



一、数据仓库基本
01数据仓库历史背景梗概
基本是在网络信息时代,企业在订单,仓储,供应方面会积存的数据,某些数据使用频率低,占用空间冗余,导致业务数据库(OLTP)性能下降。对于企业而言,既有对于业务数据库冗余数据的清除提效需求,也有对于业务数据库内冗余数据的能用需求。
对于业务数据库中调用较为少的数据,我们把它称作冷数据。对于数据仓库(OLAP)的需求,不若是对于处理冷数据的需求,即这个需求不以业务数据库自身解决,而是在外成立一个专门的冷数据管理仓库,就是数据仓库了。
用于管理冷数据的数据仓库,可以被各部门灵活调用于数据分析,这是冗余数据到达一定量级,且以冗余数据类型和特征为概念导向(实际上数据类型及特征先由公司分析需求引起),企业需求向数据的概念做利益延展时所需要的。
但请注意在直接的数据仓库之前,企业仍然是以业务数据库作为前提的,但数据分析通常不在业务数据库进行,这是由于首先访问直接的业务数据库需要进行权限管理,其次是在业务数据库中处理的数据不是“冷数据”,会导致各部门因时间差异输出的数据结果的不一致性,进而导致分析不一致性。而数据仓库信息是统一时间调取的业务数据,能够解决不一致性的问题。因此,企业对于两种数据库一般有明确对位,业务数据库直接面向业务系统,而数据仓库则面向数据分析。
02数据仓库本体基本概述
数据仓库的作用在前述讲解中被理解为:冷数据集中管理的需要及根据公司需求构建特定类型特征的数据,在涉及利益延展时的概念导向需要【简化为数据分析的需要】。
因此数据仓库的本体应当具备:
0201有主题(公司分析需求)的集成稳定存储系统
主题性:就是针对性,业务性,公司性,围绕的是公司的分析领域来组织数据,构成分析表与业务表对立,为的是能够开展分析和进行高效分析。
集成性:解决不同源(不同业务表)获取到数据的不统一情况,例如数据表头命名不一致,数据格式不一致,数据主键的编码体系不一致,数据异常(主键一致索引的其余类型数据不一致)等问题。
稳定性(非易失性):也就是数据仓库的只读性,即通常不能被修改或删除而只实行加载或查询功能。
存储性(时段性):如果说业务表只记录时刻数据,那么数据仓库表就记录时段数据,会添加时间轴表头进行相应的时刻记录,汇聚为一段时间特征的数据。
【在实际运作中,除第一种要敲定方案实施前商讨外,后三种均是对应脚本和软硬件实施方案!】
03数据仓库技术方案
0301传统数仓
是技术,架构都相对更加成熟的一种数仓搭建模式,传统模式。
一般使用单机的数据库,即传统的关系型数据库(Mysql),多个单机数据库组成集群,叫MPP(大规模并行处理)。和业务数据库架构一致,数据迁移方便。但拓展性有限,即如果想要升级,只能购买硬件,而且每个节点本质上是单机的数据库,节点间实际的串联运作需要高速网络支撑,高速网络带宽上限就决定了节点的上限。而且还有热点问题,也可以说是牛头问题,整体MPP运行时分表分库,有可能表中某一段使用频率比其他段要高,自然这个库的使用频率也高,就像被持续拽扯的牛头,一旦这个牛头库因为频率过热宕机,整个身子就都走不动了,解决牛头问题也可以使用数据随机分布方法来打乱数据存储从而尽量减少问题的产生。所以一般MPP适用于只有一定中小量级数据的企业业务。
其中,集群中每个节点负责一部分数据的存储和计算任务,即从业务数据库提前调度的数据分配到各个节点时,首先进行存储(使用hash),然后进行计算和查询任务(支持数据分析工作时分析师的select),节点生成这些部分结果最终汇总为一个完整结果返回给分析师。
0302大数据数仓
一个对具有海量数据拓展需求企业提供的方案。
主要解决关系型节点MPP架构所存在的数据扩展问题,数据首先以分布式文件而非表结构存储在系统中(解决了扩展性问题),分布式sql引擎分发任务给大数据计算引擎,大数据计算引擎将计算任务分发给特定的数据文件,分发的过程中,由于在数据存储时一般会对文件做备份,因此引擎实际上可选一个相对限制的节点进行处理(解决了热点问题),直接处理计算,然后再汇总。
由大数据计算引擎分发任务的过程中,原先是有业务迁移难题的,比如MPP使用的sql语法实际上和大数据计算引擎不相兼容。后来出现的语言兼容工具解决了这一痛点(hive,spark,flink),以及元数据来标记数据的表结构以使得文件格式能转化为表格式。因而大数据仓库架构实际的运作逻辑是:计算引擎分发任务→分布式文件由元数据还原表结构→适配语言兼容工具→输出计算结果。
结果就是解决了以上的问题,而缺点是兼容问题和对于小数据的处理速度相对较慢的问题。
0303MPP架构-传统数仓
架构本体有单机数据库节点,字面意思,节点组成集群实现数据的并行处理。节点间非共享架构(share nothing),即单节点其磁盘存储和内存独立。节点连接使用专用或商业通用网络,彼此协同运算,仅作为整体提供服务(离开整体的单个节点什么也不是)。
在设计上按优先级依次做好数据一致性(不同用户所得信息必须随时同步),系统可用性(即使用户数据滞后,系统模块仍然正常运转)和分区容错性(即使部分节点失联系统总体仍然持续工作)。(CAP)
现实中,一般只考虑CA,因为一般情况下会认为使用高速网络P问题,可以通过硬件和网络设计来避免。
MPP出现热点问题的原理:由于hash存储特征,查询数据时会遍历,因此缓慢的节点必然成为整个系统的瓶颈(通过高速网络分发至其余节点可以解决,但是高度网络带宽也有极限)。扩展节点数量也不能解决这个问题,你数据量如此,只会使得故障率越来越高。
0304分布式架构-大数据数仓
也称为Hadoop架构/批处理架构。
相对于MPP,数据在集群中全局透明共享,因而可实现场地自治。节点间用局域网/广域网相连,相较于高速网络开销较大,因此各个节点是特定分发向节点的计算任务。而因为节点使用的是局域网,在CAP设计时就会优先考虑P再考虑A然后才是C。
所以架构一般在AP和CP间进行取舍,即在P故障时,整体继续运行的前提下,要么为保障一致性停机,要么为保障可用性给出“滞后”的数据,这需要按照实际需求取舍,一般是优先选择可用。
0305MPP+分布式混合架构
鉴于上面二者存在的基本问题,一般企业会用这种混合架构,即数据存储用分布式架构方式,上层架构运算用MPP。
0306常见数仓产品-在架构中实现
传统数仓:OracleRAC,DB2,Teradata,Greenplum
Oracle本身属于共享型架构,是一个较为“常用”的,优点是使用方便,学习方便。
DB2仅少使用,一般会由IBM产品附赠给企业使用。
Teradata在易用性和性能上有出色表现,可用性与高并发性也突出,也自带数据引擎,查询工具,但一般价格较贵,并与一体机捆绑销售。
Greenplum是开源的,搭建成本整体较低,学习资料较多,技术更新较快,但性能比Teradata差一些,但性价比仍然非常高。
大数据数仓:Hive,SparkSQL,HBase,Impala,HAWQ,TIDB
Hive,支持将sql转成mapreduce或者spark,吞吐量大,延迟较高。
SparkSQL,相较于Hive还需要再加一个集群去安装和运维,SparkSQL只需要这个集群就够了。所以现行方式也是推荐Hive on Spark。
HBase,作为no SQL数据库,适合存储半结构化数据,所以其应用场景是实时流处理的数据存储以及前端业务系统高并发的业务查询,以及DDL频繁变动的业务。
Impala,MPP架构的数据查询引擎,这是作用于交互式查询的,和HBase一般用于批处理(后台),即作为数据仓库的补充产品,即查询接口使用,主要优势是响应快。
HAWQ,分布式批处理架构+MPP,本质是Greenplum的衍生,sql支持率较高的同时性能也较出色。
TIDB,是newSQL数据库,架构是MPP+SMP,它是支持并行OLTP和OLAP的,更适合于前者,在数仓选型中不占优势。
二、数据仓库架构
01架构图
根据数据流动方向进行的分类和分序:
0101ETL【Extract,Transform,Load】
数据同步模块。即将数据从数据源(业务数据库)进行抽取,然后交互转换,例如清洗,标准化,进而加载存储到ODS的过程,通过这个模块实现。
一般采用现成工具进行,例如sqoop,kettle,datax,flume,logstash或其他工具,主要看公司采集数据的需求,按情况使用现成工具或定制。
0102操作数据源层(ODS)
被ETL的数据抽取到这里,与ETL原始数据保持一致,目的就是为了存储ETL数据,同时确保数据的非易失性。
0103公共维度模型层(CDM)
细分为数据明细层(DWD),数据汇总层(DWS),一整个合成CDM是为了数据分析服务的。DWD负责接收ODS原始ETL数据,ETL原始数据可能来自于不同系统,DWD负责解决其格式统一问题,DWS负责解决因不同业务而导致表临散的集成问题,统合确保集成性。
0104数据应用层(ADS)
通过CDM表,由数据分析师分析后得到的结果上传至该层,用于报表决策,并发查询及搜索检索。由于ADS被用于向决策层展现分析后的数据,其存储逻辑可能与CDM不尽类似,因而有可能会对ADS和CDM划分不同的数据库。
02ETL流程
ETL基本概念即:Extract,Transform,Load的三个过程,这就是源数据向数仓搭建的可行通道,是数据仓库构建的极其重要的一环,基本占数仓仓库构建流程的60%-80%。
0201Extract
抽取的数据源,按结构形式和采集方法的不同,一般可以分为结构化数据(JDBC/数据库日志),非结构化数据和半结构化数据(监听文件变动)。
抽取的方式也根据实际的用途有区别,主要有两种,全量同步(抽取全部数据,一般用于数据仓库搭建后对数据装载的初始化)和增量同步(仅抽取发生变动的数据,一般用于数据更新)
方法论
结构化-如果选取直连数据库(JDBC),一般选取凌晨业务量较少时间以减少业务数据库的负载,而且一般抽取受业务数据库IO限制,时间会比较慢。
结构化-如果选取数据库日志(WAL-预写日志文件),对数据库的前端IO影响小,只是需要对于采集的日志进行基于工具的解析,比如使用(Oracle-OGG,CDC)等等。
非结构,半结构化-数据基本以文件形式存在(日志,json等),进行监听处理文件变动即可,比以上相对操作简单。
0202Transform
主要是数据清洗和数据转换。
清洗主要注意:重复性(数据重复),二义性(同主键标定的同表头数据不对齐),不完整(表头数据置空),违反业务或逻辑规则等问题的数据。
转换主要注意:标准化处理(去单位化),进行字段,数据类型,数据定义的转换。
0203Load
将数据存储到ODS层。
0204常见ETL工具
对于结构化:sqoop,kettle,datastage,informatica,kafka
sqoop在大数据中常见,将结构化数据库通过JDBC连接后抽取数据并使用并发处理导入数据库。若用直接用1.x版本,性能相比2.x要高。
kettle提供可视化界面,开源免费。
datastage/informatica商业工具。
kafka是消息队列,也提供ETL功能,即将数据抽取后存在队列中,等待数据仓库的抽取。
对于非/半结构化:flume,logstash
这俩没什么可说的。
03数据积存(ODS)
与ETL数据需保持一致,并仅提供只读功能(可添加字段用于数据管理),因而实际上是减免业务数据库IO的外数据库并是其数据的扩充集。在ODS中不允许修改,但允许追加,因此会有两种类型的数据,一种是全量和增量时导入的新数据(instert),一种是增量时业务数据对某个数据进行修改后的再次添加(update)。
企业用的比较多的方法是外连接+全覆盖,即把业务的增量数据与ODS数据进行外连接,就可以直接判断哪些是新增的,哪些是修改的数据,判断后直接在内存中将数据修改掉,而后直接将ODS数据覆盖。
04数据分析(CDM)
0401数据明细层(DWD)
对ODS的清洗,标准化以及维度退化,把表做少。
0402数据汇总层(DWS)
将所有的表汇总成一张宽表。
05数据分析(ADS)
也称为数据集市,是一个数仓外的单独数据层。
因为数仓不适合交互式查询,因而在这一层需要单独出来一个外部工具去满足其交互查询的效率。如从DWS下来的数据存到kylin(报表决策),存到hbase(并发查询),存到blastic search(搜索检索),为这些工具提供接口,将数据存储到这些工具中,而不是由数据仓库直接开放查询接口。
三、数据建模方法
01基本概念
OLTP(在线事务处理)系统主要负责随机读写,业务数据库基本框架。需求:数据一致性,少冗余,一般使用3NF来减少冗余。
OLAP(在线联机分析)系统主要负责复杂分析查询,关注数据整合,分析处理性能。根据数据存储方式不同划分为:ROLAP,MOLAP,HOLAP。其中:
ROLAP(关系型OLAP);关系模型构建,存储系统是RDBMS(关系型数据库管理系统)
MOLAP(多维型OLAP);预先聚合运算(groupby),用多维数组形式保存数据结果,加快查询分析时间
HOLAP(混合架构OLAP);R&M的集成,例如低层关系型,高层多维型,查询效率要高于ROLAP,低于MOLAP。
02ROLAP
典型的有:ER模型、维度模型、Data Value、Anchor
ER模型(属性关系模型):出发点是数据仓库,但需要全面了解业务和数据,实施周期长。
维度模型:表被分为维度表和事实表,其分层规则是实体的自构造和实体的链构造,自构造是实体自有的一些构造,如价格,用材,具体参数等等,链构造则是市场对于实体的抽象分类,例如所生产地域,所生产时间,所生产类型,标准化参数(如型号,尺寸,基础功能等)。
Data Value:ER模型的衍生,为解决动态数据变化带来的表结构冗余,难变动的问题,强调数据的历史性,可追溯,原子化。
Anchor:Data Value的衍生,搭建固定化子件来解决无限的拓展性问题。
0201维度模型
一般用的最多的就是这个模型,它也分为三种,一种是星型,一种是雪花型,一种是星座型
星型:一个事实表,维度表依托事实表进行拓展。
雪花型:一个事实表,维度表还能继续细分维度表的拓展。
星座型:多个事实表,事实表间共享拓展的维度表。
宽表模型:为避免上述表由于分表要join使得大数据性能的不佳所设置的一种模式,即在DWD层实施事实表和维度表的拓展,然后在DWS层又将其汇总为一整个宽表。
03MOLAP
将数据进行预计算,将聚合结果存储到CUBE模型中,CUBE是多维数组的形式。由于只存储预计算结果,因此存储空间占用大,使用灵活度低。
常见MOLAP产品:Kylin(常用),Druid(面向时空数据库)。
以Kylin举例,这种“聚合”是产品在做,即我们从hadoop,hive,kafka,RDBMS等拿取数据后,导入Kylin,然后进行聚合(消耗大量时间),最后导入Hbase进行存储。
这个操作在之前有讲过,它适用的场景是ADS。
04多维分析
OLAP(数据仓库)主要操作是复杂查询,即可以多表关联,使用聚合函数等;我们对这些复杂查询做了一些较为直观的定义:
a.钻取,包括上卷(roll-up)和下钻(drill-down),实质是细化或粗放化某一维度【年月日】,冻结其他维度。上卷是粗放,下钻是细化。
b.切片(slice),冻结其他维度,选择的这个维度在不粗放和细化的前提下,提取出其中某一个单元。
c.切块(dice),多个维度去提取某一个单元。
d.旋转(pivot),维度行列的切换。
四、数仓建模实践
01维度建模
0101表类型
事实表:一般指现实存在的业务对象,比如商家、用户、商品、供应商....
维度表:一般是状态编码的解释表,如未支付=1,已支付=0。
事实表的细分---
A.事务事实表:只添加不删改的记录数据,比如日常流水,记录日志等。
B.周期快照事实表:所记录数据有周期性(例如年累计,月累计等),不是对原数据进行修改,而是在数据末尾添加上去。
C.累积快照事实表:一般是生命周期表,用时间记录一个订单生命周期的关键阶段(比如下单时刻,支付时刻,确认收货时刻),也可以认为是有删改需求(当且仅当前一项数据对于后一项数据没有任何意义时)的事务事实表或周期快照事实表。它需要实现“删改需求”。
对于累积快照事实表删改需求的实现---
实现方式A.创建一个基于日期(最后更新日期,快照日期)的字段用于管理和作为分区依据,即制作日期分区表,每个分区存储的是昨天的全量数据(仓库里的数据)与当天的增量数据(业务数据库数据)合并的结果。“最后更新日期”是数据分析业务端实用数据,然后快照日期帮助数据仓库快速定位这类所需数据。这样的好处是简单,但会产生过多的冷数据(每天都要全量一次)。
实现方式B.仍然是使用日期分区表,但是基于一个较为全面对于产品生命周期的经验总结,推测一个数据最长的生命周期,仅存储周期内(今日时间前n天)的数据,其余冷数据存储到归档表(满足政策规定)。
实现方案C.使用日期(业务实体的结束时刻)分区,每日快照分区仅存放当天结束的业务数据,并设置一个时间非常大不可能达到的分区,存放当前未结束的数据。后续更新仅对这一个最大的分区进行检索。
| 订单ID | 下单日期 | 支付日期 | 发货日期 | 收货日期 | 实体结束日期 | 当前状态 | |-------|----------|----------|----------|----------|--------------|----------| | 1001 | 2024-01-01 | 2024-01-02 | 2024-01-03 | 2024-01-05 | 2024-01-05 | 已收货 | | 1002 | 2024-01-01 | NULL | NULL | NULL | 9999-12-31 | 已下单 | | 1003 | 2024-01-01 | 2024-01-02 | NULL | NULL | 9999-12-31 | 已支付 |
每日向业务数据查询更新9999的订单,若ID有实体结束日期(收货日期)则覆盖“实体结束日期”。
拉链表---
-----------------------------------
| 订单ID | 状态 | 开始日期 | 结束日期
|-------|--------|----------|----------|----------|
| 1001 | 已下单 | 2024-01-01 | 2024-01-01
| 1001 | 已支付 | 2024-01-02 | 2024-01-02
| 1001 | 已发货 | 2024-01-03 | 2024-01-04
| 1001 | 已收货 | 2024-01-05 | 9999-12-31
| 1002 | 已下单 | 2024-01-01 | 9999-12-31
开始日期就是这个状态的实际开始日期,结束日期就是这个状态更新时的日期,为9999就是这个状态还未更新。在每天新记录时,按订单id查询得到的业务数据中的状态如若变更,则做以下操作:
添加一个订单ID相同的数据,其状态为更新状态,开始日期为当前日期,结束日期为9999。
修改同一ID数据的结束日期9999为当前日期。
02ETL策略
之前讲ETL的时候,讲到了方法论和同步方式,在这里做具体的说明,需要了解“方式”名词的内涵:
JDBC方式--即在ETL过程中对于结构化数据进行同步(不论全量还是增量)的相对简单的方式。
全量同步方式--很简单,固定时间将业务数据与现行数据库数据同步覆盖即可,如果认为会有误差,可以全量几个周期的数据,然后隔天进行删改。
增量同步方式--一般是按照数据日志的时间结果,取某一段时间之后的数据就是增量数据了。要么insert要么update,采取这种merge方法。如果不支持update操作,也可以使用全外连接+全量覆盖方式解决。
监控方式--一般是处理半结构或非结构化数据,但由于这个一般有自带,所有不加说明。
03任务调度
解决任务单元间的依赖关系,以及提供自动化流程。
0301任务类型
常见任务类型:Shell、Java程序、Mapreduce程序、SQL脚本
Shell一般用于启动数据仓库的组件。
Java和Mapreduce一般用于数据清洗或其余自定义的功能,其中Mapreduce吞吐量更高。
SQL脚本用于处理DDL或数据处理任务。
0302调度工具
Azkaban、Oozie,其中Az易用性更强。在实战部分使用的调度工具就是Azkaban。
EX:数仓建模工作流
ai总结以上得出的相关工作流:
核心目标:构建一个自动化的数据管道,将分散、原始的业务数据,通过一系列标准化加工,转化为易于查询分析的数据资产,最终支撑报表、BI分析与数据决策。
第一步:技术选型
根据数据量和技术栈选择底层架构和软件。
中小数据量: 选用MPP架构产品,如 Greenplum。
海量数据: 选用大数据架构,核心组件是 Hive 或 SparkSQL。
混合架构:考虑 MPP + 分布式 混合架构(如 Spark作为计算引擎,Greenplum/ClickHouse 作为查询引擎),兼顾处理能力与查询性能。
第二步:数据同步 (ETL)
即 ETL,负责从业务数据库(如MySQL, Oracle)等数据源抽取数据,进行转换清洗,并加载至数仓ODS层。
结构化数据:常用 Sqoop (大数据生态)、Kettle (开源可视化)、DataX (阿里开源)。
日志/文件数据:使用 Flume、Logstash。
首先全量同步用于系统初始化或小表,后续增量同步,用于大表,通过数据库日志(如CDC) 或时间戳识别变化数据,对业务系统影响最小。执行窗口通常在业务低峰期(如凌晨)执行,以减少对业务数据库的压力。
第三步:数据存储 (ODS层)
同步过来的数据会原样存入ODS层。
第四步:数据加工 (CDM层)
数据明细层 (DWD): 对ODS数据清洗、标准化,得到干净、规范的明细数据。
数据汇总层 (DWS): 基于分析主题(如销售、用户),将DWD的明细数据聚合汇总成宽表(如销售宽表)。
第五步:数据服务 (ADS层)
将加工好的数据推送到适合查询的工具中,供最终用户使用。
固定报表与OLAP分析 → 推送到 Kylin 或 Druid。
高并发、低延迟点查询 → 推送到 HBase 或 ClickHouse。
全文检索与日志分析 → 推送到 Elasticsearch。
BI工具直连 → 对DWS/ADS层的宽表进行直接查询。
第六步:任务调度
使用调度工具将以上步骤自动化。
工具: 使用 Azkaban 或 DolphinScheduler。
工作方式: 设定定时任务(如每日01:00开始),调度工具会自动依次触发:数据同步 → OSD层更新 → DWD层加工 → DWS层汇总 → ADS层数据推送。整个过程无需人工干预。
数据治理:在关键环节(如ETL后、DWD层生成后)设置数据质量监控点,校验数据完整性、准确性。进行元数据管理记录表结构、数据血缘、加工逻辑,保障数据可追溯、易理解。
五、数仓建模实战
项目一期-数仓底层建设
01数据选取
优先了解搭建仓库的数据需求,即需要完成的分析需求。并在现有的业务数据中一一找到所需对应的数据,注意数据表间的关联关系。
02数仓底层架构
为了方便流程说明,暂时选型如下(一般性根据公司需求调整):
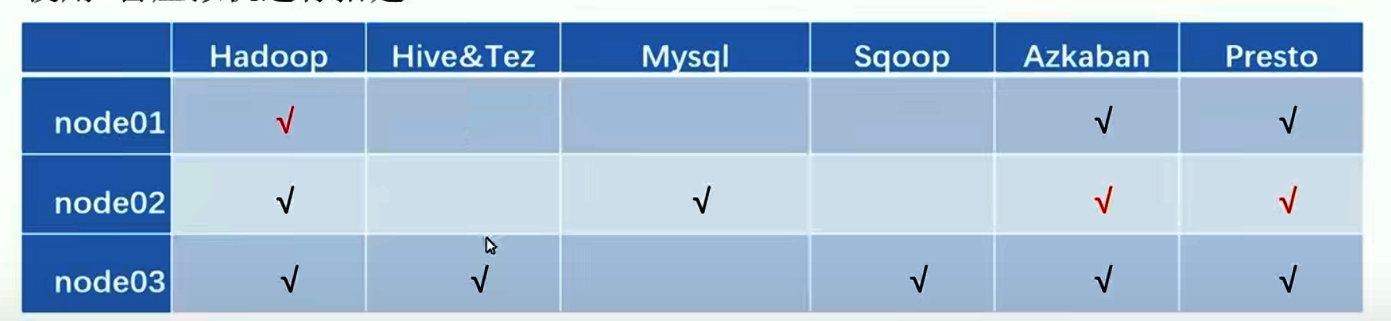
底层业务数据库为Mysql、ETL选择用sqoop、存储为HDFS(Hadoop)、(ODS→ADS)整链用Hive集成(用Tez做执行,Mapreduce为底层)。
用Presto作快速查询接口辅助数据分析业务系统功能。用Azkaban作任务调度的工具。

0301虚拟机搭建及网络环境配置
下载centOS,然后用虚拟机程序(如virtualbox)驱动。
vim /etc/sysconfig/network-scripts/ifcfg-enp0s3 --修改虚拟机网址为本地(前缀不改,最后一位随机,不与本地相同即可)
systemctl restart network--进行网络重启
成功装载三个虚拟机,即:node01/02/03
0302Xshell配置、自动化脚本配置大数据数仓环境
使用Xshell连接node01/02/03。
使用Xshell,在node中使用自动化脚本搭建基础大数据环境。
①安装自动脚本zip
wget https://github.com/MTlpc/automaticDeploy/archive/master.zip
该zip仅能在/home/hadoop/目录下运行,因此需要:
mkdir /home/hadoop/ --用于创建目录
uzip master.zip -d /home/hadoop/ --用于讲zip解压至对应目录
【注意解压后在hadoop里有一个automaticDeploy-master文件,要mv去掉“-master”】
②集群节点脚本安装配置
了解一下--
在automaticDeploy里共有
configs.txt config.txt frames.txt frame.txt hadoop host_ip.txt logs.sh README.md systems
其中:
frames.txt定义了对应环境需要安装的对应东西的名称和安装位置(如有更改就要改)
configs.txt定义了mysql和azkaban的相关配置
host_ip.txt定义了对应的node--ip配置(需要根据自己的ip进行更改)
hadoop存放了大数据组件的一键安装脚本sh
system存放了环境一键配置的脚本sh
实际操作--
首先在automaticDeploy:
chmod +x /home/hadoop/automaticDeploy/hadoop/* /home/hadoop/automaticDeploy/systems/*
--添加hadoop和systems里的sh脚本可执行的权限(赋权后颜色会变成绿色)
然后使用rz上传在frames.txt中对应的安装包:
yum install lrzsz -y --xshell自带的上传下载安装包插件
【如果网络不好:
# 进入yum源目录 cd /etc/yum.repos.d/ # 备份所有原有源 mkdir backup mv *.repo backup/ # 下载阿里云yum源(使用wget或curl) wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
# 清理yum缓存 yum clean all # 重建缓存 yum makecache # 安装lrzsz yum install lrzsz -y】
安装后使用:
cd ~
rz (乱码加-bye解决)
上传对应的软件安装包(可以整合为一个zip)
然后就是对其在automaticDeploy的解压。
然后是自动脚本针对各节点的分发:
使用远程命令连接创建hadoop目录:
ssh root@192.168.10.X “mkdir /home/hadoop/”
拷贝文件:scp -r /home/hadoop...Deploy root@192.168.10.X:/home/hadoop/
③集群节点环境初始化与hadoop安装
在system中,使用脚本:
./batchOperate.sh
其余节点依次执行此操作
检查ssh连接是否通畅:
ssh nodeX
若有问题,输入:
ssh-copy-id nodeX
再查看问题是否复现,然后在其余节点重复此检查
这样就完成了system环境脚本搭建和节点间网络畅通的检查
开始安装hadoop集群:
节点依次执行:
./installHadoop.sh
source /etc/profile--全局配置
在node01初始化hadoop:hadoop namenode format
然后执行:start-all.sh
用jps在各节点检查是否加载到位。完成hadoop安装!
进入浏览器访问node01节点:(检查)
192.168....:50070
Dead Nodes、Under-Replicated Blocks、Blocks Pending Deletion是否为0。
Datanode界面是否有三个node
【case若没有:
stop-all.sh(在node01)
# 停止可能残留的进程(在3节点) pkill -f hadoop pkill -f java # 彻底清理所有相关目录(在3节点) rm -rf /opt/app/hadoop-2.7.7/data/* rm -rf /opt/app/hadoop-2.7.7/name/* rm -rf /opt/app/hadoop-2.7.7/tmp/* rm -rf /tmp/hadoop-* 格式化 NameNode(在node01) hadoop namenode -format 启动 HDFS(在node01) start-all.sh】
【hadoop开机运行方法(root)(无需重复开启):
# 创建服务文件并编辑(可能有问题,可以让ai对着问题报错改! vi /etc/systemd/system/hadoop.service
[Unit] Description=Hadoop Service After=network.target remote-fs.target [Service] Type=forking User=root ExecStart=/opt/app/hadoop-2.7.7/sbin/start-all.sh ExecStop=/opt/app/hadoop-2.7.7/sbin/stop-all.sh Restart=on-failure RestartSec=10 TimeoutSec=30 [Install] WantedBy=multi-user.target
# 重新加载systemd配置(看是否报错) systemctl daemon-reload # 启用开机自启动(看是否报错) systemctl enable hadoop.service # 启动服务(看是否报错) systemctl start hadoop.service # 检查服务状态(看是否报错) systemctl status hadoop.service】
④Hive&Tez安装及Mysql前置安装
在node02节点:./installMysql.sh
然后登陆:mysql -uroot -p(密码是在configs.txt中定义的)
此时可以用show atabases;看到还自动安装了azkaban和hive,是因为在flames里这俩是true。(如果不用就是false)
在node03节点:./installHive.sh(由于flames.txt的定义,它会在安装Hive后同时安装Tez)
⑤Sqoop
在node03节点:./installSqoop.sh
source /etc/profile
⑥Presto&Azkaban及Presto可视化插件
在frames中定义过主从节点,直接依次:
./installPresto.sh即可
同样的安装./installAzkaban.sh
在节点中安装./installYanagishima.sh
最后source /etc/profile
至此所有环境搭建完成!
之后依据工作变动即改动:flames.txt和configs.txt以及flame文件包即可!
项目二期-项目开发全流程
01数据生成(实践忽略这一项)
在node02使用Mysql脚本进行数据生成。
export MYSQL_PWD=DBa2020* # 设置MySQL密码环境变量
mysql -uroot # 使用root用户连接MySQL
-e "create database mall" # 执行创建数据库的SQL命令
后续需要使用rz,所以先对node02添加lrzsz,具体yum步骤参考0301,安装好后:
cd ~
回到子目录
rz
选中四个脚本放在子目录:建表、分类商品数据插入、函数、存储过程,并依次操作:
mysql -uroot mall < /root/1...sql
mysql -uroot mall < /root/2...sql
...
将四个脚本依次导入到mall数据库后
可以直接输入:mysql
进入mysql(先前密码环境变量设置的作用)
use mall;
进入database-mall
CALL init_data('2025-10-19',300,200,300,FALSE);
这里的init_data是脚本中生成数据的函数,这里已经生成了基于脚本和时间的随机数据。
MALL表:
mysql> SHOW TABLES;
+----------------+
| Tables_in_mall |
+----------------+
| base_category1 |
| base_category2 |
| base_category3 |
| order_detail |
| order_info |
| payment_info |
| sku_info |
| user_info |
+----------------+
02ETL数据导入
在node03使用sqoop完成数据的ETL流程,并导入HDFS。
先在node03中创建用于存放数据的文件夹和用于存放脚本的文件夹:
mkdir -p /home/warehouse/shell
其中warehouse用于存放数据,shell用于存放脚本。
cd进shell,编写脚本(linux_shell语法):
vim sqoop_import.sh
编写通用方法:
#!/bin/bash --通用起手
#传入两个参数,$1为表名,决定抽取哪张表;$2为时间,决定抽取特定日期数据!
db_date=$2 --用这个函数时第二个参数写时间
echo $db_date
db_name=mall --写死参数
import_data(){
sqoop import \
--connect jdbc:mysql://node02:3306/$db_name \
--username root \
--password DBa2020* \
--fields-terminated-by "\t" \
--target-dir /origin_data/$db_name/db/$1/$db_date \
--delete-target-dir \
--num-mappers 1 \
--query "$2"' and $CONDITIONS;'
}
【使sqoop导入数据,并指定mall为连接的数据库→
表结构转文件步骤:指定分隔符→指定文件存放目录【原数据/数据库名/数据库(db)/表名(第一个参数)/表抽取日期】→某目录已存在就delete)
→并发执行数量
→在有涉及其余脚本时,定义$2作为其select查询规则,介入sqoop的导入行为】
【通用方法已封装,接下来对特定表写“使用”脚本】
【这里会全量或增量地处理各表,在业务中,一般存储参数的表是全量,订单和流水表是增量】
首先进行参数表的全量抽取:(可以看到没有用$2作日期限定,仅即做查询在该表全量的限定)
import_sku_info(){
import_data "sku_info" "select
id, spu_id, price, sku_name, sku_desc, weight, tm_id,
category3_id, create_time
from sku_info where 1=1"
}
import_user_info(){
import_data "user_info" "select
id, name, birthday, gender, email, user_level,
create_time
from user_info where 1=1"
}
import_base_category1(){
import_data "base_category1" "select
id, name from base_category1 where 1=1"
}
...category2和3
其次进行订单详情表的增量抽取(抽取时间以订单表为准,抽取时间定义为$2即$db_date):
import_order_detail(){
import_data "order_detail" "select
od.id,
order_id,
sku_id,
sku_name,
order_price,
sku_num,
o.create_time
from order_info o, order_detail od
where o.id=o.order_id
and DATE_FORMAT(create_time,'%Y-%m-%d')='$db_date'"
}
然后是订单表的增量抽取(较详情表少了以谁为准的条件,并列条件or关系用括号确保):
import_order(){
import_data "order_info" "select
id,
total_amount,
order_status,
user_id,
payment_way,
out_trade_no,
create_time
from order_info
where (DATE_FORMAT(create_time,'%Y-%m-%d')='$db_date' or DATE_FORMAT(create_time,'%Y-%m-%d')='$db_date')"
}
以及payment表的增量处理...
最后定义$1的各情形对于函数的调用:
case $1 in
"sku_info")
import_sku_info
;;
"user_info")
import_user_info
;;
"base_category1")
import_base_category1
;;
"base_category2")
import_base_category2
;;
"base_category3")
import_base_category3
;;
"order_detail")
import_order_detail
;;
"order_info")
import_order
;;
"payment_info")
import_payment_info
;;
"all")
import_sku_info
import_user_info
import_base_category1
import_base_category2
import_base_category3
import_order_detail
import_order
import_payment_info
;;
esac
【脚本书写完成!】为脚本附权限:
chmod +x sqoop_import.sh
可以开始操作了:
./sqoop_import.sh all 2025-10-19
无报错,数据全导给信息,去50070端口网址看无问题(success)就说明ETL流程全部完成!
03ODS层创建对HDFS的数据接入
在Hive中创建ODS层,接入HDFS数据。
建表
现在node03处启动hive元数据服务:
hive --service hiveserver2 &
hive --service metastore &
进入warehouse(之前创建shell脚本的所在处):
mkdir sql(因为建表使用sql完成,故而创建文件夹sql)
开始编写建表语句:
vim ods_ddl.sql
--创建数据库
create database if not exists mall;
use mall;
-- 创建订单表
drop table if exists ods_order_info;
create table ods_order_info (
`id` string COMMENT '订单编号',
`total_amount` decimal(10,2) COMMENT '订单金额',
`order_status` string COMMENT '订单状态',
`user_id` string COMMENT '用户id',
`pament_way` string COMMENT '支付方式',
`out_tradde_no` string COMMENT '支付流水号',
`create_time` string COMMENT '创建时间',
`operate_time` string COMMENT '操作时间',
) COMMENT '订单表'
PARTITIONED BY (`dt` string)
row format delimited fields terminated by '\t'
location '/warehouse/mall/ods/ods_order_info/'
tblproperties("parquet.compression"="snappy")
;
表抽取内容与ETL的mall中表结构(var-string,delimal等)一致,接续生成其他表:订单详情、商品、用户...
然后将sql导入至hive:
hive -f /home/warehouse/sql/ods.ddl.sql
然后:
hive
show databases;
use mall;
show tables;
来看是否在hive中存放mall,mall中是否正确有表,建表工作就完成了。
导入数据
确认表导入后,进入shell(脚本)目录,创建导入脚本
vim ods_db.sh
#!/bin/bash
#传入一个参数 $1为时间
do_date=$1
APP=mall
hive=hive
sql="
load data inpath '/origin_data/$APP/db/order_info/$do_date' OVERWRITE into table $APP" ".ods_order_info partition(dt='$ddo_date');
load data inpath '/origin_data/$APP/db/order_detail/$do_date' OVERWRITE into table $APP" ".ods_order_detail partition(dt='$ddo_date');
load data inpath '/origin_data/$APP/db/sku_info/$do_date' OVERWRITE into table $APP" ".ods_sku_info partition(dt='$ddo_date');
load data inpath '/origin_data/$APP/db/user_info/$do_date' OVERWRITE into table $APP" ".ods_user_info partition(dt='$ddo_date');
load data inpath '/origin_data/$APP/db/payment_info/$do_date' OVERWRITE into table $APP" ".ods_payment_info partition(dt='$ddo_date');
load data inpath '/origin_data/$APP/db/base_category1/$do_date' OVERWRITE into table $APP" ".ods_base_category1 partition(dt='$ddo_date');
load data inpath '/origin_data/$APP/db/base_category2/$do_date' OVERWRITE into table $APP" ".ods_base_category2 partition(dt='$ddo_date');
load data inpath '/origin_data/$APP/db/base_category3/$do_date' OVERWRITE into table $APP" ".ods_base_category3 partition(dt='$ddo_date');
"
$hive -e "$sql"
然后赋权:
chmod +x ods_db.sh
然后操作:
./ods_db.sh 2025-10-19
在hive中进行一个count(1)的查看。
数据即导入完成。
04DWD创建及导入ODS数据
在Hive中创建DWD层,接入ODS数据,进行清洗及维度退化等工作。
DWD层建表
在node03,sql文件夹中创建dwd_ddl.sql脚本:
use mall;
复用在hive中创建ods层的结构,将订单表、订单详情表、用户表、支付流水表等直接复用。
对于商品表,由于原生有商品表的下级表,此时将其合并在一起:
-- 创建商品表(增加分类)
drop table if exists dwd_sku_info;
create external table dwd_sku_info(
`id` string COMMENT 'skuid',
`spu_id` string COMMENT 'spuid',
`price` decimal(10,2) COMMENT '' ,
`sku_name` string COMMENT '',
`sku_desc` string COMMENT '',
`weight` string COMMENT '',
`tm_id` string COMMENT 'id',
`category3_id` string COMMENT '1id',
`category2_id` string COMMENT '2id',
`category1_id` string COMMENT '3id',
`category3_name` string COMMENT '3',
`category2_name` string COMMENT '2',
`category1_name` string COMMENT '1',
`create_time` string COMMENT ''
) COMMENT ''
PARTITIONED BY ( `dt` string)
stored as parquet
location '/warehouse/mall/dwd/dwd_sku_info/'
tblproperties ("parquet.compression"="snappy")
注意此时COMMENT都是置空的!
然后将sql导入至hive:
hive -f /home/warehouse/sql/dwd.ddl.sql
ODS→DWD导数据+简单清洗(去空值)+维度退化
在shell中编写脚本:dwd_db.sh用于将ODS数据导入DWD,仍然是用hive编写sql进行计算:
#!/bin/bash
APP=mall
hive=hive
if [ -n $1] ;then
log_date=$1
else
log_date=`date -d "-1 day" +%F`
fi
起手式→先定义数据库名和hive名(直接用hive是因为环境变量已装载)→
if操作是指:如果有确切传入日期就使用传入日期,如果没有指定,就使用当前运行时的日期的前一天。
sql="
set hive.exec.dynamic.partition.mode=nonstrict;
非严格模式
insert overwrite table "$APP".dwd_order_info partition(dt)
select * from "$APP".ods_order_info
where dt='$log_date' and id is not null;
insert overwrite table "$APP".dwd_order_detail partition(dt)
select * from "$APP".ods_order_detail
where dt='$log_date' and id is not null;
insert overwrite table "$APP".dwd_user_info partition(dt)
select * from "$APP".ods_user_info
where dt='$log_date' and id is not null;
insert overwrite table "$APP".dwd_payment_info partition(dt)
select * from "$APP".ods_payment_info
where dt='$log_date' and id is not null;
前四张未聚合的表,为方便起见直接划select“*”,实际运用不能这样做,要求插入的数据满足所指的log_date即$1,而且id不能为空,也就是在ods中的空数据会在这一步被清洗掉。
insert overwrite table "$APP".dwd_sku_info partition(dt)
select
sku.id,
sku.spu_id,
sku.price,
sku.sku_name,
sku.sku_desc,
sku.weight,
sku.tm_id,
sku.category3_id,
c2.id category2_id,
c1.id category1_id,
c3.name category3_name,
c2.name category2_name,
c1.name category1_name,
sku.create_time,
sku.dt
from
"$APP".ods_sku_info sku
join "$APP".ods_base_category3 c3 on sku.category3_id=c3.id
join "$APP".ods_base_category2 c2 on c3.category2_id=c2.id
join "$APP".ods_base_category1 c1 on c2.category1_id=c1.id
where sku.dt='$log_date' and c3.dt='$log_date' and c2.dt='$log_date' and c1.dt='$log_date'
and sku.id is not null;
"
$hive -e "$sql"
这里的需要将C3,C2,C1和用主键join起来,并在条件中添加上所有的dt。
然后chmod一下即可使用:
./dwd_db.sh 2025-10-19
05DWS创建及导入DWD数据
在Hive中创建DWS层,接入DWD层,利用各维度表创建主题宽表模型。
DWS建表
进入sql文件夹,编写sql语句脚本:
【
制作的具体宽表此处仅为特例,具体需按照需求
这里的要求是:
将用户表和订单表连接起来,组合成用户行为宽表
将组合成为用户购买商品明细表
】
vim dws_ddl.sql
-- 进入数据库
use mall;
-- 创建用户行为宽表
drop table if exists dws_user_action;
create external table dws_user_action
(
user_id string comment '用户 id',
order_count bigint comment '下单次数 ',
order_amount decimal(16,2) comment '下单金额 ',
payment_count bigint comment '支付次数',
payment_amount decimal(16,2) comment '支付金额 '
) COMMENT '每日用户行为宽表'
PARTITIONED BY ( `dt` string)
stored as parquet
location '/warehouse/mall/dws/dws_user_action/'
tblproperties ("parquet.compression"="snappy");
-- 创建用户购买商品明细表
drop table if exists dws_sale_detail_daycount;
create external table dws_sale_detail_daycount
( user_id string comment '用户 id',
sku_id string comment '商品 Id',
user_gender string comment '用户性别',
user_age string comment '用户年龄',
user_level string comment '用户等级',
order_price decimal(10,2) comment '订单价格',
sku_name string comment '商品名称',
sku_tm_id string comment '品牌id',
sku_category3_id string comment '商品三级品类id',
sku_category2_id string comment '商品二级品类id',
sku_category1_id string comment '商品一级品类id',
sku_category3_name string comment '商品三级品类名称',
sku_category2_name string comment '商品二级品类名称',
sku_category1_name string comment '商品一级品类名称',
spu_id string comment '商品 spu',
sku_num int comment '购买个数',
order_count string comment '当日下单单数',
order_amount string comment '当日下单金额'
) COMMENT '用户购买商品明细表'
PARTITIONED BY ( `dt` string)
stored as parquet
location '/warehouse/mall/dws/dws_user_sale_detail_daycount/'
tblproperties ("parquet.compression"="snappy");
然后将sql导入至hive:
hive -f /home/warehouse/sql/dws_ddl.sql
DWD→DWS数据导入
编写shell脚本:
vim dws_db.sh
#! /bin/bash
APP=mall
hive=hive
#断延判断
if [ -n $1] ;then
log_date=$1
else
log_date=`date -d "-1 day" +%F`
fi
#完成用户行为宽表聚合的暂时表
function user_action()
{
APP=$1
hive=$2
log_date=$3
sql="
with
tmp_order as
(
select user_id sum(oc.total_amount) order_amount, count(*) order_count
from "$APP".dwd_order_info oc
where date_format(oc.create_time,'yyyy-MM-dd')='$log_date'
group by user_id
),
tmp_payment as
(
select user_id, sum(pi.total_amount) payment_amount,count(*) payment_count
from "$APP".dwd_payment_info pi
where date_format(pi.payment_time,'yyyy-MM-dd')='$log_date'
group by user_id
)
前面是常例。需要完成用户【以用户表为核心】行为宽表时,因为涉及到两个额外表order和payment,因此需要创建两个tmp表存储所需数据,然后将二表(去空)聚合在一起:
insert overwrite table "$APP".dws_user_action partition(dt='$log_date')
select
user_actions.user_id,
sum(user_actions.order_count),
sum(user_actions.order_amount),
sum(user_actions.payment_count),
sum(user_actions.payment_amount)
from
(
select
user_id,
order_count,
order_amount ,
0 payment_count ,
0 payment_amount
from tmp_order
union all
select
user_id,
0 order_count,
0 order_amount,
payment_count,
payment_amount
from tmp_payment
) user_actions
group by user_id;
"
$hive -e "$sql"
}
接着类同的,要创建【用户购买商品明细表】,因为是针对购买商品的,因此要以【订单详情表】为核心,组合【用户表】和【商品表】:
function user_sales()
{
# 定义变量
APP=$1
hive=$2
log_date=$3
sql="
set hive.exec.dynamic.partition.mode=nonstrict;
with
tmp_detail as
(
select
user_id,
sku_id,
sum(sku_num) sku_num ,
count(*) order_count ,
sum(od.order_price*sku_num) order_amount
from "$APP".dwd_order_detail od
where od.dt='$log_date' and user_id is not null
group by user_id, sku_id
)
insert overwrite table "$APP".dws_sale_detail_daycount partition(dt='$log_date')
select
tmp_detail.user_id,
tmp_detail.sku_id,
u.gender,
months_between('$log_date', u.birthday)/12 age,
u.user_level,
price,
sku_name,
tm_id,
category3_id ,
category2_id ,
category1_id ,
category3_name ,
category2_name ,
category1_name ,
spu_id,
tmp_detail.sku_num,
tmp_detail.order_count,
tmp_detail.order_amount
from tmp_detail
left join "$APP".dwd_user_info u
on u.id=tmp_detail.user_id and u.dt='$log_date'
left join "$APP".dwd_sku_info s on tmp_detail.sku_id =s.id and s.dt='$log_date';
"
$hive -e "$sql"
}
设置非严格是最佳实践。
其次是join操作,由于tmp是订单详情表详细信息的聚合,分别将用户表和商品表的维度退化。
最后实施函数的运算:
user_actions $APP $hive $log_date
user_sales $APP $hive $log_date
然后运行chmod和:
./dwd_db.sh 2025-10-19
06ADS创建及完成数据需求(复购率)计算【使用ai】
在Hive中创建ADS层,接入DWS层数据,并在此完成数据分析的运算,存储结果表。
须知复购率要求:
在保留各品类基本信息的前提下,记录该品类的单次复购率和多次复购率。
在DWS数据中,已有:
A.用户 id, 下单次数, 下单金额, 支付次数, 支付金额
B.用户 id, 商品 Id, 用户性别, 用户年龄, 用户等级, 订单价格, 商品名称, 品牌id, 商品三级品类id, 商品二级品类id, 商品一级品类id, 商品三级品类名称, 商品二级品类名称, 商品一级品类名称, 商品 spu, 购买个数, 当日下单单数, 当日下单金额。
因而品类基本数据包含:品牌id,一级品类id,一级品类名。
复购率基本数据可以由:当日下单数获得,可依次从原表对应于相同品牌的用户计数(count),以获得单一品牌+一级品类的总购买人数,从当日下单数,分类出购买一次,购买两次,以及购买两次及以上的情况,随后count其数量得到单一品牌+一级品类的购买1次,2次和多次购买人数。并据此计算复购率和多次复购率。
创建sql:
-- 进入数据库
use mall;
-- 创建品牌复购率表
drop table ads_sale_tm_category1_stat_mn;
create table ads_sale_tm_category1_stat_mn
(
tm_id string comment '品牌id ' ,
category1_id string comment '1级品类id ',
category1_name string comment '1级品类名称 ',
buycount bigint comment '购买人数',
buy_twice_last bigint comment '两次以上购买人数',
buy_twice_last_ratio decimal(10,2) comment '单次复购率',
buy_3times_last bigint comment '三次以上购买人数',
buy_3times_last_ratio decimal(10,2) comment '多次复购率' ,
stat_mn string comment '统计月份',
stat_date string comment '统计日期'
) COMMENT '复购率统计'
row format delimited fields terminated by '\t'
location '/warehouse/mall/ads/ads_sale_tm_category1_stat_mn/'
;
创建sh:
#!/bin/bash
# 定义变量方便修改
APP=mall
hive=hive
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n $1 ] ;then
log_date=$1
else
log_date=`date -d "-1 day" +%F`
fi
sql="
set hive.exec.dynamic.partition.mode=nonstrict;
insert into table "$APP".ads_sale_tm_category1_stat_mn
select
mn.sku_tm_id,
mn.sku_category1_id,
mn.sku_category1_name,
sum(if(mn.order_count>=1,1,0)) buycount,
sum(if(mn.order_count>=2,1,0)) buyTwiceLast,
sum(if(mn.order_count>=2,1,0))/sum( if(mn.order_count>=1,1,0)) buyTwiceLastRatio,
sum(if(mn.order_count>3,1,0)) buy3timeLast ,
sum(if(mn.order_count>=3,1,0))/sum( if(mn.order_count>=1,1,0)) buy3timeLastRatio ,
date_format('$log_date' ,'yyyy-MM') stat_mn,
'$log_date' stat_date
from
(
select od.sku_tm_id,
od.sku_category1_id,
od.sku_category1_name,
user_id ,
sum(order_count) order_count
from "$APP".dws_sale_detail_daycount od
where date_format(dt,'yyyy-MM')<=date_format('$log_date' ,'yyyy-MM')
group by od.sku_tm_id, od.sku_category1_id, od.sku_category1_name, user_id
) mn
group by mn.sku_tm_id, mn.sku_category1_id, mn.sku_category1_name;
"
$hive -e "$sql"
从以品牌和用户为依据进行购买次数聚合的表(该表的购买次数体现为单个不重复用户的行为)里抽取,检索其聚合次数和大于等于1为购买总人数,大于等于2则是复购人数,大于等于3则是多次复购人数。
编写完成,运行脚本即可。
07编写ADS数据导入至Mysql的脚本;提供查询服务
在node02中首先创建对应的sql脚本位置,和node03相似:
mkdir -p /home/warehouse/sql
进入文件夹,创建sql脚本:
vim mysql_sale_ddl.sql
-- 进入数据库
use mall;
-- 创建复购率表
create table ads_sale_tm_category1_stat_mn
(
tm_id varchar(200) comment '品牌id ' ,
category1_id varchar(200) comment '1级品类id ',
category1_name varchar(200) comment '1级品类名称 ',
buycount varchar(200) comment '购买人数',
buy_twice_last varchar(200) comment '两次以上购买人数',
buy_twice_last_ratio varchar(200) comment '单次复购率',
buy_3times_last varchar(200) comment '三次以上购买人数',
buy_3times_last_ratio varchar(200) comment '多次复购率' ,
stat_mn varchar(200) comment '统计月份',
stat_date varchar(200) comment '统计日期'
)
复购率表的复刻。
export MYSQL_PWD=DBa2020*装载环境变量方便sql操作
直接使用运行:mysql -uroot mall < /home/warehouse/sql/mysql_sale_ddl.sql
即可在node02创建所需数据表。
转至node03:
编写转数据脚本sqoop_export.sh:
#!/bin/bash
# 定义MySQL数据库名称
db_name=mall
# 定义数据导出函数
export_data() {
# 使用Sqoop将HDFS数据导出到MySQL
sqoop export \
# MySQL连接字符串,指定字符编码防止中文乱码
--connect "jdbc:mysql://node02:3306/${db_name}?useUnicode=true&characterEncoding=utf-8" \
# MySQL用户名
--username root \
# MySQL密码
--password DBa2020* \
# 要导出的MySQL表名(通过函数参数传入)
--table $1 \
# 使用1个Map任务进行导出(适合数据量不大的情况)
--num-mappers 1 \
# HDFS源数据路径(warehouse/mall/ads/表名)
--export-dir /warehouse/$db_name/ads/$1 \
# HDFS数据文件字段分隔符为制表符
--input-fields-terminated-by "\t" \
# 更新依据的字段组合(当这些字段值相同时执行更新而非插入)
--update-key "tm_id,category1_id,stat_mn,stat_date" \
# 更新模式:如果记录存在则更新,不存在则插入
--update-mode allowinsert \
# 将HDFS中的\N转换为MySQL的NULL(字符串字段)
--input-null-string '\\N' \
# 将HDFS中的\N转换为MySQL的NULL(非字符串字段)
--input-null-non-string '\\N'
}
# 根据传入参数执行不同的导出任务
case $1 in
# 如果参数是"ads_sale_tm_category1_stat_mn",导出该表
"ads_sale_tm_category1_stat_mn")
export_data "ads_sale_tm_category1_stat_mn"
;;
# 如果参数是"all",导出所有表(目前只有ads_sale_tm_category1_stat_mn)
"all")
export_data "ads_sale_tm_category1_stat_mn"
;;
esac
运行下脚本,就可以在mysql看到对应的数据了!
08使用Azkaban任务调度实现脚本自动化
使用Azkaban对以上脚本进行定时的自动运行:
在mysql中已经装载10-20日的数据。
在本地编写.job文件:(使用VScode)
import.job
type=command
do_date=${dt}
command=/home/warehouse/shell/sqoop_import.sh all ${do_date}
ods.job
type=command
do_date=${dt}
ddependencies=import
command=/home/warehouse/shell/ods_db.sh ${do_date}
dwd.job
type=command
do_date=${dt}
ddependencies=ods
command=/home/warehouse/shell/dwd_db.sh ${do_date}
dws.job
type=command
do_date=${dt}
ddependencies=dwd
command=/home/warehouse/shell/dws_db.sh ${do_date}
ads.job
type=command
do_date=${dt}
ddependencies=dws
command=/home/warehouse/shell/dws_db.sh ${do_date}
export.job
type=command
do_date=${dt}
ddependencies=ads
command=/home/warehouse/shell/sqoop_export.sh all ${do_date}
将以上打压缩为一个文件“mall-job”
然后在node01/02/03上分别启动azkaban:
azkaban-executor-start.sh
在node03进入azkaban服务目录:
cd /opt/app/azkaban/server/
azkaban-web-start.sh
启动服务后进入网址
[Azkaban] Server running on ssl port 8443.
也就是:https://(前缀一定要加)192.168.10.9:8443
账号与密码均为:admin
点击create project,upload之前的zip
进而在flow中,传入参数dt。传入参数useExecutor:node03(指定执行节点/azkaban装载节点,也是zip脚本的放置位置)
点击schedule即可为此次任务做定时。
至此就可以运行之前正常运行的所有程序步骤!

















 3824
3824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









