





作者介绍
作者介绍:jennyerchen(陈再妮),PostgreSQL ACE成员,TDSQL PG开源版负责人,有多年分布式数据库内核研发经验,曾供职于百度数据库团队,加入腾讯后参与了TDSQL PG版异地多活、读写分离、Oracle兼容等多个核心模块的研发,当前主要负责CDW PG的存算分离相关特性的研发工作。
背景简介
CDW PG是腾讯自主研发的新一代分布式数据库,其具备业界领先的数据分析能力,在提供大型数据仓库处理能力的同时还能完整支持事务, 采用无共享的集群架构,适用于PB级海量 OLAP 场景。
OLAP场景列存表的应用比较广泛,而且一般数据量都非常大,会占用很多的磁盘空间。列存高效存储表,因为数据是按列存储的,如果进行压缩的话可以具备很高的压缩比,大大节省磁盘空间。
压缩解压过程
数据压缩解压过程如下图所示:

-
写入时进行压缩。
-
读取时进行解压。
-
压缩分为轻量级压缩和透明压缩2种,并且可叠加使用。数据写入时先经过轻量级压缩进行编码,然后编码结果可再进行透明压缩。数据读取时根据压缩时采用的算法先经过透明解压,然后再经过轻量级解码最后返回给用户。
-
针对压缩表的xlog、用户数据的磁盘存储形态都是压缩的,而内存buffer中需要计算使用的数据是解压过的。
注:整个过程全自主实现,对用户完全透明,用户0感知。
压缩实现
对数据进行压缩能够有效地减少磁盘IO以及数据存储成本,但对数据的压缩和解压操作也会消耗额外的CPU资源、影响数据的访问与存储性能。所以压缩是一个用CPU换取磁盘IO的过程,需要根据业务需求,由用户来指定列存表创建时可以创建压缩表,也可以创建非压缩表(行存暂且不支持指定压缩)。

对比各种透明压缩算法的压缩解压性能和压缩比,zstd是压缩比最高的,lz4是压缩解压效率最好的,因此我们选择zstd和lz4这两种压缩算法分别用于不同的压缩级别:根据用户设定需要高压缩级别的采用zstd,需要快速压缩解压而不追求压缩比的采用lz4。
轻量级压缩算法主要是使用字符编码的方式,常用的有RLE(当数据存在大量连续的相同值时,会把重复的数据存储为一个数据值和计数)、Delta(只存储数据间的差异diff,适用于数据改变很小的场景)、Dict(先会检查数据的重复值,如果某一值出现的次数达到要求则将其加入字典。列中的值将会直接指向字典中与其重复的值)。根据其原理可知:数字类型的用Delta压缩后再对diff值用RLE可以达到很好的压缩比,文本类型的用Dict更适合。
因此如果指定了压缩表,则数据写入时进行压缩,并且内核会根据数据类型自适应选择较优的压缩算法:
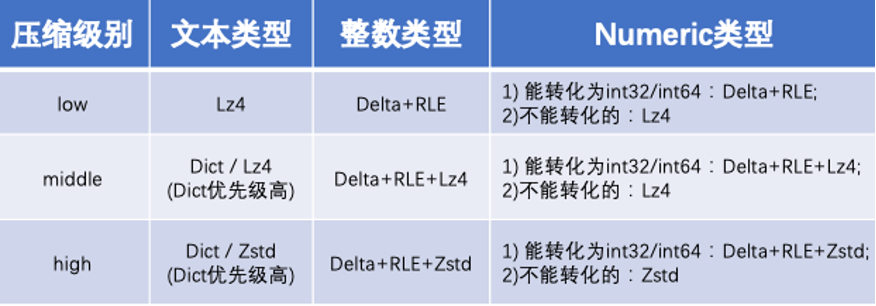
-
文本类型
ow模式只用lz4;
middle模式优先dict压缩,成功直接返回,dict
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 545
545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









