



基于贝叶斯主题模型的移动边缘计算中分组入侵检测
曹雪菲,1傅玉龙,1和陈博2
1西安电子科技大学网络工程学院,中国西安太白南路2号710071
2西安电子科技大学雷达信号处理国家重点实验室,中国西安太白南路2号710071
通讯作者为曹雪菲;xfcao@xidian.edu.cn
2020年5月6日收到;2020年6月6日修订;2020年7月7日接受;2020年8月25日发表
学术编辑:徐小龙
版权所有© 2020 徐曹二飞等人。这是一篇根据知识共享署名许可协议发布的开放获取文章,允许不受限制地使用、分发和复制,前提是必须正确引用原作品。
1. 引言
移动边缘计算(MEC)已成为5G通信的主要特征[1]。在MEC的发展过程中,研究人员一直关注其安全问题。MEC中的安全问题包括应用层安全、网络层安全、数据安全和节点安全。入侵检测系统(IDS)保护MEC的网络层安全,已成为其重要组成部分[2]。通常有两种入侵检测方法,即基于签名的方法和基于异常的方法。
基于签名的方法预先定义入侵模式,并将网络流量与这些模式进行匹配以产生检测警报。虽然该方法的误报率较低,但在检测超出预定义模式的新类型攻击方面效果不尽如人意。基于异常的方法为网络流量建立正常行为模式,如果该模式足够准确且全面,则任何偏离该模式的行为都将被视为入侵。基于异常的方法能够检测“零日暴露”攻击,且无需事先了解攻击的知识。这使得基于异常的方法优于基于签名的方法。鉴于多接入边缘计算中存在大量数据和服务的多样性,基于异常的方法为多接入边缘计算[3–5]提供了一个有吸引力的选择。基于异常检测的主要挑战在于如何利用正常的网络流量建立准确且高效的行为模式。
实现基于异常的入侵检测系统(IDS)有两种方法,即基于主机的方法和基于网络的方法[6]。在基于主机的方法中,将单个主机的进出网络流量进行汇总,并根据该流量对主机进行分析,从而为该主机的流量建立独立的行为模式。而在基于网络的方法中,则是将网络中所有主机的网络流量作为一个整体进行分析。不同的主机通常承担不同的任务,例如电子邮件传输和网页代理,因而具有不同的行为模式。因此,与基于网络的方法相比,基于主机的方法能够生成更准确的行为模式[7]。
LDA(潜在狄利克雷分配)由Blei等人提出[8]。LDA将文档视为一系列主题的混合物,每个主题是一组相关的词语。文档的生成过程是首先选择若干主题,然后从每个主题中选择词语[9]。给定一组文档后,可以使用LDA推断语料库所涵盖的主题。例如,给定5000篇文档,这些文档涵盖不同的主题,LDA能够从这些文档中识别出具体有哪些主题。在对5000篇文档运行LDA之后,可以通过提供每个主题中高频出现的词语来描述这些主题。对于一个主题,LDA模型可能输出其中使用的词语为电影、演出、音乐、电影、演员、播放、音乐剧、最佳等;对于另一个主题,LDA可能输出高频词语为百万、税收、项目、预算、十亿、联邦、年、支出等。LDA不会生成主题名称,仅输出所使用的词语,但我们可以通过观察词语了解主题内容。在上述例子中,第一个主题的名称可能是“艺术”,第二个主题的名称可能是“预算”。由于LDA具备从大规模文档语料库中提取主题的能力,因此可用于文本分类、文档建模和协同过滤。此外,我们还可以将其应用于分析同样具有海量规模的网络流量。网络流量所产生的主题可被视为网络活动的行为模式。如果我们仅向LDA提供正常流量,则它可以生成正常流量的行为模式。当出现新的网络流量会话时,如果其偏离了正常行为模式,则很可能是入侵。
基于上述思路,本文研究了在多接入边缘计算中使用LDA模型进行入侵检测的问题。挑战在于如何利用LDA分析网络流量,即如何将流量转化为“文档”,以及如何定义网络流量中的“词语”,使得生成的“主题”能够代表正常网络活动的行为模式。我们提出了一种将网络流量类比为文档的方法。从tcpdump数据包头部抽象出一组全面的网络特征,并基于这些特征将网络流量转化为文档。我们还提出了一种利用LDA模型分析网络流量以实现入侵检测的方法。我们的方法在广泛使用的网络流量数据集DARPA 1999上进行了验证,实验结果表明,我们的方法能够在多接入边缘计算中有效检测入侵。
我们列出了本研究的主要贡献:
(i) 我们探讨了LDA在多接入边缘计算中基于异常的入侵检测系统的应用。据我们所知,这是首次完整地将LDA应用于入侵检测的工作。
(ii) 我们提出了将网络流量转换为LDA所需的“文档”的方法。我们提议在网络流量分析中使用数据包。我们选择了16个特征字段,并将每个特征字段中的唯一值用作“词语”。我们还提出了一种构建词汇表的方法。基于此词语和词汇表的设置,我们能够将网络流量转化为文档,并使用LDA处理网络流量。
(iii) 我们提出了一种使用LDA检测入侵的方法。采用基于主机的方法。LDA用于分析主机的正常流量并提取主机的行为模式。然后计算主机对行为模式的似然度。以最低似然度作为阈值。对于新的流量,如果其似然度低于该阈值,则将其分类为入侵。
(iv) 我们在广泛测试的数据集上验证了我们的方法,并将结果与现有方案的结果进行比较。根据比较结果,我们的方法能够以更高的检测率检测网络入侵。
本文其余部分的结构如下:第2节讨论该领域的最新研究成果,第3节介绍LDA模型,第4节提出我们的方法,第5节描述使用我们方法的实验,而第6节对全文进行总结。
2. 相关工作
根据所使用的网络流量类型,入侵检测系统可以分为三大类。
一种正在使用的网络流量是系统调用。Forrest等人率先提出利用系统调用轨迹来检测可能的入侵[10]。他们针对特定主机在正常系统调用上训练了一个n‐gram模型(n 3 到 6),并在测试数据中查找轨迹差异。Liao和Vemuri将文本分类技术引入Forrest的方法[11]。他们采用k‐最近邻分类器统计系统调用频率,以描述正常程序行为。然后,每个进程被转换为一个向量,并使用文本分类技术计算进程间的相似性。为了确定某个进程是否正常,他们选择相似度最接近的k个邻居,并将该进程与k个邻居进行比较。Ding等人通过语义分析系统调用来提取可执行程序的静态行为[12]。静态行为定义为系统调用序列,用于检测恶意代码。文中提出了一种推导系统调用序列的方法,并使用n‐gram模型从系统调用中提取特征。Creech等人通过对内核级系统调用应用语义分析来使用系统调用,并导出一种新特征,用于将网络活动分类为正常或入侵[13]。Maggi等人提出了一种基于主机的入侵检测系统,该系统利用系统调用参数和序列[14]。他们为调用的各个参数定义了一组异常检测模型,并添加了聚类阶段,以使模型更好地适应参数。该模型还结合了马尔可夫模型来捕捉系统调用之间的相关性。
另一种形式的审计数据是TCP/IP连接描述,其中包括主机之间高层交互的汇总,例如会话持续时间、服务类型、登录失败次数、访客登录状态等。许多系统首先重构原始网络将数据转换为连接并提取连接特征,然后进行检测技术。MADAMID[15], Bro[16],和EMERALD[17]属于此类系统。这些系统分析TCP/IP连接,以抽象正常流量的行为模式,并基于这些行为模式检测入侵。Stolfo等人参与了1998年DARPA林肯实验室入侵检测评估项目[18]。他们的项目提出了一种入侵检测系统,并将其应用于DARPA 1998数据集。他们从DARPA 1998 tcpdump数据包中抽象出TCP/IP连接,然后对这些TCP/IP连接应用数据挖掘技术以获取不同的特征。他们利用这些特征构建了专用模型。模型的输出是用于训练分类器的规则,从而对新连接进行最终分类。为了减轻将tcpdump数据包转换为TCP/IP连接的负担,提出了KDD99数据集[19]。它是DARPA 1998数据集[20]的修订版本,其中原始网络流量被汇总为TCP/IP连接,每个连接由一组网络特征表示。各种机器学习技术已应用于该数据集[19]并显示出其有效性,例如,朴素贝叶斯[21–24],最近邻[25–29],神经网络[30–33],和模糊逻辑[34, 35]。
使用的第三种网络流量形式是tcpdump数据包。在某些攻击中,某些数据包特征字段或有效载荷总是采用不太常见的值,以成功发起攻击。因此,通过分析特定数据包特征字段的值,可以构建有效的入侵检测系统。一个例子是防火墙系统:它通过阻断发往特定端口或主机的数据包来保障系统安全。最近的研究提出了一种改进方法,通过构建复杂模型并结合更多的数据包特征以获得更好的检测效果。该方向的研究最早由Mahoney发起,他提出了PHAD(数据包头部异常检测器),通过对30多个数据包特征建模,并计算所选特征的异常分数。攻击通过数据包的异常分数进行检测[36]。NETAD是对PHAD的改进,同样由Mahoney提出[37]。NETAD删除了连接开始和结束等最显著的数据包,然后从数据包的前48字节中提取特征,并相应地对协议行为进行建模。[38]中的方案也使用了tcpdump数据包,并对tcpdump数据包应用了遗传算法。参考文献[39]采用了与PHAD类似的packet feature fields[36],,并为流量中采用的每种协议构建了网络行为模型。Yassin等人提出了基于主机的PHAD[40]。他们对数据包特征进行评分,并使用线性回归和Cohen’s d测量来进行正常与异常的划分。Hareesh等人[41]通过分析数据包头部和有效载荷来检测网络攻击和蠕虫。该研究针对不同的IP头部值、TCP标志和有效载荷生成直方图。该直方图用于表示在特定时间内与某一特征相关的流的数量。然后,利用数据挖掘技术建立正常行为模式。这些直方图。曼丹哈尔和昂[42]分析了tcpdump数据包,但采用了一种基于会话的方法,涉及更多数据包以检测高级攻击。
人们一直在持续努力将LDA模型应用于网络流量和网络数据的分析。克雷默和卡林[43]使用LDA研究了企业环境中网络流量的模式,发现了白天和夜间网络使用模式的差异。费拉古特等人[44]在LDA框架内提出了几种异常检测器的构建方法,并在实验室网络中发现了一些异常情况。黄等人提出了利用LDA分析网络流量的想法[45]。他们建议将网络事件视为“词汇”,而用户在特定时间内执行的一系列事件集合可视为“文档”。他们展示了使用LDA模型检测网络入侵的可能性,但未给出详细方案。施泰因豪尔等人提出了一种基于LDA的通信系统异常检测系统[46],讨论了将LDA引入通信网络流量分析的可能性。结果表明,LDA学习到的主题符合通信活动的实际情形,但该方案严重依赖通信专家对LDA模型的结果进行解释。李等人提出了LARGen,一种基于LDA的用于基于特征的入侵检测系统的自动规则生成工具[47]。他们使用LDA分析网络流量,提取恶意流量的关键内容和特征,并基于这些特征构建IDS规则。他们已在一些真实网络流量上测试了该方法。
3. 主题模型
潜在狄利克雷分配是一种统计性的贝叶斯主题模型,可用于推断一组文档的潜在语义。LDA模型基于一个基本假设构建,即观测文档是由一组主题生成的,而这些主题是词语上的概率分布。每篇文档的生成过程是首先为该文档选择主题,然后从每个主题中选择词语[48]。
LDA中使用的符号定义如下:
(i) 词汇是一个向量 V,它包含了语料库中使用的所有词。词汇的长度表示为|V|。LDA采用词袋的概念来处理文档,即文档通过预定义的词汇表以及词汇中每个词在文档中出现的次数来表示;但不考虑文档中词语的顺序。
(ii) 语料库中共有 D 篇文档。语料库中第d篇文档表示为wd,其中 1 ≤ d≤D。wd 是一个大小为 1 × |V| 的向量,wd 中的每个元素表示词汇中的一个词在该文档中出现的次数。
(iii) 语料库为 w = {w1, w2, …, wD}。
(iv) LDA假设语料库 w 是由 K潜在主题生成的。θd 服从狄利克雷分布,具有先验参数 α,表示第 d个文档的主题分布。θd是一个包含 K列的行向量(一个 1 × K向量),其中θd的所有元素之和为1,且θd中的第 i个元素表示wd中第 i个主题所占的比例。
(v) θ = {θ1, θ2, …, θD}是一个 D × K矩阵,表示w的主题分布。
(vi) 一个主题由ϕi表示,它是一个|V| × 1向量,表示第 i个主题在词汇表上的词分布。ϕi也遵循具有先验参数 β的狄利克雷分布。ϕi的所有元素之和为1。
(vii) K主题 {ϕ1, ϕ2, …, ϕK}用于w。我们定义Φ为语料库w的主题分布。Φ = {ϕ1, ϕ2, …, ϕK}是一个|V| × K矩阵。
(viii) 文档中的一个词由wd,n表示,其中1 ≤ d≤D, 1 ≤ n≤Nd。Nd表示文档wd中有 Nd个词语。zd,n是第 d个文档中第 n个词的主题标签wd,n ,且zd,n ∈ {1, …, K}。zd,n服从以 θd为先验参数的多项分布。
表1提供了符号的汇总。
在图中,α是 θ的超参数(先验参数),β是 Φ的超参数。对于语料库中的每篇文档,基于超参数 α抽取一个主题分布θd ,该过程重复 D次。对于文档中的每个词,根据主题分布抽取一个主题标签,且每个词的主题标签抽取zd,n在第 d篇文档中重复Nd次。
图1中变量的分布如下所示:
θd ∼ Dir(α),
zd,n ∼ Multinomial(θd),
ϕi ∼ Dir(β),
wd,n ∼ Multinomial(ϕzd,n).
(1)
在上述分布中,“∼”表示“服从”,Dir(x)表示超参数为x的狄利克雷分布,Multinomial(y)表示超参数为y的多项分布。
表2总结了LDA模型中使用的参数。
w是一个可观测变量,在图1中以灰色表示;θ、Φ和z是潜在变量,以白色表示。LDA的目标是推断θ和Φ。变分贝叶斯和吉布斯采样是进行推断[8, 9]的两种有效方法。吉布斯采样是推断分层狄利克雷结构的典型方法,能够计算精确的条件后验;本文采用吉布斯采样而非变分贝叶斯。吉布斯采样的性能略优于变分贝叶斯,但速度稍慢一些。
吉布斯采样基于这样一个思想:某个词的主题标签由语料库中的其他词语决定。给定观测到的语料库w,吉布斯采样首先根据z的条件后验计算z,然后根据z的分布计算θ和Φ。我们将此过程描述如下:
(i) 使用超参数 α的狄利克雷分布抽取 d=1, …, D对应的 θd。使用超参数 β的狄利克雷分布抽取i=1, …, K对应的ϕi。这些是 θ和 Φ的初始值。
(ii) 计算给定词wd,n时zd,n的条件后验。条件后验p(zd,n=j| wd,n, α, β)等于ϕwd,n,j × θd,j × c,其中 c是一个系数。
(iii) 根据条件后验p(zd,n | wd,n, α, β)抽取zd,n。
(iv) 相应地更新第d个文档中每个词的zd,n分布。
(v) 根据狄利克雷分布计算θd的条件后验,但超参数应考虑第 d个文档中zd,n的分布。
(vi) 在所有文档处理完毕后,根据狄利克雷分布计算ϕi的条件后验,但超参数应考虑w中zd,n i的分布。
zd,n、θd和ϕi的推理如下:
p(zd,n = j| wd,n, α, β) ∝ θd,j · ϕwd,n,j,
p(θd | wd, α, β) = Γ(∑Ki=1 αi) / (∏Ki=1 Γ(αi)) · ∏Ki=1 θd,in(d,i)+αi−1,
p(ϕi | w, α, β) = Γ(∑Vj=1 βj) / (∏Vj=1 Γ(βj)) · ∏Vj=1 ϕi,jn(·,i,j)+βj−1,
(2)
其中Γ(n)=(n − 1)!,n(·,i,j)表示在语料库中分配给主题i的词j的数量,而n(d,i)表示在文档d中分配给主题i的词语数量。
4. 我们的方法
在本节中,我们提出了用于多接入边缘计算的基于LDA的基于数据包的入侵检测方法。我们首先总结了如何从tcpdump数据包生成文档,然后详细描述了使用LDA进行入侵检测的方法。
4.1. 数据预处理
我们考虑如何将网络流量转换为LDA模型可处理的文档。在使用LDA模型之前,必须执行此步骤。
我们使用的网络流量是tcpdump数据包,因为它们能帮助我们轻松地将网络流量转换为文档。为了将网络流量转换为文档,我们首先应构建词汇表。我们使用基于主机的入侵检测方法,因此我们为每个主机建立一个独立的词汇表。
一个tcpdump数据包由数据包头部和包载荷组成,可以通过Wireshark等网络嗅探工具进行捕获和分析[49]。在tcpdump数据包的数据包头部中,许多特征字段都有明确定义,例如MAC地址、IP地址、TCP服务端口等。数据包头部和特征字段的格式由相应的IETF规范定义。例如,RFC 791[50]定义了IP头部的格式,RFC 793[51]定义了TCP头部的格式。对于大多数数据包而言,第一个数据包头部是以太网头部,随后是IP头部。根据IETF规范RFC 791[50],,IP头部长度为20字节,第13到第16字节是发送该数据包的源地址。由于tcpdump数据包具有如此明确的格式,我们可以加以利用。数据包头部中特征字段的值可被视为词语,而词汇表则是所有可能特征值的集合。为了定义适用于入侵检测的词汇表,我们从数据包头部选取了16个特征字段。
根据现有的研究成果,这些特征字段在入侵检测系统[36]中被广泛使用,并在表3中列出。在表3中,括号内的内容为特征字段的缩写名称。为一个数据包选取16个特征字段,从而从一个数据包生成16个词语。每个词语由特征字段的缩写名称和特征值组合而成。
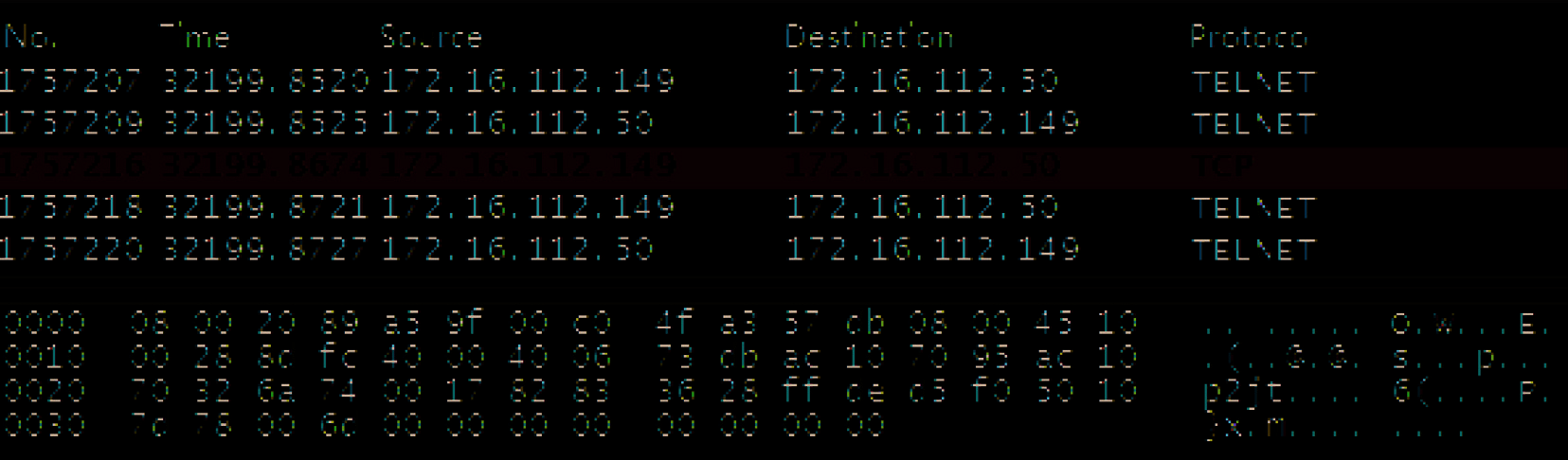
这里,我们使用Wireshark在图2中展示了一个tcpdump数据包。该数据包长度为79B。前6个字节表示以太网目的地地址,第7到12字节表示以太网源地址。因此,我们可以得到两个词语EDST_00000c和ESRC_006097。根据表3中的定义。以太网头部后面是IP头部,第16个字节是服务类型(0x10),第17到18个字节是IP包长度(十六进制为0x0041,十进制为65),因此我们得到两个词TOS_10和IL_65。使用相同的方法,我们可以从该数据包中总共抽象出16个词语,分别为EDST_00000c、ESRC_006097、TOS_10、IL_65、FF_4000、TTL_40、SRC_192.168.1.30、DST_192.168.0.20、SP_21、TF_18、TU_0、TC_ffff、TO_Null、UC_Null、IC_Null以及PS_79。
然而,在生成词汇表时,我们需要进一步考虑。由于在我们的方案中,仅使用正常流量来生成词汇表,因此可能无法覆盖所有特征值。攻击通常会使用正常流量中未包含的特征值。为了处理这些值,我们在词汇表中添加了16个额外词,以涵盖那些未在正常流量中出现但可能在攻击(或测试阶段)中出现的特征。对于每个特征字段,我们添加一个额外值,该额外值由字段的缩写名称与“其他”组合表示。例如,对于IP源字段,额外值为SRC_其他。我们使用SRC_其他来覆盖所有未在正常流量中出现但在测试阶段中出现的IP源地址。因此,最终的词汇表是流量中出现的所有唯一特征值加上16个“其他”值的总和。设Fi i ∈ {1,2,…,16}表示第i个特征字段中不同特征的数量;那么,|V| = F1+ F2+ …+ F16+ 16即为词汇表的长度。
根据词汇表,我们可以将流量转换为文档。我们将给定时间段(例如五分钟)内的tcpdump流量视为一个文档。我们统计该文档中使用了哪些词语,并统计每个词出现的次数。文档表示为词汇表中的词语在该文档中出现的次数。
我们还在表4中列出了将网络流量转换为文档时符号的含义。
4.2. 使用LDA的入侵检测
在文档转换完成后,我们使用基于异常的方法,利用LDA来检测入侵。由于LDA能够提取语料库的潜在语义,因此我们用它来抽象网络流量的潜在行为结构。我们训练LDA模型仅使用正常流量。在仅包含正常流量的训练流量上运行LDA后,我们可以自动获得潜在变量θ和Φ的推断。
由于我们的方法仅使用正常流量,Φ实际上描述了正确行为的特征,总结了正常流量行为中应包含的特征。例如,主机172.16.112.100的一个主题‐词分布ϕi为TO_空、FF_0000、SP_53和DST_172.16.112.20,因此与ϕi相关的主机172.16.112.100的正常流量模式可能是通过UDP协议(服务端口53)与主机172.16.112.20建立连接。文档θi的主题分布即为给定网络流量会话的行为结构分布。描述了这种网络流量中包含哪些类型的行为。
为了触发入侵警报,我们采用文档似然度。它可以解释为文档与正常行为结构相似的程度。我们使用主机在训练阶段的最低似然度作为阈值。如果测试文档的似然度低于该阈值,则将该测试文档标记为异常并触发警报。在我们的方法中,每个主机都有其自身的阈值,该阈值为主机所有训练文档似然度的最小值。
文档的似然度使用以下公式计算:
likd = (1/Nd) ∏n=1Nd ∑j=1K p(wd,n|zd,n = j, ϕj) · p(zd,n = j| θd)
= (1/Nd) ∏n=1Nd ∑j=1K ϕwd,n,jθd,j.
(3)
总之,我们的方法包含四个模块。
(i) 主机的词汇表基于该主机在足够长时间内的无攻击tcpdump数据包数据构建。每个数据包由16个特征表示,并收集每个特征字段的异常情况。词汇表由16个特征字段中所有异常以及每个特征字段额外的一个词组成。
(ii) 流量按主机进行分离。每个主机的流量被划分为多个片段,每个片段包含五分钟的tcpdump数据包。通过计算片段中使用的特征以及每个特征的使用次数,将一个片段转化为一个文档。
(iii) 使用主机的无攻击网络流量(训练流量)为每个主机训练LDA模型,以计算该主机的Φ。使用公式(3)计算该主机每个训练文档在Φ和θd下的似然度。将最小似然度设为该主机的阈值。
(iv) 在测试阶段,根据训练阶段计算出的Φ和测试阶段计算出的θd,我们计算每个测试文档的似然度。如果测试文档的似然度低于阈值,则将其标记为攻击。
5. 实验结果
本节中,我们实现了第4节所述的基于LDA的基于数据包的入侵检测方法。我们描述了所使用的数据集、数据预处理过程、训练阶段、测试阶段以及结果。
5.1. 数据集描述
本节使用的网络流量是麻省理工学院林肯实验室的DARPA 1999数据集,该数据集是为1999年DARPA入侵检测评估项目准备的[52]。它是网络入侵检测系统中最常用的实验数据集之一。尽管它存在许多局限性,例如攻击的简单性、信息不准确等,但它仍被用作许多入侵检测系统的基准,并为比较不同入侵检测系统的性能提供了基线。
DARPA 1999数据集提供了一套广泛收集的标准审计数据,其中包含了在军事网络环境中模拟的多种类型的入侵。该数据集中包含三周的训练数据和两周的测试数据。在这三周的训练数据集中,提供了不同类型的数据,包括tcpdump数据和审计数据。第1周和第3周的训练流量中没有攻击,第2周的训练流量中包含由数据集提供的攻击信息。测试流量共有两周,其中提供了201次攻击,涵盖了56种不同类型的四种攻击类别。这四种攻击类别包括:拒绝服务攻击(DOS),例如海王星(neptune);远程到本地(R2L),即从远程机器对本地机器的未授权访问,例如猜测密码;用户到根(U2R),即对本地超级用户(根用户)权限的未授权访问,例如弹出(eject);以及探测(probing),即对服务端口的非法扫描,例如ip扫描(ipsweep)。测试数据集中所有攻击的真实标签均在单独的文件中提供。
在我们的实验中,训练阶段使用了第三周的8天tcpdump流量(3月15日–3月19日及三天额外时间)。我们使用内部.tcpdump数据,即在内部网络中收集的数据。在测试阶段,使用了两周的测试数据(3月29日–4月2日和4月5日–4月9日),同样采用了内部tcpdump数据。
5.2. 数据预处理过程
DARPA 1999数据集是一个包含多个主机的军事网络的流量。我们的入侵检测系统是基于主机的;因此,在数据预处理过程中,我们首先根据主机地址对流量进行划分。有18台主机生成了训练和测试流量;因此,我们根据主机对网络流量进行划分。图3展示了训练流量中网络流量的划分方式,图中的每一列代表一台主机。测试流量也采用相同的方式进行划分。
对于每台主机,我们生成其自身的词汇表。主机的词汇表是利用该主机的训练数据集生成的。总共生成了18个词汇表。词汇的生成采用第4.1节中描述的方法。以主机172.16.112.50(Pascal)的词汇生成为例,表5展示了Pascal在训练阶段使用的唯一特征,表6展示了Pascal生成的词汇结果。Pascal的词汇表大小为2788。
为了将网络流量转换为文档,我们将每个主机的流量划分为五分钟会话。会话中第一个数据包的到达时间比该会话中最后一个数据包的到达时间最多早300秒。选择这样的时间槽是因为我们希望时间槽足够大以覆盖完整攻击。然后,我们计算每个词在会话中出现的次数,并将该会话转化为一个文档。
为了说明文档是如何生成的,我们假设一个包含200个数据包的Pascal简化会话。该会话的特征分布如表7所示。根据Pascal的词汇表,生成的文档是一个大小为 1 × 2788的向量。在该向量中,第{1, 2, 8, 9, 15, 20, 1348, 1350, 1359, 1363, 1365, 1394, 1396, 1425, 1442, 1452, 1455, 1458, 1461, 1465, 1466, 1467, 2788}位的数字分别设置为{100, 100, 100, 100, 200, 199, 1, 200, 200, 100, 100, 100, 100, 200, 200, 200, 200, 200, 200, 199, 1, 199, 1}。注意,该会话应来自一个测试会话,因为它包含了IL_其他、IC_其他和PS_其他的值。
5.3. 训练阶段
对于每台主机,都会训练一个独立的LDA模型。这是因为不同的主机可能用于不同的用途,例如邮件代理和互联网服务器。因此,各主机之间的主题分布可能会完全不同。如果为每台主机单独训练一个LDA模型,则检测准确率可以得到显著提高。
对于所有主机,狄利克雷先验参数α和β通过经验设定以获得良好的模型质量。我们设置α = (10/K) 和 β = 0.01。根据[47],LDA使用的话题数量对检测准确率影响有限;因此,对于大多数词汇量大小约为2000的主机,我们设置K = 150,而对于词汇量大小约为100的主机172.16.118.80和192.168.1.1,设置K = 10。由于过大的K会增加运行时间,我们并未选择较大的K。我们使用训练文档来训练LDA模型。对于不同的主机,在训练阶段最多使用1716个文档,最少使用829个文档。
在设置LDA参数后,我们使用主机的文档训练LDA模型,并得到该主机的主题‐词分布Φ和主题分布θ。由于训练阶段仅使用正常流量,因此Φ可视为主机的正常行为模式。每个文档的似然度通过公式(3)计算,主机的阈值被设为最小似然度。
5.4. 测试阶段
我们在测试阶段检测攻击。在此阶段,我们仍然使用α、β和T的相同参数设置来运行LDA模型。Φ在此阶段不会被推断。训练阶段已经计算出Φ,该结果被视为正常行为结构。每个测试文档的主题分布θ是基于训练阶段计算出的Φ推断得出的。根据Φ和测试文档的主题分布θ,使用公式(3)计算每个测试文档的似然度。该似然度用于衡量测试文档与正常行为结构的相似程度。如果似然度低于阈值,则将该文档识别为攻击。在测试阶段也使用了基于主机的方法。
5.5. 检测结果
所有18台主机使用我们的方法共生成24037个文档。其中,1041个文档被标记为入侵。误报为490个,真正例为730个。共检测到94次攻击,因为多个文档可能对应同一次攻击实例。
我们将我们的方案与PHAD[36]在检测入侵方面的能力进行性能比较。比较结果列于表8中。表8的第1列是DARPA 1999数据集中包含的所有攻击实例,第2列是PHAD检测到的入侵数量,第3列是我们的方法检测到的入侵数量。
5.6. 结果分析
从表8的比较结果可以看出,我们的方法优于PHAD,因为它检测到了更多类型的攻击以及更多的攻击实例。原因是我们的方法采用LDA来学习网络流量的行为规则。通过使用LDA,每个特征都被视为一个独立变量,并且所有特征都得到了充分使用。正常流量的行为规则是自动产生的。在LDA模型中,一个主题是以不同概率表示的所有正常特征的集合。Φ是对正常流量行为的描述。一个五分钟会话的流量,即一个文档,如果要被标记为正常,则应由正常主题生成。因此,如果一个文档根据正常行为规则计算出的似然度,即Φ,低于阈值,则可能存在攻击。
然而,在PHAD中,正常流量的行为规则是通过累加每个特征字段的所有异常值生成的,然后使用该总和将攻击与正常流量区分开来。以这种方式生成的行为规则严重依赖于单个变量,且过于严格。该方法丢失了特征所呈现的信息准确性和广泛性。因此,PHAD无法检测到像我们方法所能检测到的那么多攻击。我们方法的局限性在于它检测到的探测攻击较少,例如端口扫描、queso和ip扫描。原因是我们的方法是基于主机的,而PHAD是基于网络的,后者在检测探测攻击方面具有优势。为了解决这个问题,我们可以增加某些特征(包括端口号和TCP标志)的权重。我们将在未来的工作中对此进行研究。
6. 结论
利用主题模型,本文提出了一种网络入侵检测方案。我们的方案提出了一种使用LDA模型分析网络流量的方法。数据包特征被用来将网络流量转化为文档,并使用LDA模型学习正常流量行为。在标准数据集上使用我们的方法进行了实验,实验结果表明我们的方法在检测网络入侵方面的有效性。我们的方法可以提前自动构建网络的正常行为规则,进而保护网络流量。它适用于存在多种数据格式和数据来源的网络,从而为移动边缘计算提供了一种安全保护方式。


















 51
51

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









