






前期准备
linux与vagrant
写python个人感觉还是比较偏向于linux,老实说现在除了打打游戏之外会用到window之外,上课,学习,工作等等都已转到linux,因为linux给了我更大的自由和权限。所以我在我的macbook通过了virtualbox与vagrant搭建了一个虚拟环境,其实这样也方便我的备份和随时切换。
python与virtualenv
python的本班是2.7.9,使用virtualenv开启了一个独立的Python环境,使各个python项目之间的依赖等等不互相影响。
版本一,抓取百思不得姐的段子
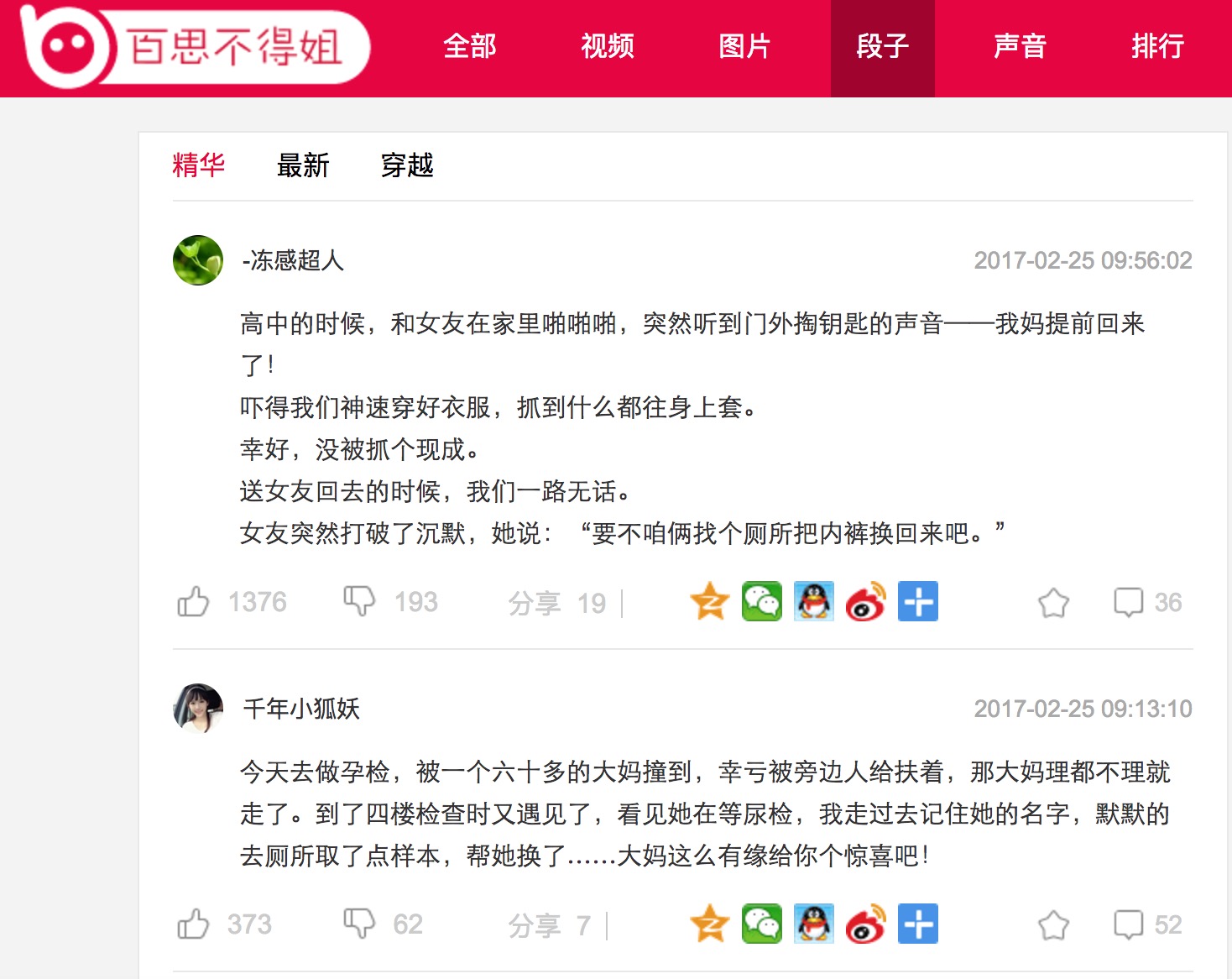
请求地址
http://www.budejie.com/new-text/2
构造请求页面
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import urllib2
page = 1
url = 'http://www.budejie.com/new-text/' + str(page)
try:
de_url = url + str(page)
request = urllib2.Request(url)
response = urllib2.urlopen(request)
print response.read().decode('utf-8')
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
if hasattr(e, "reason"):
print e.reason
居然失败了
403
Forbidden
加上headers验证
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import urllib2
page = 1
url = 'http://www.budejie.com/new-text/' + str(page)
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
try:
de_url = url + str(page)
request = urllib2.Request(de_url, headers=headers)
response = urllib2.urlopen(request)
print response.read().decode('utf-8')
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
if hasattr(e, "reason"):
print e.reason
成功了打印了html
抓取某一页的所有段子
审查元素
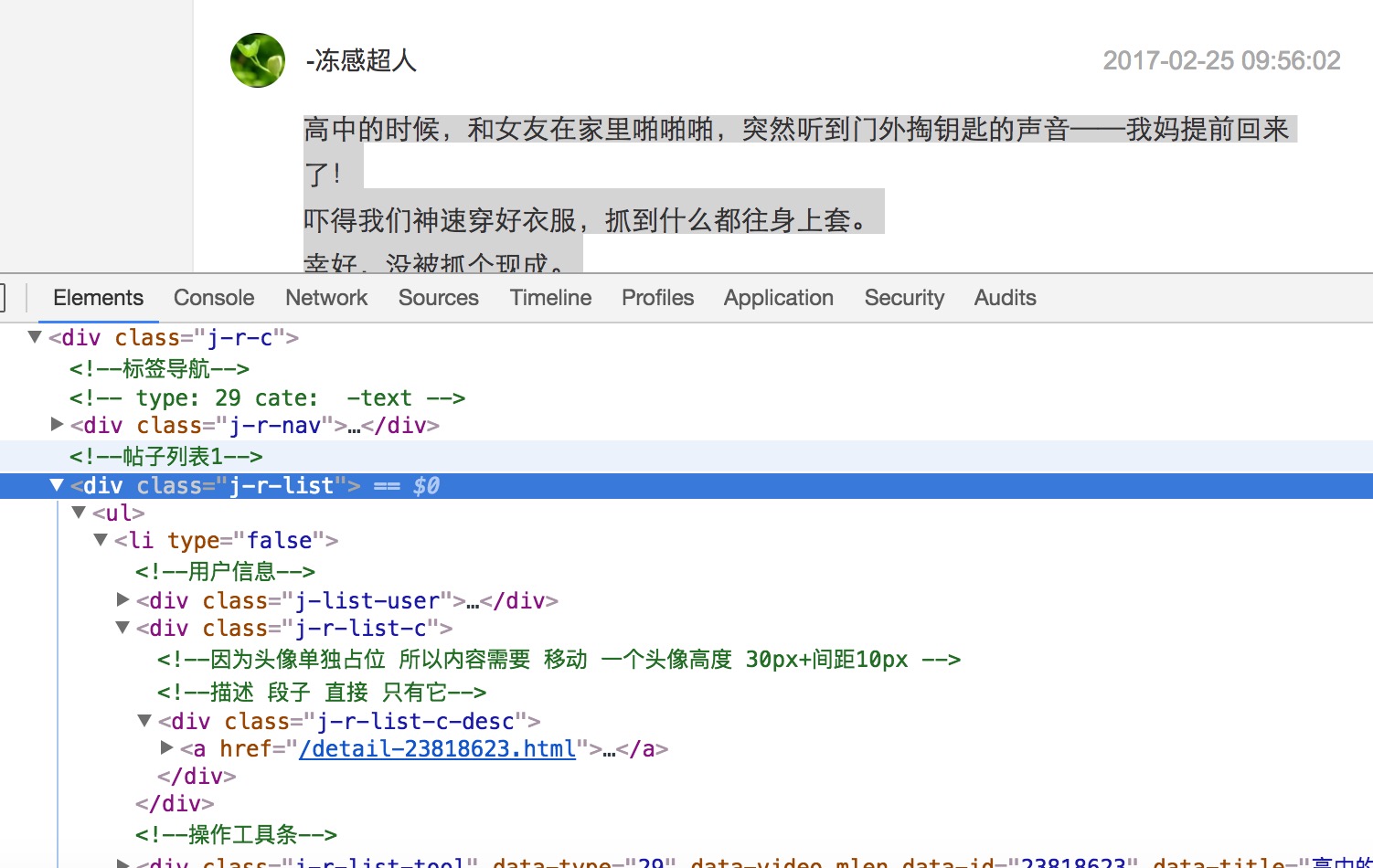
可以看到 段子都包含在帖子列表下 <div class="j-r-list"></div>下,一个段子都为一个li。先看看发送邮件的效果。
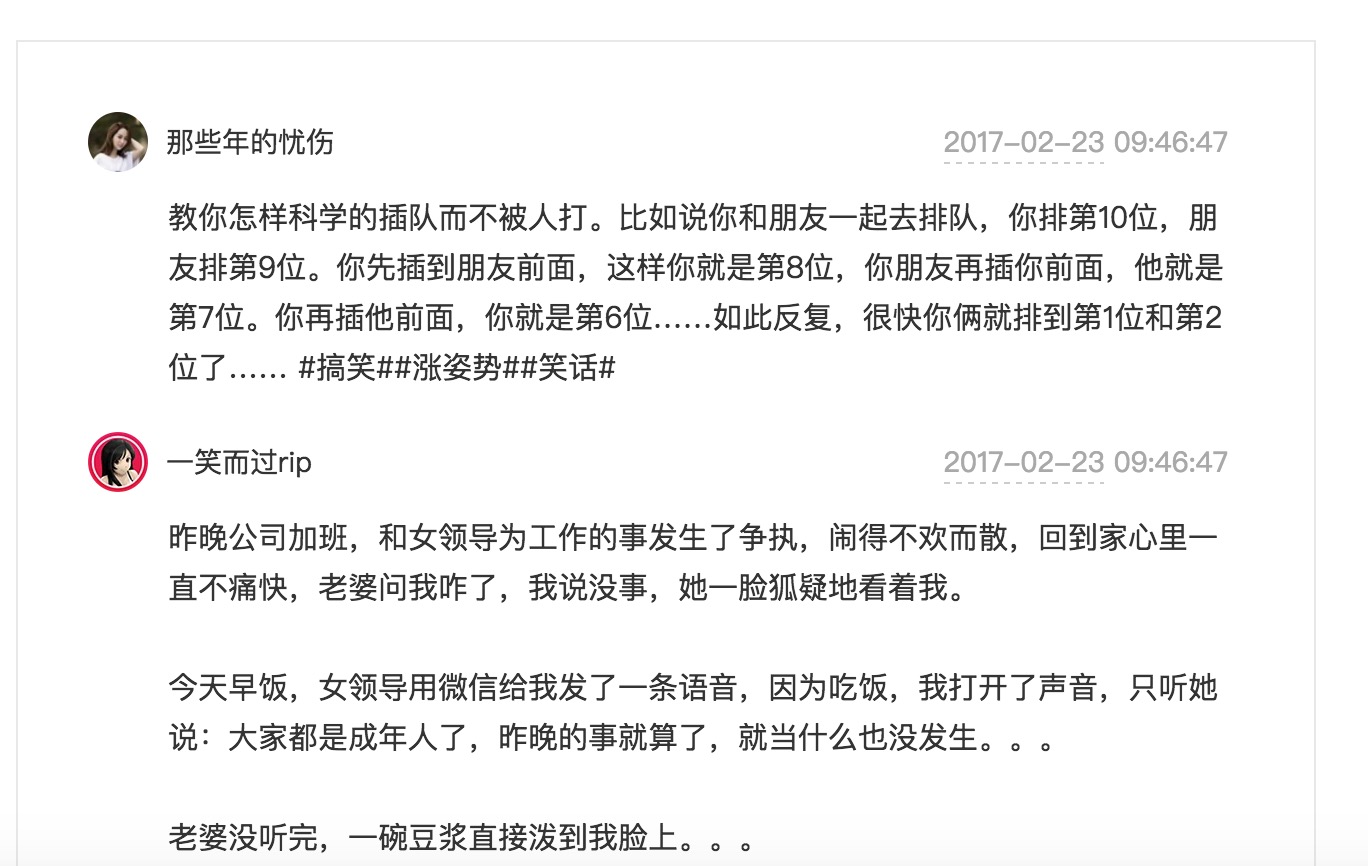
那也就是抓取头像,作者,内容。这里直接采用正则来匹配,紧接上面的代码。
content = response.read().decode('utf-8')
pattern = re.compile(r'<div.*?u-img">.*?<img.*?u-logo.*?data-original="(.*?)".*?<div.*?u-txt.*?_blank">(.*?)</a>.*?<div.*?j-r-list-c-desc">.*?html">(.*?)</a>.*?.*?j-r-list-tool-l-up.*?<span>(.*?)</span>.*?</div>', re.S)
outputs = re.findall(pattern, content)
for output in outputs:
print output[1] + ':' + output[2] + '-->' + output[1] + '\n'
关于上面的正则表达式的几点说明
-
.? 是一个固定的搭配,.和代表可以匹配任意无限多个字符,加上?表示使用非贪婪模式进行匹配,也就是我们会尽可能短地做匹配,以后我们还会大量用到 .*? 的搭配。
-
(.?)代表一个分组,在这个正则表达式中我们匹配了三个分组,在后面的遍历outputs中,output[0]就代表第一个(.?)所指代的内容,output1就代表第二个(.*?)所指代的内容,以此类推。
-
re.S 标志代表在匹配时为点任意匹配模式,点 . 也可以代表换行符。
这里已经实现了抓取该页下的段子了。
版本二,抓取糗事百科的段子
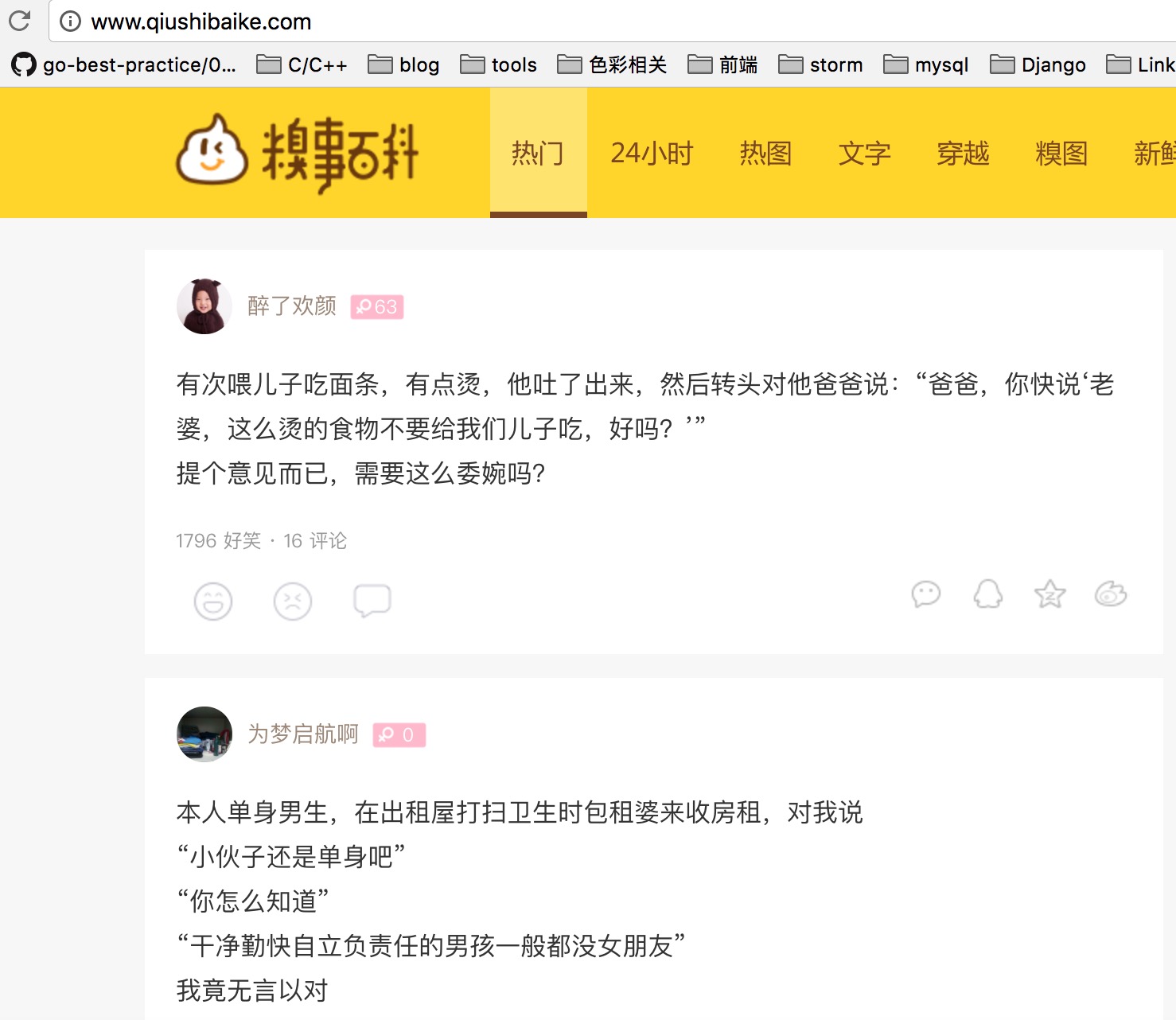
请求地址 http://www.qiushibaike.com/hot/page/2
审查一下元素
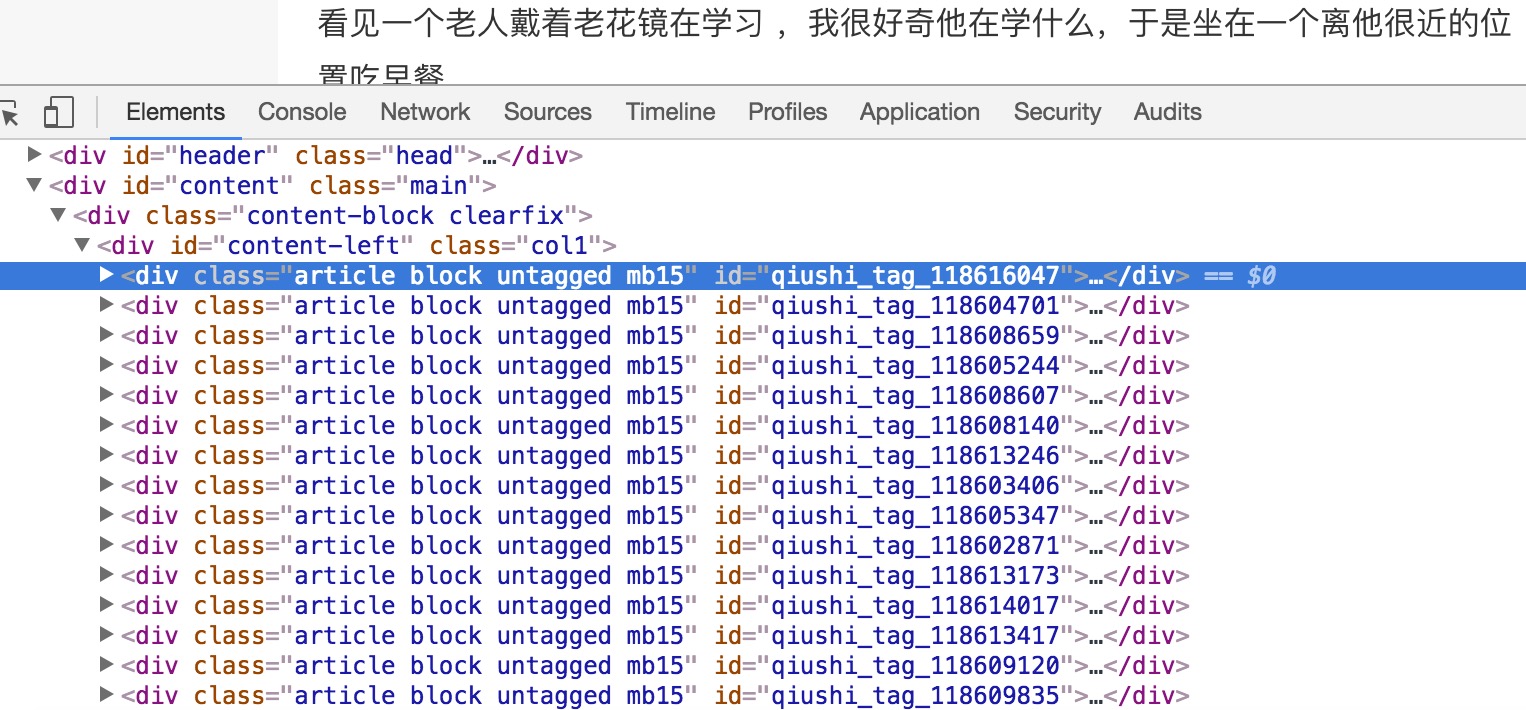
可以发现每个段子的都是一个<div class="article block untagged mb15"
这里就使用了BeautifulSoup来抓取。
关于如何安装BeautifulSoup,可直接用pip安装。这里的BeautifulSoup版本是第4版。
抓取所有段子
from bs4 import BeautifulSoup
page = 1
url = 'http://www.qiushibaike.com/hot/page/' + str(page)
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
try:
request = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(request)
content = response.read().decode('utf-8')
soup = BeautifulSoup(content, "lxml")
items = soup.find_all(name='div', class_='article block untagged mb15')
print items
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
if hasattr(e, "reason"):
print e.reason
关于BeautifulSoup的使用方法可以看它的官方文档。
抓取单个段子信息
def print_qiushi(item):
# 过滤有图片的段子
if item.find('div', class_='thumb'):
return
# 过滤有视频的段子
if item.find(name="div", class_='video_holder'):
return
# 获取揭晓这条段子的用户名
author = item.find("div", class_='author')
if author != None:
author = author.get_text().strip()
else:
author = 'anonymous'
# 获取用户名头像
avatar = item.find("img")
img = avatar['src']
if str(img).strip() == '':
img = "http://mpic.spriteapp.cn/profile/large/2016/12/03/58427c5196782_mini.jpg"
# 获取段子内容
content = item.find("div", class_='content').get_text().strip()
data = {
'author': '%s' % author,
'img': '%s' % img,
'content': '%s' % content,
'created_time': '%s' % time.strftime("%Y-%m-%d %H:%M:%S")
}
return data
完整代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Filename : get_csbk
# @Author : asd
# @Date : 2017-02-23 17:40
import urllib2
import time
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
from Utils import myutils
def main():
page = 1
url = 'http://www.qiushibaike.com/hot/page/' + str(page)
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent': user_agent}
try:
request = urllib2.Request(url, headers=headers)
response = urllib2.urlopen(request)
content = response.read().decode('utf-8')
soup = BeautifulSoup(content, "lxml")
items = soup.find_all(name='div', class_='article block untagged mb15')
result = list()
for item in items:
if item:
result.append(print_qiushi(item))
print result
except urllib2.URLError, e:
if hasattr(e, "code"):
print e.code
if hasattr(e, "reason"):
print e.reason
def print_qiushi(item):
# 过滤有图片的段子
if item.find('div', class_='thumb'):
return
# 过滤有视频的段子
if item.find(name="div", class_='video_holder'):
return
# 获取揭用户名
author = item.find("div", class_='author')
if author != None:
author = author.get_text().strip()
else:
author = 'anonymous'
# 获取用户头像
avatar = item.find("img")
img = avatar['src']
if str(img).strip() == '':
img = "http://mpic.spriteapp.cn/profile/large/2016/12/03/58427c5196782_mini.jpg"
# 获取段子内容
content = item.find("div", class_='content').get_text().strip()
data = {
'author': '%s' % author,
'img': '%s' % img,
'content': '%s' % content,
'created_time': '%s' % time.strftime("%Y-%m-%d %H:%M:%S")
}
return data
if __name__ == '__main__':
main()

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









