







HDFS读写解析
读流程
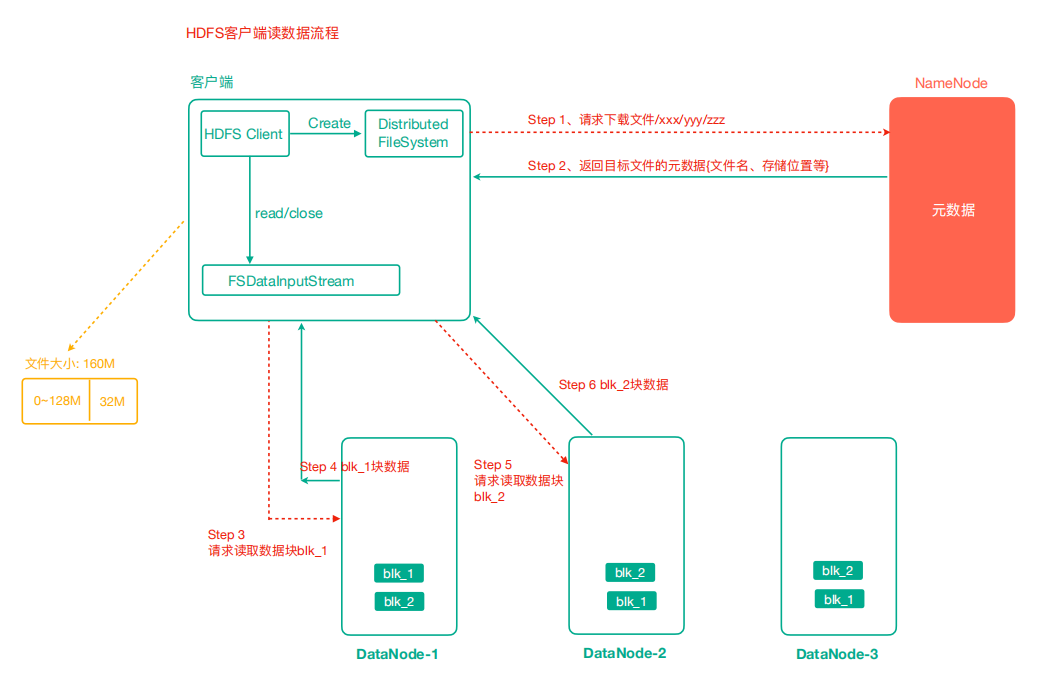
- 客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
- 挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
- DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
- 客户端以Packet 为单位接收,先在本地缓存,然后写入目标文件。
写流程
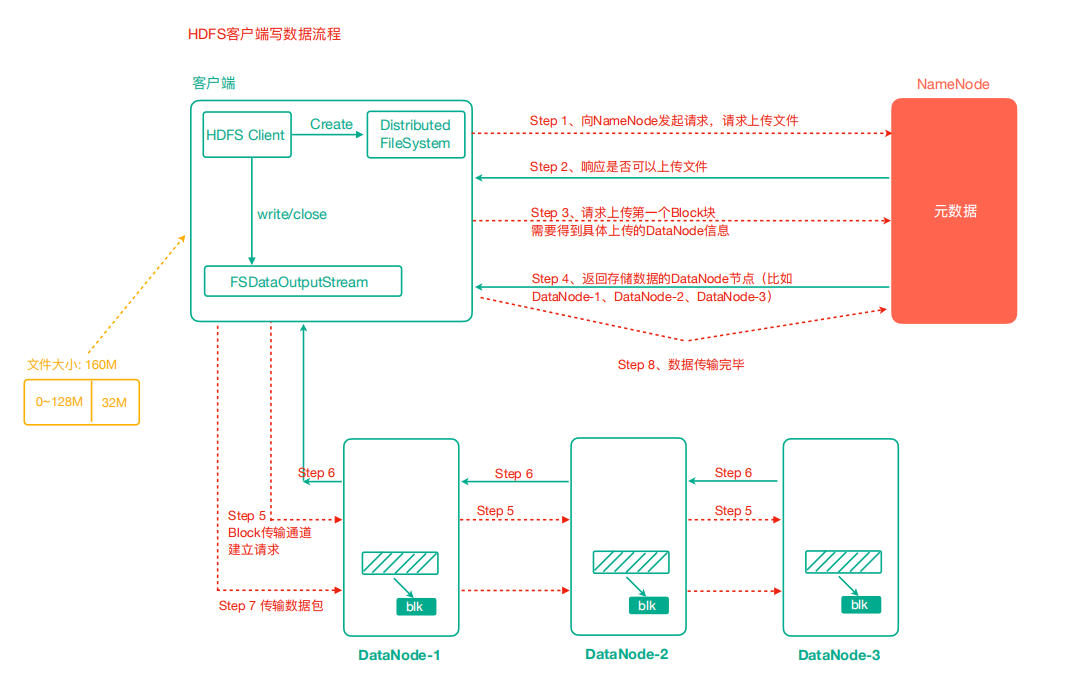
- 客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件 是否已存在,父目录是否存在。
- NameNode返回是否可以上传。
- 客户端请求第一个 Block上传到哪几个DataNode服务器上。
- NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
- 客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后 dn2调用dn3,将这个通信管道建立完成。
- dn1、dn2、dn3逐级应答客户端。
- 客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个确认队列等待确认。
- 当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
HDFS元数据管理机制
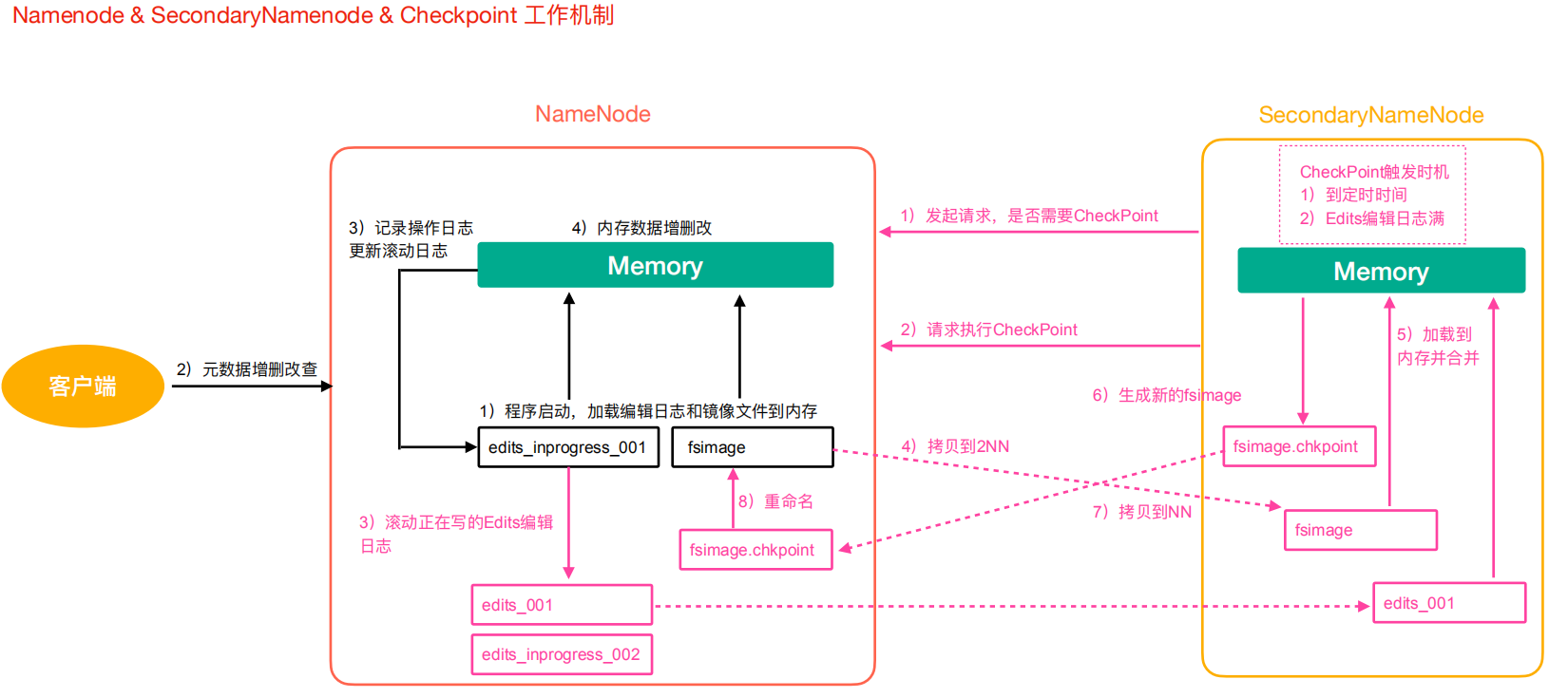
第一阶段:NameNode启动
- 第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加
- 载编辑日志和镜像文件到内存。
- 客户端对元数据进行增删改的请求。
- NameNode记录操作日志,更新滚动日志。
- NameNode在内存中对数据进行增删改。
第二阶段:Secondary NameNode工作
- Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否执行检查点操作结果。
- Secondary NameNode请求执行CheckPoint。
- NameNode滚动正在写的Edits日志。
- 将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
- Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
- 生成新的镜像文件fsimage.chkpoint。
- 拷贝fsimage.chkpoint到NameNode。
- NameNode将fsimage.chkpoint重新命名成fsimage。
checkpoint周期
vim hdfs-default.xml
<!-- 定时一小时 -->
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
<!-- 一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次 -->
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property>Hadoop的限额与归档以及集群安全模式
HDFS文件的限额配置
允许我们以文件大小或者文件个数来限制我们在某个目录下上传的文件数量或者文件内容总量,以便达到我们类似百度网盘网盘等限制每个用户允许上传的最大的文件的量
数量限额
hdfs dfs -mkdir -p /user/root/lxq #创建hdfs文件夹
hdfs dfsadmin -setQuota 2 /user/root/lxq# 给该文件夹下面设置最多上传两个文件,上传文件,发现只能上传一个文件
hdfs dfsadmin -clrQuota /user/root/lxq# 清除文件数量限制空间大小限额
hdfs dfsadmin -setSpaceQuota 4k /user/root/lxq # 限制空间大小4KB
#上传超过4Kb的文件大小上去提示文件超过限额
hdfs dfs -put /export/softwares/xxx.tar.gz /user/root/lxq
hdfs dfsadmin -clrSpaceQuota /user/root/lxq #清除空间限额
#查看hdfs文件限额数量
hdfs dfs -count -q -h /user/root/lxqHDFS的安全模式
安全模式是 HDFS 所处的一种特殊状态,在这种状态下,文件系统只接 受读数据请求,而不接受删除、修改等变更请求 。在 NameNode 主节点启动时, HDFS 首先进入安全模式, DataNode 在启动的时候会向NameNode 汇报可用的 block 等状态,当整个系统达到安全标准时, HDFS 自动离开安全模式。如果HDFS 出于安全模式下,则文件 block 不能进行任何的副本复制操作,因此达到最小的副本数量要求是基于DataNode 启动时的状态来判定的,启动时不会再做任何复制(从而达到最小副本数量要求),HDFS 集群刚启动的时候,默认 30S 钟的时间是出于安全期的,只有过了30S之后,集群脱离了安全期,然后才可以对集群进行操作。
hdfs dfsadmin -safemodeHadoop归档技术
主要解决 HDFS 集群存在大量小文件的问题。由于大量小文件会占用NameNode 的内存,因此对于 HDFS 来说存储大量小文件造成 NameNode内存资源的浪费!Hadoop 存档文件 HAR 文件,是一个更高效的文件存档工具, HAR 文件是由一组文件通过 archive工具创建而来,在减少了 NameNode 的内存使用的同时,可以对文件进行透明的访问,通俗来说就是 HAR 文件对 NameNode 来说是一个文件减少了内存的浪费,对于实际操作处理文件依然是一个一个独立的文件。
[root@linux121 hadoop-2.9.2]$ bin/hadoop archive -archiveName input.har –p /user/root/input /user/root/output查看归档
[root@linux121 hadoop-2.9.2]$ hadoop fs -lsr /user/root/output/input.har
[root@linux121 hadoop-2.9.2]$ hadoop fs -lsr har:///user/root/output/input.har解归档文件
[root@linux121 hadoop-2.9.2]$ hadoop fs -cp har:///user/root/output/input.har/* /user/rootMR思想
自定义Mapper类
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 输出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}自定义Reduce类
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountReducer extends Reducer<Text, IntWritable, Text,
IntWritable> {
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
// 1 累加求和
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2 输出
v.set(sum);
context.write(key,v);
}
}import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
// 1 实现writable接口
public class SpeakBean implements Writable {
private long selfDuration;
private long thirdPartDuration;
private long sumDuration;
//2 反序列化时,需要反射调用空参构造函数,所以必须有
public SpeakBean() {
}
public SpeakBean(long selfDuration, long thirdPartDuration) {
this.selfDuration = selfDuration;
this.thirdPartDuration = thirdPartDuration;
this.sumDuration=this.selfDuration+this.thirdPartDuration;
}
//3 写序列化方法
public void write(DataOutput out) throws IOException {
out.writeLong(selfDuration);
out.writeLong(thirdPartDuration);
out.writeLong(sumDuration);
}
//4 反序列化方法
//5 反序列化方法读顺序必须和写序列化方法的写顺序必须一致
public void readFields(DataInput in) throws IOException {
this.selfDuration = in.readLong();
this.thirdPartDuration = in.readLong();
this.sumDuration = in.readLong();
}
// 6 编写toString方法,方便后续打印到文本
@Override
public String toString() {
return selfDuration +
"\t" + thirdPartDuration +
"\t" + sumDuration ;
}
public long getSelfDuration() {
return selfDuration;
}
public void setSelfDuration(long selfDuration) {
this.selfDuration = selfDuration;
}
public long getThirdPartDuration() {
return thirdPartDuration;
}
public void setThirdPartDuration(long thirdPartDuration) {
this.thirdPartDuration = thirdPartDuration;
}
public long getSumDuration() {
return sumDuration;
}
public void setSumDuration(long sumDuration) {
this.sumDuration = sumDuration;
}
public void set(long selfDuration, long thirdPartDuration) {
this.selfDuration = selfDuration;
this.thirdPartDuration = thirdPartDuration;
this.sumDuration=this.selfDuration+this.thirdPartDuration;
}
}mr原理
mapTask机制
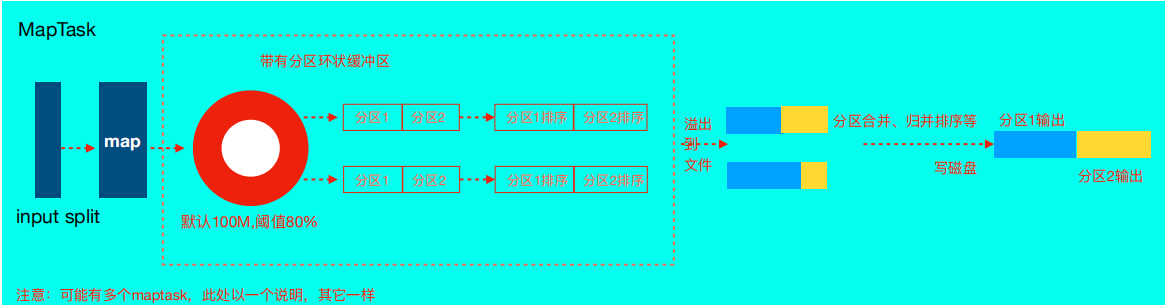
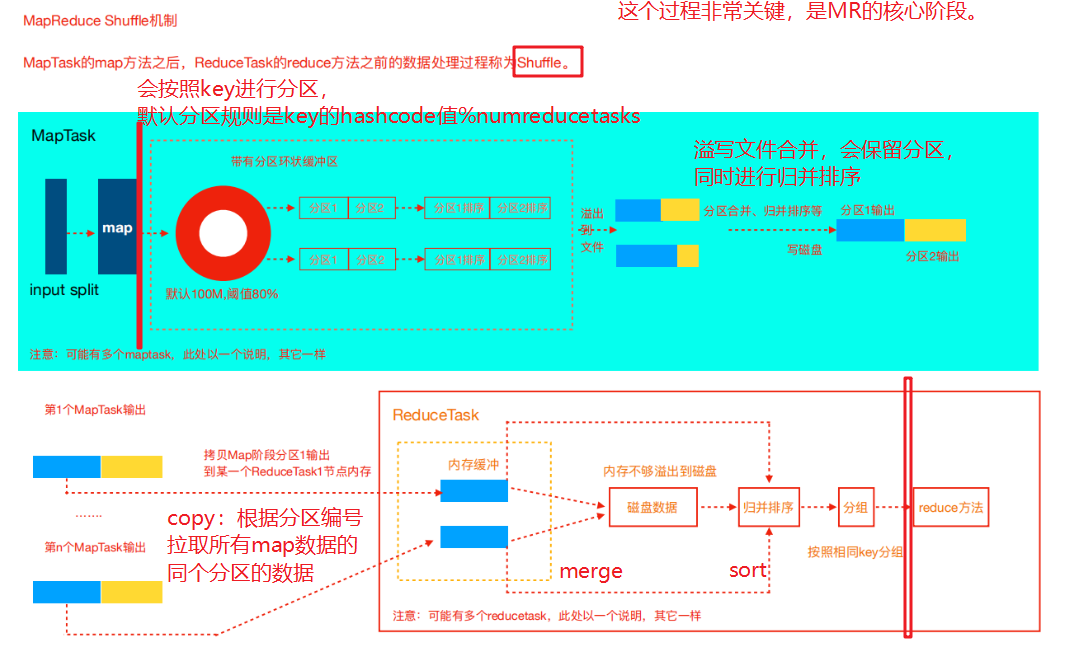
详细步骤:1. 首先,读取数据组件 InputFormat (默认 TextInputFormat )会通过 getSplits 方法对输入目录中文件进行逻辑切片规划得到splits ,有多少个 split 就对应启动多少个 MapTask 。 split 与 block 的对应关系默认是一对一。2. 将输入文件切分为 splits 之后,由 RecordReader 对象(默认 LineRecordReader )进行读取,以 \n作为分隔符,读取一行数据,返回<key , value> 。 Key 表示每行首字符偏移值, value 表示这一行文本内容。3. 读取 split 返回 <key,value> ,进入用户自己继承的 Mapper 类中,执行用户重写的 map 函数。 RecordReader读取一行这里调用一次。4. map 逻辑完之后,将 map 的每条结果通过 context.write 进行 collect 数据收集。在 collect 中,会先对其进行分区处理,默认使用HashPartitioner 。MapReduce 提供 Partitioner 接口,它的作用就是根据 key 或 value 及 reduce 的数量来决定当前的这对 输出数据最终应该交由哪个 reduce task 处理。默认对 key hash 后再以 reduce task 数量取模。默认的 取模方式只是为了平均 reduce 的处理能力,如果用户自己对 Partitioner 有需求,可以订制并设置到 job 上。5. 接下来,会将数据写入内存,内存中这片区域叫做环形缓冲区,缓冲区的作用是批量收集 map 结果,减少磁盘IO 的影响。我们的 key/value 对以及 Partition 的结果都会被写入缓冲区。当然写入之前,key 与 value 值都会被序列化成字节数组。
- 环形缓冲区其实是一个数组,数组中存放着key、value的序列化数据和key、value的元数据信息,包括partition、key的起始位置、value的起始位置以及value的长度。环形结构是一个抽象概念。
- 缓冲区是有大小限制,默认是100MB。当map task的输出结果很多时,就可能会撑爆内存,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写。这个溢写是由单独线程来完成,不影响往缓冲区写map结果的线程。溢写线程启动时不应该阻止map的结果输出,所以整个缓冲区有个溢写的比例spill.percent。这个比例默认是0.8,也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),溢写线程启动,锁定这80MB的内存,执行溢写过程。Map task的输出结果还可以往剩下的20MB内存中写,互不影响。
6 、当溢写线程启动后,需要对这 80MB 空间内的 key 做排序 (Sort) 。排序是 MapReduce 模型默认的行为 !
- 如果job设置过Combiner,那么现在就是使用Combiner的时候了。将有相同key的key/value对的value加起来,减少溢写到磁盘的数据量。Combiner会优化MapReduce的中间结果,所以它在整个模型中会多次使用。
- 那哪些场景才能使用Combiner呢?从这里分析,Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。Combiner的使用一定得慎重,如果用好,它对job执行效率有帮助,反之会影响reduce的最终结果。
7. 合并溢写文件:每次溢写会在磁盘上生成一个临时文件(写之前判断是否有 combiner ),如果map的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个临时文件存在。当整个数据处理结束之后开始对磁盘中的临时文件进行merge 合并,因为最终的文件只有一个,写入磁盘,并且为这个文件提供了一个索引文件,以记录每个reduce 对应数据的偏移量。至此 map 整个阶段结束 !!

Reduce机制
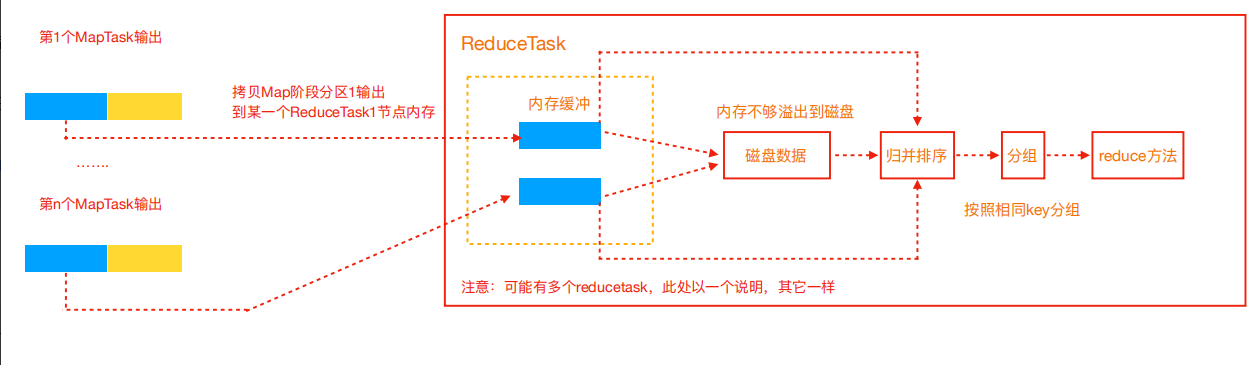
Reduce 大致分为 copy 、 sort 、 reduce 三个阶段,重点在前两个阶段。 copy 阶段包含一个eventFetcher 来获取已完成的 map 列表,由 Fetcher 线程去 copy 数据,在此过程中会启动两个 merge 线程,分别为inMemoryMerger 和 onDiskMerger ,分别将内存中的数据 merge 到磁盘和将磁盘中的数据进行merge 。待数据 copy 完成之后, copy 阶段就完成了,开始进行 sort 阶段, sort 阶段主要是执行finalMerge操作,纯粹的 sort 阶段,完成之后就是 reduce 阶段,调用用户定义的 reduce 函数进行处理。详细步骤
- Copy阶段,简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求maptask获取属于自己的文件。
- Merge阶段。这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活。merge有三种形式:内存到内存;内存到磁盘;磁盘到磁盘。默认情况下第一种形式不启用。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的文件。
- 合并排序。把分散的数据合并成一个大的数据后,还会再对合并后的数据排序。
- 对排序后的键值对调用reduce方法,键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对,最后把这些输出的键值对写入到HDFS文件中。
Shuffle机制
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class CustomPartitioner extends Partitioner<Text,PartitionBean> {
@Override
public int getPartition(Text text, PartitionBean partitionBean, int
numPartitions) {
int partition=0;
final String appkey = text.toString();
if(appkey.equals("kar")){
partition=1;
}else if(appkey.equals("pandora")){
partition=2;
}else{
partition=0;
}
return partition;
}
}数据倾斜通用解决方案:对key增加随机数。
YARN工作机制
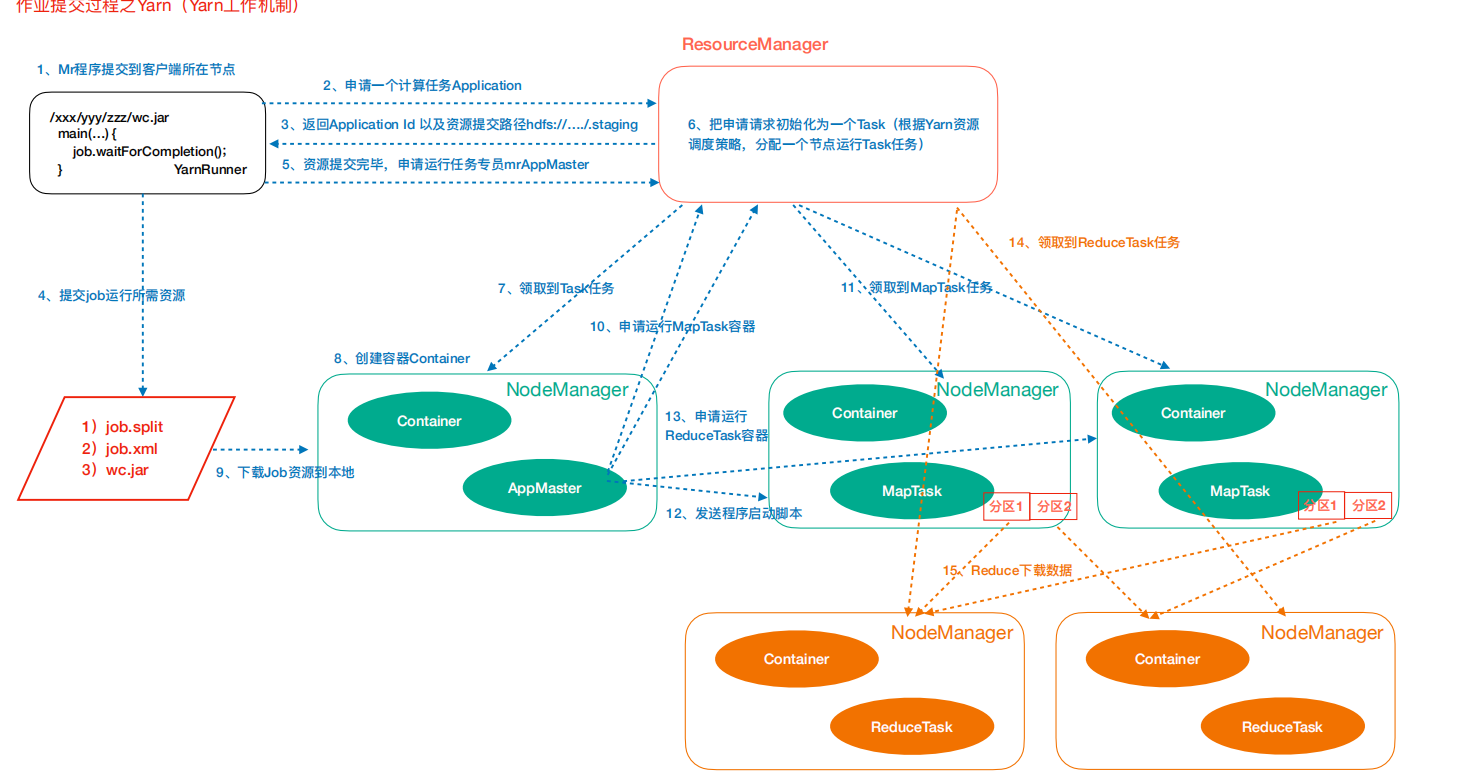
作业提交过程之 YARN作业提交第 1 步: Client 调用 job.waitForCompletion 方法,向整个集群提交 MapReduce 作业。第 2 步: Client 向 RM 申请一个作业 id 。第 3 步: RM 给 Client 返回该 job 资源的提交路径和作业 id 。第 4 步: Client 提交 jar 包、切片信息和配置文件到指定的资源提交路径。第 5 步: Client 提交完资源后,向 RM 申请运行 MrAppMaster 。作业初始化第 6 步:当 RM 收到 Client 的请求后,将该 job 添加到容量调度器中。第 7 步:某一个空闲的 NM 领取到该 Job 。第 8 步:该 NM 创建 Container ,并产生 MRAppmaster 。第 9 步:下载 Client 提交的资源到本地。任务分配第 10 步: MrAppMaster 向 RM 申请运行多个 MapTask 任务资源。第 11 步: RM 将运行 MapTask 任务分配给另外两个 NodeManager ,另两个 NodeManager 分别领取任务并创建容器。任务运行第 12 步: MR 向两个接收到任务的 NodeManager 发送程序启动脚本,这两个 NodeManager分别启动 MapTask , MapTask 对数据分区排序。第 13 步: MrAppMaster 等待所有 MapTask 运行完毕后,向 RM 申请容器,运行 ReduceTask 。第 14 步: ReduceTask 向 MapTask 获取相应分区的数据。第 15 步:程序运行完毕后, MR 会向 RM 申请注销自己。进度和状态更新YARN 中的任务将其进度和状态返回给应用管理器 , 客户端每秒 ( 通过mapreduce.client.progressmonitor.pollinterval 设置 ) 向应用管理器请求进度更新 , 展示给用户。作业完成除了向应用管理器请求作业进度外 , 客户端每 5 秒都会通过调用 waitForCompletion() 来检查作业是否完成。时间间隔可以通过 mapreduce.client.completion.pollinterval 来设置。作业完成之后 , 应用管理器和 Container 会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查。
Yarn调度策略
Hadoop 作业调度器主要有三种: FIFO 、 Capacity Scheduler 和 Fair Scheduler 。 Hadoop2.9.2 默认的资源调度器是Capacity Scheduler 。可以查看 yarn-default.xmlFIFO按照任务到达顺序,先到先服务容量调度器( Capacity Scheduler 默认的调度器)Apache Hadoop 默认使用的调度策略。 Capacity 调度器允许多个组织共享整个集群,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。除此之外,队列内部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源了,在一个队列内部,资源的调度是采用的是先进先出(FIFO) 策略。Fair Scheduler (公平调度器, CDH 版本的 hadoop 默认使用的调度器)Fair 调度器的设计目标是为所有的应用分配公平的资源(对公平的定义可以通过参数来设置)。公平调度在也可以在多个队列间工作。举个例子,假设有两个用户A 和 B ,他们分别拥有一个队列。当A 启动一个 job 而 B 没有任务时, A 会获得全部集群资源;当 B 启动一个 job 后, A 的 job 会继续运行,不过一会儿之后两个任务会各自获得一半的集群资源。如果此时B 再启动第二个 job并且其它j ob 还在运行,则它将会和 B 的第一个 job 共享 B 这个队列的资源,也就是 B 的两个 job 会用于四分之一的集群资源,而A 的 job 仍然用于集群一半的资源,结果就是资源最终在两个用户之间平等的共享YARN调度模式详解
YARN(Yet Another Resource Negotiator)是Hadoop的资源管理系统,支持多种调度器模式来管理集群资源分配。以下是三种主要调度器的详细说明:
1. FIFO调度器(先进先出)
工作特点:
mermaidCopy Code
flowchart LR A[Job1] --> B[Job2] --> C[Job3]
- 执行顺序:按照作业提交顺序执行
- 资源分配:前一个作业完成后才分配资源给下一个作业
- 优点:
- 实现简单,无额外配置
- 缺点:
- 大作业会阻塞小作业("head-of-line"阻塞)
- 资源利用率低
- 适用场景:小型集群或测试环境
2. 容量调度器(Capacity Scheduler)
核心特性:
mermaidCopy Code
graph TD Root[Root Queue 100%] Root --> Prod[Production 70%] Root --> Dev[Development 30%] Prod --> ETL[ETL Jobs 50%] Prod --> Reporting[Reporting 20%] Dev --> Research[Research 15%] Dev --> Test[Testing 15%]
- 队列分层:
- 父队列分配总资源比例
- 子队列继承父队列资源
- 核心机制:
- 容量保证:每个队列有保障的最小资源
- 弹性分配:空闲资源可被其他队列借用
- 多租户支持:ACL控制队列访问权限
- 资源配置(示例):
xmlCopy Code
<property> <name>yarn.scheduler.capacity.root.queues</name> <value>prod,dev</value> </property> <property> <name>yarn.scheduler.capacity.root.prod.capacity</name> <value>70</value> </property>- 优势:
- 资源隔离性好
- 支持多租户
- 防止小作业被大作业饿死
- 适用场景:企业级生产环境(Cloudera/Hortonworks默认调度器)
3. 公平调度器(Fair Scheduler)
工作原理:
mermaidCopy Code
pie title 资源分配比例随时间变化 “Job1(60s)” : 60 “Job2(30s)” : 25 “Job3(新提交)” : 15
- 动态分配机制:
- 新作业启动时立即获得均等资源
- 运行中的作业逐步释放超额资源
- 核心特性:
- 公平共享:所有作业获得相等资源份额
- 最小资源保证:可为队列设置最低资源
- 资源抢占:可回收超额分配的资源
- 权重分配:重要作业可设置更高权重
- 配置示例:
xmlCopy Code
<allocations> <queue name="prod"> <minResources>10000 mb, 10vcores</minResources> <weight>2.0</weight> </queue> <queue name="dev"> <minResources>5000 mb, 5vcores</minResources> </queue> </allocations>- 优势:
- 快速响应短作业
- 自动平衡资源分配
- 适合交互式查询场景
- 适用场景:共享分析集群(如Spark/Flink交互查询)
调度器对比总结
特性 FIFO调度器 容量调度器 公平调度器 资源分配策略 顺序分配 队列容量保证 公平共享 弹性扩展 ❌ 无 ✅ 队列间借用资源 ✅ 自动平衡 资源隔离 ❌ 无 ✅ 强隔离 ✅ 队列级隔离 饥饿问题 ❌ 严重 ✅ 通过容量避免 ✅ 自动解决 配置复杂度 无需配置 ⚪ 中等 复杂 适用场景 测试/小集群 企业生产环境 交互式分析集群 默认启用 Hadoop 1.x Hadoop 3.x 默认 CDH可选 高级调度特性
节点标签调度:
- 将节点分组(如SSD/GPU节点)
- 作业可指定运行在特定标签节点
shellCopy Code
yarn node -addToClusterNodeLabels "GPU"预约调度:
- 提前预约未来时间段资源
- 保证重要作业按时执行
动态资源自动伸缩:
- 基于队列负载自动调整容量
- 需要配置弹性伸缩策略
最佳实践建议
生产环境选择:
- 稳定需求 → 容量调度器
- 交互分析 → 公平调度器
队列设计原则:
- 按部门/项目划分队列
- 为关键作业保留专用队列
- 设置合理的最大资源限制
参数调优:
javaCopy Code
// 防止资源碎片化 yarn.scheduler.minimum-allocation-mb = 1024 // 启用抢占保证SLA yarn.resourcemanager.scheduler.monitor.enable=true注:在Hadoop 3.0+版本中,所有调度器都支持层级队列和资源动态管理功能,可根据实际需求组合使用不同调度器的优势特性。

















 1691
1691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









