






 实习报告探讨了如何通过构建支持向量机和深度学习模型预测学术合作中的advisor-advisee关系。通过数据预处理、特征工程,训练集划分,比较了两种方法在合著者关系识别上的性能。
实习报告探讨了如何通过构建支持向量机和深度学习模型预测学术合作中的advisor-advisee关系。通过数据预处理、特征工程,训练集划分,比较了两种方法在合著者关系识别上的性能。
一、实习目的及要求
此次实习的任务中有Advisor-advisee Relationships (AARs)和通过分别计算AAR的概率而取得的共同作者关系。在数据中,用八个4位代码表示作者。
数据从合作双方的学术经历,合作经历的角度提取了特征。例如,如果已知A与B在2008年曾合作发表过论文,并且A在2008年之前的论文比B多;那么在他们的合著关系中,A就越有可能是导师,B就越可能是得到指导的学生。数据中有22个通过互信息相关性排序的有序特征。(具体细节将在补充材料中补充)
已知 AAR 可以用于训练和测试机器学习模型,实验将使用训练的模型来预测常见的合著者关系是否为 AAR。
coauthor_feature_raw.csv包含两个作者的ID和22个有序特征。
coauthor_feature_data.csv是删除作者ID后的数据。
GroundTruth_and_Features.csv包含标签与多个特征。
(1) 数据准备
构建训练集与测试集:将GroundTruth_and_Features.csv的第一列作为标签,第2列到第23列作为排序好的22个特征。训练集与测试集自行划分。
(2) 模型构建
- 构建一个传统机器学习模型(支持向量机或决策树)。(Sklearn实现)
- 构建一个简单的深度学习网络。(Keras实现)
(3)实验验证
将传统机器学习模型与深度学习网络的实验结果进行对比分析。有兴趣的同学可以使用sklearn对几个模型的结果进行评估。
二、实习选题的背景及目标
2.1背景
本次实验侧重于学习基本的机器学习方法并且在特定主题上解决特定的任务。在学术异质网络中寻找advisor-advisee的关系。在本次实验中会学习一些机器学习工具并基于Python和Sklearn[1]构造机器学习模型,使用Keras[2]或Tensorflow[3]来构建深度学习模型,并比较传统机器学习和深度学习方法之间的性能差异。
Scikit-learn是用于Python的自由软件机器学习库。它的特征是具有各种分类、回归和聚类算法、包括支持向量机、随机森林、梯度提升、k均值聚类和DBSCAN、被设计协同与Python数值计算科学库Numpy[3]和Scipy。
Keras是用Python编写的开源神经网络库,能够在Tensorflow、Microsoft Cognitive Toolkit、Theano或PlaidML之上运行。Keras旨在快速实现深度神经网络,专注于用户友好、模块化和可扩展性。
TensorFlow是谷歌公司开发的一个计算框架,类似于NumPy,但是比后者功能强大的多。TensorFlow可以快速开发一些机器学习算法,特别是深度学习算法。TensorFlow的核心如字面意思就是张量流。
2.2目标
(1) 数据准备
构建训练集与测试集:将GroundTruth_and_Features.csv的第一列作为标签,第2列到第23列作为排序好的22个特征。训练集与测试集自行划分。
(2) 模型构建
- 构建一个传统机器学习模型(支持向量机或决策树)。(Sklearn实现)
- 构建一个简单的深度学习网络。(Keras实现)
(3)实验验证
将传统机器学习模型与深度学习网络的实验结果进行对比分析。有兴趣的同学可以使用sklearn对几个模型的结果进行评估。
三、设计方案
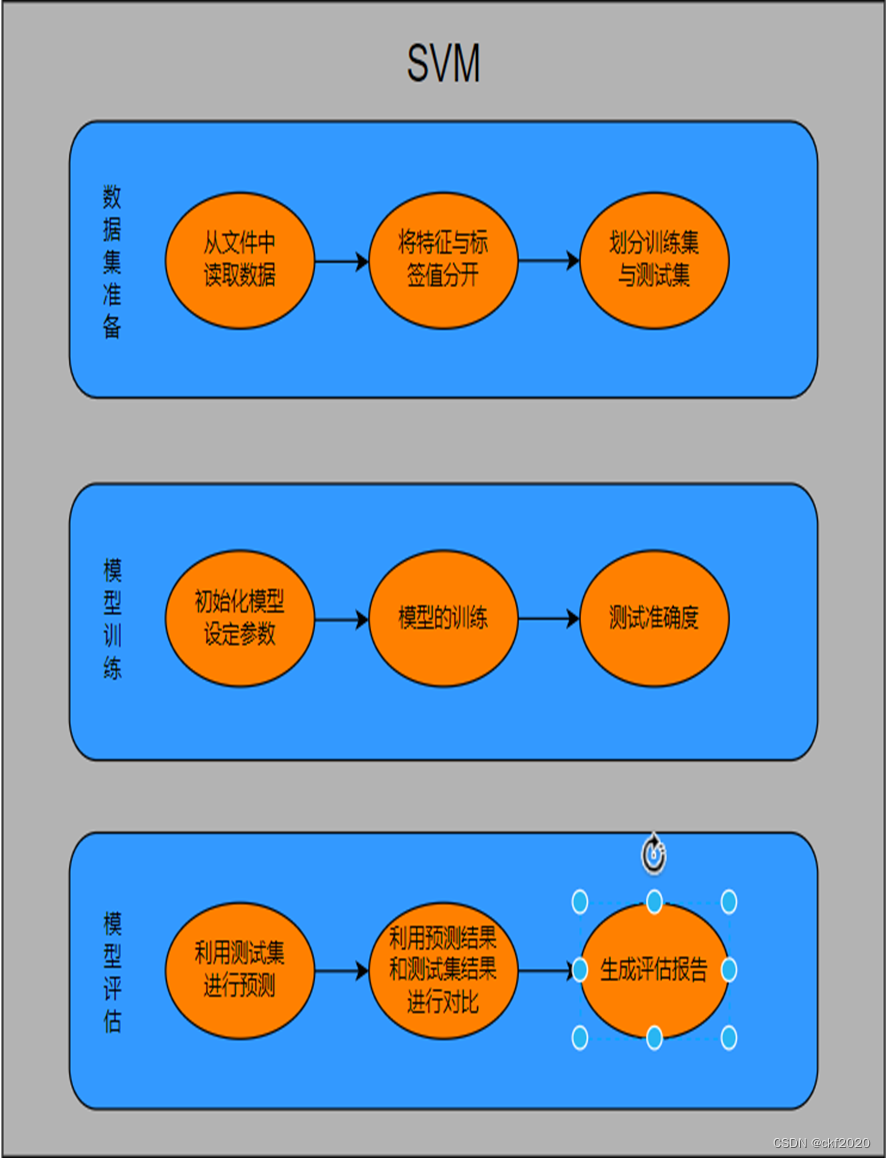
图1 Svm的流程图
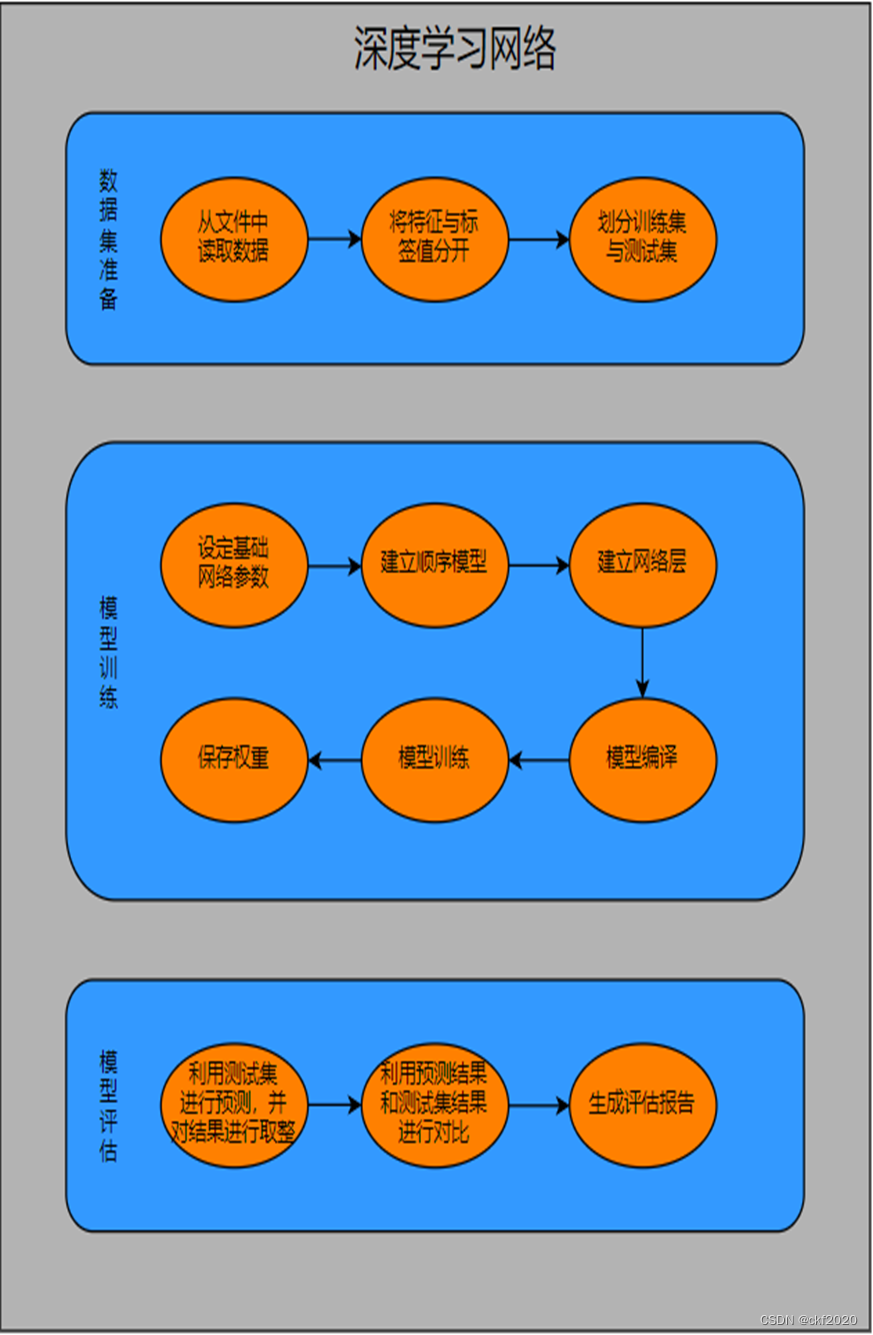
图2 深度学习网络流程图
四、实习环境与主要步骤描述
4.1传统机器学习模型——支持向量机
(1)数据集的准备
这里我们的原始数据是存储在csv文件当中的,其本质是一个txt文件,这里我们利用Numpy中的loadtxt函数来读取数据,读取时我们的数据类型选择为float类型,数据与数据之间以“,”作为分隔符来进行分割,最终将我们的数据存储到一个二维数组当中去,为了将训练的数据和标签值给分离开来,这里我们对数据的行列进行划分,我们将第一列的值分离出来得到全部的标签值,将1-23列划分出来得到我们所需要的22个特征值。
对于训练集和测试集的划分,这里我们sklearn库里面的train_test_split函数来进行划分,输入我们特征与标签值,然后设置我们的划分比,这里采用的是机器学习里面最常用的训练集:测试集=4:1的比例来进行划分的,随机数种子采用的是默认值。
- print("数据集准备")
- datapath="GroundTruth_and_Features.csv"
- data = np.loadtxt(datapath,dtype="float",delimiter=',',skiprows=0,usecols=None,unpack=False)
- x = data[:,1:23] #22个特征值
- y = data[:,0] # 标签
- print("划分测试集与验证集")
- x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.8)#进行训练集和验证集的划分
(2)SVM模型的搭建
这里我们直接使用sklearn库里面的线性svm的模型,在模型的搭建时主要设置容忍程度C与损失函数,这里的容忍程度设置得越小,代表我们容忍错误能力越强,返回能力越强,这里我设置的C为1,损失函数采用的是hinge,random_state在随机数据混洗时使用的伪随机数生成器的种子,我们设置的默认值为42,这里我们利用了流水线里面使用scaler来对特征进行缩放敏感。
- print("模型初始化")
- svm_clf = Pipeline([
- ("scaler", StandardScaler()), # SVM 对特征缩放敏感
- ("linear_svc", LinearSVC(C=1, loss="hinge", random_state=42)), # 这个损失函数就是 max(0, 1-x)
- ]) # C 越小模型越容忍错误,返回能力越强
- svm_clf=LinearSVC(dual=False)
(3)SVM模型的训练
利用我们划分出来的测试集与训练集进行训练,并查看其在两个集中的准确度。
- svm_clf.fit(x, y)
- print("训练集精确度:",svm_clf.score(x_train, y_train))
- print("测试集精确度:",svm_clf.score(x_test, y_test))
(4)SVM模型的评估
利用我们训练出的模型对测试集进行预测,将预测结果与测试集的标签值进行比对,这里我们利用sklearn里面metrics库中的classification_report来生成评估的报告,这里的的测试报告当中,各项的具体信息如下:
y_true 为样本真实标签,y_pred 为样本预测标签;
support:当前行的类别在测试数据中的样本总量,如上表就是,在class 0 类别在测试集中总数量为1;
precision:精度=正确预测的个数(TP)/被预测正确的个数(TP+FP);人话也就是模型预测的结果中有多少是预测正确的
recall:召回率=正确预测的个数(TP)/预测个数(TP+FN);人话也就是某个类别测试集中的总量,有多少样本预测正确了;
f1-score:F1 = 2*精度*召回率/(精度+召回率)
micro avg:计算所有数据下的指标值,假设全部数据 5 个样本中有 3 个预测正确,所以 micro avg 为 3/5=0.6
macro avg:每个类别评估指标未加权的平均值,比如准确率的 macro avg,(0.50+0.00+1.00)/3=0.5
weighted avg:加权平均,就是测试集中样本量大的,我认为它更重要,给他设置的权重大点;比如第一个值的计算方法,(0.50*1 + 0.0*1 + 1.0*3)/5 = 0.70
- y_hat=svm_clf.predict(x_test)
- classreport=metrics.classification_report(y_test,y_hat)
- print(classreport)
4.2 深度学习网络
(1)数据集的准备
数据集的准备与机器学习的模型相一致,就不赘述了。
(2)深度学习网络模型的搭建
这里我们是借助keras库来进行模型的搭建的,在模型的搭建时主要设置网络的层数,这里我们建立的是四层的网络,输入层,隐藏层1,隐藏层2,输出层,对于我们建立的网络,输入层和两个隐藏层,采用的是Dense层,就是我们所说的就是全连接层。输入层我们直接是输入我们的22个对应的特征;隐藏层的神经元个数为15个,激活函数采用的是relu函数,input_shape为22;隐藏层2对应的神经元数目为8,激活函数采用的是relu函数;输出层的神经元为1个,因为最后我们只需要分类的类别,最后的激活函数采用的是sigmoid函数。
- #建立神经网络
- model = Sequential()#先建立一个顺序模型
- #向顺序模型里加入第一个隐藏层,第一层一定要有一个输入数据的大小,需要有input_shape参数
- model.add(Dense(n_hidden_1, activation='relu', input_dim=n_input)) #这个input_dim和input_shape一样,就是少了括号和逗号
- model.add(Dense(n_hidden_2, activation='relu'))
- model.add(Dense(n_classes, activation='sigmoid'))
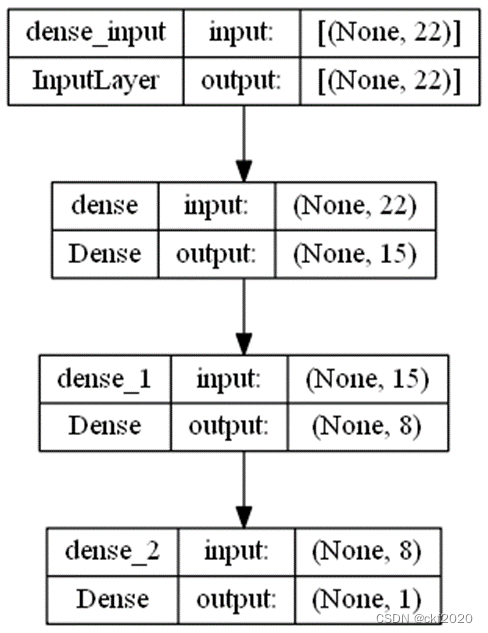
图3 深度学习网络结构图
(3)深度学习网络模型的编译
我们在模型建立完成之后,我们首先需要对模型进行编译,编译时我们需要指定编译时的优化器,这里我们采用的是SGD优化器,随机梯度下降优化器,损失函数采用均方误差回归损失(mean_squared_error),选用评估标准的是模型的准确度。
- model.compile(optimizer = SGD(), loss = 'mean_squared_error',metrics=['accuracy'])
(4)深度学习网络模型的训练
这里我们利用训练集与测试集对模型进行训练,训练时我们可以指定循环训练的次数,这里我们设置epochs为20,以及每次循环中送入的数据的大小,设置得越大,在不超显存得情况下训练越快,这里设置的batch_size为128,validation_data设置为我们的测试集。
- model.fit(x_train,y_train,epochs=training_epochs,validation_data=(x_test, y_test),batch_size=128)
- model.save_weights("best_weights")
(5)深度学习网络模型的评估
利用我们训练出的模型对测试集进行预测,将预测结果与测试集的标签值进行比对,利用sklearn里面metrics库中的classification_report来生成评估的报告,这里会进行报错,这里我们会由于我们利用模型进行预测时得到的是小数,和我们原始的标签值不一样,就会导致两种数据不一致而无法进行效果的评估,所以我们首先需要对预测数据进行转化,将其转化为int类型的数据。
- y_predict=model.predict(x_test)
- y_predict=np.argmax(y_predict, axis=1)
- report=classification_report(y_test,y_predict)
- print(report)
五、实习的结果与讨论
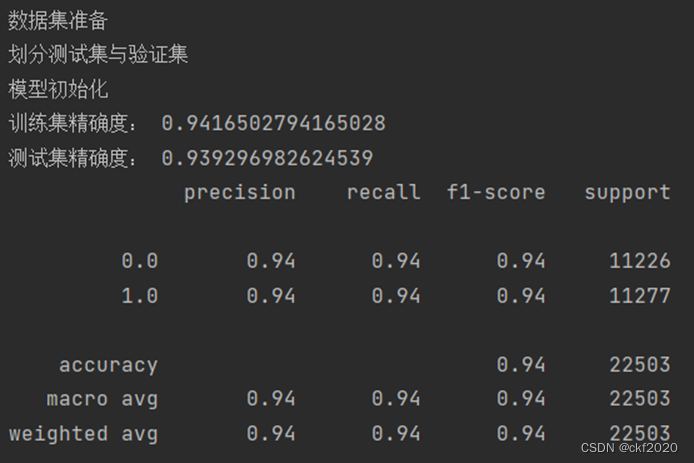
图4 SVM模型结果
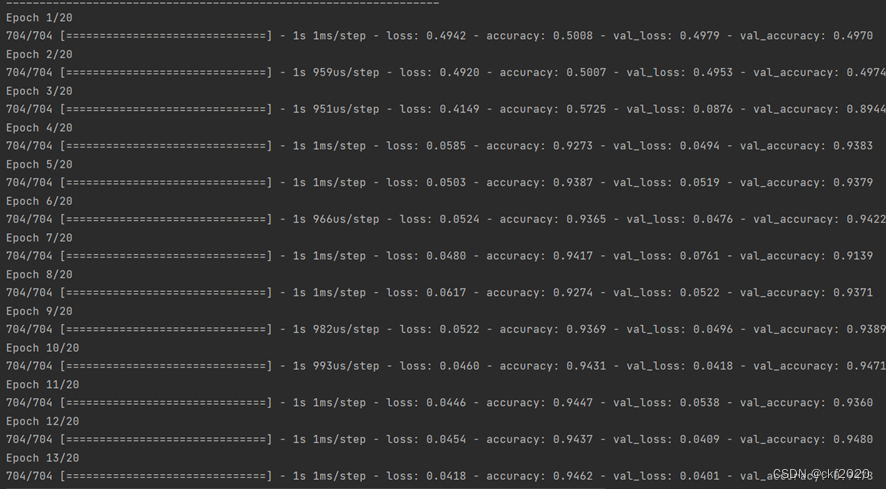
图5 深度学习网络训练
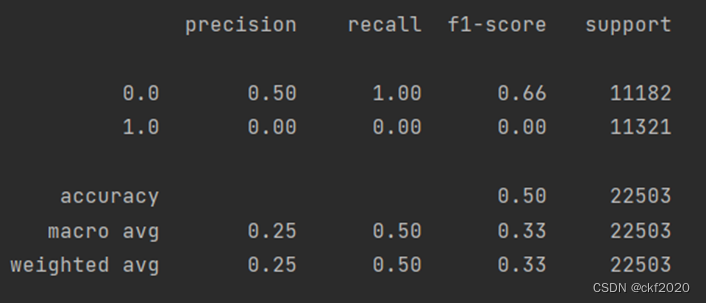
图6 深度学习网络测试报告
这里从测试得结果可以看出,两种方法在进行训练的过程当中,精确度都是保证在90%以上,可以看出两个模型的效果都是比较好的,但是我们通过classification_report所得到的精确度以及召回率来查看,利用SVM来进行预测的效果是较好的,建立的深度学习网络的效果是比较差的,这里可能是由于我们利用训练出来的模型所预测得到的是小数,不是对应的整数,由于我们进行了转化,所以和实际的标签有所误差,所以导致准确度和召回率的效果是比较差。
六、实习总结
通过本次的学习,我们通过传统的机器学习模型和kreas建立简单的深度学习网络来对我们的数据来进行训练,并对其结果进行相应的评估,查看我们的模型的准确度,学会了利用了classification_report来对我们训练的模型进行测试,查看其精度和召回率来对我们的模型进行评估,加深了我们对机器学习和深度学习的认知和了解。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









