



点击蓝字⬆ 关注我们
本文共计2640字 预计阅读时长8分钟
2025年开年,在人工智能浪潮的推动下,DeepSeek等大模型的横空出世已渗透到企业的核心业务环节,它不仅重新定义了人机交互的边界,更将数据的价值推向了前所未有的高度。越来越多的企业意识到,数据已不再是业务的副产品,而是驱动决策、优化体验、构建竞争壁垒的核心资产。
然而,当大多数企业已建立起成熟的数据仓库(Data Warehouse)来分析交易、日志、用户行为等结构化数据,但是另一类数据(文本、图像、音视频等非结构化数据)并没有发挥出分析的价值,如同“暗数据”般沉睡在系统中。据IDC预测,到2025年,全球非结构化数据占比将突破80%,但仅有不到20%的企业能有效挖掘其潜力。在这场数据智能的竞赛中,传统数仓的“结构化思维”已显疲态,而融合向量计算能力的新一代智能数据仓库,正成为破局的关键。
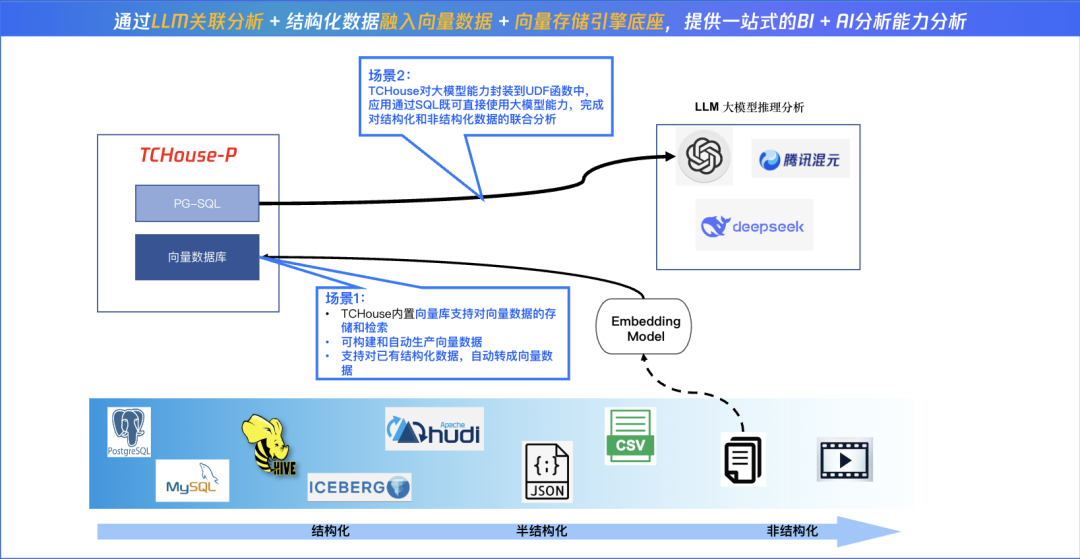
腾讯TCHouse-P 2025年的升级能力之一就是针对非结构化数据进行分析,借助自身向量引擎(下图场景 1)+DeepSeek等大模型联合能力(下图场景 2),实现结构+非结构数据的联合分析,TCHouse-P真正成为实现企业数据智能的核心基座,也让非结构化数据从企业“成本负担”转化为“战略资产”。
1
DeepSeek启示录-非结构化数据的价值创造
DeepSeek的成功验证了**嵌入表示(Embedding)**作为通用语义载体的可行性。通过将文本映射为高维向量,模型不仅能捕捉词汇间的语法相关性(如"猫→狗"),更能揭示深层的概念相似性(如"算法→数学→抽象思维")。这为企业指明了一条路径:构建能够原生支持向量运算的新型数据基础设施,使非结构化数据真正融入分析主链。
非结构化数据中蕴藏着用户真实需求、市场趋势乃至创新灵感。例如,电商平台的商品评论中隐藏着消费者对“便携性”“耐用性”的隐性诉求;工业设备的运维日志可能预示着潜在的故障模式;医疗影像的像素阵列则是疾病诊断的核心依据。然而,传统数仓的表格范式对此束手无策——它们擅长处理“用户ID-购买金额-时间戳”的规整记录,却难以解析一段客服对话的情感倾向,或是一张设计图纸的语义特征。
但是,要让非结构化数据“开口说话”,需经历两个关键跃迁:向量化存储与语义化分析。这也正是TCHouse-P向量引擎(pgvector)的核心使命。与TCHouse-P传统结构化数据分析能力不同,TCHouse-P的向量引擎通过将文本、图像等数据映射为高维向量(如768维的BERT嵌入),使得“语义相似度”可被量化计算。例如,将“智能手机”和“5G旗舰机型”的向量距离缩短至0.1,而“智能手机”与“咖啡机”的距离拉大到1.2,从而实现精准的语义检索。TCHouse-P向量化引擎无需将非结构化数据迁移至独立系统,直接在数仓内完成“结构化表+向量索引”的统一管理,比如,零售企业可在同一张商品表中,既有SKU、价格等字段,又包含商品描述文本的向量化结果,彻底告别“结构化分析靠数仓或者 Hive,语义搜索靠Elasticsearch”的割裂架构。
2
如何通过TCHouse-P
实现高效的向量存储和检索
✧ TCHouse-P 向量引擎现状:TCHouse-P集成pgvector后,已完成对pgvector的分布式架构改造,同时优化数据分片和路由规则、跨节点向量计算下推、混合查询优化、资源隔离以及向量存储和列式存储引擎的兼容,简单说,TCHouse-P通过pgvecter已支持对向量数据的数存储和检索。
➢ 存储方面支持的向量格式除了传统embedding模型的单精度浮点数外,还支持半精度浮点数,二元向量或者稀疏向量以及对上述类型在存储上的性能优化
➢ 检索方面同时支持精确检索和模糊检索。支持多度量相似性计算,通过内置余弦相似度(<=>)、欧氏距离(<->)、内积(<#>)等算子,支持复杂查询场景
➢ HNSW/IVFFlat/Binary/Sparse索引动态适配
✧ 具体 TCHouse-P 的 SQL示例:
--TCHouse-P已经支持vector类型数据,可以直接创表
CREATE TABLE items (id bigserial PRIMARY KEY, embedding vector(3));
--添加2条向量数据
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]');
--向量检索(基于L2距离度量,向量在空间中的直线距离,值越小,表示两个向量越相似)
SELECT * FROM items ORDER BY embedding <-> '[3,1,2]' LIMIT 5;○ 具体应用场景示例:
为特定用户(user_id=“123”)推荐与其历史行为向量相似的产品,具体实现逻辑是通过计算用户行为向量(ub.user_vector)与产品向量(p.embedding)的欧氏距离(<->),筛选出距离小于0.2的产品,并按相似度排序返回。
--TCHouse-P已经支持vector类型数据,可以直接创表
CREATE TABLE items (id bigserial PRIMARY KEY,embedding vector(3));
--添加2条向量数据
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]');
--向量检索(基于L2距离度量,向量在空间中的直线距离,值越小,表示两个向量越相似)
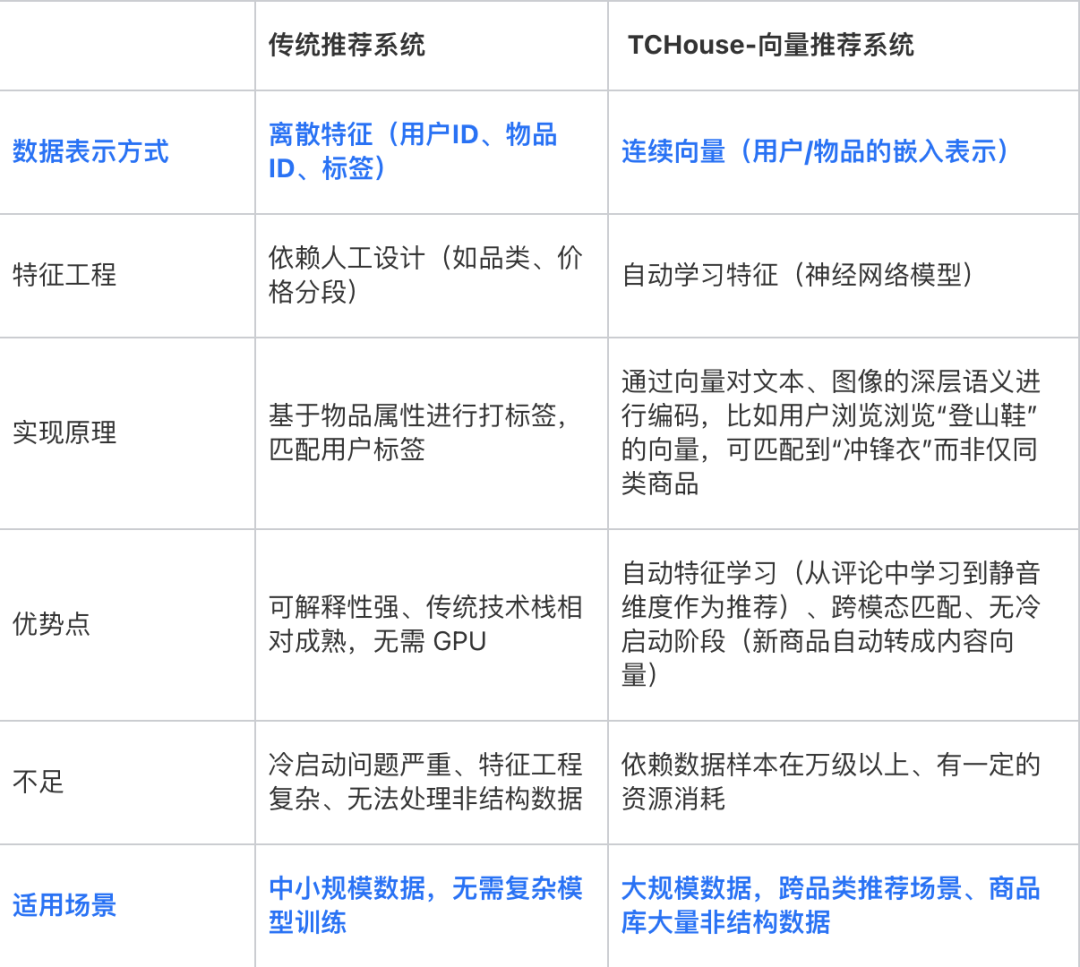
SELECT * FROM items ORDER BY embedding <-> '[3,1,2]' LIMIT 5;○ 与传统推荐系统的差异分析
3
TCHouse-P&DeepSeek的新火花
SQL驱动的AI普惠化
TCHouse-P另一大核心能力是通过UDF(用户自定义函数)封装DeepSeek等模型的接口能力,企业可直接用SQL调用大模型来完成对模型能力的调用。
流程和场景如下:
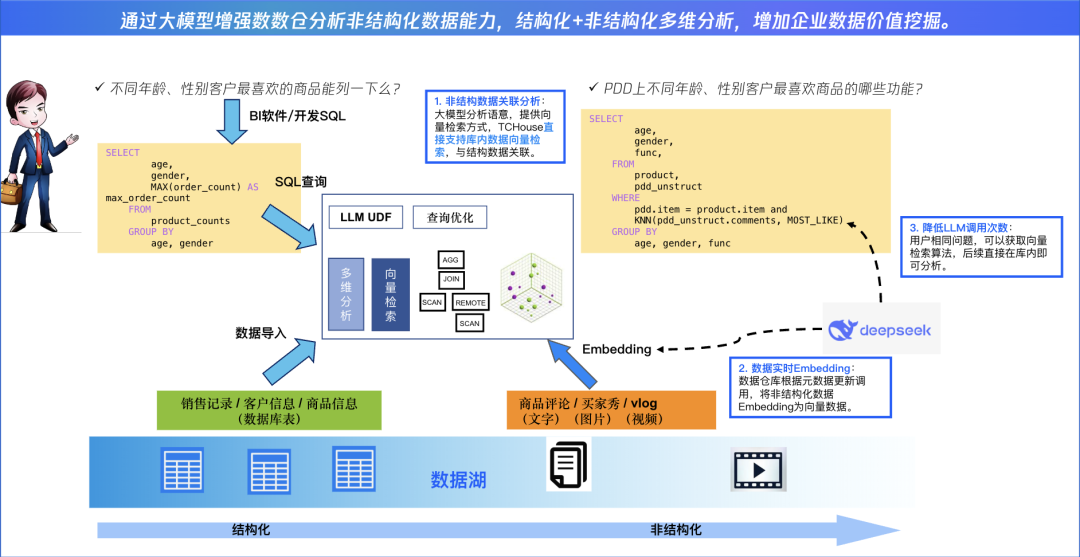
比如,在分析客户工单时,一条SQL即可完成“情感分析(调用NLP模型)-关键实体抽取(调用NER模型)-相似案例推荐(向量检索)”的全链路处理:
--定义情感分析UDF:情感分析模型调用
CREATE FUNCTION ml_sentiment_analysis(text STRING)
--此处省略定义过程,调用DeepSeek-API--
-- 定义实体识别UDF:提取产品名称
CREATE FUNCTION ml_ner_extract(text STRING, entity_type STRING)
--此处省略定义过程,会加载各行业的精调模型--
-- 定义文本向量化UDF:生成Embedding
--此处省略定义过程,将文本返回成 768维向量--
-- 查询
SELECT
ticket_id,
-- 调用情感分析UDF,自动批处理提升性能
ml_sentiment_analysis(content) AS sentiment_score,
-- 调用实体识别UDF,提取产品实体
ml_ner_extract(content, 'product') AS product_name,
-- 子查询:向量检索关联知识库
(SELECT kb.product_id
FROM knowledge_base kb
ORDER BY kb.embedding <-> text_to_vector(t.content) -- 计算向量距离
LIMIT 1) AS related_product_id
FROM customer_tickets t
WHERE
create_time > '2025-01-01'
-- 混合过滤:结构化条件+语义条件
AND ml_sentiment_analysis(content) < -0.7 -- 筛选负面情感
AND ml_ner_extract(content, 'product') IS NOT NULL;○ 其他场景举例:
✧ 金融客诉分析-识别高风险投诉
SELECT ...
WHERE ml_ner_extract(content, 'financial_risk') = '资金冻结'
AND sentiment_score < -0.9;✧ 电商产品推荐-根据评论语义推荐替代品
SELECT product_id,
(SELECT product_name FROM knowledge_base
ORDER BY embedding <-> text_to_vector('轻便透气') LIMIT 1) AS suggestion
FROM product_reviews;○ 这种调用方式带来的好处是非常多方面的
✧ 【超便捷】“SQL+AI”的模式,让数据分析师无需学习Python或ML框架,即可在数仓中完成复杂的非结构化数据分析。
✧ 【低成本】可对大模型的调用进行动态批处理,UDF自动合并多个请求,调用大模型批量推理(如50条/次),大幅减少大模型API调用开销。同时这种针对数仓架构就能进行 DeepSeek大模型能力的落地,对金融、农文旅建、教育、政务、能源工业等行业的非结构化数据分析成本降低70%以上。
✧ 【分析加速】高频调用的模型(如行业精调模型)常驻内存,避免重复加载;向量索引加速,比如向量字段建立HNSW索引,亿级数据检索<100ms。
4
TCHouse-P可落地的
行业应用实践
向量能力与数仓的融合,绝非简单的功能叠加,而是从架构到场景的体系化重构,在SnowFlake以及国内等产品的落地探索中,已有非常多的场景可以落地实践:
✧ 场景一:多维关联增强分析
某金融集团在数仓中内置风控报告的向量索引,将监管文件、历史案例与实时交易数据进行联合分析。通过SQL查询快速定位“与高风险模式相似的交易”,使洗钱识别效率提升40%。
--省略:高风险模式向量插入、监管文件向量插入、历史案例向量插入
--省略:基于高风险、监管文件、历史案例联合后的综合风险向量库的建立过程
-- 直接展示查询与高风险模式相似的交易的示例
WITH ranked_transactions AS (
SELECT
t.transaction_id,
t.transaction_vector,
r.risk_vector,
t.transaction_vector <-> r.risk_vector AS distance
FROM
transactions t
CROSS JOIN
risk_vector_library r
ORDER BY
distance
LIMIT 5
)
SELECT * FROM ranked_transactions;✧ 场景二:实时推荐引擎
一家视频平台将用户观看记录实时向量化,在数仓中通过<->运算符计算视频相似度。当用户点击一部纪录片,系统立即返回:
SELECT video_id, title FROM videos
WHERE category='纪录片'
ORDER BY embedding <-> '[0.23, 0.56, 0.41]' -- 当前播放视频的向量
LIMIT 10;推荐响应时间从秒级降至毫秒级,点击率提升18%。
✧ 场景三:知识图谱增强
制造业客户将设备手册、故障记录转化为向量,并与传感器时序数据关联。通过SQL直接查询“与当前振动波形相似的历史故障”,精准定位设备隐患,减少非计划停机70%。
--省略历史故障波形向量的插入以及传感器时序数据的向量转换和插入
--直接展示查询与当前振动波形相似的历史故障
WITH ranked_faults AS (
SELECT
s.timestamp,
s.vibration_vector,
f.fault_id,
f.fault_vector,
s.vibration_vector <-> f.fault_vector AS distance
FROM
sensor_data s
CROSS JOIN
fault_records f
WHERE
s.timestamp = '2025-10-01 10:02:00' -- 当前时间戳
ORDER BY
distance
LIMIT 1
)
SELECT * FROM ranked_faults;5
TCHouse-P适合哪些客户
探索更多商机
○ 预算敏感型客户:中小型企业、传统行业(如区域银行、制造工厂),IT预算有限,需最大化复用现有数仓资源;同时通过TCHouse-P的UDF减少大模型调用次数。
○ 数据混合型客户:同时拥有大量结构化和非结构化数据(如电商、保险),急需打破数据孤岛,对企业非结构化数据、结构数据进行联合分析。
○ AI初步探索客户:尚未建立完整MLOps体系,希望通过SQL快速验证AI场景,降低试错成本。
○ 合规强监管客户:金融、医疗、政务机构,要求数据不出仓、全链路审计,避免引入外部向量库导致合规风险。
6
未来TCHouse-P的
智能化探索之路
○ 架构层:统一存储与计算分离的智能化升级
向量化存储引擎
将向量数据作为原生数据类型,与结构化数据共享存储层,支持混合索引(结构化B+树索引与向量HNSW/IVF索引自动协同,优化复合查询),同时对冷热分级进行升级,向量数据根据访问频率自动分层(内存→SSD→对象存储),成本预计可降低50%+。
Serverless向量计算
基于云原生弹性资源池,动态扩缩容向量检索算力,应对突发流量(如电商大促期间的实时推荐需求)。
○ 计算层:AI-Native查询优化器
语义感知的查询重写
自动识别SQL中的语义意图(如WHERE text SIMILAR TO '价格投诉'),将其转换为向量检索+关键词过滤的混合执行计划。
模型推理与向量检索联合优化
对大模型UDF调用和向量计算进行成本预估,动态选择执行位置(CPU/GPU/边缘节点),降低端到端延迟。
○ 生态层:多模态数据湖融合
支持对接外部数据源(如对象存储中的视频、IoT传感器数据流),构建统一的多模态分析能力。
腾讯云大数据始终致力于为各行业客户提供轻快、易用,智能的大数据平台。
END
关注腾讯云大数据╳探索数据的无限可能

⏬点击阅读原文
了解更多产品详情

分享给认识的人吧



















 4145
4145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









