




MapleFE是一个可适配的灵活使用的parser。它最大的特点是能够采用LL parsing算法解析左递归语法生成式。本文是一个简要说明,包括代码结构和使用方法。
MapleFE的组织结构在以往已经有过介绍(见过往知乎文章),此处再重复一下以便于说明。其结构如图一所示,parser是核心算法,通过遍历规则表格实现对左递归语法的解析。此外还包括了几个重要的辅助算法,autogen, recursion detector, lookahead detector,以及两个衍生工具ast2mpl和ast2cpp。
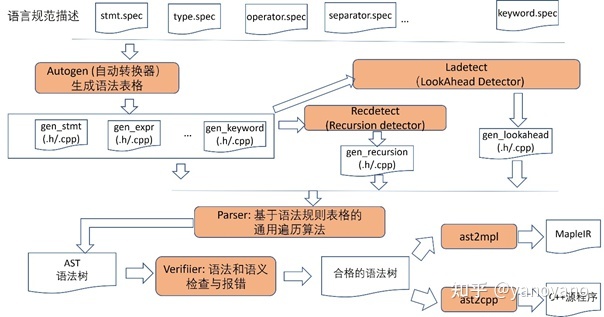
图一、MapleFE结构图
本文重点介绍MapleFE的使用方法。主要包括几个部分。(1)代码结构及部分算法的简要说明;(2)如何实现一个语言的parser;(3)描述语法规范的.spec文件如何写;(4)以TypeScript为例简要介绍如何编译及运行MapleFE。
【一】 代码结构
MapleFE包括几个主要目录如图二所示。

图二、MapleFE目录
1. shared目录存放语言无关的代码,包括了许多核心算法。这些核心代码是parser的灵魂。
a. parser和lexer的算法代码。这是整个前端的核心部位。无论是parser还是lexer都依赖于autogen产生的table(autogen描述见下文),通过遍历table来match合适的语法规则。对于parser来说,为了能够解析左递归,它的算法变得略微复杂,但是基本思想非常简单,就是模拟人脑的思维来处理递归,即,对一个递归语法,一遍又一遍的尝试能不能match当前的token,如果可以,则可以得到一颗match的树,然后开始尝试后面的token,直到失败或者成功为止。如果成功的话,则将每一遍match的结果叠加起来,就构成一个完整的match树(此时并不是语法树,代码中是AppealNode构成的树)。思想虽然简单,具体代码实现却非常复杂。
b. ASTBuilder。代码在ast_builder.cpp。这是在parse成功之后将前面的match树生成语法树(AST)的过程。ASTBuilder同样依赖autogen产生的table,因为在这些table中除了包含语法规则以外,也包括了每条语法规则生成语法树时需要调用的接口。这些接口在书写spec规则时同时书写。具体说明见下文。
c. AST。代码主体在ast.cpp。这是语法树上不同Node的实现代码。完整的一颗语法树由各种节点构成,通过父子关系构成树。所有的Node都继承自最基本的TreeNode。详细代码参考shared/include/ast.h。
2. autogen目录存放autogen工具的代码,这是一个独立的工具,会单独运行。这也是语言无关的。它的功能是读取spec文件,把spec文件里面的每一条语法生成式转换成一个c++的table,并生成相应的.h文件和.cpp文件。比如,Java语法规则生成的table都放在output/java/gen/*.h(cpp),TypeScript生成的table放在output/typescript/gen/*.h(cpp)。
3. recdetect目录存放recdetect工具的代码,这是一个独立的工具,会单独运行。这也是语言无关的。它的功能是读取output里面由autogen生成的cpp文件中的table,即所有语法规则对应的数据表格,通过分析,寻找所有的左递归,并组织成c++表格的形式,输出到文件gen_
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









