







电力预测赛道
耶耶!第一期AI夏令营结束,收获了很多,所以报名了第二期继续学习。
这是我第一次做时间序列的数据预测,又可以学习新知识喽!
当然还有其他赛道,有余力的同学就同时报名好几个赛道,我就先只报一个赛道学习啦!学新知识总是令人无比地兴奋!
如果有想参加的可以私信我报名
有什么疑问可以评论区互相交流讨论呀,share你的最佳分数!
赛题思考
- 阅读赛题要求

核心:给定多个房屋对应电力消耗历史N天的相关序列数据,预测房屋对应电力的消耗,以MSE作为衡量标准。 - 下载数据

查看数据
train = pd.read_csv('./data/data283474/train.csv')
test = pd.read_csv('./data/data283474/test.csv')
submit = pd.read_csv('./data/data283474/sample_submit.csv')
print(train)
print(test)
print(submit)
输出


观察数据
可以发现是做连续值预测
提交文件格式也很清楚
然后我们在具体看看train数据一些值

从id这列数据,可以发现,不同id有不一样长度的时间序列数据
总5832个样本,大部分id是496条数据,最多是506条
其他列包括test数据也可以稍微通过这种统计去观察数据形式
3. 先套个机器学习方法跑一下
# 1. 导入需要用到的相关库
import pandas as pd
from lightgbm import LGBMRegressor
# 2. 读取训练集和测试集
train = pd.read_csv('./data/data283474/train.csv')
test = pd.read_csv('./data/data283474/test.csv')
# 3. 检查数据
for col in train.columns[:-1]:
if train[col].dtype == object or test[col].dtype == object:
train[col] = train[col].isnull()
test[col] = test[col].isnull()
# 4. 加载决策树模型进行训练
model = LGBMRegressor(verbosity=-1)
model.fit(train.iloc[:, :-1].values, train['target'])
pred = model.predict(test.values)
# 5. 保存结果文件到本地
pd.DataFrame(
{
'id': test['id'],
'dt': test['dt'],
'target': pred
}
).to_csv('LGBMRegressor.csv', index=None)
提交后七百多分哈哈哈哈

但不知道为什么跑出来是同一个房屋的预测值是一样的
既然如此那还不如直接取均值呢
所以就取均值看看
import pandas as pd
# 读取数据
train = pd.read_csv('./data/data283474/train.csv')
test = pd.read_csv('./data/data283474/test.csv')
# 计算train中每个id对应的target的平均值
id_to_mean_target = train.groupby("id")["target"].mean().reset_index()
# 将平均值与test数据集合并
test_with_pred = test.merge(id_to_mean_target, on="id", suffixes=("", "_pred"))
# 以指定格式保存预测结果到CSV文件
result = pd.DataFrame({
'id': test_with_pred['id'],
'dt': test_with_pred['dt'],
'target': test_with_pred['target']
})
result.to_csv('clq_mean.csv', index=False)
提交上去后分数确实也有所提升
后续又改了一些别的方法,XGB什么的,效果不行
所以觉得应该用时序特征一些处理方法
import pandas as pd
import numpy as np
from sklearn.metrics import mean_squared_error
from lightgbm import LGBMRegressor
import lightgbm as lgb
import matplotlib.pyplot as plt
from prophet import Prophet
# 读取数据
train = pd.read_csv('./data/data283474/train.csv')
test = pd.read_csv('./data/data283474/test.csv')
# 数据预处理
train['dt'] = pd.to_datetime(train['dt'], format='%Y%m%d')
train = train.sort_values('dt')
# 特征工程
def feature_engineering(df):
df['year'] = df['dt'].dt.year
df['month'] = df['dt'].dt.month
df['day'] = df['dt'].dt.day
df['weekday'] = df['dt'].dt.weekday
return df
train = feature_engineering(train)
test = feature_engineering(test)
# 使用Prophet提取特征
def extract_prophet_features(df):
df = df[['dt', 'target']]
df.columns = ['ds', 'y']
model = Prophet()
model.fit(df)
future = model.make_future_dataframe(periods=0, freq='D')
forecast = model.predict(future)
return forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()
train_prophet_features = extract_prophet_features(train)
test_prophet_features = extract_prophet_features(test)
# 合并特征
train = pd.merge(train, train_prophet_features, left_on='dt', right_on='ds', how='left')
train = train.drop(columns=['ds'])
test = pd.merge(test, test_prophet_features, left_on='dt', right_on='ds', how='left')
test = test.drop(columns=['ds'])
# 训练LightGBM模型
lgbm = LGBMRegressor()
lgbm.fit(train.drop(columns=['target', 'id', 'type']), train['target'])
# 预测
predictions = lgbm.predict(test.drop(columns=['id', 'type']))
# 计算MSE
mse = mean_squared_error(test['target'], predictions)
print('MSE:', mse)
由于不了解这个方法,还有不清楚时序特征一般怎么处理
我就先放着了,坐等官方baseline学习学习
Baseline尝试

无比丝滑!
核心idea是计算训练数据最近11-20单位时间内对应id的目标均值
Task2尝试

画个图观察目标数据,直观多了

原来还能这么观察数据呢
学到了
重点学习特征工程
历史平移特征、差分特征、和窗口统计特征
- 历史平移特征:通过历史平移获取上个阶段的信息;如下图所示,可以将d-1时间的信息给到d时间,d时间信息给到d+1时间,这样就实现了平移一个单位的特征构建。
- 差分特征:可以帮助获取相邻阶段的增长差异,描述数据的涨减变化情况。在此基础上还可以构建相邻数据比值变化、二阶差分等;
- 窗口统计特征:窗口统计可以构建不同的窗口大小,然后基于窗口范围进统计均值、最大值、最小值、中位数、方差的信息,可以反映最近阶段数据的变化情况。如下图所示,可以将d时刻之前的三个时间单位的信息进行统计构建特征给我d时刻。

跑通task2
优化方向
还有一些可以考虑的优化点来降低MSE:
-
特征工程:
- 考虑添加更多的时间序列特征,如滚动均值、滚动标准差、滚动中位数等。
- 尝试不同的窗口大小,不仅仅是3天的窗口。
- 添加趋势特征,如前n天的斜率。
- 考虑添加周期性特征,如星期几、月份等。
-
模型调优:
- 使用网格搜索或随机搜索来优化LightGBM的超参数。
- 尝试其他模型,如XGBoost、CatBoost,或者尝试模型集成。
-
交叉验证:
- 实现时间序列交叉验证,而不是简单的训练-验证集分割。
-
处理异常值和缺失值:
- 检查并处理可能的异常值。
- 考虑更复杂的缺失值填充方法。
-
特征选择:
- 使用特征重要性来选择最相关的特征。
-
目标变量转换:
- 尝试对目标变量进行对数转换或其他转换,可能会改善模型性能。
-
增加历史数据:
- 如果可能,尝试使用更多的历史数据来创建特征。
-
差分特征:
- 考虑添加差分特征,捕捉变化率。
-
调整学习率:
- 尝试使用学习率衰减策略。
-
增加迭代次数:
- 可能需要增加
early_stopping_rounds和最大迭代次数。
- 可能需要增加
-
尝试不同的评估指标:
- 除了MSE,也可以尝试RMSE或MAE作为评估指标。
-
数据归一化:
- 对某些特征进行归一化处理可能会有帮助。
具体的代码示例。需要逐步实施并评估效果。
- 增加更多的时间序列特征:
# 添加更多的滚动统计特征
for window in [3, 7, 14, 30]:
data[f'rolling_mean_{window}'] = data.groupby('id')['target'].rolling(window=window).mean().reset_index(0,drop=True)
data[f'rolling_std_{window}'] = data.groupby('id')['target'].rolling(window=window).std().reset_index(0,drop=True)
data[f'rolling_median_{window}'] = data.groupby('id')['target'].rolling(window=window).median().reset_index(0,drop=True)
# 添加趋势特征
data['trend'] = data.groupby('id')['target'].diff(periods=1)
# 添加周期性特征
data['day_of_week'] = pd.to_datetime(data['dt']).dt.dayofweek
data['month'] = pd.to_datetime(data['dt']).dt.month
- 特征选择:
from sklearn.feature_selection import SelectKBest, f_regression
def select_features(X, y, k=20):
selector = SelectKBest(score_func=f_regression, k=k)
selector.fit(X, y)
cols = selector.get_support(indices=True)
return X.columns[cols].tolist()
# 在模型训练之前使用
selected_features = select_features(train[train_cols], train['target'])
train_cols = selected_features
- 目标变量转换:
import numpy as np
train['target_log'] = np.log1p(train['target'])
test['target_log'] = np.log1p(test['target'])
# 在预测后需要进行逆变换
test['target'] = np.expm1(lgb_test)
- 实现时间序列交叉验证:
from sklearn.model_selection import TimeSeriesSplit
def time_series_cv(clf, train_df, test_df, cols, n_splits=5):
oof = np.zeros(len(train_df))
predictions = np.zeros(len(test_df))
tscv = TimeSeriesSplit(n_splits=n_splits)
for fold, (train_index, val_index) in enumerate(tscv.split(train_df)):
print(f"Fold {fold + 1}")
trn_x, trn_y = train_df.iloc[train_index][cols], train_df.iloc[train_index]['target']
val_x, val_y = train_df.iloc[val_index][cols], train_df.iloc[val_index]['target']
train_matrix = clf.Dataset(trn_x, label=trn_y)
valid_matrix = clf.Dataset(val_x, label=val_y)
model = clf.train(lgb_params, train_matrix, 50000, valid_sets=[train_matrix, valid_matrix],
categorical_feature=[], verbose_eval=500, early_stopping_rounds=500)
oof[val_index] = model.predict(val_x, num_iteration=model.best_iteration)
predictions += model.predict(test_df[cols], num_iteration=model.best_iteration) / n_splits
score = mean_squared_error(oof, train_df['target'])
print(f"Overall MSE: {score}")
return oof, predictions
lgb_oof, lgb_test = time_series_cv(lgb, train, test, train_cols)
- 调整LightGBM参数:
from sklearn.model_selection import RandomizedSearchCV
from sklearn.model_selection import TimeSeriesSplit
param_dist = {
'num_leaves': [31, 127],
'max_depth': [-1, 5, 8],
'learning_rate': [0.01, 0.1],
'n_estimators': [100, 1000],
'min_child_samples': [5, 10, 20],
'subsample': [0.6, 0.8, 1.0],
'colsample_bytree': [0.6, 0.8, 1.0],
}
tscv = TimeSeriesSplit(n_splits=5)
lgb_model = lgb.LGBMRegressor(random_state=42)
random_search = RandomizedSearchCV(lgb_model, param_distributions=param_dist,
n_iter=100, cv=tscv, verbose=1,
scoring='neg_mean_squared_error', n_jobs=-1)
random_search.fit(train[train_cols], train['target'])
print("Best parameters found: ", random_search.best_params_)
print("Best MSE found: ", -random_search.best_score_)
# 使用最佳参数更新lgb_params
lgb_params.update(random_search.best_params_)
这些优化应该能帮助改善模型性能。但是要逐步实施这些更改,并在每一步评估其对模型性能的影响。同时,要注意避免过拟合,确保模型在测试集上的表现也有相应的提升。
我自己先进一步尝试,等有好的结果再继续写本帖
这是目前我的成绩

任何好的结果都不是一蹴而就的
唯有一次次不断的尝试,总结,提高,才能不断地突破,超越自己
进阶尝试
- 首先,我尝试寻找lgbm的最佳参数
但我try了五六次,都因为超过平台负荷而终止
一开始是500fits至少跑三四个小时都没跑下来
后来改成50fits也没跑下来
所以就手动调参吧!分数有一定提高的
试试别的优化方法先。

可以看到手动调参,因为我缺乏经验,只能瞎调,而且非常耗费时间,效果只提高了一点点
-
增加特征

感觉这个效果应该会很不错
好吧结果效果特别差,一千多分呢 -
交叉验证

浅浅提升了三分
三分也是爱啊
就这样,我继续优化吧!
后面我跑了三折交叉和五折
三折效果太差了
我又重新换回之前的参数
发现五折分数有所提高
所以有一定变动,我们参数不断调整还是可以使得结果有一定改善

当然我们微调参数这一步可能来说没有太大优化空间了
下一步要思考的可以显著提高分数的,可以做一些特征工程优化,正则化
持续更新,今天的提交次数达到上限啦!期待分享交流会大佬们分享进阶方法
Task3终极尝试
使用catboost、xgboost和lightgbm三个模型分别输出三个结果
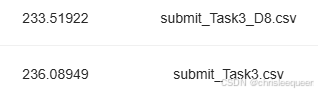
效果有所提升,但提升不多
于是调参修改
迭代到到一万次
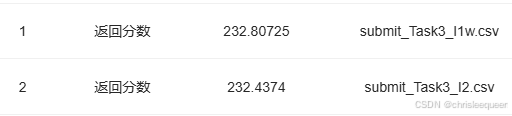
结果来看,可以认为是过拟合了
感觉两千次和一万次效果差不多啊
接着调整参数进行提升

有一种精疲力尽的美感哈哈哈哈哈
期待下一个分享会直播
根据上次baseline进阶1的分享会直播进行调整参数
由于我算力用完了,模型融合需要跑很久,所以这几天在寻找更多的免费算力
感悟
非常开心
参考
参考了官方文档
[1]: https://mp.weixin.qq.com/s/d7dXGYnF4NZuuazktK4SXQ
[2]: https://mp.weixin.qq.com/s/2-V1kFbSzi3Z5UJ7GV_WBw
[3]: https://mp.weixin.qq.com/s/KeD9kPG8PowlKrz69zSHNQ
[4]: https://mp.weixin.qq.com/s/4NSVh1HniNT4CGakzHxm1w
[5]: https://mp.weixin.qq.com/s/JY9RcZ-EquNWdT5k6tLEWg
[6]: https://book.douban.com/subject/35595757/
[7]: https://zhuanlan.zhihu.com/p/67832773


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









