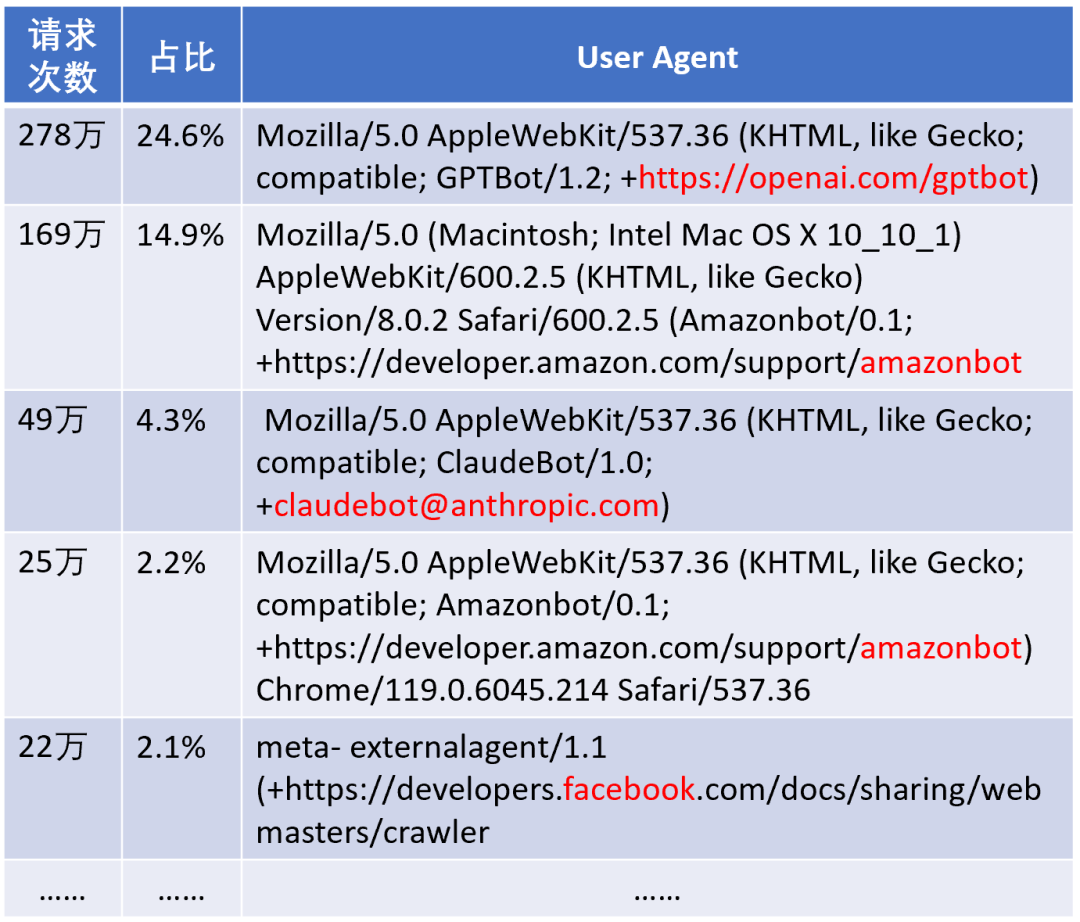
(码农翻身老刘注:如果对这些奇奇怪怪的User Agent感到好奇的话,可以看看我之前写的漫画:浏览器真是一个比一个无耻)

丹尼斯一合计,70%的流量都来自OpenAI、亚马逊、Antropic、Facebook这些大名鼎鼎的人工智能巨头。
更气人的是,这些巨头们的爬虫不是访问了一次就走了,它们每隔6小时就会回来再爬一次!
它们完全无视了robots.txt(规定了搜索引擎抓取工具可以访问网站上的哪些网址),什么数据都要!
ChatGPT 和 Amazon 甚至爬取了 wiki 的整个编辑历史!每个wiki页面的每次编辑都被它们记录下来,这到底要干什么?难道是想了解Wiki上的文本随着时间如何变化?
这种行为让自家系统和数据库负载极重,用户访问缓慢。
丹尼斯赶紧想招应对,他尝试去限制爬虫的访问速率,但是巨头的网络爬虫会迅速地改变IP。
然后又根据User Agent 去阻止爬虫访问,但它们会使用一个非网络爬虫的User Agent。
这实在是没办法了,丹尼斯说,这简直是对整个互联网的DDoS!
这个文章被发到了HackerNews,立刻成为热帖,引发了强烈的共鸣。
网友markerz说:
我的网站被Facebook的 AI 机器人彻底摧毁了,它的请求越来越多,直到我的服务器崩溃....我也修改了robots.txt,但是AI机器人无视了它...
网友buro9说:
我的服务器被Cluade访问了480万次,被Amazon访问了39万次,ChatGPT访问了14.8万次
网友Saris说:
我有一个内容不经常变化的网站(公司网站),总共有几百页面。但同一个人工智能机器人每天会多次扫描整个网站,真不明白它们为什么要这么干。
这些爬虫带来的危害显而易见,首先让这些网站不堪重负,速度变慢,其次会增加网站的运营费用。
更有趣的是,这些网站中有大量是部署在亚马逊、Google,微软的云上的,现在巨头们正在向自己的客户发起“DDoS攻击”并收取流量费用。
网友joshdavham说:
几个月前,我在GCP上部署了一个小型应用,这些愚蠢的AI机器人让我花掉了一大笔钱。
网友oriettaxx说:
上周我们不得不把AWS-RDS数据库和CPU配置翻番,最大的流量就是AmazonBot,这个AmazonBot到底在干什么?!
看到这些消息,我心里是有些疑问的,这些都是IT巨头,如果它们为了获得足够的数据来训练人工智能,忽视robot.txt这些业界的规范,那可真是集体放弃契约精神,不顾道德底线了!
我甚至想,是不是有人打着这些大厂的User Agent的旗号在爬数据呢?我看不到这些爬虫的IP,很难做成准确的判断。
人工智能巨头们创造了数万亿美元的市值,如果真的是不择手段地把别人的数据拿走,真的是太过分了。
“利润私有化,损失社会化”,这就是活生生的案例。
前一段有个说法叫做“互联网已死”,认为网上大部分内容都是机器人产生的,如果这个是真的,那就惨了,机器人创建的内容,被机器人抓取,然后用于训练大模型,AI机器人再到网上发帖...... 这样循环下去,互联网就真的死了。
难道就没有办法来对于这些没有底线的AI爬虫了吗?
有矛就有盾,有种办法叫做Tarpit (焦油坑),本意是让动物会陷入其中并慢慢沉入水面下。这是一种反向延迟攻击,AI爬虫连接后,你的网站要非常缓慢地输出内容(速度也不能太慢,防止AI爬虫超时而断开连接)。当然,输出应该是垃圾。
大模型很厉害,自然也拥有识别垃圾的能力,有人提出了一种更加高级的办法,把所有AI爬虫的请求都路由到另外一个静态的、可以缓存的网页去。
这个网页可以像论坛的页面,内容由较老版本的大模型来生成,让其中包含一些微妙的事实错误,相当于对大模型“投毒”了。
还有人出了更狠的点子:当监测到是AI 爬虫请求以后,提供的内容需要JavaScript才能执行,然后在JavaScript中进行挖矿......
参考资料:
https://pod.geraspora.de/posts/17342163
https://news.ycombinator.com/item?id=42549624
全文完,觉得不错的话点个赞或者在看吧!
近期爆文:
世界上最厉害的协作软件,让程序员痛不欲生,最后被印度人搞走了
1970年以来技术的发展趋势,怪不得程序员35岁就被裁......

















 3545
3545




 到【灌水乐园】发言
到【灌水乐园】发言







