



一、*Mysql数据库的连接(2次)
1、MySQL 服务启动
确保 MySQL 服务已经启动:
可以通过命令检查,也可以在Windows的可视化界面查看:底层搜索栏输入“服务”,即打开服务管理器,在服务列表中查找 MySQL名称,查看其状态,Running表示服务正在运行,Stopped表示服务未启动。右键点击该服务,选择 Start(启动)或 Restart(重启)。
- MySQL 数据库支持多种连接方式,包括:命令行客户端、GUI 工具(如 DBeaver、MySQL Workbench)、编程语言(如 Python、Java、PHP)
2、使用命令行连接
第一种:使用MySQL提供的客户端命令行工具,叫“MuSQL 8.0 Command Line Client”
输入密码即可连上
第二种: Windows命令行连接
mysql [-h 主机地址] [-P 端口号] -u 用户名 -p 主机地址和端口号可省略,因为一般都是默认的示例:
mysql -h 127.0.0.1 -P 3306 -u root -p 系统会提示输入密码,成功后进入 MySQL 命令行界面。
注意:使用这种方式需要配饰PATH环境变量,把mysql地址的bin目录加到path
3、使用编程语言连接(Python)
- 安装驱动程序
pip install mysql-connector-python- 代码示例
import mysql.connector
# 配置连接信息
config = {
'host': '127.0.0.1', #主机地址
'user': 'root', #用户名
'password': 'your_password', #密码
'database': 'your_database', #数据库名称,一个数据库服务器中可以创建多个数据库,一个数据库里可以有多个表
'port': 3306 #端口号,默认的
}
try:
# 建立连接
conn = mysql.connector.connect(**config)
print("连接成功!")
# 创建游标
cursor = conn.cursor()
# 执行 SQL 查询
cursor.execute("SELECT DATABASE();")
result = cursor.fetchone()
print("当前数据库:", result)
# 关闭连接
cursor.close()
conn.close()
except mysql.connector.Error as e:
print("连接失败,错误:", e)
二、在命令行定义和使用数据库
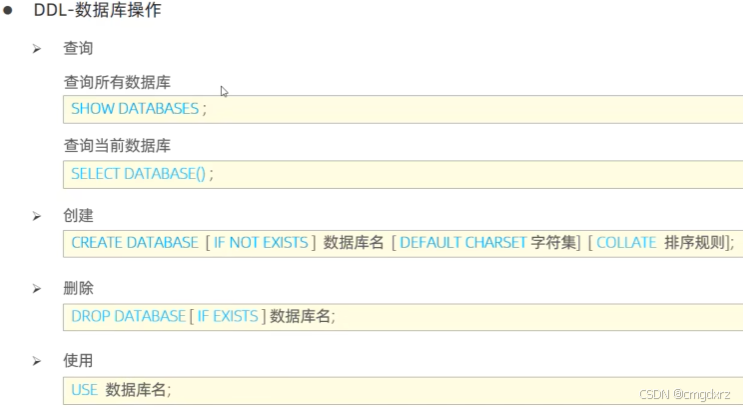
use 数据库名 后,就可以对该数据库进行表的增删改查了
三、常考SQL语句
- 删除一个表
DROP TABLE table_name;- 学生成绩表student_scores,查询课程号course_id为123且成绩score<60的学生学号student_id
SELECT student_id
FROM student_scores
WHERE course_id = 123
AND scores < 60;
- 学生成绩表student_scores,查询成绩score前20的学生信息
SELECT *
FROM student_scores
ORDER BY score DESC
LIMIT 20;order by默认升序排序,如果要降序排序需要加desc
- 修改某一列的类型
-- 将 `age` 列的数据类型修改为 `BIGINT`
ALTER TABLE students
MODIFY COLUMN age BIGINT;
-- 修改列名为 `student_age`,同时将类型改为 `BIGINT`
ALTER TABLE students
CHANGE COLUMN age student_age BIGINT;
modify column:仅修改数据类型。
change column:不仅可以修改类型,还可以修改列名。
- 查询员工薪资第二高的信息
SELECT *
FROM employees
WHERE salary = (
SELECT DISTINCT salary
FROM employees
ORDER BY salary DESC
LIMIT 1 OFFSET 1
);
使用到了子查询
OFFSET 是用于跳过查询结果中的前 N 行的关键字,通常与 LIMIT 一起使用,主要用于分页查询或跳过不需要的记录。
- 一张表里很多班,每个班很多学生,每个学生都有成绩,查询每个班的平均分
SELECT class_id,avg(score)
FROM students
GROUP BY class_id;- 查找重复的数据
SELECT name, COUNT(*)
FROM students
GROUP BY name
HAVING COUNT(*) > 1;
四、一些概念
1、聚合函数
聚合函数(Aggregate Functions)是一类用于对一组值进行计算的函数,通常与 SELECT 和 GROUP BY 子句结合使用,用于对结果进行汇总或统计。
1️⃣COUNT():计算行的数量
括号里可以是*,其他聚合函数都不可以使用*
SELECT COUNT(*) AS total_employees
FROM employees; # 结果:返回员工总人数。2️⃣SUM():计算数列值总和
SELECT SUM(salary) AS total_salary
FROM employees; # 结果:返回薪资总和。3️⃣AVG():计算数列值平均值
SELECT AVG(salary) AS avg_salary
FROM employees; # 结果:返回薪资平均值。
4️⃣MAX():返回列中最大值
同上
5️⃣MIN():返回列中最小值
同上
注意:
- 聚合函数会忽略
NULL值(COUNT(*)除外)。如AVG(salary)不会计算包含NULL的薪资。 - 聚合函数不能用在where条件中使用
- 在没有使用group by时,不能将聚合函数与普通列直接结合,否则会报错。
2、数据分组
按照字段分组,表示此字段相同的数据被放到一个组里;
分组的目的是配合聚合函数,让聚合函数对每一组的数据分别进行统计
SELECT sex,count(*) from students group by sex; #查询各种性别的人数3、主键、外键、索引的区别
- 主键是表中的一个或多个字段,它的值用于唯一表示一张表中的记录。主键不能重复也不能为空。建表时系统会自动给主键建索引,按照主键查记录,效率会很高,如果没有唯一可标识的数据,则可以用auto_increment修饰id字段自增长。
- 外键是用来和其他表建立联系用的,表的外键是另一张表的主键。外键可以重复也可以为空。
- 索引是对数据库中的某些关键字段进行存储,类似于数据中的目录,里面包含了关键数据和数据的位置,通常需要对where条件后的字段加索引,不能加太多,一个表不超过4个索引。
4、*左连接、右连接、内连接、全连接(2次)
都是数据库表连接的方式
- 左连接(LEFT JOIN):左连接以左表为基础,展示左表特有的数据,加上左右两个表同时存在的数据(内连接内容)。对于右表中不存在的数据使用null填充。
- 右连接(RIGHT JOIN):右连接以右表为基础,展示右表特有的数据,加上左右两个表同时存在的数据(内连接内容)。对于左表中不存在的数据使用null填充。
- 内连接(INNER JOIN):展示两个表中同时存在的数据。
- 全连接(FULL JOIN):展示左右表中的所有记录。mysql不支持FULL JOIN 可以使用UNION
- 其他三种连接都是在以上基础上,加上where语句。参考:mysql的7种join(图码并茂,清晰易懂!)_mysql join-优快云博客
5、UNION
在 MySQL 中,UNION 用于合并两个或多个 SELECT 语句的结果.并去除重复的行
SELECT column1, column2 FROM table1
UNION
SELECT column1, column2 FROM table2;
6、事务
MySQL数据库04|内置函数、存储过程、视图、事务、索引-优快云博客
7、索引
MySQL数据库04|内置函数、存储过程、视图、事务、索引-优快云博客
8、排序函数
1️⃣order by:排序关键字
SELECT * FROM employees ORDER BY salary ASC; -- 按薪资升序排序
SELECT * FROM employees ORDER BY salary DESC; -- 按薪资降序排序
2️⃣field():自定义排序
-- 语法:FIELD(column, val1, val2, val3, ...) --不在val1, val2, val3, ...中的记录放在最后
SELECT *
FROM employees
ORDER BY FIELD(level, '高级', '中级', '初级');
3️⃣round():随机排序
RAND() 生成 0 到 1 之间的随机数,用于随机排序。
-- 随机排序
SELECT *
FROM products
ORDER BY RAND() LIMIT 5; -- 随机选出 5 条记录
四、其他问题
1、*数据库引起数据慢查询的原因?(两次)
(1)索引问题
- 缺少索引:数据库需要进行全表扫描
- 索引失效:使用
LIKE "%xxx%"可能导致索引无法使用;对索引字段进行函数计算(如WHERE LEFT(name, 3) = 'abc')可能导致索引失效。(2)SQL 语句问题
- 查询数据过多
- JOIN操作未优化:没有索引,数据量过大
- 子查询嵌套过深
(3)数据库锁问题
- 行锁、表锁、死锁等导致查询等待
(4)服务器资源瓶颈
- CPU 过载:高并发查询或复杂计算可能导致 CPU 资源耗尽。
- 频繁的磁盘读取导致I/O瓶颈
- 内存不足
(5)网络延迟
2、数据库死锁
数据库死锁是指两个或多个事务(Transaction)相互等待对方释放资源,导致它们都无法继续执行的情况。
举个简单的例子:
- 事务 A 锁住了表 X,并尝试获取表 Y 的锁。
- 事务 B 锁住了表 Y,并尝试获取表 X 的锁。
- 事务 A 等待事务 B 释放表 Y,但事务 B 也在等待事务 A 释放表 X。
- 由于双方都不释放锁,就形成了死锁,导致事务无法继续执行。
如何避免死锁?
① 避免长时间持有锁
-
事务执行时,尽量减少锁的持有时间,执行完后立即提交 (
COMMIT) 或回滚 (ROLLBACK)。
② 统一锁定顺序
-
例如,所有事务都先锁住
account1,再锁住account2,避免交叉锁定导致死锁。
③ 使用超时机制
-
在 MySQL、PostgreSQL、SQL Server 中可以设置超时,避免事务无限等待:
④ 让数据库自动检测和解除死锁
-
许多数据库(如 MySQL、Oracle)都有死锁检测机制,当检测到死锁时,会自动回滚其中一个事务:
3、事务的四大特性(1次)

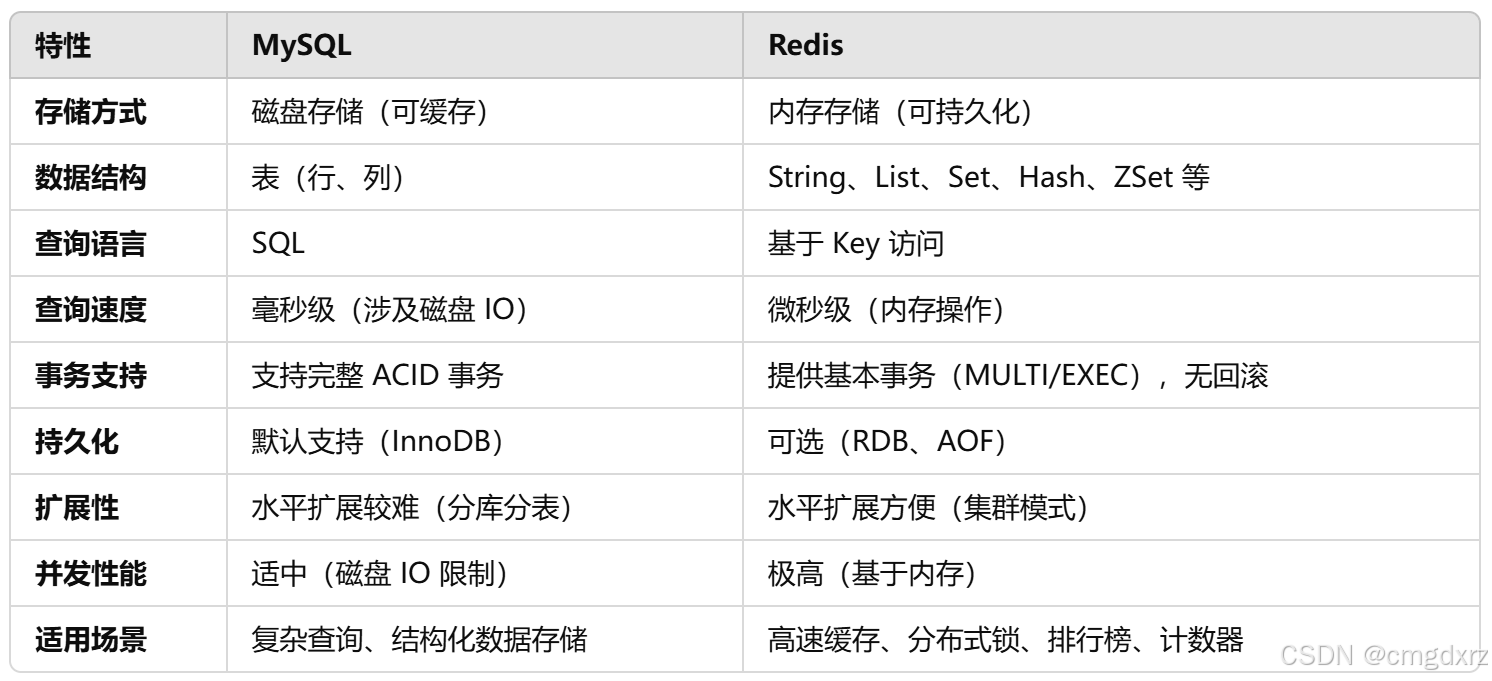
4、MySql和Redis的区别(3次)
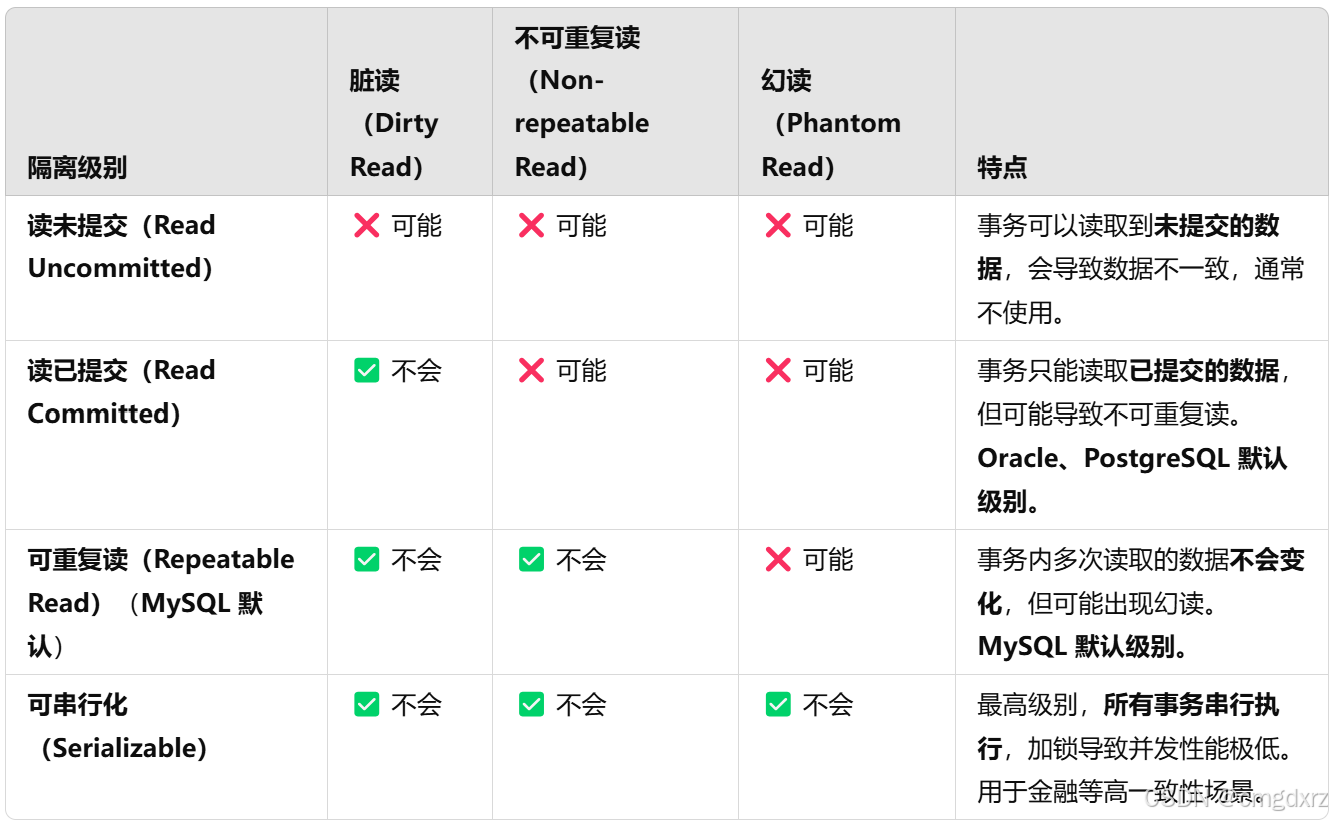
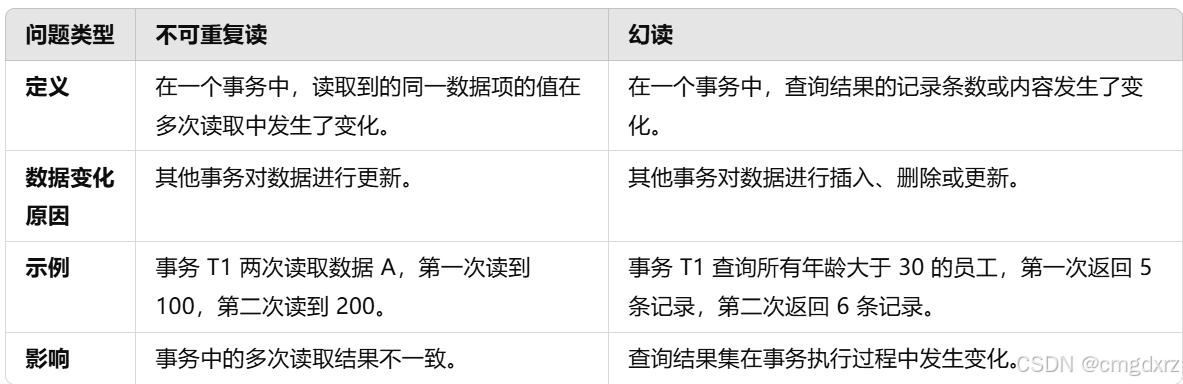
5、Mysql的四种隔离级别(2次)
并发事务之间互不干扰,事务的执行过程对其他事务不可见,直到提交后才可见
6、数据库的索引类型

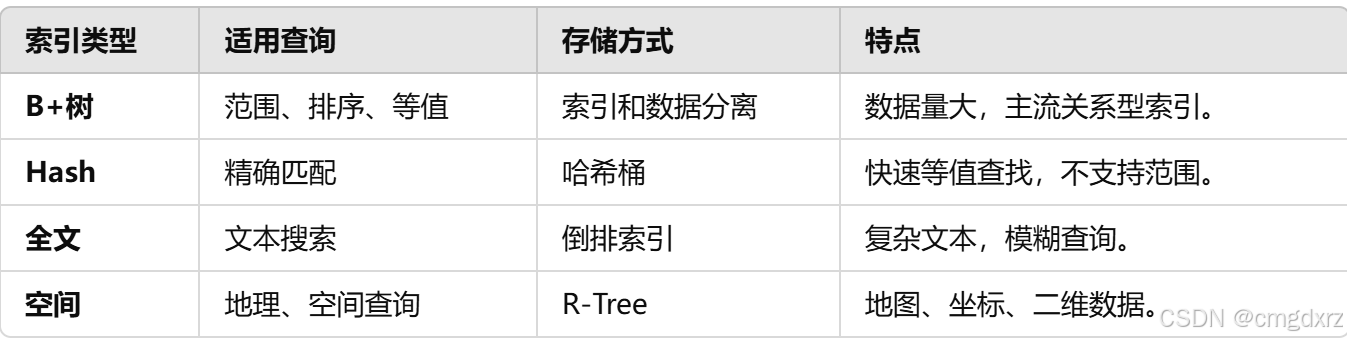
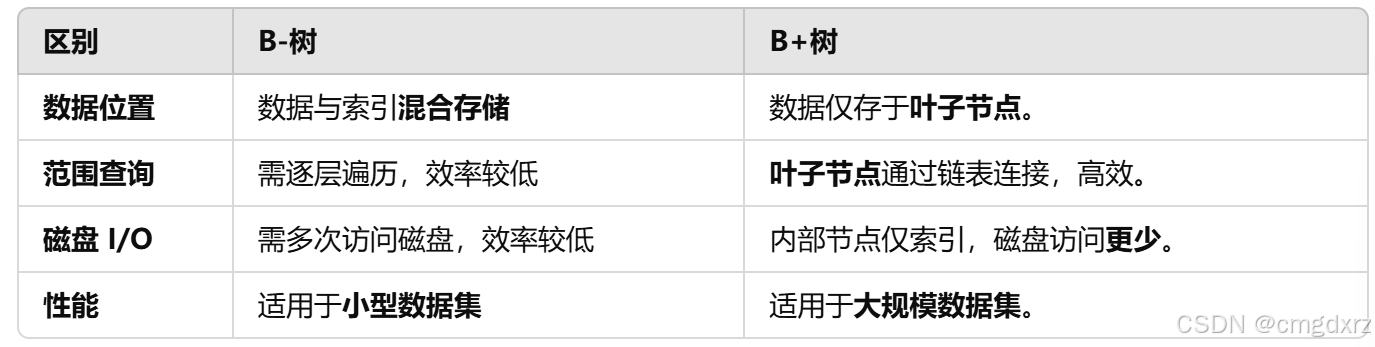
7、B树和B+树
B-树是一种多路平衡查找树(Balanced Tree),其特点是保证数据始终保持平衡,所有叶子节点处于同一高度。B-树索引用于对范围查询、排序 和 模糊匹配 提供良好的性能。
B+树是 B-树的扩展版本,数据库中大部分索引(如 MySQL InnoDB 引擎的主键索引)都采用 B+树实现。特点:叶子节点存储数据,非叶子节点存储键值+指针。
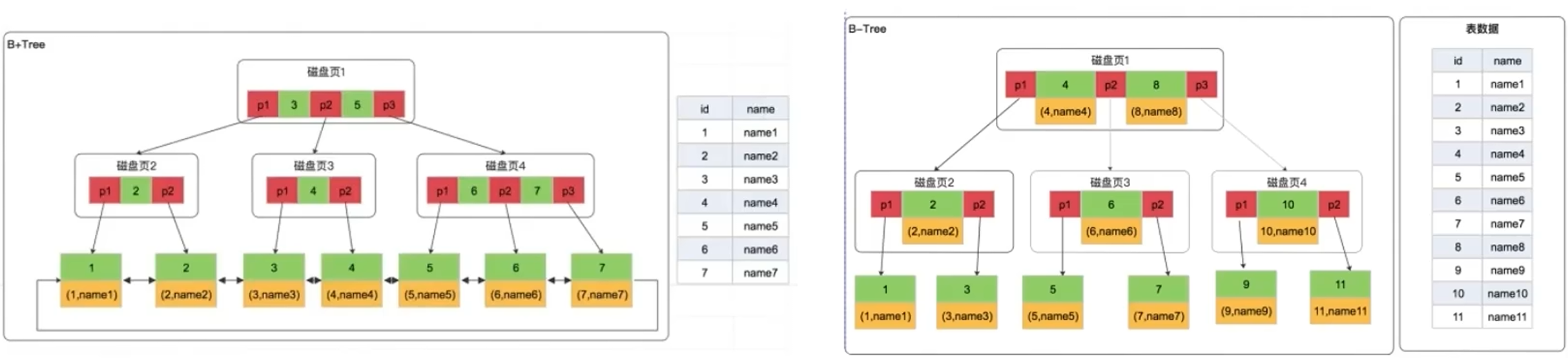
mysql采用B+树构建索引的优点:
- 数据放在叶子节点,可以腾出空间让分支节点可以组织更宽的树一一提高数据检索性能。
- 叶子节点双向链表,所有数据都维护在叶子节点一一对范围查询和排序性能更好
8、分库分表是什么?怎么实现?
分库分表是将一个大型数据库/表拆分成多个小型数据库/表的技术:
分库:当数据库的读或写的QPS过高,导致数据库连接不足,需要分库,通过增加数据库实例的方式,来提供更多的数据库连接,提升系统并发性能。
分表:当单表数据量非常大,但并发不高,所以数据库的连接够用,但是由于此时B+树又宽又高,导致慢查询,就要考虑水平拆分(也就是按行拆分)表,减少单表的数据量,从而提升查询性能。
分库+分表:数据库连接不够,且单表数据量也非常大的情况,导致查询速度慢,考虑既分库又分表。
实现方式:可以按照数范围、哈希取模、时间等方式实现分库或表的水平拆分。
9、什么情况导致mysql的索引失效?
- 当
OR两侧的条件有些不能利用索引时,或OR运算符两侧的字段数据类型不同时(会隐式类型转换)。 - 如果
LIKE前面有通配符(%),索引将失效。会进行全表扫描。 - 对索引字段进行计算或函数操作。
- 所查询的列使用过多NULL值,并且查询条件包含判断该列
IS NULL或IS NOT NULL。 DISTINCT和GROUP BY需要排序或分组操作,索引不总是能完全加速这些操作。
所有章节:



















 1286
1286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









