




点击蓝字⬆ 关注我们
本文共计5107 预计阅读时长16分钟
*
本文将分享腾讯云流式湖仓的架构与实践。主要内容包括:
流计算Oceanus介绍
腾讯云流式湖仓架构
腾讯云流式湖仓实践
腾讯云流式湖仓发展规划
一、流计算Oceanus介绍
随着大数据技术的发展,客户对实时处理与分析需求日益增长,实时数据分析已成为驱动业务创新、提升竞争力的关键要素。传统批处理方式存在时效性差、数据孤岛、难以扩展等问题,因此需要实时计算来弥补。

腾讯云流计算基于开源的Apache Flink搭建,作为腾讯云大数据产品中的实时链路,是企业级实时大数据平台,具备一站式开发、5秒无缝衔接、亚秒延迟、低成本、安全稳定等特性。
二、腾讯云流式湖仓架构
接下来进入本次分享的核心部分,详细介绍腾讯云流式湖仓解决方案。
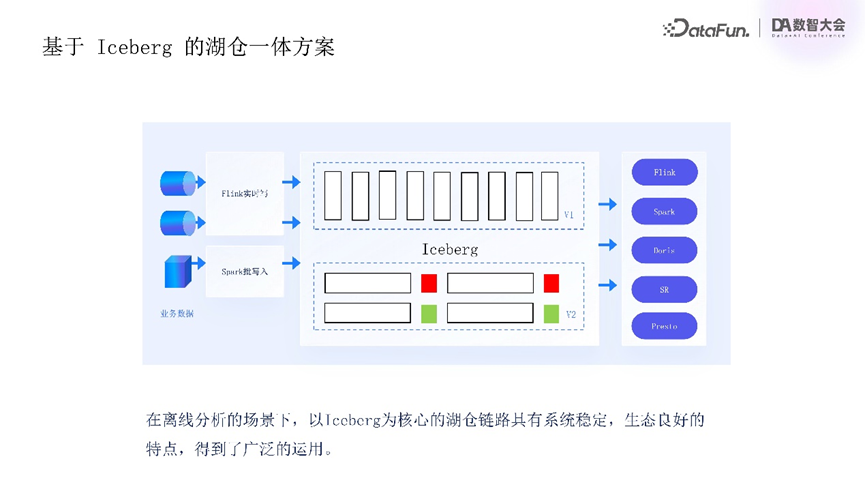
首先来介绍基于Iceberg的湖仓一体化基础方案,该方案以Iceberg为核心,其生态稳定,能提供强大的表管理与数据组织能力,支持大规模数据集高效处理,即便海量数据场景也可稳定运行,且生态集成良好,与主流大数据计算引擎(如Spark、Flink、Presto等)无缝对接,在腾讯云内部与DLC、EMR等大数据产品深度结合。Iceberg湖仓链路可以覆盖从实时流处理到离线批处理的完整数据链路,在腾讯云内部广泛应用于离线分析场景,因此腾讯云流式湖仓基于Iceberg设计。
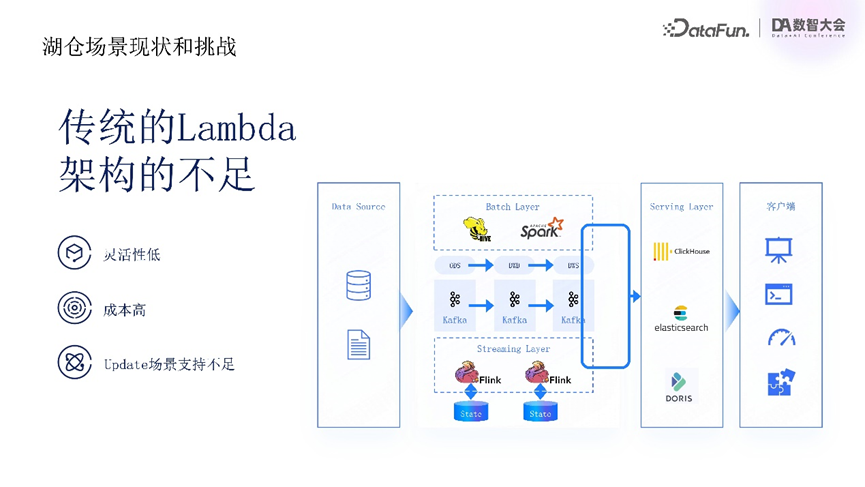
回顾大数据链路发展,除离线链路外,许多客户都有实时链路需求。传统上,实时与离线业务客户常用Lambda架构搭建实时分析链路。在Lambda架构中,离线与实时链路分离,离线链路数据存储于Iceberg等离线存储引擎,后用Spark进行多层数据转换。在时效需求不高时,在数据规模支持与成本方面有优势。但随着实时场景增加,单一Iceberg方式难以满足业务需求,客户常采用Flink加Kafka方式构建实时分层链路,数据最终写入数据仓库或主流数据库(如CK、Doris等)。此链路虽可实现秒级延迟,但存在诸多问题。
其一,灵活性低,Kafka仅作数据管道,无法应用于数据探索、分析场景,且不能保存较长历史数据,限制用户使用灵活性,导致数据处理问题排查困难。
其二,成本高,实时链路单独存在,Kafka与Flink对state维护及存储计算资源需求大,导致成本较高。
其三,对update场景支持不足,Kafka写入非完整change log流时,后续接入Fink作业进行流式处理困难,虽Flink提供upset Kafka解决,但依赖本地状态存储,成本较高。
此外,Lambda架构将离线与实时链路、存储及计算引擎隔离,相同数据需多次重复存储,实时与离线计算逻辑需单独开发,维护、管理及业务变更成本高,因此需要新的架构来统一实时与离线分析链路,降低成本。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2241
2241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









