




 本文详细比较了JDK1.7和1.8版本ConcurrentHashMap与Hashtable在数据结构、并发控制、性能优劣上的区别,重点讲解了ConcurrentHashMap的分段锁升级与优化策略,以及两者在并发度和效率上的显著差别。
本文详细比较了JDK1.7和1.8版本ConcurrentHashMap与Hashtable在数据结构、并发控制、性能优劣上的区别,重点讲解了ConcurrentHashMap的分段锁升级与优化策略,以及两者在并发度和效率上的显著差别。
面试题:ConcurrentHashMap 和 Hashtable 的区别
关键词
- 1.8ConcurrentHashMap 只锁 首节点
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
-
底层数据结构: JDK1.7 的 ConcurrentHashMap 底层采⽤ 分段的数组+链表 实现,JDK1.8采⽤的数据结构跟 HashMap1.8 的结构⼀样,数组+链表/红⿊⼆叉树。 Hashtable 和JDK1.8 之前的 HashMap 的底层数据结构类似都是采⽤ 数组+链表 的形式,数组是HashMap 的主体,链表则是主要为了解决哈希冲突⽽存在的;
-
实现线程安全的⽅式(重要): ① 在 JDK1.7 的时候, ConcurrentHashMap (分段锁)对整个桶数组进⾏了分割分段( Segment ),每⼀把锁只锁容器其中⼀部分数据,多线程访问容器⾥不同数据段的数据,就不会存在锁竞争,提⾼并发访问率。 到了 JDK1.8 的时候已经摒弃了 Segment 的概念,⽽是直接⽤ Node 数组+链表+红⿊树的数据结构来实现,并发控制使⽤ synchronized 和 CAS 来操作。(JDK1.6 以后 对 synchronized 锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap ,虽然在 JDK1.8 中还能看到Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② Hashtable (同⼀把锁) :使⽤ synchronized 来保证线程安全,效率⾮常低下。当⼀个线程访问同步⽅法时,其他线程也访问同步⽅法,可能会进⼊阻塞或轮询状态,如使⽤ put 添加元素,另⼀个线程不能使⽤ put 添加元素,也不能使⽤ get,竞争会越来越激烈效率越低。
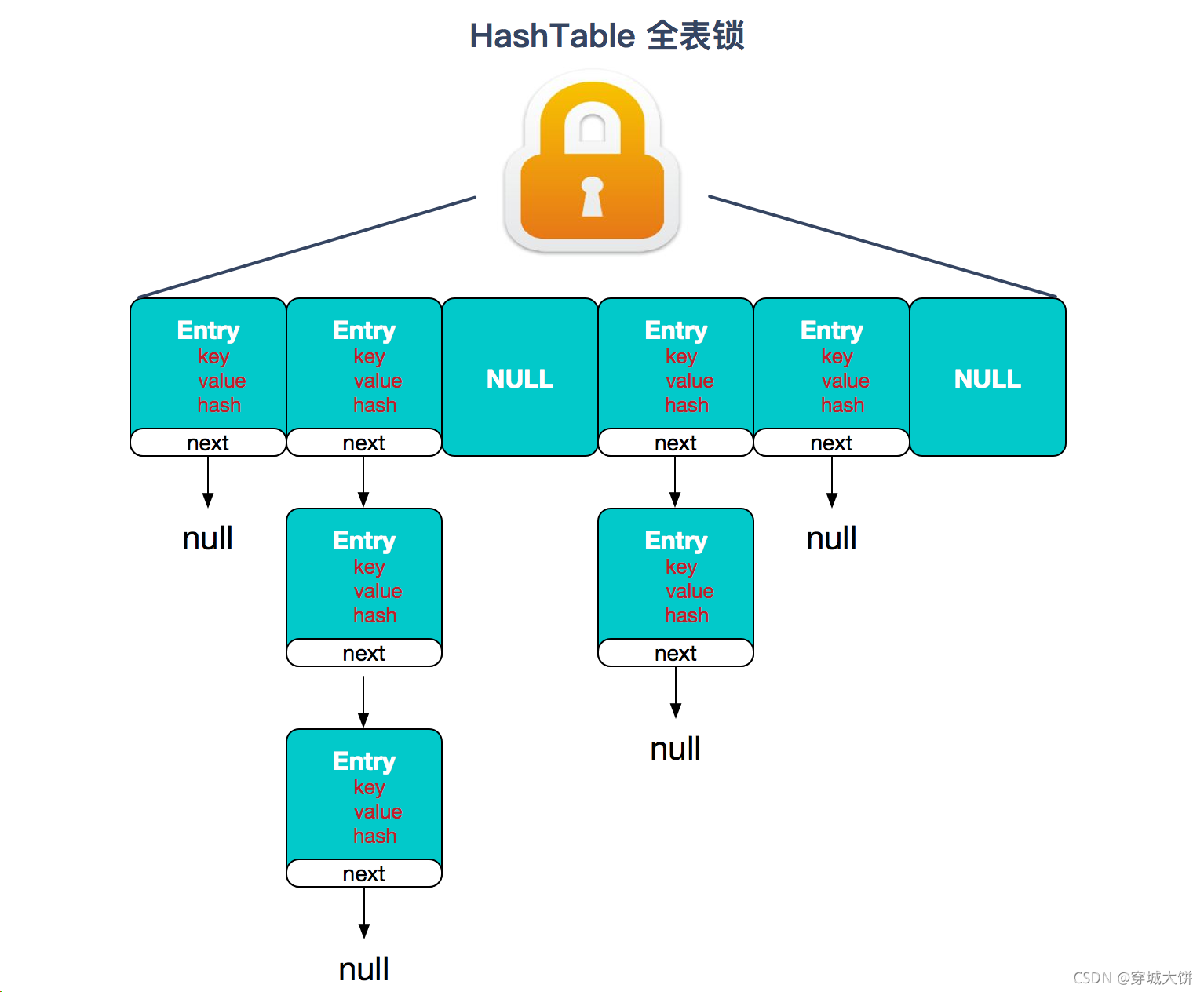
HashTable:
JDK1.7 的 ConcurrentHashMap:
⾸先将数据分为⼀段⼀段的存储,然后给每⼀段数据配⼀把锁,当⼀个线程占⽤锁访问其中⼀个段数据时,其他段的数据也能被其他线程访问。
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
Segment 实现了 ReentrantLock , 所以 Segment 是⼀种可重⼊锁,扮演锁的⻆⾊。 HashEntry ⽤于存储键值对数据。
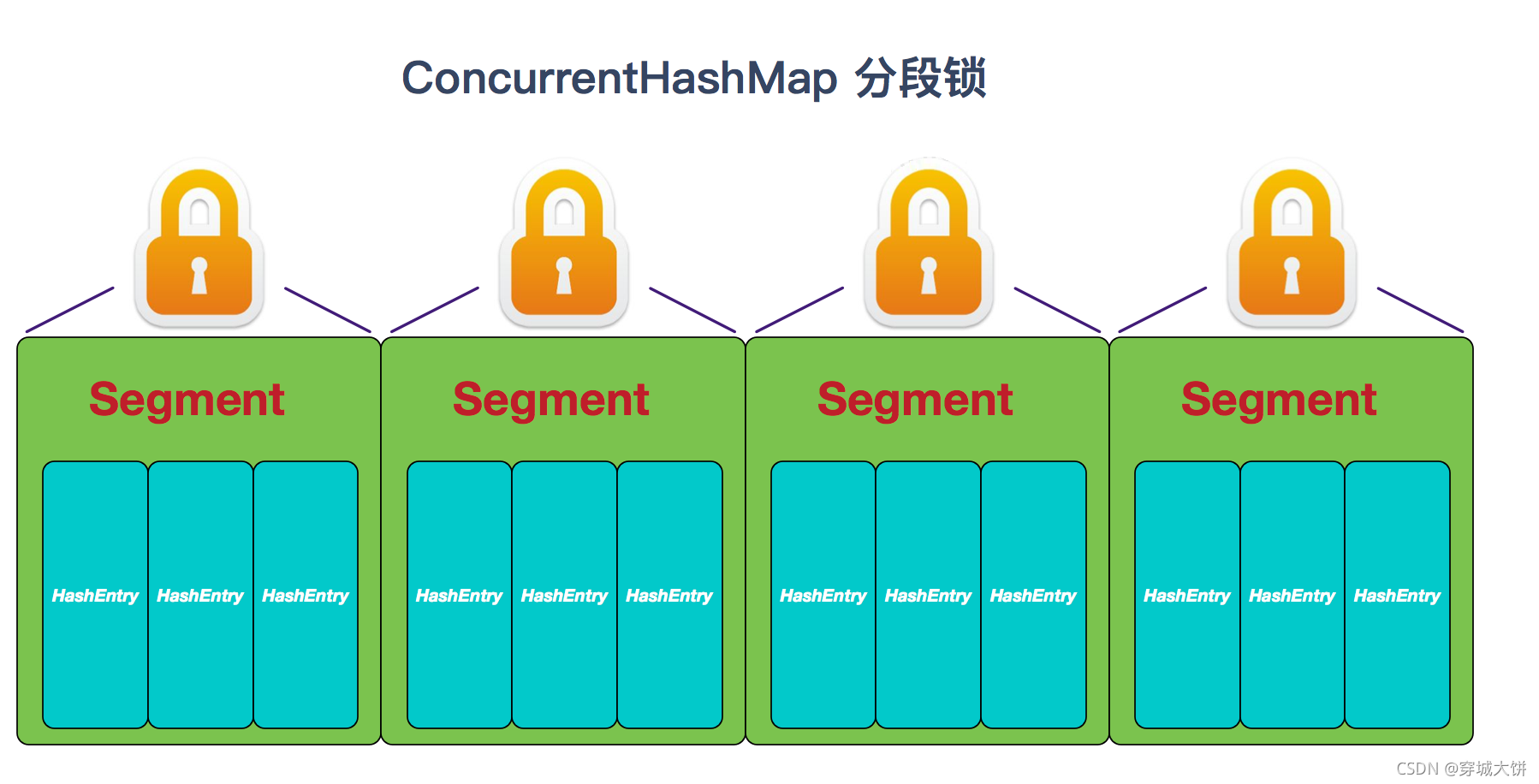 ⼀个 ConcurrentHashMap ⾥包含⼀个 Segment 数组。 Segment 的结构和 HashMap 类似,是⼀种数组和链表结构,⼀个 Segment 包含⼀个 HashEntry 数组,每个 HashEntry 是⼀个链表结构的元素,每个 Segment 守护着⼀个 HashEntry 数组⾥的元素,当对 HashEntry 数组的数据进⾏修改时,必须⾸先获得对应的 Segment 的锁。
⼀个 ConcurrentHashMap ⾥包含⼀个 Segment 数组。 Segment 的结构和 HashMap 类似,是⼀种数组和链表结构,⼀个 Segment 包含⼀个 HashEntry 数组,每个 HashEntry 是⼀个链表结构的元素,每个 Segment 守护着⼀个 HashEntry 数组⾥的元素,当对 HashEntry 数组的数据进⾏修改时,必须⾸先获得对应的 Segment 的锁。
JDK1.8 的 ConcurrentHashMap:
JDK1.8 的 ConcurrentHashMap 不在是 Segment 数组 + HashEntry 数组 + 链表,⽽是 Node 数组 + 链表 / 红⿊树。不过,Node 只能⽤于链表的情况,红⿊树的情况需要使⽤ TreeNode 。当冲突链表达到⼀定⻓度时,链表会转换成红⿊树。
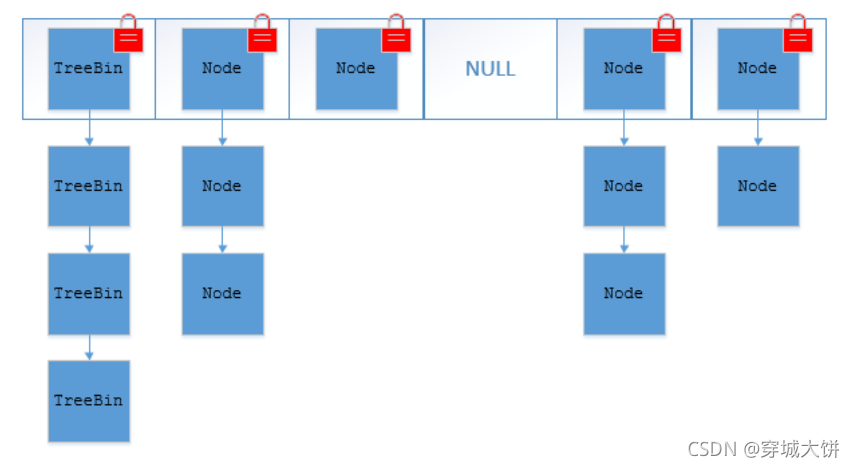
ConcurrentHashMap 取消了 Segment 分段锁,采⽤ CAS 和 synchronized 来保证并发安全。数据结构跟 HashMap1.8 的结构类似,数组+链表/红⿊⼆叉树。Java 8 在链表⻓度超过⼀定阈值(8)时将链表(寻址时间复杂度为 O(N))转换为红⿊树(寻址时间复杂度为 O(log(N)))
synchronized 只锁定当前链表或红⿊⼆叉树的⾸节点,这样只要 hash 不冲突,就不会产⽣并发,效率⼜提升 N 倍。
Hashtable 对比 ConcurrentHashMap
- Hashtable 与 ConcurrentHashMap 都是线程安全的 Map 集合
- Hashtable 并发度低,整个 Hashtable 对应一把锁,同一时刻,只能有一个线程操作它
- ConcurrentHashMap 并发度高,整个 ConcurrentHashMap 对应多把锁,只要线程访问的是不同锁,那么不会冲突
ConcurrentHashMap 1.7
- 数据结构:Segment(大数组) + HashEntry(小数组) + 链表 ,每个Segment 对应一把锁,如果多个线程访问不同的 Segment,则不会冲突
- 并发度:Segment 数组大小即并发度,决定了同一时刻最多能有多少个线程并发访问。Segment 数组不能扩容,意味着并发度在
ConcurrentHashMap 创建时就固定了 - 索引计算
- 假设大数组长度是 2m2^m2m,key 在大数组内的索引是 key 的二次hash 值的高 m 位
- 假设小数组长度是 2n2^n2n,key 在小数组内的索引是 key 的二次hash 值的低 n 位
- 扩容:每个小数组的扩容相对独立,小数组在超过扩容因子时会触发扩容,每次扩容翻倍
- Segment[0] 原型:首次创建其它小数组时,会以此原型为依据,数组长度,扩容因子都会以原型为准
ConcurrentHashMap 1.8
- 数据结构:Node 数组 + 链表或红黑树 ,数组的每个头节点作为锁,如果多个线程访问的头节点不同,则不会冲突。首次生成头节点时如果发生竞争,利用 cas 而非 syncronized,进一步提升性能
- 并发度:Node 数组有多大,并发度就有多大,与 1.7 不同,Node 数组可以扩容
- 扩容条件:Node 数组满 3/4 时就会扩容
- 扩容单位:以链表为单位从后向前迁移链表,迁移完成的将旧数组头节点替换为 ForwardingNode
- 扩容时并发 get
- 根据是否为 ForwardingNode 来决定是在新数组查找还是在旧数组查找,不会阻塞
- 如果链表长度超过 1,则需要对节点进行复制(创建新节点),怕的是节点迁移后 next 指针改变
- 如果链表最后几个元素扩容后索引不变,则节点无需复制
- 扩容时并发 put
- 如果 put 的线程与扩容线程操作的链表是同一个,put 线程会阻塞
- 如果 put 的线程操作的链表还未迁移完成,即头节点不是ForwardingNode,则可以并发执行
- 如果 put 的线程操作的链表已经迁移完成,即头结点是ForwardingNode,则可以协助扩容
- 与 1.7 相比是懒惰初始化
- capacity 代表预估的元素个数,capacity / factory 来计算出初始数组大小,需要贴近 2n2^n2n
- loadFactor 只在计算初始数组大小时被使用,之后扩容固定为 3/4
- 超过树化阈值时的扩容问题,如果容量已经是 64,直接树化,否则在原来容量基础上做 3 轮扩容


















 3125
3125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











