




 本文介绍YARN产生的背景,包括解决MapReduce1.x版本中的问题,如JobTracker单点故障、扩展性和资源分配不合理等问题。同时详细阐述YARN的设计思路、体系结构及工作流程。
本文介绍YARN产生的背景,包括解决MapReduce1.x版本中的问题,如JobTracker单点故障、扩展性和资源分配不合理等问题。同时详细阐述YARN的设计思路、体系结构及工作流程。
YARN产生背景
在hadoop 1.x版本中MapReduce架构如下图所示:
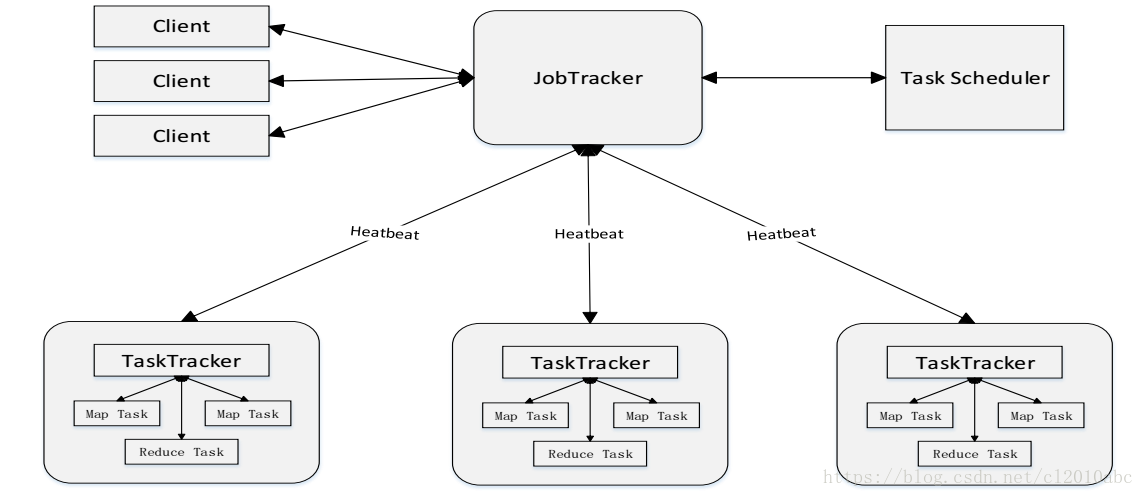
整个集群采用master/slave模式:1个JobTracker和多个TaskTracker。
JobTracker职责:
- 负责整个集群的资源管理:JobTracker通过定期收集TaskTracker节点资源使用情况以确定下一个任务在哪个TaskTracker节点上运行。
- 负责作业调度:定期收集TaskTracker节点job运行情况,对于运行失败的job则会下发到另外的节点上运行。
TaskTracker职责:
- 定期向JobTracker汇报本节点的健康情况,资源使用情况,job运行情况。
- 接受TaskTracker的指令:启动job,杀死job等。
可以看得出原来的 map-reduce 1.x 架构是比较简单明了的,在最初推出的几年,也得到了众多的成功案例,获得业界广泛的支持和肯定,但随着分布式系统集群的规模和其工作负荷的增长,原框架的问题逐渐浮出水面,主要的问题集中如下:
- JobTracker单点故障
- 不易扩展:JobTracker兼具资源调度和作业调度双重职责,在任务较多时内存开销会很大。当节点数达到4000,任务数达到40000时,MapReduce 1.x 将遇到可扩展性瓶颈。
- 资源划分不合理:MapReduce 1.x中资源是以slot为分配的基本单元,并被划分为map slot和reduce slot。一个map slot仅能用于运行一个map任务,同样一个reduce slot仅能运行一个reduce任务。
YARN架构
YARN设计思路
YARN的设计思路:
- 将原JobTracker的功能进行拆分。
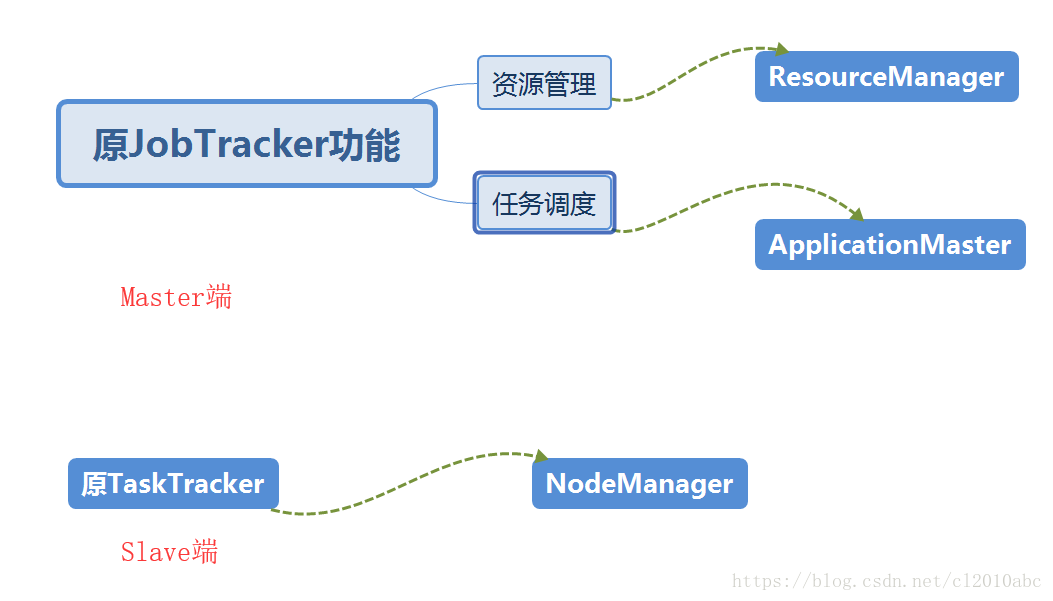
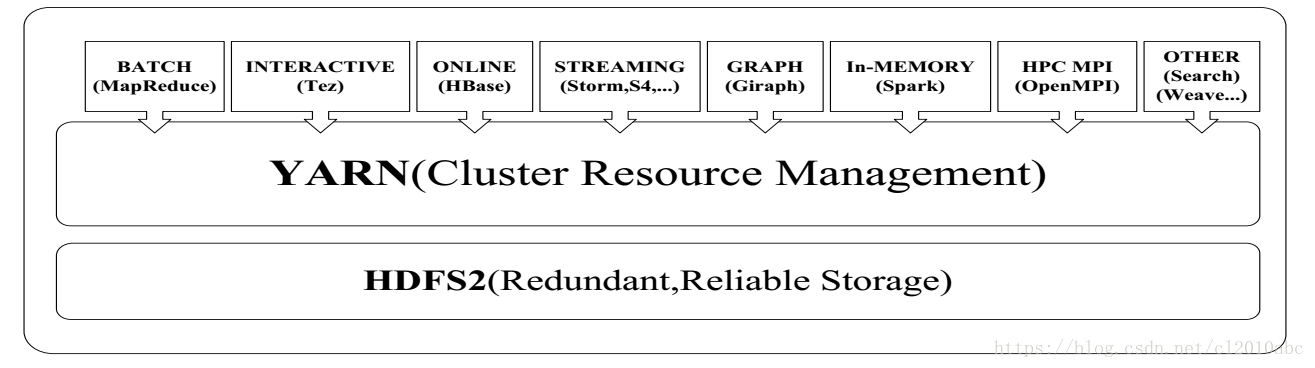
- 一个集群多个框架,即在一个集群上部署一个统一的资源调度框架YARN,在YARN之上可以部署各种计算框架。
YARN体系结构
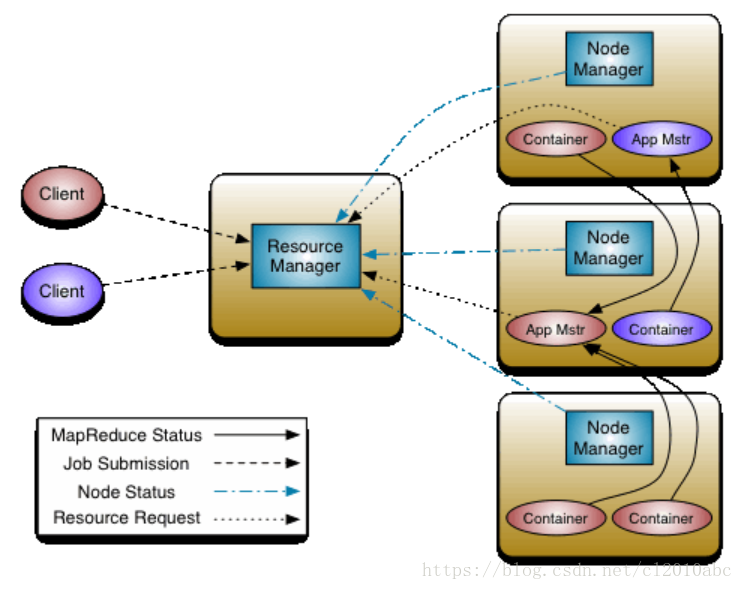
ResourceManager
- 处理客户端请求
- 启动/监控ApplicationMaster
- 监控NodeManager
- 资源分配与调度
ApplicationMaster
- 为应用程序申请资源,并分配给内部任务
- 任务调度,监控与容错
NodeManger
- 单个节点上的资源管理
- 处理来自ResourceManager的命令
- 处理来自ApplicationMaster的命令
YARN工作流程
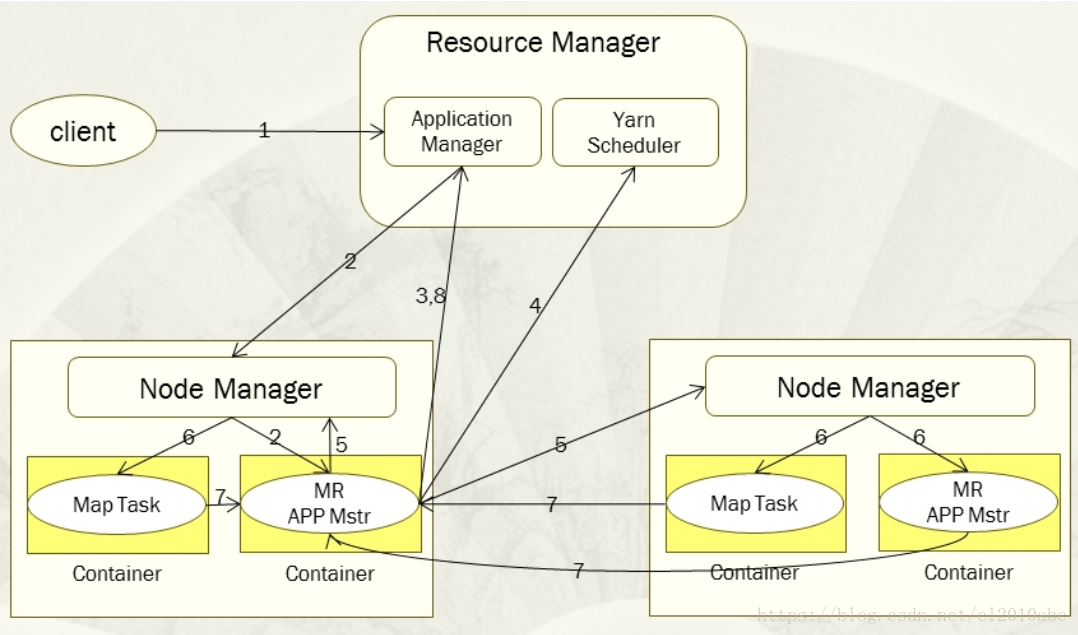
- 用户向Yarn提交应用程序,其中包括用户程序、相关文件、启动ApplicationMaster命令、ApplicationMaster程序等。
- Yarn中的ResourceManager为应用程序分配一个容器,在该容器中启动一个ApplicationMaster。
- ApplicationMaster会首先向ResourceManager注册。
- ApplicationMaster采用轮询的方式向ResourceManager申请资源。
- ResourceManager向ApplicationMaster分配容器资源。
- 在容器中启动任务(运行环境,脚本)。
- 各个任务向其对应的ApplicationMaster汇报自己的运行状态和进度。
- 应用程序运行完毕后,ApplicationMaster与ResourceManager通信,要求注销和关闭自己。
总结
本文介绍了YARN的产生背景以及设计架构,工作流程。

















 1815
1815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









