*&---------------------------------------------------------------------*
*& Report YABC_TEXT_LEN
*&---------------------------------------------------------------------*
*&
*&---------------------------------------------------------------------*
REPORT YABC_TEXT_LEN.
DATA: GO_SALV TYPE REF TO CL_SALV_TABLE.
PARAMETERS: P_STR TYPE STRING.
PARAMETERS: P_LEN TYPE I.
DATA: BEGIN OF GT_STR OCCURS 0.
DATA: ZLINE TYPE CHAR255.
DATA: END OF GT_STR.
START-OF-SELECTION.
PERFORM SUB_GET_STRING_TO_ITAB_LEN TABLES GT_STR USING P_STR P_LEN .
PERFORM FRM_DISPLAY_ALV TABLES GT_STR USING GO_SALV .
*&---------------------------------------------------------------------*
*& Form SUB_TRAN_GET_ZH_EN
*&---------------------------------------------------------------------*
* text
*----------------------------------------------------------------------*
FORM SUB_TRAN_GET_ZH_EN USING I_STR_SPLIT CHANGING CV_ZH CV_EN.
DATA: LT_RESULT_TAB TYPE MATCH_RESULT_TAB.
DATA: L_STRM1 TYPE STRING VALUE '[^\\u4E00-\\u9FA5\\uF900-\\uFA2D]'. " 汉字
DATA: L_STRM2 TYPE STRING VALUE '[\\u4E00-\\u9FA5\\uF900-\\uFA2D]'. " 非汉字
DATA: L_STR1 TYPE STRING.
L_STR1 = I_STR_SPLIT.
CLEAR: CV_ZH,CV_EN.
""提取汉字
FIND ALL OCCURRENCES OF REGEX L_STRM1 IN L_STR1
RESULTS LT_RESULT_TAB.
DESCRIBE TABLE LT_RESULT_TAB[] LINES CV_ZH.
""非汉字
FIND ALL OCCURRENCES OF REGEX L_STRM2 IN L_STR1
RESULTS LT_RESULT_TAB.
DESCRIBE TABLE LT_RESULT_TAB[] LINES CV_EN.
ENDFORM.
*&---------------------------------------------------------------------*
*& Form SUB_GET_STRING_TO_ITAB_LEN
*&---------------------------------------------------------------------*
*& text
*&---------------------------------------------------------------------*
FORM SUB_GET_STRING_TO_ITAB_LEN TABLES IT_STR TYPE STANDARD TABLE
USING I_STR
I_LEN.
DATA: L_STR_IN TYPE STRING. " 字符串
DATA: L_STR_SPLIT TYPE STRING. " 分割长度
DATA: L_LEN TYPE I. " 字符串总长度
DATA: L_IDX TYPE I. " 字符串分割截取位置
DATA: L_ZH TYPE I.
DATA: L_EN TYPE I.
DATA: L_CON_STR TYPE STRING. " 分割拼接当前字符串
DATA: L_CON_STR_LEN TYPE I. " 分割计算当前长度
L_STR_IN = I_STR.
L_STR_SPLIT = I_LEN.
L_LEN = STRLEN( L_STR_IN ).
DO L_LEN TIMES.
L_IDX = SY-INDEX - 1.
DATA(L_CHAR) = L_STR_IN+L_IDX(1).
PERFORM SUB_TRAN_GET_ZH_EN USING L_CHAR CHANGING L_ZH L_EN.
""" 累计拼接后的总长度
L_CON_STR_LEN = L_CON_STR_LEN + L_ZH * 2 + L_EN.
""""" 分割计算当前长度 大于 分割长度
IF L_CON_STR_LEN GT L_STR_SPLIT.
APPEND L_CON_STR TO IT_STR.
CLEAR: L_CON_STR.
"" 分割后重新赋值当前字符长度
CLEAR: L_CON_STR_LEN.
L_CON_STR_LEN = L_ZH * 2 + L_EN.
ENDIF.
L_CON_STR = L_CON_STR && L_CHAR.
""" 计算到总长度位置时
IF SY-INDEX = L_LEN.
APPEND L_CON_STR TO IT_STR.
ENDIF.
ENDDO.
ENDFORM.
*&---------------------------------------------------------------------*
*& Form FRM_DISPLAY_ALV
*&---------------------------------------------------------------------*
* text
*----------------------------------------------------------------------*
* --> p1 text
* <-- p2 text
*----------------------------------------------------------------------*
FORM FRM_DISPLAY_ALV TABLES PT_TAB TYPE STANDARD TABLE
USING LR_TAB TYPE REF TO CL_SALV_TABLE.
DATA: LR_FUNS_L TYPE REF TO CL_SALV_FUNCTIONS_LIST.
DATA: LR_DISPSET TYPE REF TO CL_SALV_DISPLAY_SETTINGS.
DATA: LO_EVENTS TYPE REF TO CL_SALV_EVENTS_TABLE.
DATA: LR_COLS TYPE REF TO CL_SALV_COLUMNS_TABLE.
DATA: LR_SELC TYPE REF TO CL_SALV_SELECTIONS.
DATA: L_ERROR TYPE REF TO CX_SALV_MSG.
DATA: L_ERR_MSG TYPE STRING.
TRY .
CL_SALV_TABLE=>FACTORY(
IMPORTING
R_SALV_TABLE = LR_TAB
CHANGING
T_TABLE = PT_TAB[] ).
CATCH CX_SALV_MSG INTO L_ERROR.
L_ERR_MSG = L_ERROR->GET_TEXT( ) .
WRITE: L_ERR_MSG.
ENDTRY.
" 标题
DATA: L_GC_TITLE TYPE LVC_TITLE.
DATA: L_LC_COUNT TYPE STRING.
L_GC_TITLE = TEXT-Z11 .
DESCRIBE TABLE PT_TAB LINES L_LC_COUNT.
CONCATENATE SY-TITLE L_GC_TITLE L_LC_COUNT INTO L_GC_TITLE.
LR_DISPSET = LR_TAB->GET_DISPLAY_SETTINGS( ).
LR_DISPSET->SET_LIST_HEADER( L_GC_TITLE ).
" 工具条
LR_FUNS_L = LR_TAB->GET_FUNCTIONS( ).
LR_FUNS_L->SET_ALL( ABAP_TRUE ).
" 设置记录选择框
LR_SELC = LR_TAB->GET_SELECTIONS( ).
LR_SELC->SET_SELECTION_MODE( IF_SALV_C_SELECTION_MODE=>CELL ).
" 设置字段优化
LR_COLS = LR_TAB->GET_COLUMNS( ).
LR_COLS->SET_OPTIMIZE( 'X' ). " 优化列宽度
LR_TAB->DISPLAY( ).
ENDFORM.

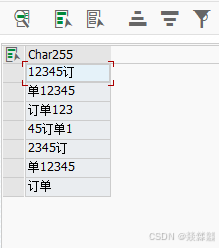






















 2386
2386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









