







 本文介绍了推荐系统的排序阶段及其重要性,并概述了从WideDeep到DeepFM等模型的发展历程。详细探讨了特征工程、LR模型及GBDT+LR等算法的应用,并提供了基于TensorFlow的WDL实现案例。
本文介绍了推荐系统的排序阶段及其重要性,并概述了从WideDeep到DeepFM等模型的发展历程。详细探讨了特征工程、LR模型及GBDT+LR等算法的应用,并提供了基于TensorFlow的WDL实现案例。
文章目录
简述
推荐系统一般分为 召回, 排序, 展示打散 等几个阶段. 排序阶段较为重要, 从召回的上千个相关结果中, 预测出用户的点击概率, 以此排序. 一般地, 一个推荐系统在使用排序模型前后, 效果可以提升20% 以上.
- 模型演进
WideDeep->DeepFM->DIN->DIEN->DSIN
数据准备
features
- user特征
静态特征, 如人口属性.
交互统计特征, 如近期偏好类目等. - item特征
静态特征, 如类目, 价格, 标题等.
交互统计特征, 如近期曝光点击情况. - context特征
上阶段的召回信息, 当时的时间, 季节什么的.
label
l a b e l = { 0 , 只曝光无点击 1 , 曝光且有点击 label = \begin{cases} 0, & \text{只曝光无点击} \\ 1, & \text{曝光且有点击} \end{cases} label={0,1,只曝光无点击曝光且有点击
特征工程
详见参考[3].
- 普通离散特征
职业, 婚姻状态等, 同常枚举值不超过100个. - id类特征
如淘宝上的活跃卖家, 可能就上千万了. - 连续特征正规化
如 身高,体重, 点击数. 不一定要缩放到0-1, 对数平滑也是可以的, 如 l n ( 1 + x ) ln(1+x) ln(1+x).
在工业界的特征工程中,大多数做法是构造大量离散特征,再根据经验对特征交叉构造高阶特征。这样的特征构造方式,在大样本的前提下,操作简单有效。简单体现在较少的人工设计。
那么离散特征是不是无所不能的?其实不然。首先,特征交叉不是无限度的,两个万级别的特征,交叉之后就是亿级别,所以一般交叉特征都是2、3阶;其次,特征依赖于数据,当我们的数据来源不能继续增加的时候,新特征的设计就很难做了。
特征生成
叫 feature generate.
一般LR的训练组件, 都只用一个kv格式的string字段来存储特征.
如对于 item_id=1,seller_id=2这样的特征, 一般会要求编码成item_id_1 seller_id_2这样以下划线分隔单个kv, 以空格分隔多个kv 的字符串. 这些特征就是一个bool变量.
LR 模型
同 常规的LR二分类任务, 见参考[15]. 只不过工业界的特殊之处在于 超大规模稀疏特征及特征的交叉.
工程落地算法
有 OWL_QN, FTRL 等. 详见
工业界的特点是:
特征高阶交叉后规模可达百亿, 使用 Parameter Server 训练, 比如 ali 只支持离散特征, 即
x
i
∈
{
0
,
1
}
x_i\in\{0,1\}
xi∈{0,1}, 损失函数为平方损失.
GBDT+LR
略.
WDL
对应paper, 详见[2]
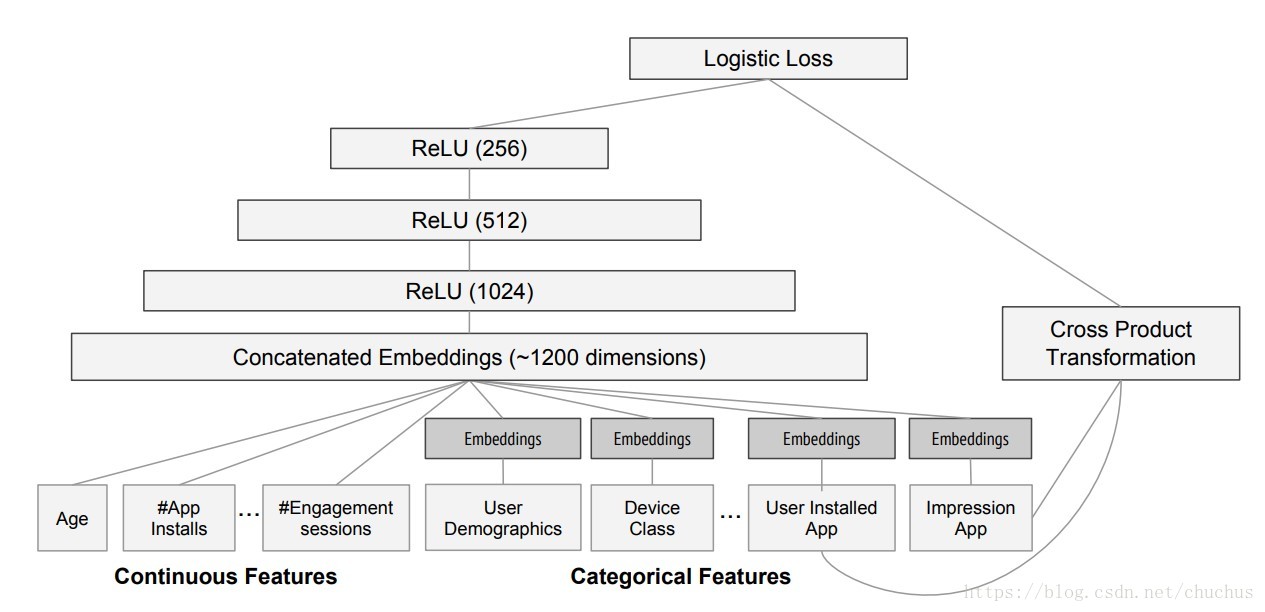
figure WDL图解
motivation
- LR
具有 memorization 特性. 从历史数据中学习并利用各个被交叉特征的共现关系, 推荐结果同历史行为高度相似并因此带来了局限性. - NN
具有 generalization 特性. 从历史数据中学习到了特征的传递性, 因此具有了未见特征组合的探索能力, 推荐结果可提升多样性.
LR是广义的线性模型, 除了工程师精心构造的交叉特征, 此外不具备任何非线性的表达能力.
GBDT都是浅层模型, 表征能力也有限.
基于此, 可以考虑 Wide & Deep Learning.
wide linear part
交叉特征与离散特征.
deep part
连续特征与高维稀疏离散特征.
where is the number of unique features in a feature column.
tf1.12 实现
from tensorflow.contrib import layers
self.linear_logits, self.collections_linear_weights, self.linear_bias = \
layers.weighted_sum_from_feature_columns(
columns_to_tensors=features,
feature_columns=self.wide_column,
num_outputs=1,...)
self.deep_input_layer = layers.input_from_feature_columns(self.features, self.deep_column, scope=embedding_scope)
self.deep_network = tf.concat([self.deep_input_layer],axis=1)
self.deep_network = layers.fully_connected(self.deep_network,num_hidden_units, ...)
self.dnn_logits = layers.fully_connected(self.deep_network,1,...)
self.logits = self.dnn_logits + self.linear_logits
self.loss = tf.nn.sigmoid_cross_entropy_with_logits(
logits=logits,
labels=labels)
self.train_ops=[
layers.optimize_loss(loss=loss_op, optimizer='Ftrl', variables=tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES,scope='wide')),
layers.optimize_loss(loss=loss_op, optimizer='AdagradDecay', variables=tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES,scope='deep'))
]
实验评测
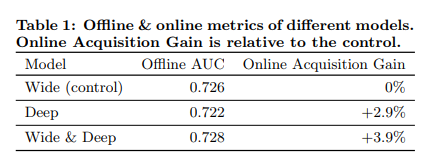
figure 评测结果
- 数据集
论文中没有提数据集, 直接在 GooglePlay 做三周的线上AB. 这样的论文我还是第一次见 . - baseline
only Wide Component. 与 only Deep Component.
可以看到后者的AUC较前者低, 但线上表现反而好. - WDL approach
app 安装率(app acquisition)提升了+3.9%.
MF
FM
见[5].
FFM
见[7].
DeepFM
架构
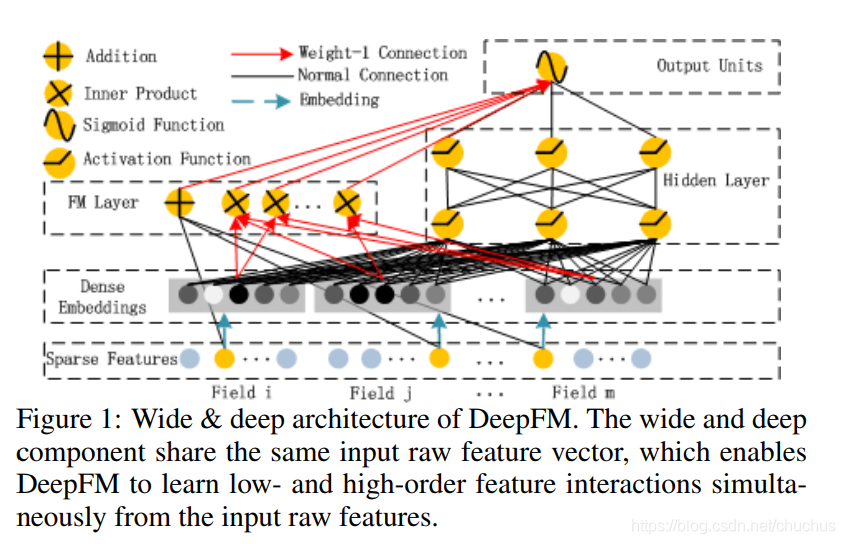
图1, 相应论文中的架构截图.
formula
p
r
e
d
_
c
t
r
=
s
i
g
m
o
i
d
(
y
F
M
+
y
D
N
N
)
pred\_ctr = sigmoid(y_{FM} + y_{DNN} )
pred_ctr=sigmoid(yFM+yDNN)
where
Y
F
M
=
w
0
+
∑
i
=
1
d
w
i
x
i
+
∑
i
=
1
d
∑
j
=
i
+
1
d
<
V
i
,
V
j
>
x
i
x
j
(1)
Y_{FM} = w_0 + \sum_{i=1}^d{w_ix_i}+\sum_{i=1}^d\sum_{j=i+1}^d<V_i,V_j>x_i x_j \tag 1
YFM=w0+i=1∑dwixi+i=1∑dj=i+1∑d<Vi,Vj>xixj(1)
参考
- TF教程, TensorFlow Wide & Deep Learning Tutorial
- google的paper, Wide & Deep Learning for Recommender Systems
- 我的blog,特征工程
- 他人blog,FFM原理与实践简单理解
- paper, FM
- s.e.Difference between Factorization machines and Matrix Factorization?
- paper, FFM
- paper,FTRL
- paper,Listwise Collaborative Filtering
- paper,2017,DeepFM
- paper, 2018, Deep Interest Network for Click-Through Rate Prediction
- paper,2018,Deep Interest Evolution Network for Click-Through Rate Prediction
- paper,2019,Deep Session Interest Network for Click-Through Rate Prediction
- paper,2019,BST, Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
- my blog, 逻辑回归


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









