



 本文探讨了JVM堆内存分配过大导致的swap情况,解释了Linux系统如何在物理内存不足时使用swap内存,以及虚拟内存分配超过物理内存时为何引发swap而非GC。此外,还分析了直接内存、线程并发量对swap的影响,提出了解决swap异常的方案,包括检查线程使用和增加物理内存。
本文探讨了JVM堆内存分配过大导致的swap情况,解释了Linux系统如何在物理内存不足时使用swap内存,以及虚拟内存分配超过物理内存时为何引发swap而非GC。此外,还分析了直接内存、线程并发量对swap的影响,提出了解决swap异常的方案,包括检查线程使用和增加物理内存。
写在前面
虚拟机技术可以使得一个只有1g物理内存的机器可以运行总共需要4g内存的任务,主要方法是通过虚拟内存和物理内存映射来实现的,当物理内存不够用的时候,可以通过swap内存(存在于磁盘)和物理内存的交换来释放刚交换的物理内存,使其可以重新分配,当需要使用以前换出的内存时,在进行换入操作。
但是内存到磁盘换入换出操作十分占用CPU,因此在线上应该限制swap区的大小,如果swap占用比例较高应该进行排查和解决。
是否活跃虚拟内存大于物理内存
以jdk8为例,配置如下:
CUSTOM_JVM = -Xmx5g -Xms5g -Xmn2g -server -XX:PermSize=128m -XX:MaxPermSize=256m -XX:+PrintCommandLineFlags -XX:+UseConcMarkSweepGC -XX:CMSFullGCsBeforeCompaction=0 -XX:+UseCMSCompactAtFullCollection -XX:CMSInitiatingOccupancyFraction=68 -XX:+HeapDumpOnOutOfMemoryError -XX:+PrintGCDetails
首先怀疑因为metaspace没有达到最大内存限制,因此无限增大,并且不执行fullgc,造成新分配的young对象分配时没有达到最大的NewSize,从而引起物理内存和虚拟内存的swap操作。
可以通过jstat -gccapacity pid分析GC情况,以判断年轻代,年老代,metaspace区的晋升状态。
通过TOP命令查看内存使用情况,java进程只使用了6.5G内存,但是虚拟内存达到了13G。
Tasks: 136 total, 1 running, 135 sleeping, 0 stopped, 0 zombie
Cpu(s): 7.0%us, 3.7%sy, 0.0%ni, 88.6%id, 0.0%wa, 0.0%hi, 0.3%si, 0.4%st
Mem: 8059416k total, 7747344k used, 312072k free, 20048k buffers
Swap: 2096440k total, 1993920k used, 102520k free, 368492k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
16907 sankuai 20 0 13.0g 6.5g 6880 S 41.6 84.4 1965:06 java
5063 sankuai 20 0 1916m 24m 2884 S 6.3 0.3 171:42.18 cplugin
676 sankuai 20 0 839m 6568 1600 S 0.3 0.1 288:01.72 log_agent
9317 root 20 0 1350m 9348 2940 S 0.3 0.1 24:25.22 falcon-agent
1 root 20 0 39952 300 132 S 0.0 0.0 0:01.92 init
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root RT 0 0 0 0 S 0.0 0.0 0:11.90 migration/0
为什么过多的分配虚拟内存会引起swap而不会引起gc?
linux中物理内存是linux的主要内存区域,当物理内存不够时,linux会把一部分暂时不使用的内存数据放到磁盘swap区去,以便腾出更多可用内存空间。当需要使用位于swap区的数据时,必须先将其换回内存中。
整个内存区域分为:内核内存和用户内存。
虚拟内存技术给每一个进程一定虚拟内存空间,只有当虚拟内存实际被使用时,才分配物理内存,通过虚拟内存技术+swap内存可以使得每个用户进程使用的虚拟地址大小是一样的,并且可以大于实际物理内存空间。当一个虚拟内存准备映射到物理内存时,发现没有空闲的物理内存,操作系统会在已经被其他进程使用或者还没有立即使用的物理空间和swap内存进行交换,从而将置换出的物理内存分配给进程。swap过程相当影响性能。
为什么虚拟内存分配大小>物理内存时引起swap操作而不是gc操作?
对于linux系统而言,其只可以运行可执行的二进制代码,jvm进程本身是一个C语言开发的进程,因此其在使用虚拟内存时和其他普通的linux进程一样。
虚拟内存用户内存部分分成以下几部分:
- 代码区,linux进程的代码
- 数据区,linux进程的全局或者静态数据等
- 堆区,运行时数据动态申请的空间,程序运行时直接申请/释放的内存资源
- 栈区,存放函数的入参,临时变量,及地址返回值数据等
- 未使用区
对于JVM而言,在启动时会将自己jvm进程的全局或者静态变量存放的数据区,同时jvm进程代码放入代码区,并且申请一整块虚拟内存作为堆区给jvm中的线程使用,其中包括了jvm中的年轻代,年老代,永久代。
如果设置过大的堆区或者过大的元空间,会引起swap操作。堆大小通过Xmx,Xms设置,元空间通过MetaspaceSize设置。jdk8中该大小只是表示虚拟内存大小,并不会完全映射到物理内存(会按照一定比例申请一部分内存),但是这个值会作用到垃圾回收的阈值上。
如果未达到设置容量值,但是物理内存不够时,会将一些不再活跃的内存替换到swap中,从而分配给jvm使用。
我们看一幅图:
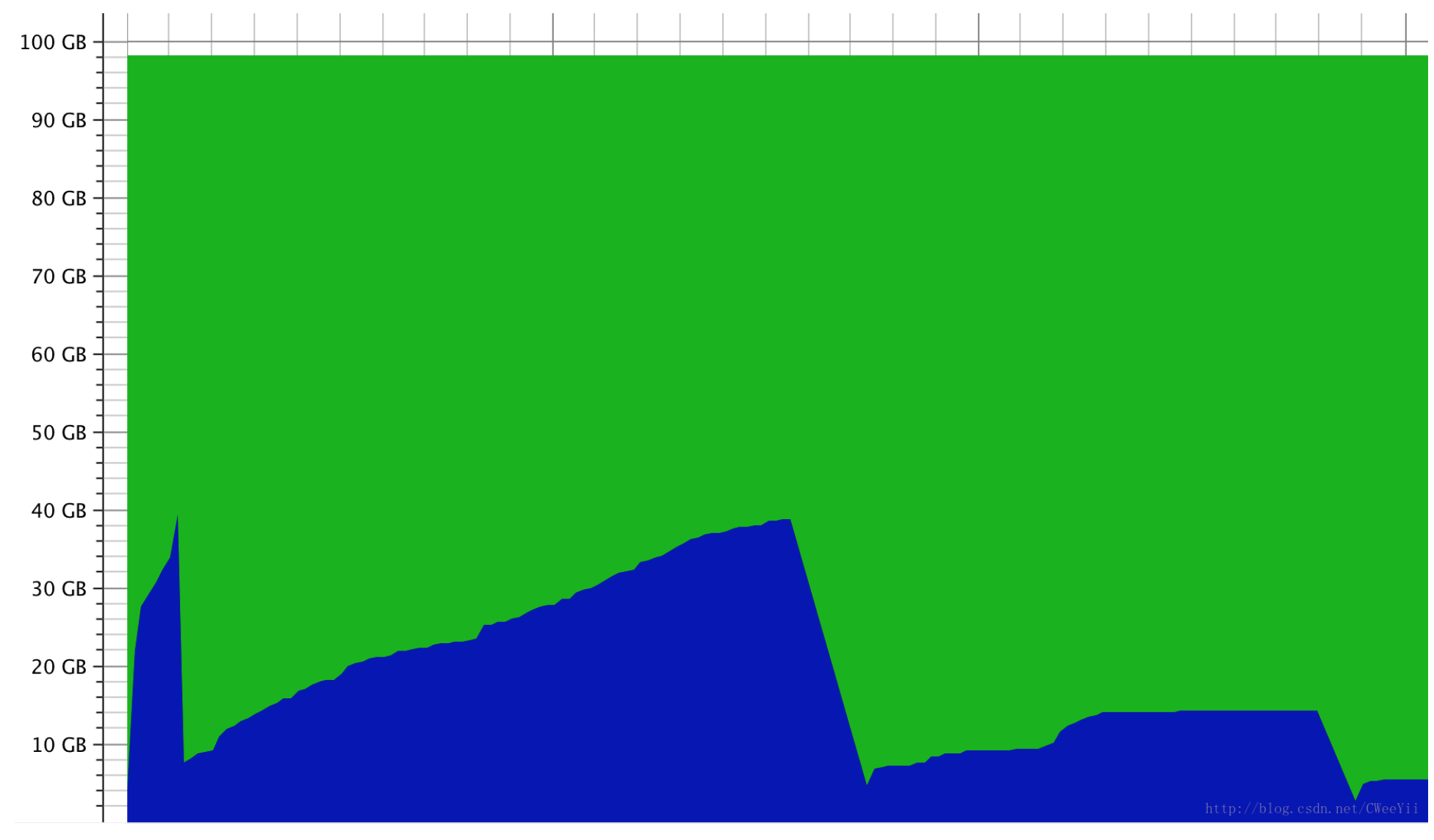
jvm启动时会分配100g虚拟内存,实际使用的内存有40g,其原理是通过swap实现的。所以过大的设置虚拟内存会引起swap操作而不是gc操作。
当我们手动触发一次fullgc,发现使用的空间只有3g。
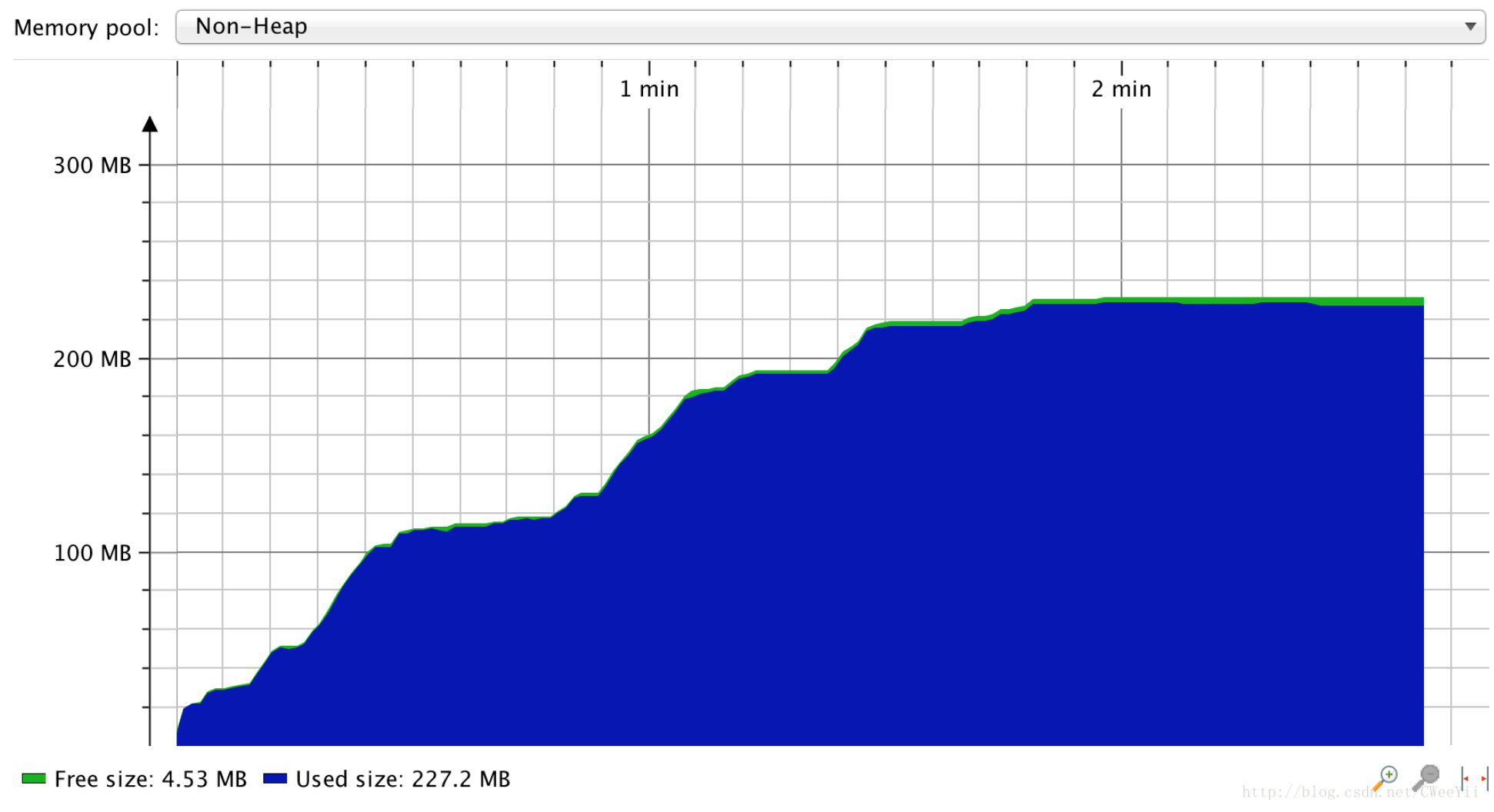
所以在设置jvm参数时建议显示的设置:MaxMetaspaceSize 值,因为默认是无穷大的,如果无休止的使用被os kill。
直接内存和swap的关系
jvm参数默认加上了-XX:+DisableExplicitGC参数,可以在用户调用system.gc时被忽略不引起gc过程。
system.gc调用不一定立即引起fullgc,具体情况视jvm自己决定,此参数可以防止用户提醒jvm进行垃圾回收。
DisableExplicitGC 也可能引起swap操作,我们通过XX:MaxDirectMemorySize 来限制直接内存大小,因此直接内存可以无限使用。
线程并发量过大引起swap
并发线程数量过大可以引起jvm线程栈占用物理内存过大,最终可能引起swap情况。
比如jvm使用内存大约使用了1.62g(最大swap区大小为2g)。当swap区增大的同一时间,观察线程数量可以发现同一时间线程数量峰值达到了650个,大约占swap区650m(每个线程1m)。
观察近3天线程和swap情况,发现所有发生swap异常的时机,线程数量都有激增,可以肯定swap异常和并发线程数量有直接关系。
通过top查看物理内存使用情况:
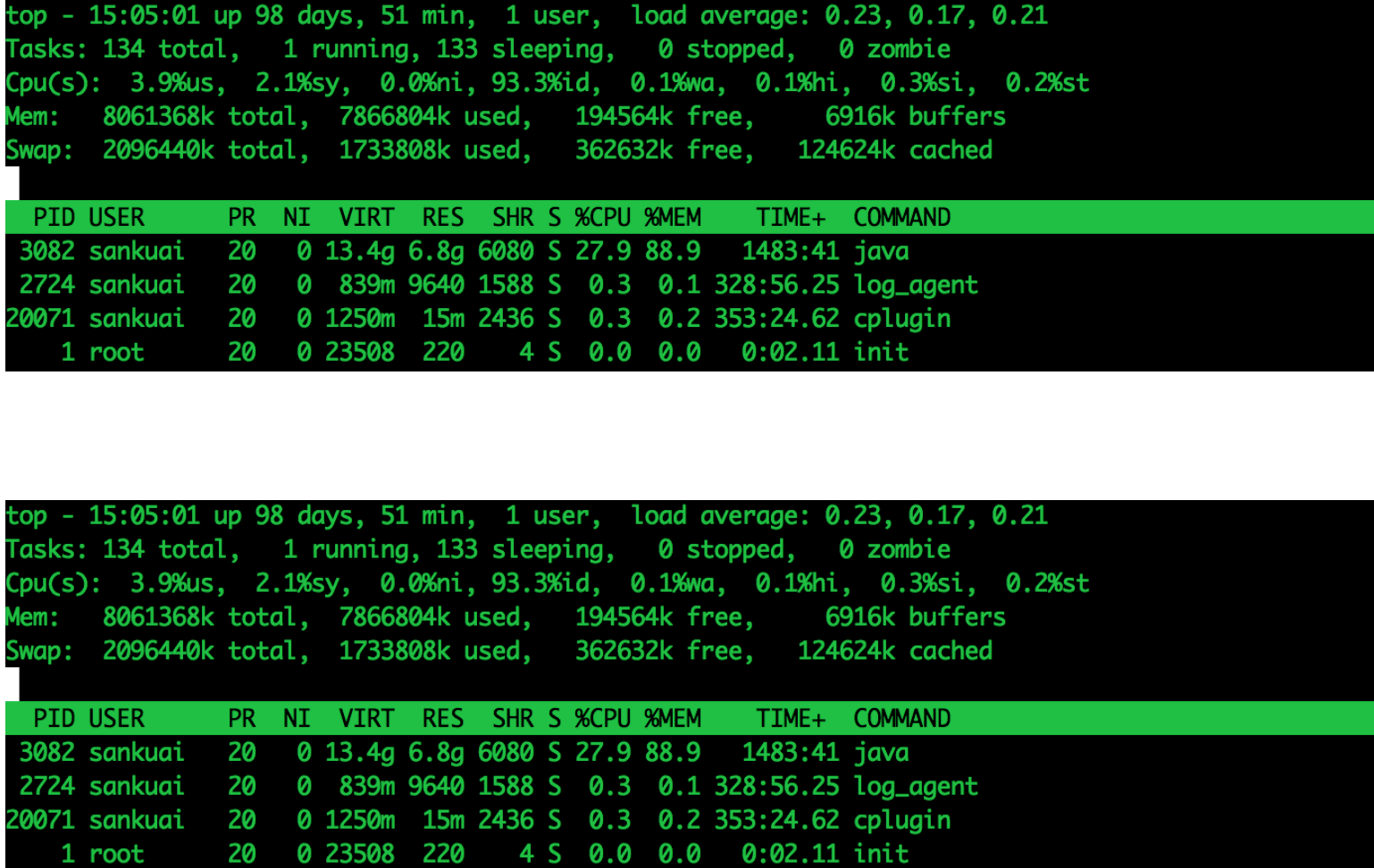
jvm内存使用情况:5g(堆内存)+0.5g(堆外内存)+0.7g(栈内存)+0.5g(meta内存)+其他内存+linux内存,再加上其他占用物理内存必定会触发使用swap区空间。
swap会占用cpu的,因此在高qps时候会引起性能下降。
可以有两种方案解决:
- 查看是否有错误使用线程的情况
- 申请加大机器内存
上面情况说明,swap区增高和jvm线程数量强相关,和qps强相关,需要看下机器线程使用情况。
排查是否存在错误使用线程情况:
[xxx@xxxx ~]$ jstack 3082 | grep 'java.lang.Thread.State' | awk '{print $2,$3,$4,$5}' | sort | uniq -c
1 BLOCKED (on object monitor)
119 RUNNABLE
25 TIMED_WAITING (on object monitor)
106 TIMED_WAITING (parking)
26 TIMED_WAITING (sleeping)
15 WAITING (on object monitor)
207 WAITING (parking)
[xxx@xxxx ~]$
统计各个线程出现次数:
[xxx@xxxx ~]$ jstack 3082 | grep 'tid.*nid' | awk -F '"' '{print $2}' | cut -d - -f 1 | cut -d# -f 1 | sort | uniq -c | sort -k1 -nr
80 Thread
53 DynamicAgentCluster
44 Pigeon
24 com.sankuai.meituan.waimai.wdc.service.IRelationService
20 jetty
18 MySQL Statement Cancellation Timer
18 jedis
16 New I/O worker
12 pool
10 Curator
10 com.sankuai.meituan.waimai.wdc.service.IWmTagService
10 com.sankuai.meituan.waimai.wdc.service.IWdcPoiQueryService
10 com.sankuai.meituan.waimai.wdc.service.IWdcMergeGroupService
10 com.sankuai.meituan.waimai.wdc.service.ISubversiveService
10 com.sankuai.meituan.waimai.wdc.service.ISimilarPoiRecommendService
10 com.sankuai.meituan.waimai.wdc.service.IPublicSeaPoiReportAuditService
10 com.sankuai.meituan.waimai.wdc.service.IPoiSegmentService
10 com.sankuai.meituan.waimai.wdc.service.IOuterRelationService
10 com.sankuai.meituan.waimai.wdc.service.IGeoCodeService
10 com.sankuai.meituan.waimai.wdc.service.IBrandService
10 com.sankuai.meituan.waimai.wdc.service.IBrandRelationService
10 com.sankuai.meituan.waimai.wdc.service.IAutoAuditService
8 main
8 elasticsearch[Big Wheel][transport_client_worker][T
8 api
5 XMDFileAppender
5 tair
4 Gang worker
4 Druid
3 cat
3 AsyncAppender
2 Timer
2 TAsyncClientManager
2 metrics
2 avatar
1 VM Thread
1 VM Periodic Task Thread
1 TraceCollector
1 threadDeathWatcher
1 Tair
1 Surrogate Locker Thread (Concurrent GC)
1 Squirrel
1 squirrel
1 Signal Dispatcher
1 Service Thread
1 Reference Handler
1 pollingConfigurationSource
1 org.eclipse.jetty.util.RolloverFileOutputStream
1 nioEventLoopGroup
1 New I/O server boss
1 New I/O boss
1 mtthrift
1 mtrace
1 MnsCacheManager
1 mafka
1 lion
1 JMonitor Http Agent Sender for app[]
1 jmonitor
1 HashSessionScavenger
1 Hashed wheel timer
1 Finalizer
1 FalconCollect
1 elasticsearch[Big Wheel][transport_client_timer][T
1 elasticsearch[Big Wheel][transport_client_boss][T
1 elasticsearch[Big Wheel][[timer]]
1 elasticsearch[Big Wheel][scheduler][T
1 elasticsearch[Big Wheel][generic][T
1 DestroyJavaVM
1 ConfigCacheManager
1 Concurrent Mark
1 commons
1 C2 CompilerThread1
1 C2 CompilerThread0
1 C1 CompilerThread2
1 Attach Listener
1 AsyncLoggerConfig
1 AsyncLogger
1 Abandoned connection cleanup thread
1 1429208949@qtp
1 1171978040@qtp
线程waiting情况:
[xxx@xxxx ~]$ jstack 3082 | grep -B1 'java.lang.Thread.State.*WAITING' | grep 'tid.*nid' | awk -F '"' '{print $2}' | cut -d - -f 1 | cut -d# -f 1 | sort | uniq -c | sort -k1 -nr
53 DynamicAgentCluster //该线程是一个scheduleAtFixedRate的线程,其是Thrift用于从OCTO中获取指定appkey对应的serverLists,每个ThriftClient都会有一个thread
44 Pigeon
37 com.sankuai.meituan.waimai.wdc.service.IRelationService
18 MySQL Statement Cancellation Timer
16 jetty
15 Thread
15 jedis
12 pool
10 Curator
10 com.sankuai.meituan.waimai.wdc.service.IWmTagService
10 com.sankuai.meituan.waimai.wdc.service.IWdcPoiQueryService
10 com.sankuai.meituan.waimai.wdc.service.IWdcMergeGroupService
10 com.sankuai.meituan.waimai.wdc.service.ISubversiveService
10 com.sankuai.meituan.waimai.wdc.service.ISimilarPoiRecommendService
10 com.sankuai.meituan.waimai.wdc.service.IPublicSeaPoiReportAuditService
10 com.sankuai.meituan.waimai.wdc.service.IPoiSegmentService
10 com.sankuai.meituan.waimai.wdc.service.IOuterRelationService
10 com.sankuai.meituan.waimai.wdc.service.IGeoCodeService
10 com.sankuai.meituan.waimai.wdc.service.IBrandService
10 com.sankuai.meituan.waimai.wdc.service.IBrandRelationService
10 com.sankuai.meituan.waimai.wdc.service.IAutoAuditService
8 api
5 XMDFileAppender
4 main
4 Druid
3 cat
3 AsyncAppender
2 Timer
2 metrics
2 avatar
1 TraceCollector
1 threadDeathWatcher
1 Tair
1 Squirrel
1 squirrel
1 Reference Handler
1 pollingConfigurationSource
1 org.eclipse.jetty.util.RolloverFileOutputStream
1 mtthrift
1 mtrace
1 MnsCacheManager
1 mafka
1 lion
1 JMonitor Http Agent Sender for app[]
1 jmonitor
1 HashSessionScavenger
1 Hashed wheel timer
1 Finalizer
1 FalconCollect
1 elasticsearch[Big Wheel][transport_client_timer][T
1 elasticsearch[Big Wheel][[timer]]
1 elasticsearch[Big Wheel][scheduler][T
1 elasticsearch[Big Wheel][generic][T
1 ConfigCacheManager
1 commons
1 AsyncLoggerConfig
1 AsyncLogger
1 Abandoned connection cleanup thread
1 1429208949@qtp
需要排查那些wait的线程情况:
- 53 DynamicAgentCluster:美团thrift rpc框架,每个rpc客户端都有一个线
- 44 Pigeon:点评pigeon rpc框架:其会分配一些线程来获取最新的服务器信
- 18 MySQL Statement Cancellation Timer:mysql事务超时判断timer
- 16 jetty: 阻塞中的jetty工作线程
- 15 jedis: jedis相关线程,包括renew-slots的slot重新分配以及相关的请求线
- com.sankuai.meituan.waimai.wdc.service: 和业务请求相关的线程,可以发现这个占比较大。
最终结论线程使用合理,大量线程的产生式因为请求量的递增相关。
申请大物理内存机器:
将机器从8g内存扩展到16g内存,解决了swap异常。
8g内存:

16g内存:


















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









