 Pandas索引与抽样
Pandas索引与抽样




一、索引器
1. 表的列索引
- 列索引是最常见的索引形式,一般通过 [] 来实现。通过 [列名] 可以从 DataFrame 中取出相应的列,返回值为 Series, 等价于用 .列名 取出单列,且列名中不包含空格
df.Name.head() # 等价于 df['Name'].head()

请不要把纯浮点以及任何混合类型(字符串、整数、浮点类型等的混合)作为索引,否则可能会在具体的操作时报错或者返回非预期的结果, 最好用[ ]来实现
- 如果要取出多个列,则可以通过 [列名组成的列表] ,其返回值为一个 DataFrame

2. 序列的行索引
(1), 以字符串为索引的 Series
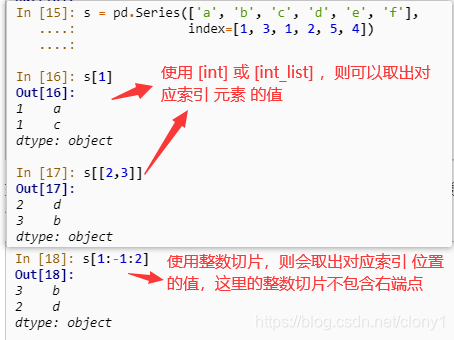
- 如果取出单个索引的对应元素,则可以使用 [item] ,若 Series 只有单个值对应,则返回这个标量值,如果有多个值对应,则返回一个 Series
- 如果取出多个索引的对应元素,则可以使用 [items的列表]
- 如果想要取出某两个索引之间的元素,并且这两个索引是在整个索引中唯一出现,则可以使用切片,同时需要注意这里的切片会包含两个端点
- 如果前后端点的值存在重复,即非唯一值,那么需要经过排序才能使用切片:

(2), 以整数为索引的 Series
- 在使用数据的读入函数时,如果不特别指定所对应的列作为索引,那么会生成从0开始的整数索引作为默认索引。当然,任意一组符合长度要求的整数都可以作为索引。
3. loc索引器
-
对于表而言,有两种索引器,一种是基于
元素的loc索引器,另一种是基于位置的iloc索引器。 -
loc 索引器的一般形式是
loc[*, *],其中第一个*代表行的选择,第二个*代表列的选择,如果省略第二个位置写作loc[*],这个 * 是指行的筛选。其中,*的位置一共有五类合法对象,分别是:单个元素、元素列表、元素切片、布尔列表以及函数,
4. iloc索引器
iloc的使用与loc完全类似,只不过是针对位置进行筛选,在相应的*位置处一共也有五类合法对象,分别是:整数、整数列表、整数切片、布尔列表以及函数,函数的返回值必须是前面的四类合法对象中的一个,其输入同样也为DataFrame本身。
5. query方法
- 在 pandas 中,支持把字符串形式的查询表达式传入
query方法来查询数据,其表达式的执行结果必须返回布尔列表。在进行复杂索引时,由于这种检索方式无需像普通方法一样重复使用DataFrame的名字来引用列名,一般而言会使代码长度在不降低可读性的前提下有所减少。
6. 随机抽样
-
如果把 DataFrame 的每一行看作一个样本,或把每一列看作一个特征,再把整个 DataFrame 看作总体,想要对样本或特征进行随机抽样就可以用 sample 函数。有时在拿到大型数据集后,想要对统计特征进行计算来了解数据的大致分布,但是这很费时间。同时,由于许多统计特征在等概率不放回的简单随机抽样条件下,是总体统计特征的无偏估计,比如样本均值和总体均值,那么就可以先从整张表中抽出一部分来做近似估计。
-
sample 函数中的主要参数为 n, axis, frac, replace, weights ,前三个分别是指抽样数量、抽样的方向(0为行、1为列)和抽样比例(0.3则为从总体中抽出30%的样本)。
-
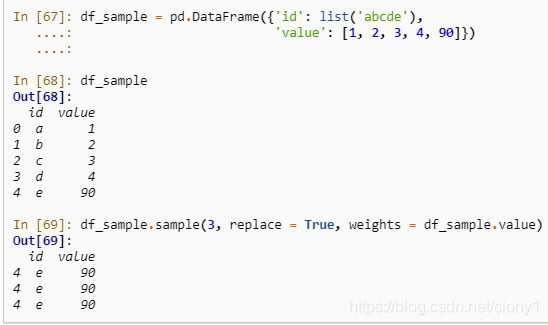
replace 和 weights 分别是指是否放回和每个样本的抽样相对概率,当 replace = True 则表示有放回抽样。例如,对下面构造的 df_sample 以 value 值的相对大小为抽样概率进行有放回抽样,抽样数量为3。

















 1025
1025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









