




阅读本文需要10分钟
1. 准备
- 共需要三台虚拟机,bigdata11(192.168.130.11),bigdata12,bigdata13(12和13等11配置好再克隆虚拟机即可)
- hadoop安装包
- 修改主机名为bigdata11, vi /etc/sysconfig/network
- 在bigdata11上修改hosts文件,做域名映射,vi /etc/hosts
192.168.130.11 bigdata11 192.168.130.12 bigdata12 192.168.130.13 bigdata13 - 关闭防火墙
#查看防火墙状态 service iptables status #关闭防火墙 service iptables stop #查看防火墙开机启动 chkconfig iptables --list #关闭防火墙开机启动 chkconfig iptables off - 安装ssh客户端
yum install -y openssh-clients
重启生效,reboot - 安装rz(文件拖放工具,可不装,用ftp也行哈)
yum install -y lrzsz
2. 系统环境变量配置
- 上传jdk和hadoop的压缩包
- 解压tar -zxvf xxx.tar.gz
- 修改环境配置 vi /etc/profile
export JAVA_HOME=/root/apps/jdk.1.8
export HADOOP_HOME=/root/apps/hadoop.xxx
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
重新加载,使用输入java即可看到信息:source /etc/profile
验证:输入java,hadoop会有相关帮助信息
3. 修改etc/hadoop下的配置文件
要修改的文件如下
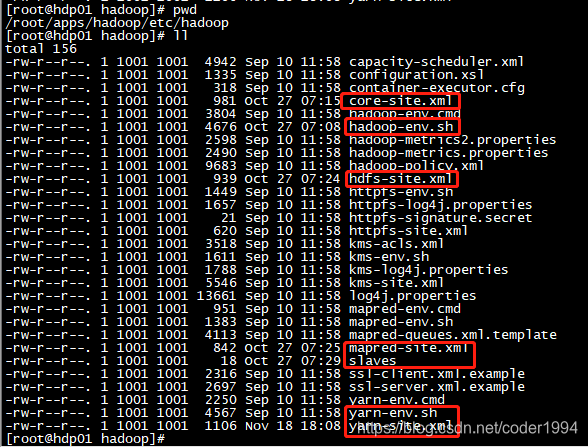
- 修改hadoop-env.sh
export JAVA_HOME=java的根目录
export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop(日志路径) - 修改yarn-env.sh
export JAVA_HOME=java的根目录
export YARN_LOG_DIR=/data/hadoop_repo/logs/yarn(日志路径) - core-site.xml
<!-- 指定hadoop所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://bigdata11:9000</value> </property> <!-- 指定hadoop运行时产生文件的储存目录 --> <property> <name>hadoop.tmp.dir</name> <value>/root/apps/hadoop/temp</value> </property> - hdfs-site.xml
<!-- 指定HDFS副本的数量(最大值为节点数) --> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.secondary.http.address</name> <value>bigdata11:50090</value> </property> - mapred-site.xml
可以修改模板,mv mapred-site.xml.template mapred-site.xml<!-- 指定mr运行在yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> - yarn-site.xml
<!-- 指定yarn的老大(ResourceManager)的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>bigdata11</value> </property> <!-- reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> - 删除sales原有内容,以便一次性启动hadoop,内容如下
bigdata11 bigdata12 bigdata13
请确保配置正确,并保留快照,以防万一
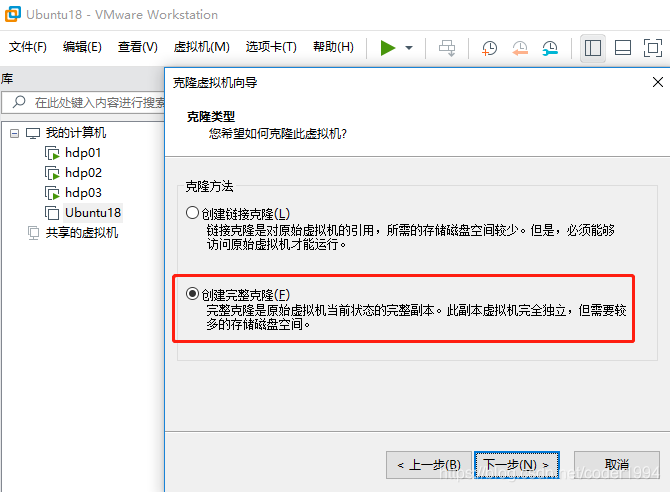
4. 克隆机器
- 用vmware克隆bigdata11,重命名为bigdata12,注意,需要创建完全克隆(即各个克隆体没有关系)
- 修改主机名,vi /etc/sysconfig/network

- 修改虚拟机IP, 记得去掉UUID和MAC地址,vi /etc/sysconfig/network-scripts/ifcfg-eth0
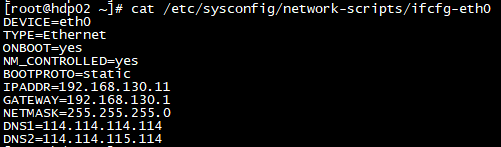
- 删除网卡, rm -f /etc/udev/rules.d/70-persistent-net.rules
- 关闭虚拟机,到vmvare-bigdata12-虚拟机设置-网络适配器-NAT模式的高级-重新生成mac地址
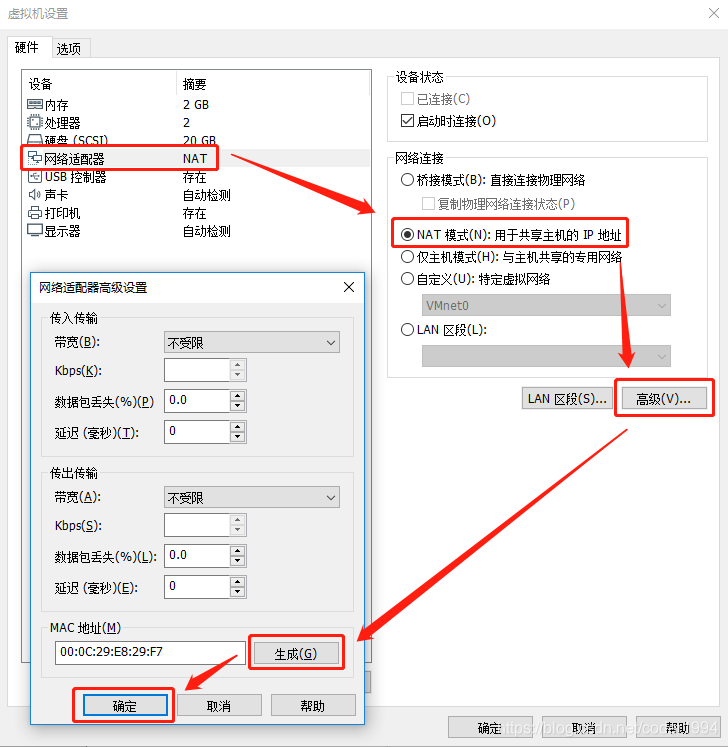
- 打开虚拟机,service network restart
确定主宿互通后,如法炮制克隆bigdata13
5. 设置免密登录
只需要在bigdata11下执行
ssh-keygen -t rsa //声明秘钥,这样在用户的.ssh文件夹下就会产生两个文件
ssh-copy-id -i /root/.ssh/id_rsa.pub root@bigdata11 //为某个机器配置免密登录(bigdata12和bigdata13也要)
6. 启动集群
- 格式化hdfs namenode -format
- 格式化操作不能重复执行,如果一定要重复格式化,带参数-force即可
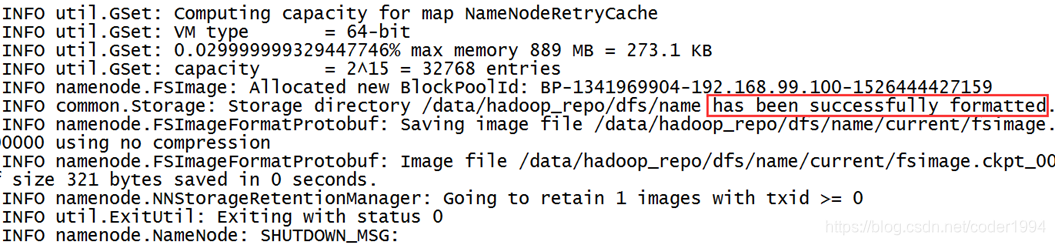
- 格式化操作不能重复执行,如果一定要重复格式化,带参数-force即可
- 启动/停止命令
- 第一种:全部启动集群所有进程
启动:sbin/start-all.sh
停止:sbin/stop-all.sh - 第二种:单独启动hdfs【web端口50070】和yarn【web端口8088】的相关进程
启动:sbin/start-hdfs.sh sbin/start-yarn.sh
停止:sbin/stop-hdfs.sh sbin/stop-yarn.sh
每次重新启动集群的时候使用 - 第三种:单独启动某一个进程
启动hdfs:sbin/hadoop-daemon.sh start (namenode | datanode)
停止hdfs:sbin/hadoop-daemon.sh stop (namenode | datanode)
启动yarn:sbin/yarn-daemon.sh start (resourcemanager | nodemanager)
停止yarn:sbin/yarn-daemon.sh stop(resourcemanager | nodemanager)
用于当某个进程启动失败或者异常down掉的时候,重启进程
- 第一种:全部启动集群所有进程
7. 验证
- 在hdp01输入jps应有
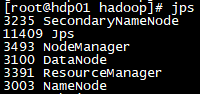
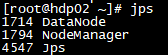
- 在hdp02,03输入jps也应有
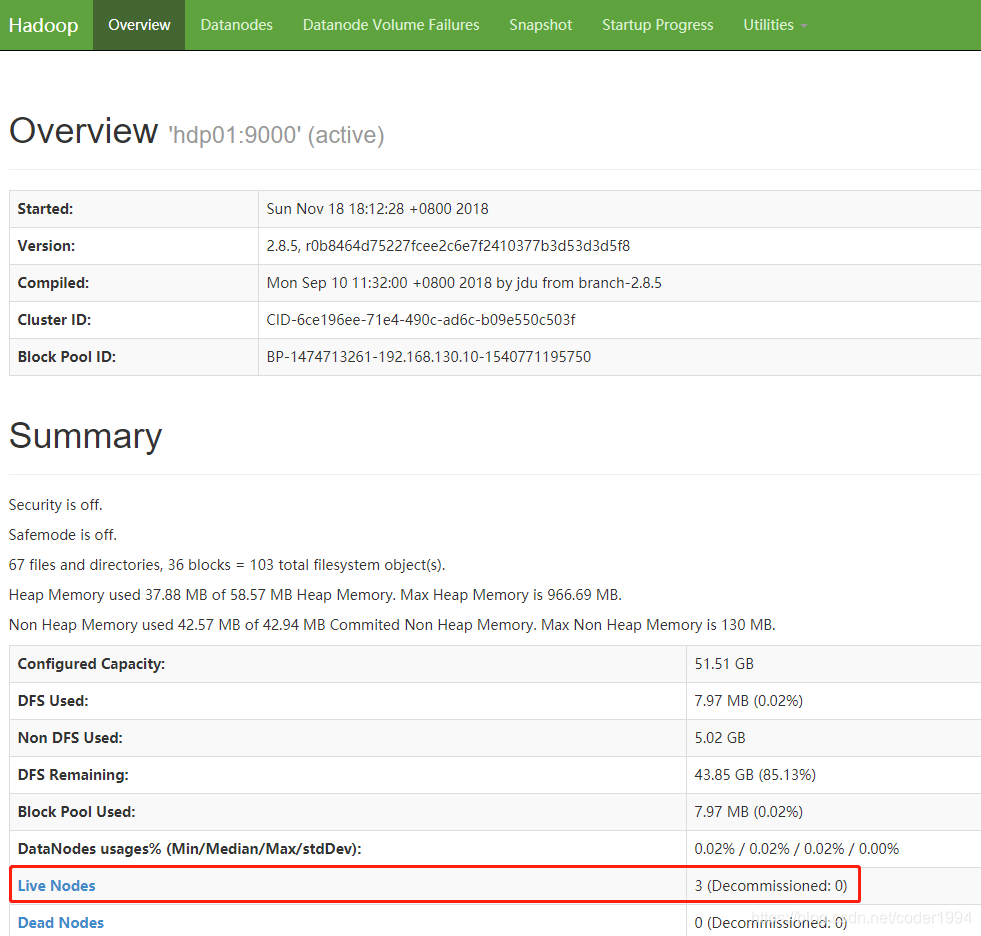
- 访问http://192.168.130.11:50070
- 访问http://192.168.130.11:8088



















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











