







 本文深入探讨了Netty的内存池架构,包括PooledByteBufAllocator的创建和Arena的组织。每个Arena维护一组根据使用率划分的双向链表,用于内存分配。当请求的内存无法在threadCache或subPage中找到合适规格时,会通过Chunk(16MB)进行分配,采用满二叉树结构管理。内存分配过程中,通过深度优先搜索找到合适的Chunk节点并占用,更新树中节点的可用空间。
本文深入探讨了Netty的内存池架构,包括PooledByteBufAllocator的创建和Arena的组织。每个Arena维护一组根据使用率划分的双向链表,用于内存分配。当请求的内存无法在threadCache或subPage中找到合适规格时,会通过Chunk(16MB)进行分配,采用满二叉树结构管理。内存分配过程中,通过深度优先搜索找到合适的Chunk节点并占用,更新树中节点的可用空间。
一、整体内存池架构设计
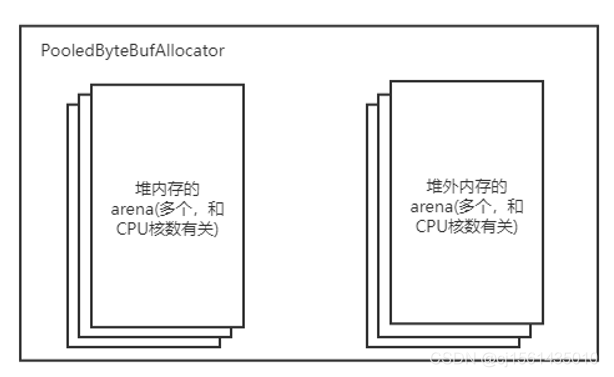
顶层使用allocator分配内存,类似门面模式,将内存分配真正交给对应的arena。
二、PooledByteBufAllocator、Arena的创建
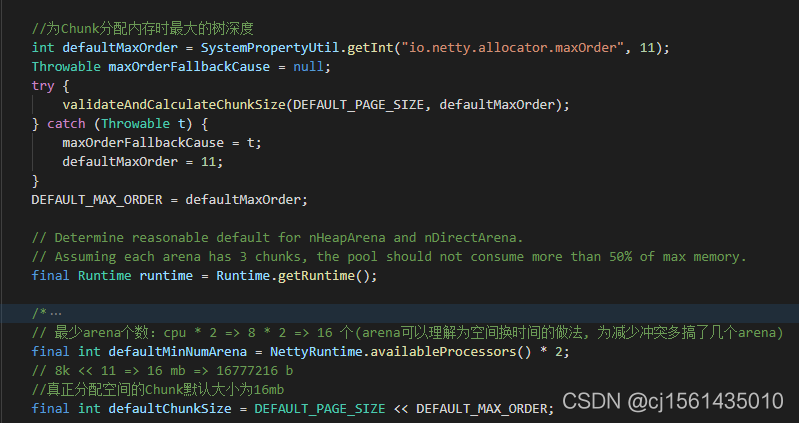
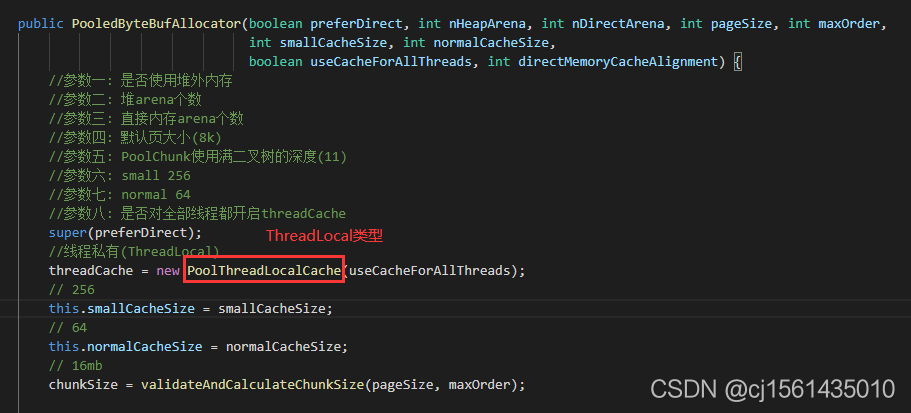
PooledByteBufAllocator构造的时候根据CPU核数创建了多个arena数组。

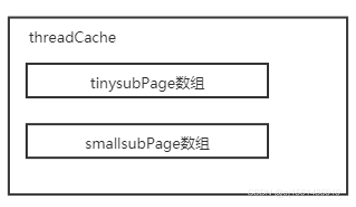
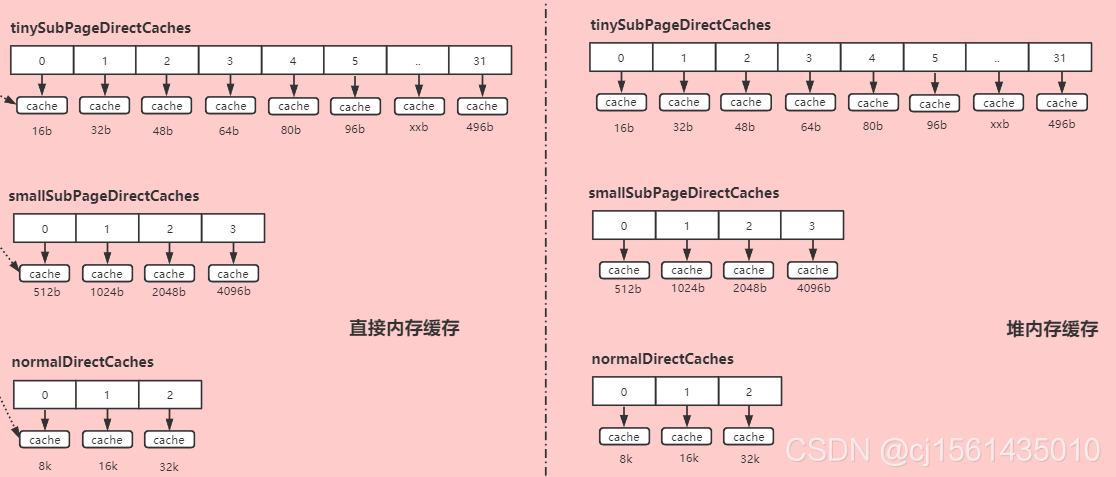
线程本地也存放了一个threadCache,threadLocalMap中保存的key是threadLocal对象,value是PoolThreadCache。
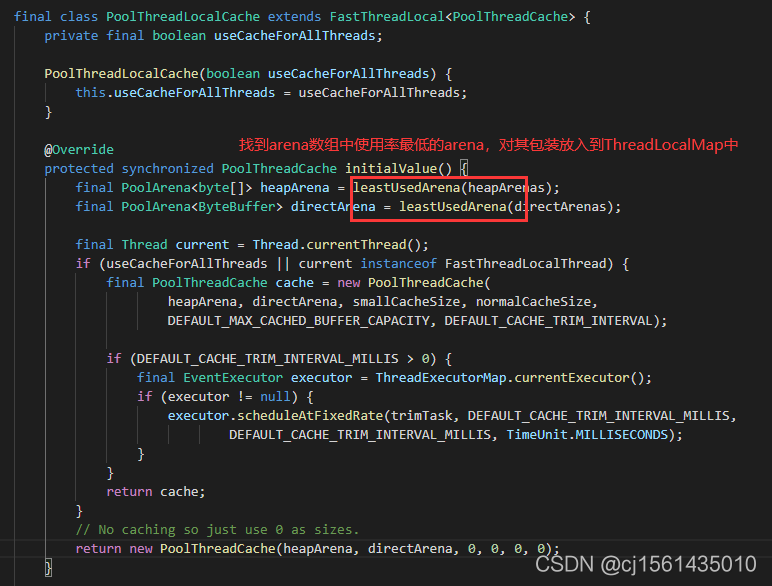
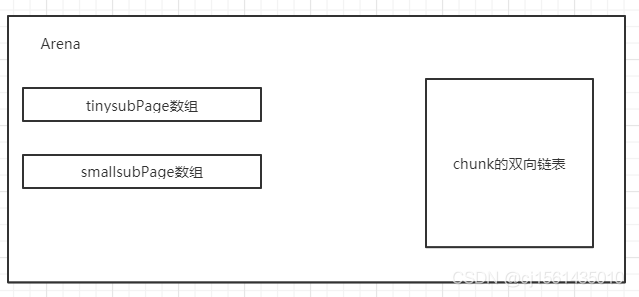
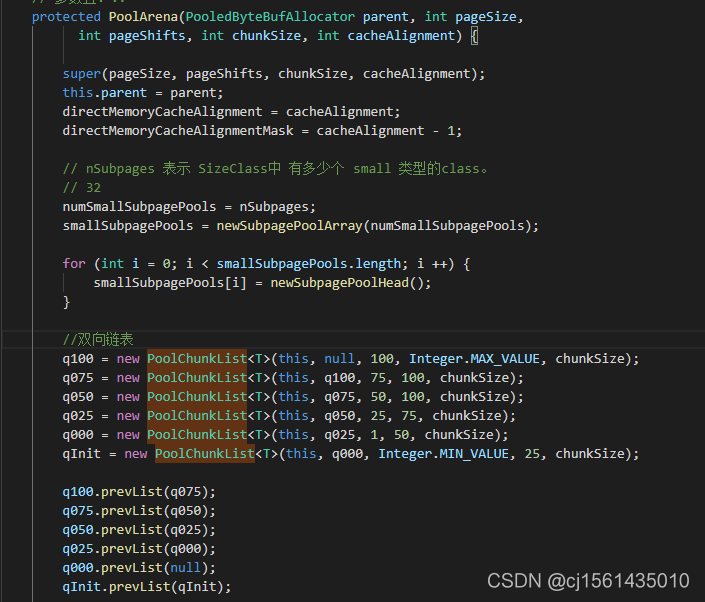
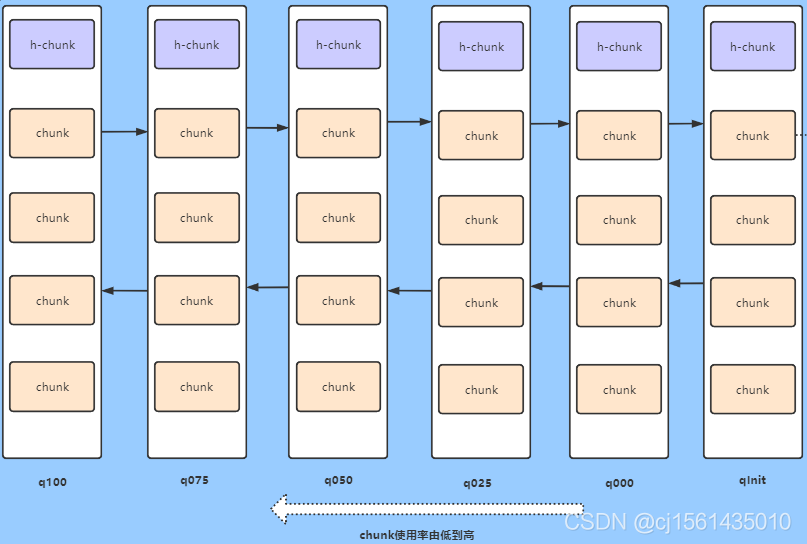
每个Arena里面创建了一组双向链表,根据使用率的不同保存不同的chunk信息。
三、内存分配
allocator调用分配内存的方法: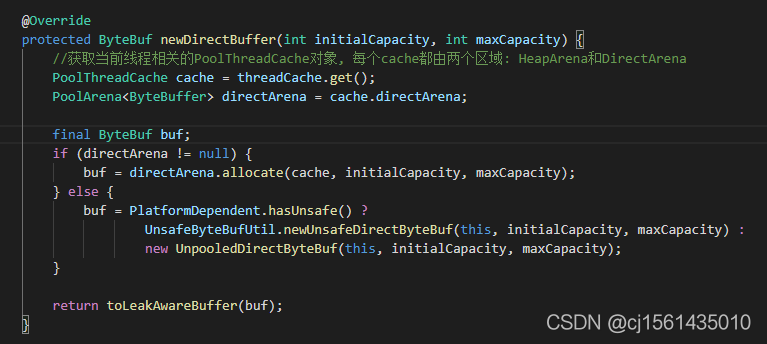
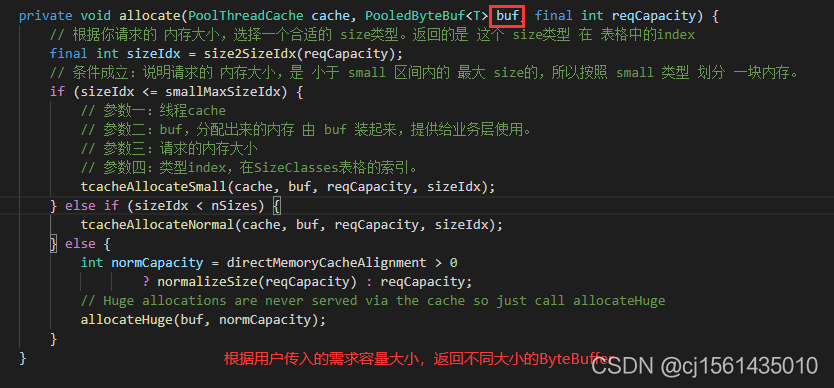
如果请求的容量在arena的subPage和threadCache中都没有对应规格(如果有,先哈希定位到对应的桶,再对头结点加锁),需要到arena中的双向链表即Chunk那里分配内存。
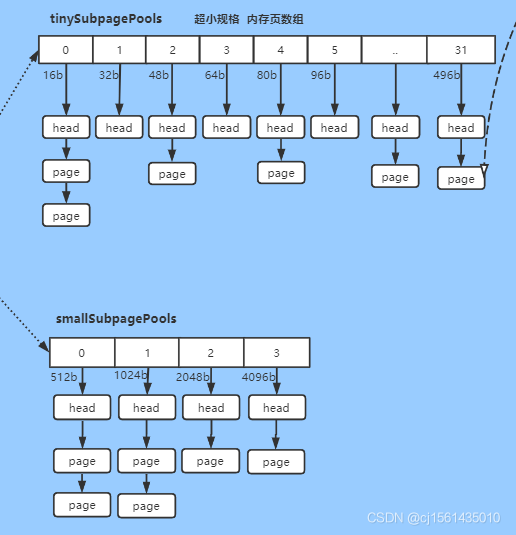
subPage的规格如下图,桶节点上就是对应subPage能分配的大小。
subPage类关键代码如下:
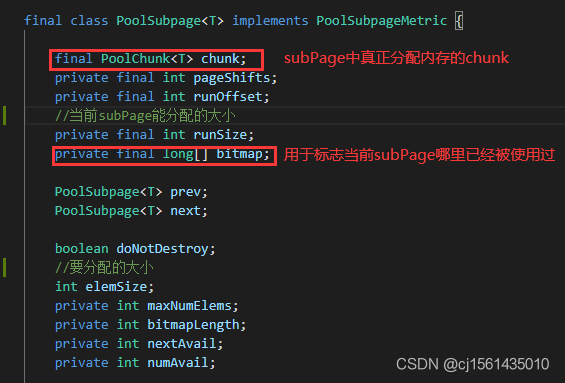
bitmap在构造函数执行的时候就初始化长度为当前subPage的值除以64再加上一些其他信息长度。
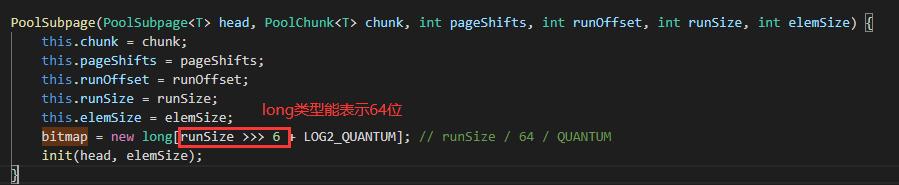
bitmap管理subPage页的使用也很好理解,如果当前subPage页大小为4K,我们需要的空间是1024b,那计算出需要的页数是2K,如果对应页被占了,将bitmap上对应的bit位置为1即可。
如果arena中的threadCahe和subPage都无法分配成功,需要使用Chunk(16mb)分配内存,Netty中使用满二叉树进行维护的。满二叉树的叶子节点有2048个,一个节点拥有8k的空间。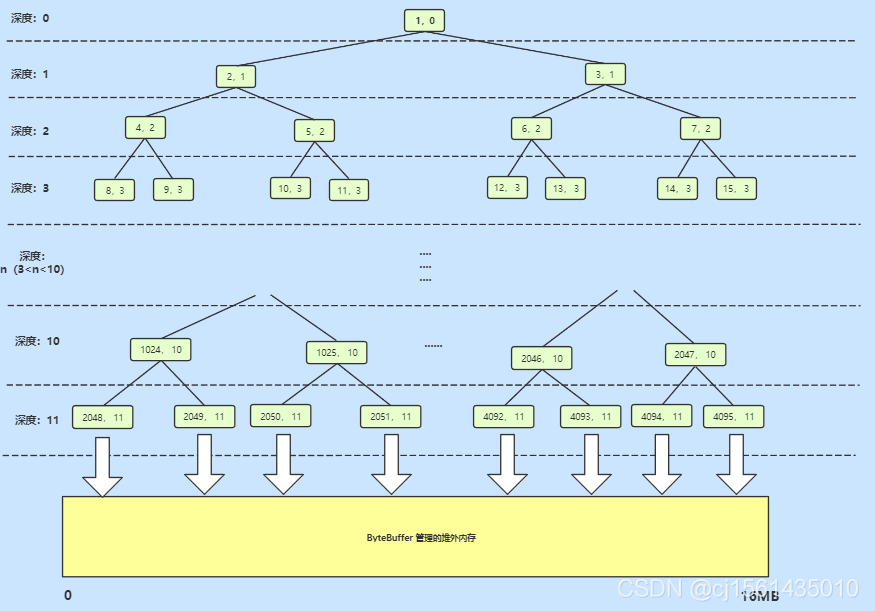
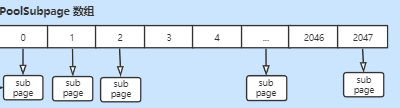
其中PoolChunk中也有一个subPage数组对整个Chunk进行维护。
大致思想就是从根结点出发,深度优先搜索,知道找到合适的节点,将其占用,更新其父节点可以使用的内存空间。比如:当需要8K空间时,找到并占用16K节点的子节点,将16K节点可用空间从16K改为8K。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









