







学习笔记第二次打卡
文本预处理
读入文本
分词
建立字典,将每个词映射到一个唯一的索引(index)
将文本从词的序列转换为索引的序列,方便输入模型
建立词典
class Vocab(object):
def __init__(self, tokens, min_freq=0, use_special_tokens=False):
counter = count_corpus(tokens) # :
self.token_freqs = list(counter.items())
self.idx_to_token = []
if use_special_tokens:
# padding, begin of sentence, end of sentence, unknown
self.pad, self.bos, self.eos, self.unk = (0, 1, 2, 3)
self.idx_to_token += ['', '', '', '']
else:
self.unk = 0
self.idx_to_token += ['']
self.idx_to_token += [token for token, freq in self.token_freqs
if freq >= min_freq and token not in self.idx_to_token]
self.token_to_idx = dict()
for idx, token in enumerate(self.idx_to_token):
self.token_to_idx[token] = idx
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
def count_corpus(sentences):
tokens = [tk for st in sentences for tk in st]
return collections.Counter(tokens) # 返回一个字典,记录每个词的出现次数
无论use_special_token参数是否为真,都会使用的特殊token是____,作用是用来____。
< unk >,表示未登录词
< pad >, 补齐至句子的长度
< bos >,< eos > 句子开始和结束
语言模型

缺点:
参数空间过大
数据稀疏
建立字符索引
idx_to_char=list(set(corpus_chars))# 去重,得到索引到字符的映射char_to_idx={char:ifori,charinenumerate(idx_to_char)}# 字符到索引的映射vocab_size=len(char_to_idx)print(vocab_size)corpus_indices=[char_to_idx[char]forcharincorpus_chars]# 将每个字符转化为索引,得到一个索引的序列sample=corpus_indices[:20]print(‘chars:’,’’.join([idx_to_char[idx]foridxinsample]))print(‘indices:’,sample)
随机采样
下面的代码每次从数据里随机采样一个小批量。其中批量大小batch_size是每个小批量的样本数,num_steps是每个样本所包含的时间步数。
在随机采样中,每个样本是原始序列上任意截取的一段序列,相邻的两个随机小批量在原始序列上的位置不一定相毗邻。
相邻采样
在相邻采样中,相邻的两个随机小批量在原始序列上的位置相毗邻。
卷积神经网络基础
python二维乘法
填充和步幅
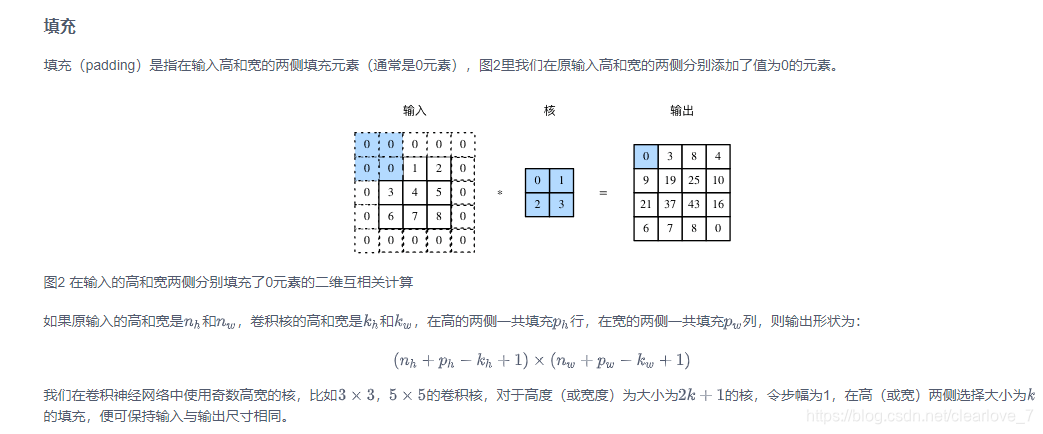

1*1卷积层(这个还是不太懂)
池化
循环神经网络
裁剪梯度



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









