






JFinal的框架的逻辑架构是十分简单的,说更加简单一点,它是简单的经典的MVC模式。
它大致分为6个步骤:
客户端的request和response http请求
JFinalFilter过滤器
Handler请求处理器,对所有的请求进行公共处理
Action动作处理器,先执行拦截器,最后执行具体方法
模型层 在这个层面上包括实体模型的定义,Db+ActiveRecord模式数据库操作的支持,从请求中解析出对应参数构造Model实例,可以理解为DAO层
render 渲染器 负责将服务端的数据组装成客户端需要的数据类型或格式,返回给客户端。
JFinal的运作原理(Web):
通过表单提交数据
JFinalFilter拦截后调用Handler处理,执行ActionHandler
ActionHandler根据请求的target从缓存的ActionMapping中获取映射的Action对象
通过Action对象获得在Controller中相映射的Method
从request中获取参数 进行model处理
数据库操作
渲染视图 render页面
打完收工!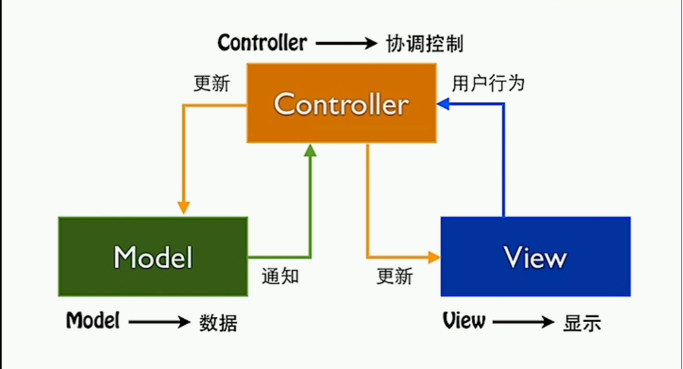

















 587
587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









