




MapReduce介绍
MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题。
MapReduce是分布式运行的,由两个阶段组成,分别是:Map和Reduce。
- Map阶段:是一个独立的程序,有很多个节点同时运行,每个节点处理一部分数据。
- Reduce阶段:是一个独立的程序,有很多个节点同时运行,每个节点处理一部分数据。
MapReduce框架都有默认实现,用户只需要覆盖map()和reduce()两个函数,即可实现分布式计算,map()和reduce()函数的形参和返回值都是<key,value>形式。
MapReduce原理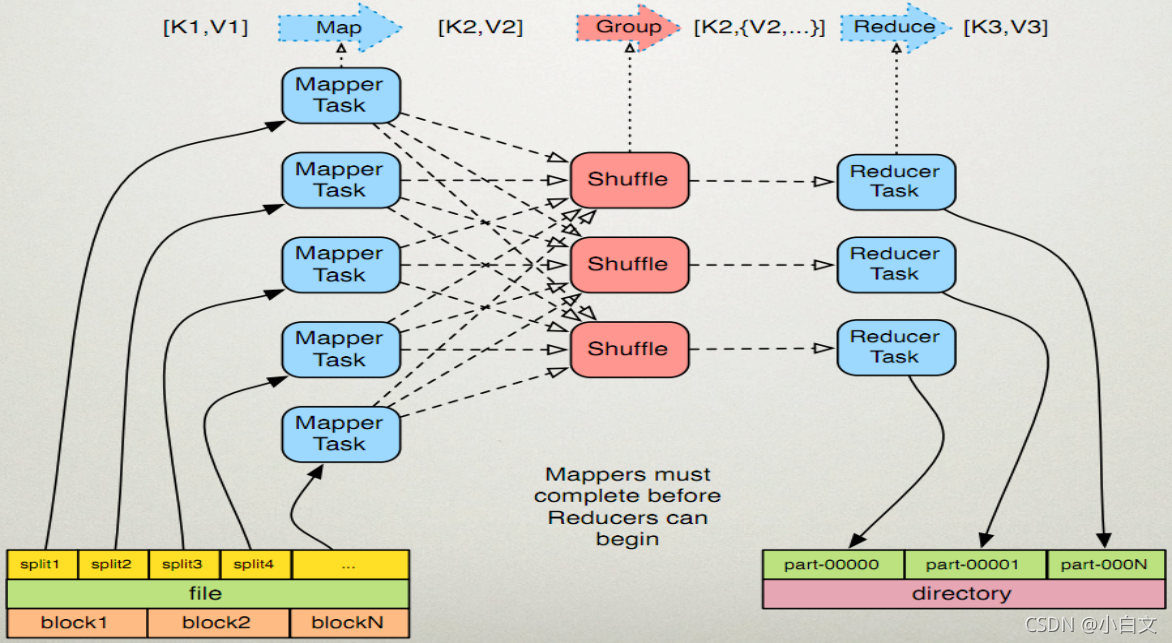
- 首先,Map的输入,从HDFS上读取文件,拿到文件后,对文件进行按行切片,一个切片默认128M。一个切片会产生一个Map任务(有几个切片就有几个Map任务,一个文件至少会产生一个Map任务), 切片完成之后,map将切好的文件读进来,通过TextInputFormat类将文件的每一行格式化成<K1,V1>形式(K1是每一行的偏移量,V1是这一行的数据),经过覆盖map()最终形成新的<K2,V2>输出。
- 其次,经过shuffle过程,将Map的输出<K2,V2>进行分组,形成[K2,{V2…}]形式传到Reduce。
- 最后,将多个Map的任务的输出作为Reduce的输入,按照不同的分区,通过网络IO复制到不同的Reduce节点上,进行合并、排序,经过覆盖reduce()最终形成新的<K3,V3>格式输出写到hdfs中。每个Reduce任务会生成一个分区文件。
Shuffle原理
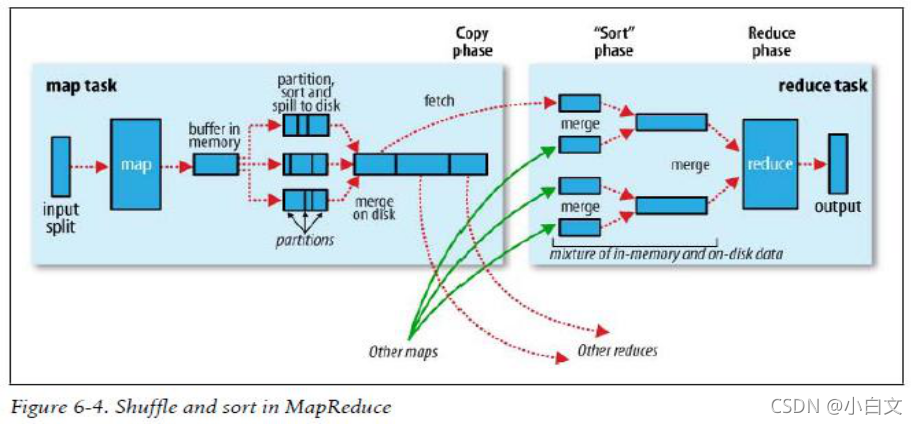
首先,从HDFS上读取文件,拿到文件后,对文件进行按行切片。一个切片会产生一个Map任务,Map任务结束后,会产生<K2,V2>的输出,<K2,V2>的输出先写到环形缓冲区中(环形缓冲去默认大小100M)一旦达到阀值80%(io.sort.spil l.percent)时,将内容锁定,启动另一个线程把内容溢写到(spilt)磁盘的指定目录(mapred.local.dir)下的一个新建文件中。写磁盘前,要进行分区和排序,每个Map任务可能会产生多个文件,最后Reduce任务会从Map任务拉取数据,为了减少网络IO以及磁盘IO读写次数,会将这些小文件合并成大文件,在进行合并操作时,会对每个分区进行排序(这里用到的排序算法是归并排序)map任务在产生分区文件的时候用到的分区原理是hash partition,会根据Map端输出的key不同计算key的哈希值对Reduce数量进行取余(Reduce数量是提前设定好的,有几个Reduce任务就有几个分区),相同的key会进入到同一个Reduce中,同一个Reduce中有不同的key。(根据每个key的哈希值对reduce数量进行取模),每个Map任务最终会生成一个大文件,这个大文件是经过分区和排序的,然后通过网络IO将每个相同的分区拉到同一个Reduce中,最后交给Reduce进行处理,Reduce最终处理完之后将结果写到磁盘。

















 587
587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









