






flink本身是专注有状态的无限流处理,有限流处理【batch批次】是无限流处理的一中特殊情况!
应用场景
- 实时ETL
集成流计算现有的诸多数据通道和 SQL 灵活的加工能力,对流式数据进行实时清洗、归并和结构化处理;同时,对离线数仓进行有效的补充和优化,并为数据实时传输提供可计算通道。
- 实时报表
实时化采集、加工流式数据存储;实时监控和展现业务、客户各类指标,让数据化运营实时化。如通过分析订单处理系统中的数据获知销售增长率;通过分析分析运输延迟原因或预测销售量调整库存;
- 监控预警
对系统和用户行为进行实时监测和分析,以便及时发现危险行为,如计算机网络入侵、诈骗预警等
- 在线系统
实时计算各类数据指标,并利用实时结果及时调整在线系统的相关策略,在各类内容投放、智能推送领域有大量的应用,如在客户浏览商品的同时推荐相关商品等
flink主要角色
JobManager
协调分布式执行,它们用来调度 task ,协调检查点 (CheckPoint) ,协调失败时恢复等TaskManager
也称之为worker,主要职责是接收jobmanager协调的task,部署和启动任务,接收上游的数据并处理。同时向resourcemanager反注册自己的资源信息。
ResourceManager
管理集群资源,如Yarn
Dispatcher
作用:提供一个 REST 接口来让我们提交需要执行的应用。一旦一个应用提交执行,Dispatcher 会启动一个 JobManager ,并将应用转交给他。Dispatcher 还会启动一个 webUI 来提供有关作业执行信息注意:某些应用的提交执行的方式,有可能用不到 DispatcherTask一个完整的处理阶段(如map阶段),由多个相同功能的SubTask组成SubTaskTask的并行实例,是实际执行的最小单元。例如设置并行度为3的map操作会产生3个SubTaskslot:TaskManager中的资源格子,每个Slot有独立的内存分配(如4GB)一个Slot可以运行多个SubTask(线程级共享)
不同Job的Slot内存隔离,但共享网络等资源
slot sharing:默认行为:同一Job的上下游SubTask可共享Slot(如map和filter挤在一个Slot)
优势:减少数据传输延迟(同Slot内直接内存交换)提高资源利用率(轻量级操作不独占Slot)
程序架构主要部分
source
本地集合:fromCollection(seq); fromElements();
文件:readTextFile(path);
socket:socketTextStream();
自定义:StreamExecutionEnvironment.addSource(sourceFunction),flink本身提供了许多源,也可以implements SourceFunction方法是为非并行源,或者为并行源 implements ParallelSourceFunction接口,或者extends RichParallelSourceFunction。
RichParallelSourceFunction与ParallelSourceFunction是Flink中用于实现自定义数据源的两种关键接口,主要区别如下:
功能扩展性
- RichParallelSourceFunction继承了RichFunction,提供了
open()和close()方法,支持访问运行时上下文(如并行度、任务ID等),便于资源管理(如数据库连接)7。- ParallelSourceFunction仅标记接口,无额外方法,需自行实现资源管理逻辑2。
并行度支持
- 两者均支持并行执行(通过实现ParallelSourceFunction标记接口)26。
- 但RichParallelSourceFunction通过运行时上下文可动态分配数据分片(如MySQL分页查询)7。
状态管理
- RichParallelSourceFunction可结合检查点机制实现状态一致性,适合有状态数据源(如偏移量记录)5。
- ParallelSourceFunction需自行处理状态持久化4。
典型应用场景
- RichParallelSourceFunction适用于需要复杂初始化或状态管理的场景(如连接外部系统)
- ParallelSourceFunction适合简单无状态数据源(如内存集合)3。
实现复杂度
- RichParallelSourceFunction需实现更多生命周期方法,但开发更规范6。
- ParallelSourceFunction更轻量,但灵活性较低2。
总结:优先选择RichParallelSourceFunction以获得更完善的开发支持,仅在无状态且无需资源管理时考虑ParallelSourceFunction
- 需要访问运行时上下文(如获取并行任务ID)25
- 需管理资源(如数据库连接、文件句柄)310
- 需结合检查点机制实现状态一致性(如Kafka偏移量记录)58
- 典型场景:MySQL分页查询、Kafka消费者、分布式日志采集
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction import org.apache.flink.configuration.Configuration import java.sql.{Connection, DriverManager, ResultSet} class MySQLRichParallelSource extends RichParallelSourceFunction[String] { private var connection: Connection = _ private var isRunning = true override def open(parameters: Configuration): Unit = { // 初始化数据库连接 connection = DriverManager.getConnection( "jdbc:mysql://localhost:3306/test", "user", "password" ) } override def run(ctx: SourceFunction.SourceContext[String]): Unit = { val stmt = connection.createStatement() val rs = stmt.executeQuery("SELECT * FROM sensor_data") while (isRunning && rs.next()) { ctx.collect(rs.getString("value")) // 发射数据 } } override def cancel(): Unit = isRunning = false override def close(): Unit = { if (connection != null) connection.close() } }
- 简单无状态数据生成(如内存集合、随机数流)914
- 无需资源初始化/清理的并行任务115
- 典型场景:模拟传感器数据、内存集合并行读取
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction import scala.util.Random class RandomParallelSource extends ParallelSourceFunction[Int] { private var isRunning = true override def run(ctx: SourceFunction.SourceContext[Int]): Unit = { val rand = new Random() while (isRunning) { ctx.collect(rand.nextInt(100)) // 生成0-100随机数 Thread.sleep(500) } } override def cancel(): Unit = isRunning = false }transformation
- Map
功能:对数据流中的每个元素进行一对一转换14
val dataStream: DataStream[Int] = env.fromElements(1, 2, 3) val mappedStream = dataStream.map(_ * 2) // 输出2,4,6
- FlatMap
功能:将每个元素转换为0个、1个或多个输出元素17
val words = env.fromElements("hello world", "flink streaming") val splitWords = words.flatMap(_.split(" ")) // 输出各单词
- Filter
功能:根据条件过滤数据元素24
val numbers = env.fromElements(1, 2, 3, 4) val evens = numbers.filter(_ % 2 == 0) // 输出2,4
- KeyBy
功能:按指定key对数据进行分区25
case class Sensor(id: String, temp: Double) val sensors = env.fromElements(Sensor("s1", 35.2), Sensor("s2", 28.5)) val keyedStream = sensors.keyBy(_.id)
- Reduce
功能:对分组数据流进行聚合操作59
keyedStream.reduce((s1, s2) => Sensor(s1.id, s1.temp + s2.temp)) // 相同id的温度累加
- Aggregations
功能:内置聚合函数(sum/min/max等)25
keyedStream.sum("temp") // 按key求温度总和
- Window
功能:在数据流上定义时间或计数窗口58
sensors.keyBy(_.id) .window(TumblingProcessingTimeWindows.of(Time.seconds(5))) .sum("temp")
- Union
功能:合并多个同类型数据流48
val stream1 = env.fromElements(1, 2) val stream2 = env.fromElements(3, 4) val merged = stream1.union(stream2) // 输出1,2,3,4
- Join
功能:基于key连接两个数据流89
val streamA = env.fromElements(("a", 1), ("b", 2)) val streamB = env.fromElements(("a", 3), ("b", 4)) streamA.join(streamB) .where(_._1).equalTo(_._1) .window(TumblingEventTimeWindows.of(Time.seconds(5))) .apply((a,b) => (a._1, a._2 + b._2)) // 输出("a",4),("b",6)
- CoFlatMap
功能:连接两个流并共享状态8
val controlStream = env.fromElements("HIGH", "LOW") val dataStream = env.fromElements(1.2, 3.4, 5.6) controlStream.connect(dataStream) .flatMap( (ctrl: String, out: Collector[Double]) => {}, (value: Double, out: Collector[Double]) => { if (currentThreshold == "HIGH") out.collect(value) } )
- ProcessFunction
功能:提供对时间和状态的底层访问
class TempAlertFunction extends ProcessFunction[Sensor, String] { override def processElement( sensor: Sensor, ctx: ProcessFunction[Sensor, String]#Context, out: Collector[String]): Unit = { if (sensor.temp > 100) { out.collect(s"Alert! ${sensor.id} temp=${sensor.temp}") } } }
- Iterate
功能:创建迭代流处理循环
val numbers = env.fromElements(1, 2, 3, 4) val iterated = numbers.iterate( iteration => { val minusOne = iteration.map(_ - 1) val stillGreaterThanZero = minusOne.filter(_ > 0) val lessThanZero = minusOne.filter(_ <= 0) (stillGreaterThanZero, lessThanZero) } )
- Window Apply
功能:对窗口数据应用自定义函数
sensors.keyBy(_.id) .window(TumblingEventTimeWindows.of(Time.seconds(5))) .apply { (key, window, vals, out: Collector[String]) => out.collect(s"$key: ${vals.map(_.temp).sum}") }
- Side Output
功能:将数据分流到侧输出流
val outputTag = OutputTag[String]("side-output") val mainStream = numbers.process(new ProcessFunction[Int, Int] { override def processElement( value: Int, ctx: ProcessFunction[Int, Int]#Context, out: Collector[Int]): Unit = { if (value % 2 != 0) { ctx.output(outputTag, s"Odd: $value") } out.collect(value) } }) val sideStream = mainStream.getSideOutput(outputTag)
- Broadcast
功能:将流广播到所有并行任务8
val ruleStream = env.fromElements("rule1", "rule2").broadcast val dataStream = env.fromElements(1, 2, 3) dataStream.connect(ruleStream) .process(new BroadcastProcessFunction[Int, String, String] { override def processElement( value: Int, ctx: BroadcastProcessFunction[Int, String, String]#ReadOnlyContext, out: Collector[String]): Unit = { val rules = ctx.getBroadcastState(...) // 使用广播规则处理数据 } })完整项目实现示例:
import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.util.Collector object FlinkOperatorsDemo { case class SensorReading(id: String, timestamp: Long, temperature: Double) def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment // 1. 数据源 val sensorData = env.fromElements( SensorReading("sensor1", 1L, 35.6), SensorReading("sensor2", 2L, 28.3), SensorReading("sensor1", 3L, 37.2) ) // 2. 算子演示 val processed = sensorData .filter(_.temperature > 30) // Filter .map(r => (r.id, r.temperature)) // Map .keyBy(_._1) // KeyBy .timeWindow(Time.seconds(5)) // Window .reduce((r1, r2) => (r1._1, r1._2 + r2._2)) // Reduce processed.print() env.execute("Flink Operators Demo") } }代码说明:
- 包含Flink核心算子链式调用演示
- 使用case class定义数据类型
- 展示从数据源到窗口聚合的完整流程
其他重要算子补充说明:
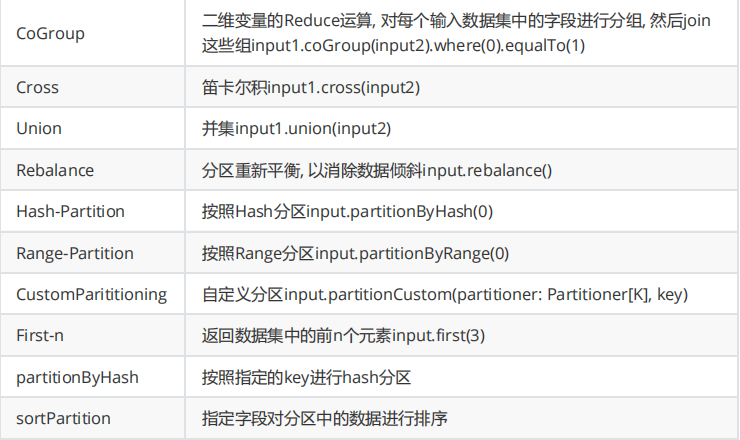
- Fold:已弃用,推荐使用Reduce
- WindowAll:非分组全局窗口
- Project:选择部分字段(仅DataSet API)
- Cross:两个流的笛卡尔积
- CoGroup:分组连接两个数据集
sink
文件: writeAsText(path)
HDFS:
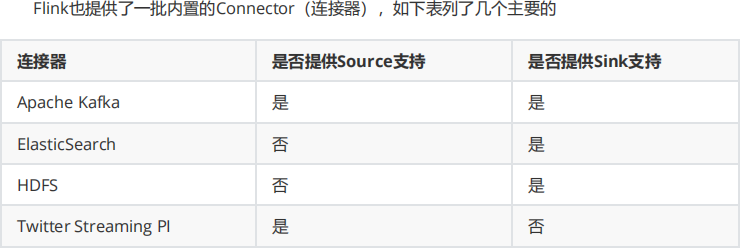
import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink import org.apache.flink.core.fs.Path import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy import java.time.ZoneId object FlinkToHdfs { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment // 1. 创建测试数据源 val dataStream = env.fromElements( "2025-08-20 15:00:00,user1,click", "2025-08-20 15:01:00,user2,purchase", "2025-08-20 15:02:00,user3,view" ) // 2. 配置HDFS输出路径 val hdfsPath = "hdfs://namenode:9000/flink/output" // 3. 创建StreamingFileSink val sink = StreamingFileSink .forRowFormat( new Path(hdfsPath), new SimpleStringEncoder[String]("UTF-8") ) .withBucketAssigner(new DateTimeBucketAssigner[String]( "yyyy-MM-dd--HH", ZoneId.of("UTC") )) .withRollingPolicy( DefaultRollingPolicy.builder() .withRolloverInterval(60 * 60 * 1000) // 1小时滚动一次 .withInactivityInterval(15 * 60 * 1000) // 15分钟不活动则滚动 .withMaxPartSize(128 * 1024 * 1024) // 128MB .build() ) .build() // 4. 添加sink到数据流 dataStream.addSink(sink) env.execute("Flink to HDFS Example") } }kafka: FlinkKafkaProducer
redis:RedisSink
hbase:
自定义:SinkToMySql extends RichSinkFunction
Chain
Operator Chain
数据传输
Flink 在处理任务间的数据传输过程中,采用了缓冲区机制。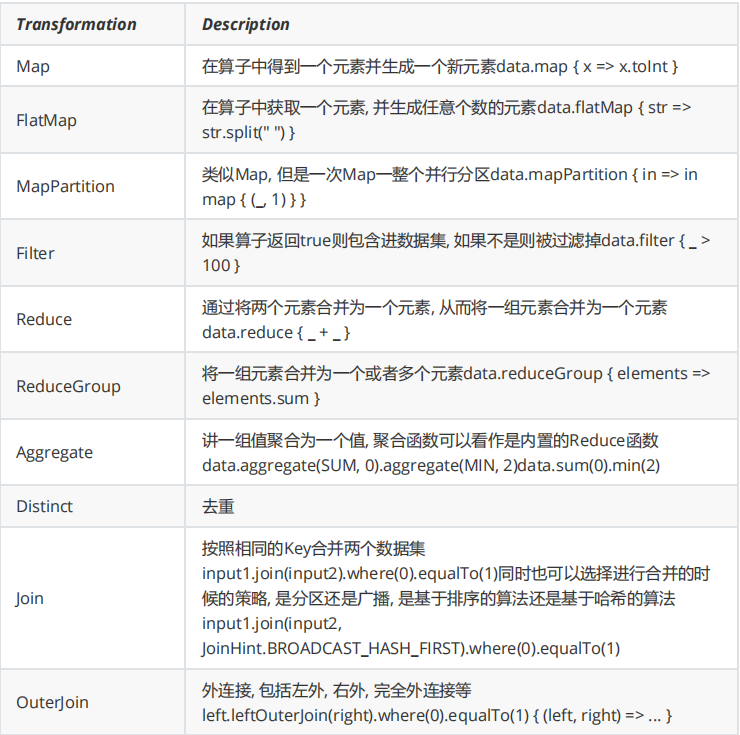
Yarn部署机制
(1)启动一个YARN yarn-session.sh -h /export/servers/flink/bin/yarn-session.sh -n 2 -tm 800 -s 1 -d# -n 表示申请 2 个容器,这里指的就是多少个 taskmanager# -s 表示每个 TaskManager 的 slots 数量# -tm 表示每个 TaskManager 的内存大小# -d 表示以后台程序方式运行如果不想让 Flink YARN 客户端始终运行,那么也可以启动分离的 YARN 会话。该参数被称为 -d 或 --detached。在这种情况下, Flink YARN 客户端只会将 Flink 提交给集群,然后关闭它自己(2) 直接在 YARN 上提交运行 Flink 作业 (Run a Flink job on YARN)
/export/servers/flink/bin/yarn-session.sh -n 2 -tm 800 -s 1 -d# -n 表示申请 2 个容器,这里指的就是多少个 taskmanager# -s 表示每个 TaskManager 的 slots 数量# -tm 表示每个 TaskManager 的内存大小# -d 表示以后台程序方式运行如果不想让 Flink YARN 客户端始终运行,那么也可以启动分离的 YARN 会话。该参数被称为 -d 或 --detached。在这种情况下, Flink YARN 客户端只会将 Flink 提交给集群,然后关闭它自己(2) 直接在 YARN 上提交运行 Flink 作业 (Run a Flink job on YARN)bin/flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 /export/servers/flink/examples/batch/WordCount.jar
# -m jobmanager的地址
# -yn 表示 TaskManager 的个数停止 yarn-cluster :yarn application -kill application_1527077715040_0003rm -rf /tmp/.yarn-properties-root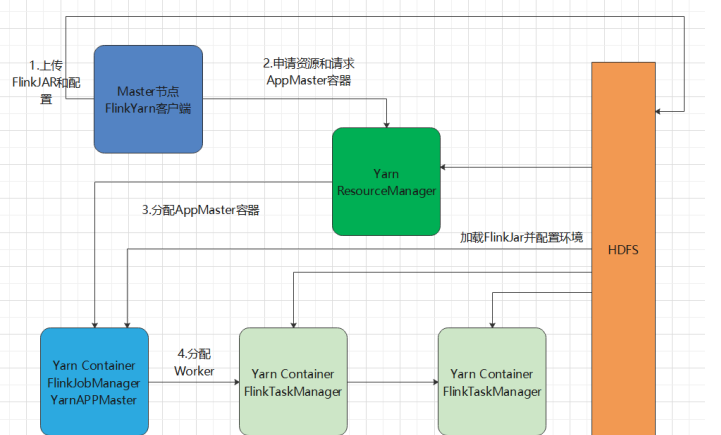
窗口
通俗讲, Window 是用来对一个无限的流设置一个有限的集合,从而在有界的数据集上进行操作的一种机制。流上的集合由Window 来划定范围,比如 “ 计算过去 10 分钟 ” 或者 “ 最后 50 个元素的和 ”分为:时间窗口(TimeWindow)数量窗口(CountWindow)滚动窗口
时间驱动: keyedStream . timeWindow ( Time . seconds ( 10 ))数量驱动: keyedStream.countWindow(3)滑动窗口
时间驱动: keyedStream.timeWindow(Time.seconds(10), Time.seconds(5))数量驱动: keyedStream . countWindow ( 3 , 2 )会话窗口
keyedStream . window ( ProcessingTimeSessionWindows . withGap ( Time . seconds ( 10 )))全局窗口
EventTime[事件时间]
事件发生的时间,例如:点击网站上的某个链接的时间,每一条日志都会记录自己的生成时间。如果以EventTime 为基准来定义时间窗口那将形成 EventTimeWindow,要求消息本身就应该携带EventTime。如果要使用事件时间,要设置: env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //设置使用事件时间IngestionTime[摄入时间]
数据进入 Flink 的时间,如某个 Flink 节点的 source operator 接收到数据的时间,例如:某个 source 消费到kafka 中的数据。如果以IngesingtTime 为基准来定义时间窗口那将形成 IngestingTimeWindow, 以 source 的 systemTime为准ProcessingTime[处理时间]
某个 Flink 节点执行某个 operation 的时间,例如: timeWindow 处理数据时的系统时间,默认的时间属性就是Processing Time如果以ProcessingTime 基准来定义时间窗口那将形成 ProcessingTimeWindow ,以 operator 的systemTime为准水印(水位线)
水位线是为了控制这个事件能不能被处理,如果在水位线允许的事件范围之外,肯定是不会被当前窗口处理的。emitWatermark(当前最大时间 - 乱序允许时间)这个方法200ms周期执行,就是告诉框架只能提交这个时间及之后的时间的事件过来。 当水位线超过窗口结束时间时,对应的窗口才会被触发计算。这种机制确保了:即使数据乱序到达,只要在允许的时间范围内,仍然能被正确处理;超过容忍时间的迟到数据会被丢弃。
窗口的创建是根据事件时间来的,是独立的任务来创建,框架会根据事件时间,将当前事件归到那个窗口。水位线是触发窗口计算,跟窗口创建没关系。
例如:窗口[10:00:00 - 10:00:10),当窗口接收到第一条10:00:10事件,就会创建下一个[10:00:10- 10:00:20),但是这个时候因为水位线,上一个窗口还没被触发计算,只有当水位线时间 >= 10:00:10时,才会被触发计算。
水位线生成器: 事件处理方法,给下游发送水位时间方法(200ms执行一次)
事件时间提取器:提取事件时间
new WatermarkStrategy[OrderDetail] { override def createWatermarkGenerator(context: WatermarkGeneratorSupplier.Context): WatermarkGenerator[OrderDetail] = { new WatermarkGenerator[OrderDetail] { //每来一条数据,都会调用onEvent var maxTimestamp = Long.MinValue var maxOutOfOrderness = 500L; override def onEvent(event: OrderDetail, eventTimestamp: Long, output: WatermarkOutput): Unit = { maxTimestamp = Math.max(maxTimestamp, format.parse(event.orderCreateTime).getTime) } override def onPeriodicEmit(output: WatermarkOutput): Unit = { output.emitWatermark(new Watermark(maxTimestamp - maxOutOfOrderness)) } } } //1.老版本 2. lambda }.withTimestampAssigner(new SerializableTimestampAssigner[OrderDetail] { override def extractTimestamp(element: OrderDetail, recordTimestamp: Long): Long = { format.parse(element.orderCreateTime).getTime } }
整体流程:
- 数据流中每个事件会先经过
extractTimestamp提取时间戳- 然后触发
onEvent方法处理- 最后周期性调用
onPeriodicEmit生成水位线方法调用时机详解:
(1)
extractTimestamp方法:
- 调用时机:每条数据到达时立即调用
- 作用:就像快递员拆包裹看发货日期,从数据中提取事件时间戳
- 示例:
MyEvent("A", 1630000000000)会提取出1630000000000(2)
onEvent方法:
- 调用时机:紧接在
extractTimestamp之后- 作用:像记录最高水位的标尺,比较并保存当前最大时间戳
- 示例:当收到时间戳1000的事件,会更新
currentMaxTimestamp = 1000(3)
onPeriodicEmit方法:
- 调用时机:默认每200ms自动调用一次(类似心跳机制)
- 作用:发出水位线 = 当前最大时间戳 - 允许乱序时间
- 示例:如果
currentMaxTimestamp=5000,maxOutOfOrderness=3000,则发出水位线2000参数说明:
maxOutOfOrderness:相当于"宽容度",设置允许迟到数据的最长时间(如设为3000表示允许3秒内的迟到数据)currentMaxTimestamp:动态变化的变量,始终记录已见数据的最大时间戳工作类比:
想象老师在批改时间乱序提交的作业:
extractTimestamp:查看每份作业的提交日期onEvent:记录目前看到的最晚提交日期onPeriodicEmit:每隔一段时间宣布:"现在开始只接受比(最晚日期-3天)更早的作业"迟到数据处理方法:允许延迟,侧输出流,自定义触发器,全局窗口+延迟合并迟到数据的处理机制
1. 允许延迟(Allowed Lateness)
这是最常用的方式,扩展窗口等待时间:
javaCopy Code
.window(TumblingEventTimeWindows.of(Time.seconds(10))) .allowedLateness(Time.seconds(5)) // 允许5秒延迟
- 运作方式:
- 水位线到达
窗口结束时间时触发初次计算- 在
[窗口结束时间, 窗口结束时间+允许延迟]区间内:
- 新到达的属于该窗口的数据重新触发窗口计算
- 窗口状态持续更新
- 示例:
mermaidCopy Code
timeline title 10秒窗口 + 5秒允许延迟 section 事件时间 00:13 : 水位线到达00:10 → 触发初次计算 00:14 : 迟到数据(事件时间00:09)到达 → 重新触发计算 00:15 : 迟到数据(事件时间00:08)到达 → 再次触发计算 00:16 : 水位线到达00:11 → 窗口正式关闭2. 侧输出流(Side Output)
捕获超过允许延迟的迟到数据:
javaCopy Code
OutputTag<Event> lateTag = new OutputTag<>("late-data"); DataStream<Event> main = stream .keyBy(...) .window(...) .allowedLateness(Time.seconds(3)) .sideOutputLateData(lateTag) // 捕获超时迟到数据 .process(...); // 获取迟到数据流 DataStream<Event> lateStream = main.getSideOutput(lateTag);
- 应用场景:
- 关键业务数据补全(如金融交易)
- 延迟监控和告警
- 数据质量分析
3. 触发器(Trigger)自定义
精细控制计算触发逻辑:
javaCopy Code
.trigger(new ContinuousEventTimeTrigger(20) { @Override public TriggerResult onElement(...) { // 自定义迟到数据处理逻辑 if (isLateData(element)) { updateWindowState(element); // 手动更新窗口状态 return TriggerResult.FIRE; // 立即触发计算 } return super.onElement(...); } })
- 适用场景:
- 特殊业务规则(如证券交易中的尾单处理)
- 动态延迟策略(基于数据量调整)
4. 全局窗口(GlobalWindow)+ 延迟合并
处理无界迟到数据:
javaCopy Code
.window(GlobalWindows.create()) .trigger(PurgingTrigger.of( new LateDataFireTrigger() // 自定义处理所有迟到数据 ))
迟到数据处理流程
mermaidCopy Code
flowchart TD A[数据到达] --> B{事件时间是否在<br/>当前水位线之前?} B -->|是| C[迟到数据] B -->|否| D[正常处理] C --> E{是否在允许延迟内?} E -->|是| F[更新窗口状态并重新触发计算] E -->|否| G{是否配置侧输出?} G -->|是| H[输出到侧输出流] G -->|否| I[直接丢弃]
实际案例:电商订单统计
场景:统计每10分钟的订单总额,容忍3秒延迟,超时订单单独记录
javaCopy Code
// 定义迟到标签 OutputTag<Order> lateOrders = new OutputTag<>("late-orders"); SingleOutputStreamOperator<Double> result = orders .keyBy(Order::getCategory) .window(TumblingEventTimeWindows.of(Time.minutes(10))) .allowedLateness(Time.seconds(3)) .sideOutputLateData(lateOrders) .aggregate(new OrderSumAggregator()); // 处理主结果 result.print(); // 处理超时订单 result.getSideOutput(lateOrders) .map(order -> "LATE_ORDER: " + order) .addSink(new LateOrderSink());数据处理效果:
数据事件时间 处理水位线 处理方式 12:15:07 12:15:10 进入正常窗口 [12:10,12:20) 12:19:58 12:20:05 允许延迟期内 → 更新窗口结果 12:20:02 12:20:08 允许延迟期内 → 再次更新结果 12:20:05 12:20:13 超过延迟期 → 输出到侧输出流
最佳实践建议
允许延迟设置:
- 一般设为网络延迟峰值的 2-3倍(如Kafka延迟监控的P99值)
- 不宜过大(避免状态膨胀)
监控配置:
javaCopy Code
// 监控迟到数据比例 lateDataStream .map(_ => 1L).windowAll(TumblingProcessingTimeWindows.of(Time.hours(1))) .sum(0) .addSink(new LateDataMetricSink());状态清理优化:
javaCopy Code
.withLateFiredPurgingTrigger() // 及时清理已完成窗口状态动态延迟策略(高级):
javaCopy Code
.allowedLateness(ctx => { if (ctx.element().isPriority()) return Time.minutes(5); return Time.seconds(30); })💡 核心原则:水位线决定何时触发计算,允许延迟决定等待迟到数据多久,侧输出决定超时数据的归宿。三者协同实现完整的迟到数据处理机制
状态
Flink中的状态(State)是指算子任务在运行过程中需要记住的信息,这些信息可以用来实现复杂的有状态计算。状态是Flink实现精确一次(exactly-once)语义和故障恢复的基础。
keyed state 键控状态 只能用于keyedStream上
ValueState,MapState,ReducingState,AggregatingState
import org.apache.flink.api.common.functions.RichMapFunction import org.apache.flink.api.common.state._ import org.apache.flink.api.common.typeinfo.TypeInformation import org.apache.flink.configuration.Configuration import org.apache.flink.streaming.api.scala._ object KeyedStateExamples { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment // 示例数据流 val input = env.fromElements( ("user1", 10), ("user2", 5), ("user1", 20), ("user3", 8), ("user2", 15) ) // 1. ValueState示例 val valueStateResult = input.keyBy(_._1) .map(new ValueStateExample) .print("ValueState结果") // 2. ListState示例 val listStateResult = input.keyBy(_._1) .map(new ListStateExample) .print("ListState结果") // 3. MapState示例 val mapStateResult = input.keyBy(_._1) .map(new MapStateExample) .print("MapState结果") // 4. ReducingState示例 val reducingStateResult = input.keyBy(_._1) .map(new ReducingStateExample) .print("ReducingState结果") // 5. AggregatingState示例 val aggregatingStateResult = input.keyBy(_._1) .map(new AggregatingStateExample) .print("AggregatingState结果") env.execute("Keyed State Examples") } } // 1. ValueState实现 class ValueStateExample extends RichMapFunction[(String, Int), (String, Int)] { private var state: ValueState[Int] = _ override def open(parameters: Configuration): Unit = { val stateDesc = new ValueStateDescriptor[Int]( "valueState", TypeInformation.of(classOf[Int]) ) state = getRuntimeContext.getState(stateDesc) } override def map(value: (String, Int)): (String, Int) = { val current = Option(state.value()).getOrElse(0) val newValue = current + value._2 state.update(newValue) (value._1, newValue) } } // 2. ListState实现 class ListStateExample extends RichMapFunction[(String, Int), (String, List[Int])] { private var state: ListState[Int] = _ override def open(parameters: Configuration): Unit = { val stateDesc = new ListStateDescriptor[Int]( "listState", TypeInformation.of(classOf[Int]) ) state = getRuntimeContext.getListState(stateDesc) } override def map(value: (String, Int)): (String, List[Int]) = { state.add(value._2) (value._1, state.get().asScala.toList) } } // 3. MapState实现 class MapStateExample extends RichMapFunction[(String, Int), (String, Map[String, Int])] { private var state: MapState[String, Int] = _ override def open(parameters: Configuration): Unit = { val stateDesc = new MapStateDescriptor[String, Int]( "mapState", TypeInformation.of(classOf[String]), TypeInformation.of(classOf[Int]) ) state = getRuntimeContext.getMapState(stateDesc) } override def map(value: (String, Int)): (String, Map[String, Int]) = { state.put(value._1, value._2) (value._1, state.entries().asScala.map(e => e.getKey -> e.getValue).toMap) } } // 4. ReducingState实现 class ReducingStateExample extends RichMapFunction[(String, Int), (String, Int)] { private var state: ReducingState[Int] = _ override def open(parameters: Configuration): Unit = { val stateDesc = new ReducingStateDescriptor[Int]( "reducingState", (a: Int, b: Int) => a + b, // ReduceFunction TypeInformation.of(classOf[Int]) ) state = getRuntimeContext.getReducingState(stateDesc) } override def map(value: (String, Int)): (String, Int) = { state.add(value._2) (value._1, state.get()) } } // 5. AggregatingState实现 class AggregatingStateExample extends RichMapFunction[(String, Int), (String, Double)] { private var state: AggregatingState[Int, Double] = _ override def open(parameters: Configuration): Unit = { val stateDesc = new AggregatingStateDescriptor[Int, (Int, Int), Double]( "aggregatingState", new AverageAggregate, TypeInformation.of(classOf[(Int, Int)]), TypeInformation.of(classOf[Double]) ) state = getRuntimeContext.getAggregatingState(stateDesc) } override def map(value: (String, Int)): (String, Double) = { state.add(value._2) (value._1, state.get()) } } // 用于AggregatingState的聚合函数 class AverageAggregate extends AggregateFunction[Int, (Int, Int), Double] { override def createAccumulator(): (Int, Int) = (0, 0) override def add(value: Int, accumulator: (Int, Int)): (Int, Int) = { (accumulator._1 + value, accumulator._2 + 1) } override def getResult(accumulator: (Int, Int)): Double = { accumulator._1.toDouble / accumulator._2 } override def merge(a: (Int, Int), b: (Int, Int)): (Int, Int) = { (a._1 + b._1, a._2 + b._2) } }算子状态
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor} import org.apache.flink.runtime.state.{FunctionInitializationContext, FunctionSnapshotContext} import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction import org.apache.flink.streaming.api.functions.source.SourceFunction class BufferingSource(threshold: Int) extends SourceFunction[String] with CheckpointedFunction { private var isRunning = true private var bufferedElements = List[String]() private var checkpointedState: ListState[String] = _ override def run(ctx: SourceFunction.SourceContext[String]): Unit = { while (isRunning) { bufferedElements ::= s"element-${System.currentTimeMillis()}" if (bufferedElements.size >= threshold) { bufferedElements.reverse.foreach(ctx.collect) bufferedElements = Nil } Thread.sleep(100) } } override def snapshotState(context: FunctionSnapshotContext): Unit = { checkpointedState.update(bufferedElements.asJava) } override def initializeState(context: FunctionInitializationContext): Unit = { checkpointedState = context.getOperatorStateStore.getListState( new ListStateDescriptor[String]("buffered-elements", classOf[String])) if (context.isRestored) { bufferedElements = checkpointedState.get().asScala.toList } } }class UnionListSource extends SourceFunction[Int] with CheckpointedFunction { private var checkpointedState: ListState[Int] = _ private var toEmit = (1 to 100).toList override def run(ctx: SourceFunction.SourceContext[Int]): Unit = { toEmit.foreach { num => ctx.collect(num) Thread.sleep(10) } } override def snapshotState(context: FunctionSnapshotContext): Unit = { checkpointedState.update(toEmit.asJava) } override def initializeState(context: FunctionInitializationContext): Unit = { checkpointedState = context.getOperatorStateStore.getUnionListState( new ListStateDescriptor[Int]("union-state", classOf[Int])) if (context.isRestored) { toEmit = checkpointedState.get().asScala.toList } } }import org.apache.flink.api.common.state.{MapStateDescriptor, BroadcastState} import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction import org.apache.flink.util.Collector class DynamicFilterFunction extends BroadcastProcessFunction[String, String, String] { private final val ruleDescriptor = new MapStateDescriptor[String, String]("rules", classOf[String], classOf[String]) override def processElement( value: String, ctx: ReadOnlyContext, out: Collector[String]): Unit = { val rule = ctx.getBroadcastState(ruleDescriptor).get("filter") if (rule == null || value.contains(rule)) { out.collect(value) } } override def processBroadcastElement( rule: String, ctx: Context, out: Collector[String]): Unit = { ctx.getBroadcastState(ruleDescriptor).put("filter", rule) } }
广播状态
状态存储
状态生存时间

CEP

















 612
612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









