




 本文详细介绍EfficientDet,一种高效能目标检测模型,通过BiFPN和复合缩放方法,实现在不同资源约束下的优秀性能。EfficientDet-D7在COCO数据集上达到51.0mAP,相比前代模型参数量减少4倍,FLOPs减少9.3倍,精度更高。
本文详细介绍EfficientDet,一种高效能目标检测模型,通过BiFPN和复合缩放方法,实现在不同资源约束下的优秀性能。EfficientDet-D7在COCO数据集上达到51.0mAP,相比前代模型参数量减少4倍,FLOPs减少9.3倍,精度更高。
EfficientDet: Scalable and Efficient Object Detection
论文:https://arxiv.org/abs/1911.09070
代码(非官方):https://github.com/toandaominh1997/EfficientDet.Pytorch#datasets
专有名词
Object Detection:目标检测
parameters:一个模型所要学习的权重(W, b),或者说是定义这个模型的所需要的变量。
FLOPs:全称是floating point operations per second,意指每秒浮点运算次数,即用来衡量硬件的计算性能。小s后缀是复数的缩写,可以看做FLOPs在时间上的积分,区别类似速度和时间。
Abstract:
Model efficiency has become increasingly important in computer vision. In this paper, we systematically study various neural network architecture design choices for object detection and propose several key optimizations to improve efficiency. First, we propose a weighted bi-directional feature pyramid network (BiFPN), which allows easy and fast multi-scale feature fusion; Second, we propose a compound scaling method that uniformly scales the resolution, depth, and width for all backbone, feature network, and box/class prediction networks at the same time. Based on these optimizations, we have developed a new family of object detectors, called EfficientDet, which consistently achieve an order-of-magnitude better efficiency than prior art across a wide spectrum of resource constraints. In particular, without bells and whistles, our EfficientDet-D7 achieves stateof-the-art 51.0 mAP on COCO dataset with 52M parameters and 326B FLOPS1, being 4x smaller and using 9.3x fewer FLOPS yet still more accurate (+0.3% mAP) than the best previous detector.
翻译:模型的效率在计算机视觉中变得更加重要。本文系统介绍目标检测的神经网络结构设计选择以及提出改善模型效率的关键优化方法。首先,我们提出易操作且速度快的多尺度特征融合方法(BiFPN,bi-directional feature pyramid network)。然后,我们提出复合缩放方法,可以同时统一缩放所有的基础网络结构(backbone)、特征网络和box/class预测网络的分辨率、深度和输入尺寸。基于这些优化点,我们开发了新系列的目标检测器,称为EfficientDet,能够在跨越大量的资源限制的条件下,在效率上比现有技术提升一个数量级。尤其,没有华丽的点缀下,EfficientDet-D7在COCO数据集下达到51.0 mAP、52M parameters和326B FLOPS,实现了比现在最好预测器参数量小4倍,FLOPs小9.3倍,精度跟高(+0.3%mAP).
贡献:
提出BiFPN子网络结构,双向的多尺度特征融合网络。
提出一种扩展网络的方法,就是扩展backbone,BiFPN,box net 和class net,具体包括网络层数,输入尺寸,深度。
由上面的1,2点,结合得到了EfficientDet一系列网络。
精度
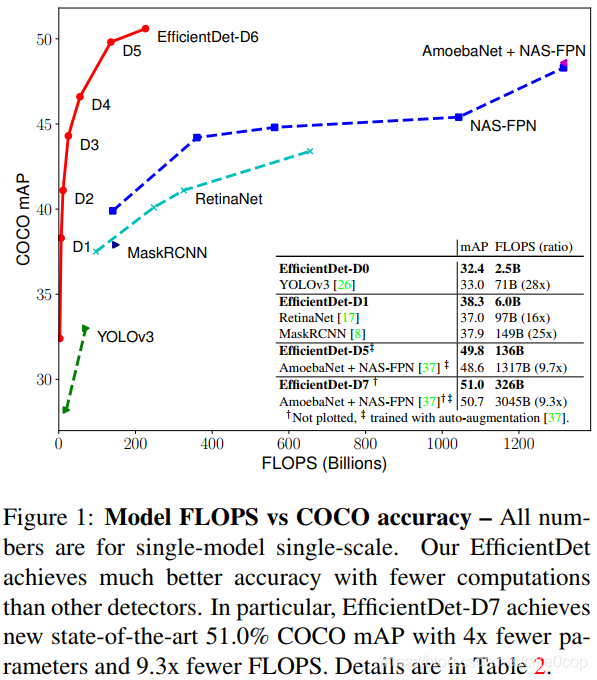
特征网络
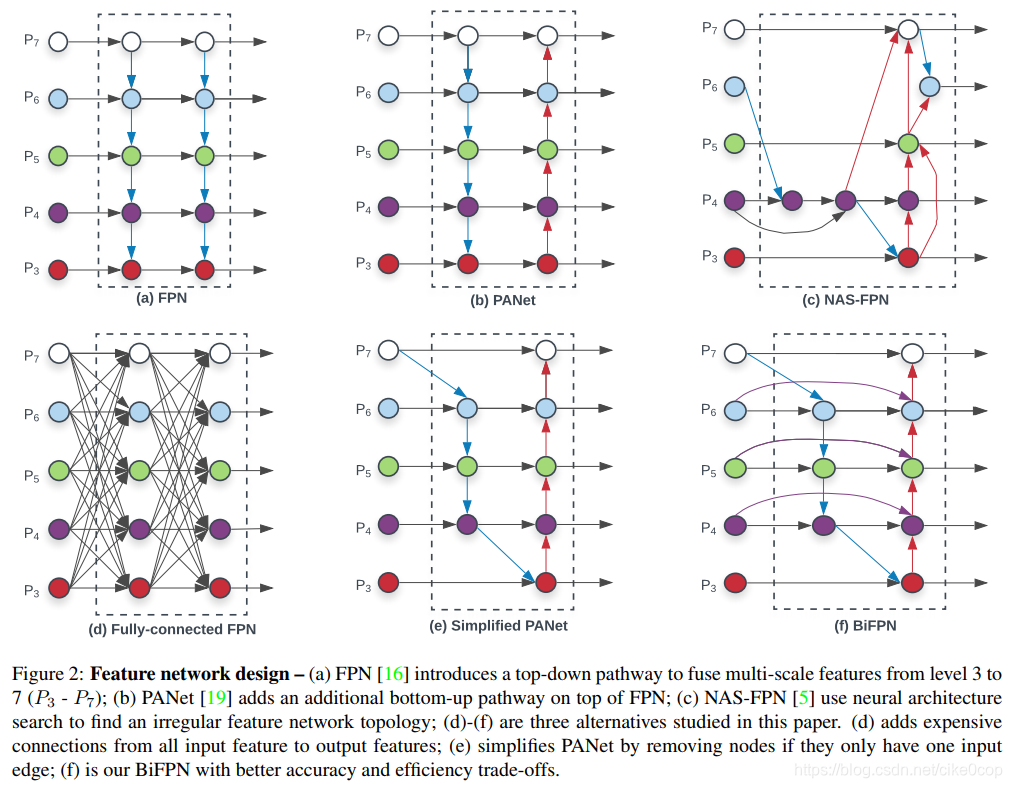
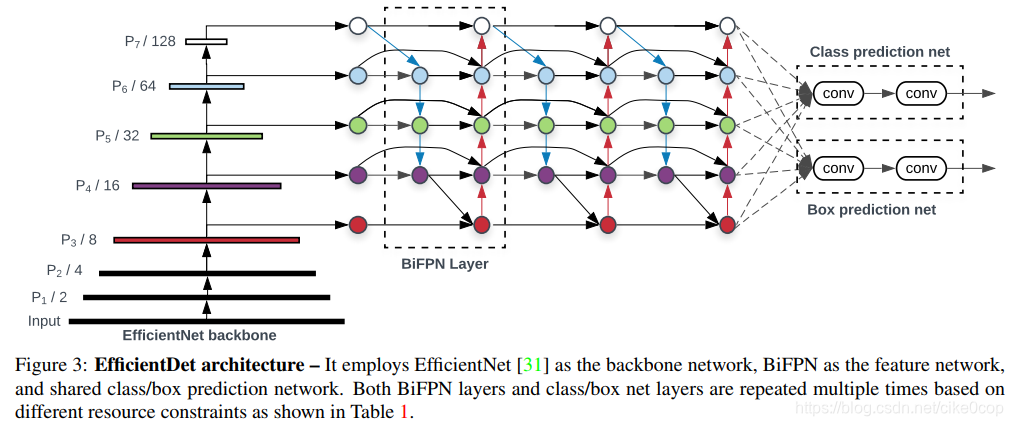
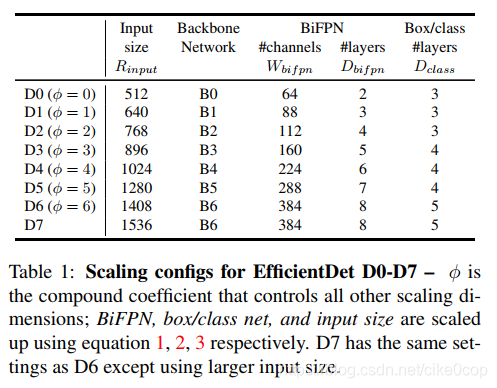
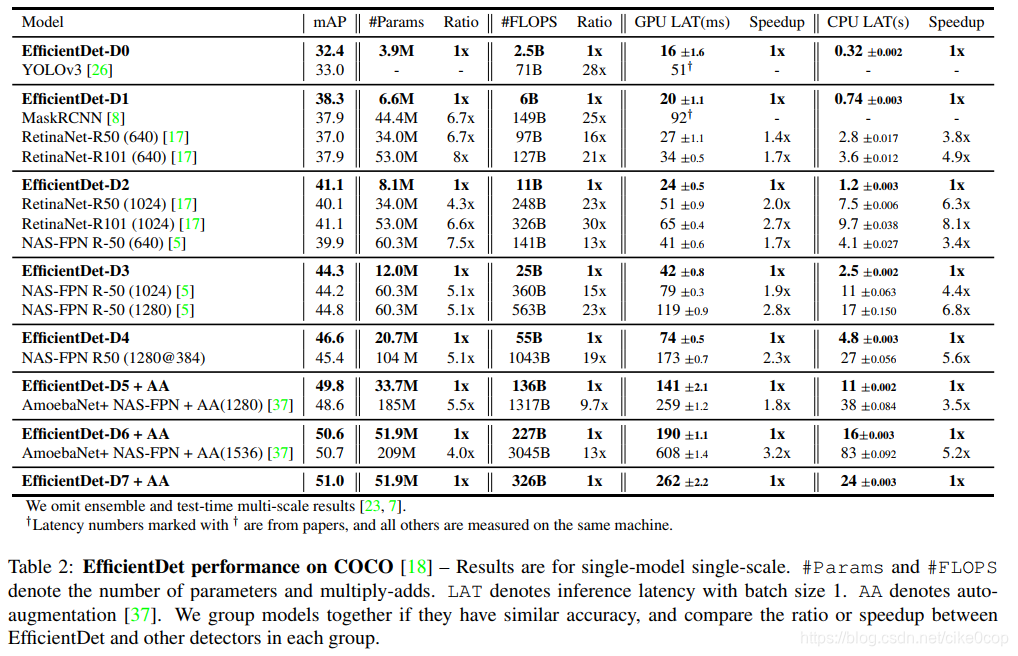

https://wxt.sinaimg.cn/thumb300/8fd1643cgy1gby1ecjzm0j20gl0iwjtt.jpg?tags=%5B%5D

参考博客:
https://blog.youkuaiyun.com/mrjkzhangma/article/details/103280044
https://blog.youkuaiyun.com/weixin_38632246/article/details/103400788


















 584
584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











