



 本文深入探讨Dubbo服务治理技术,涵盖服务注册、发现、负载均衡、容错及降级机制。同时,剖析Dubbo源码,解读SPI机制、服务消费与发布流程,以及性能参数调优策略。
本文深入探讨Dubbo服务治理技术,涵盖服务注册、发现、负载均衡、容错及降级机制。同时,剖析Dubbo源码,解读SPI机制、服务消费与发布流程,以及性能参数调优策略。
Dubbo
初步认识dubbo及基本应用
官方网址:http://dubbo.apache.org
由于业务的复杂度公司服务不断增多,那么远程服务之 间的调用才是实现分布式的关键因素。
服务与服务之间的调用无非 就是跨进程通信而已,我们可以使用 socket 来实现通信,我们也可以使用 nio来实现高性能通信。我们不用这些开源的RPC框架,也可以完成通信的过程。
官方图解: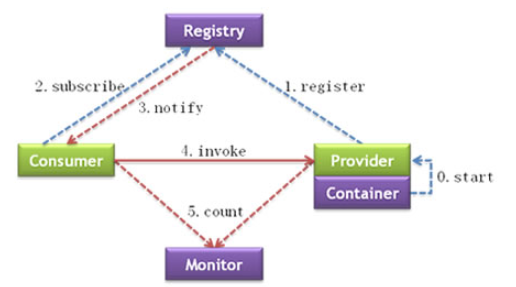
图解说明:
| 节点 | 角色说明 |
|---|---|
Provider | 暴露服务的服务提供方 |
Consumer | 调用远程服务的服务消费方 |
Registry | 服务注册与发现的注册中心 |
Monitor | 统计服务的调用次数和调用时间的监控中心 |
Container | 服务运行容器 |
但是为什么要用现成的框架呢?
1. 底层网络通信协议的处理 ;
2. 序列化和反序列化的处理工作 ;
3. 网络请求之间的负载均衡、容错机制、服务降级机制等等要一一处理太麻烦;
大规模服务化对于服务治理的要求 ?
我认为到目前为止,还只是满足了通信的基础需求,但是当企业开始大规模 的服务化以后,远程通信带来的弊端就越来越明显了。比如说
1. 服务链路变长了,如何实现对服务链路的跟踪和监控呢?
2. 服务的大规模集群使得服务之间需要依赖第三方注册中心来解决服务的 发现和服务的感知问题
3. 服务通信之间的异常,需要有一种保护机制防止一个节点故障引发大规模 的系统故障,所以要有容错机制
4. 服务大规模集群会是的客户端需要引入负载均衡机制实现请求分发
而这些对于服务治理的要求,传统的 RPC 技术在这样的场景中显得有点力 不从心,因此很多企业开始研发自己的RPC框架,比如阿里的HSF、Dubbo; 京东的JSF框架、当当的dubbox、新浪的motan、蚂蚁金服的sofa等等 又技术输出能力的公司,都会研发适合自己场景的rpc框架,要么是从0到 1 开发,要么是基于现有的思想结合公司业务特色进行改造。而没有技术输 出能力的公司,遇到服务治理的需求时,会优先选择那些比较成熟的开源框架。而Dubbo就是其中一个 。
分析Dubbo服务治理技术
基于注册中心的dubbo服务
作为主流的服务治理组件,Dubbo 提供了很多丰富的功能,那么最根本的就是要解决大规模集群之后的服务注册和发现的问题。而 dubbo中对于注 册中心这块是使用zookeeper来支撑的。当然在目前最新的版本中。 Dubbo能够支持的注册中心有:consul、etcd、nacos、sofa、zookeeper、 redis、multicast 。
使用zookeeper作为注册中心的jar包依赖
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.0.0</version>
</dependency>
dubbo集成zookeeper的实现原理图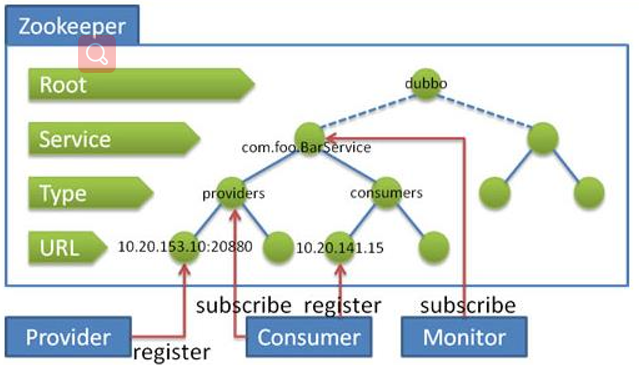
provider将自己的接口服务注册在zookeeper节点中,节点上包含了provider的url、接口、以及一些其他的配置信息(协议,负载均衡机制,容错机制,序列化等),当consumer要请求接口时,通过接口路径在zookeeper中拿到url和配置信息,根据配置信息访问接口拿到数据。
dubbo 每次都要连 zookeeper拿数据?
并不需要,dubbo会拿到zookeeper上数据缓存在本地,只要zookeeper上的节点数据不发生改变,dubbo会优先读取本地缓存数据,所以当启动一段时间即使zookeeper服务挂了也不影响dubbo的使用。
负载均衡机制
dubbo集成zookeeper解决了服务注册以及服务动态感知的问题。那么 当服务端存在多个节点的集群时,zookeeper 上会维护不同集群节点,对于客户端而 言,他需要一种负载均衡机制来实现目标服务的请求负载。
在服务端配置:
1.配置文件配置—<dubbo:service interface="..." loadbalance="roundrobin" />
2.注解配置—@Service(loadbalance = "roundrobin")
public class HelloServiceImpl implements IHelloService{
在客户端配置(客户端配置优先级大于服务端):
1.配置文件配置—<dubbo:reference interface="..." loadbalance="roundrobin" />
2.注解配置—@Reference(loadbalance = "random")
private IHelloService helloService;
在java客户端中用下面四种英文表示 roundrobin/random/ leastactive/ consistenthash ,分别对应一下四种
RoundRobinLoadBalance:加权轮询算,按公约后的权重设置轮循比率。所谓轮询是指将请求轮流分配给每台服务器。举个例子,我们有三台服务器 A、 B、C。 我们将第一个请求分配给服务器 A,第二个请求分配给服务器 B,第三个请求分配给 服务器 C,第四个请求再次分配给服务器 A。这个过程就叫做轮询。轮询是一种无状 态负载均衡算法,实现简单,适用于每台服务器性能相近的场景下。但现实情况下, 我们并不能保证每台服务器性能均相近。如果我们将等量的请求分配给性能较差的服 务器,这显然是不合理的。因此,这个时候我们需要对轮询过程进行加权,以调控每 台服务器的负载。经过加权后,每台服务器能够得到的请求数比例,接近或等于他们 的权重比。比如服务器 A、B、C 权重比为 5:2:1。那么在 8 次请求中,服务器 A 将 收到其中的 5 次请求,服务器 B 会收到其中的 2 次请求,服务器 C 则收到其中的 1次请求。
RandomLoadBalance:随机权重算法,根据配置的的weight属性,占总的weights的百分比进行按比重分配。假设我们有一组服务器 servers = [A, B, C],他们对应的权重为 weights = [5, 3, 2],权重总和为10。随机一个[0,10)的数字,比如说8,把8减去A,如果大于等于0(结果3>0),拿结果3-B还是大于等于0,以此类推,直到相减结果小于0,得到此时的服务器,也就是C。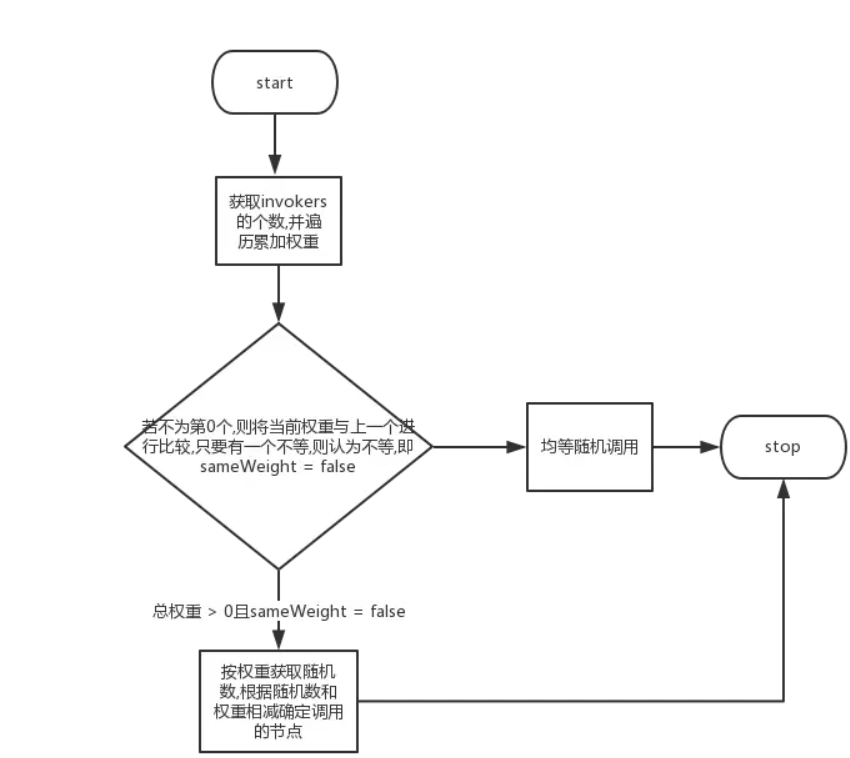
LeastActiveLoadBalance:最少活跃数算法,每个服务维护一个活跃数计数器。当A机器开始处理请求,该计数器加1,此时A还未处理完成。若处理完毕则计数器减1。而B机器接受到请求后很快处理完毕。那么A,B的活跃数分别是1,0。当又产生了一个新的请求,则选择B机器去执行(B活跃数最小),这样使慢的机器A收到少的请求。因此活跃数下降的也越快,此时这样的服 务提供者能够优先获取到新的服务请求。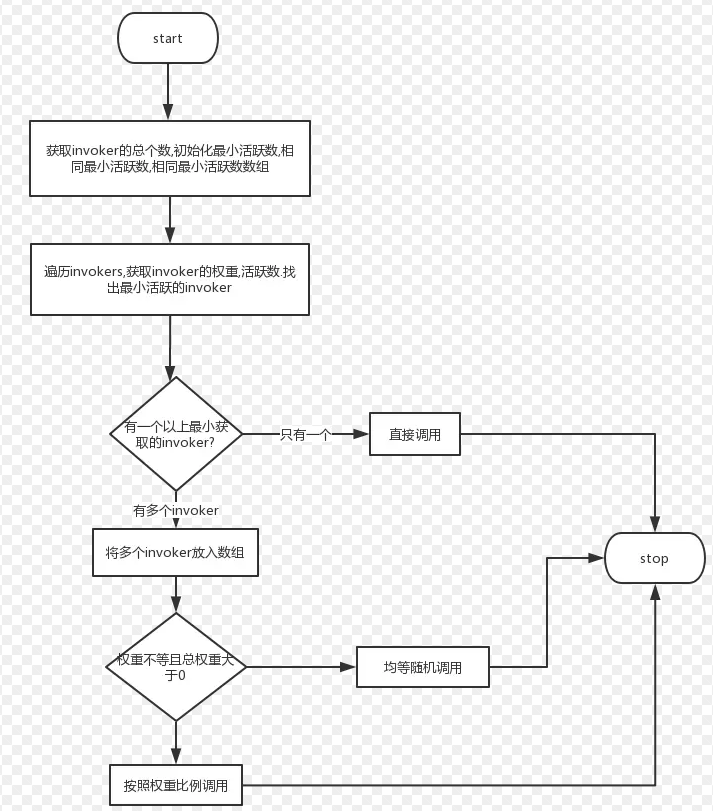
ConsistentHashLoadBalance:hash一致性算法,能使相同参数数据发送到同一台机器上。(默认只对第一个参数 Hash,默认160份虚拟节点)当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动+。假如有N个真实节点,把每个真实节点映射成M个虚拟节点,再把 M*N 个虚拟节点, 散列在圆环上. 各真实节点对应的虚拟节点相互交错分布这样,某真实节点down后,则把其影响平均分担到其他所有节点上。例如:也就是a,b,c,d的虚拟节点a0,a1,a2,b0,b1,b2,c0,c1,c2,d0,d1,d2散落在圆环上,假设C号节点down,则c0,c1,c2的压力分别传给d0,a1,b1,如下图:
集群容错机制
在java中配置方式:@Service(loadbalance = "random", cluster = "failsafe")
Faiover Cluster:默认的容错机制,当client集群调用失败时,重试其他的服务器。可通过retries=2来设置重试次数。
Failfast Cluster:快速失败,只发起一次调用,失败立即报错,用于非幂等性的写操作。
Failsafe Cluster:失败安全,出现异常时,直接忽略,通常用了写入日志操作。
Failback Cluster:失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知。
Forking Cluster:并行调用多个服务器,只要一个返回成功即返回。
Broadcast Cluster:广播调用所有提供者,依次调用,任意一条报错则宝座
服务降级
当某个非关键服务出现错误时,可以通过降级功能来临时屏蔽这个服务。
实现如下:在dubbo-client端创建一个mock类,当出现服务降级时,会被调用
@Reference( loadbalance = "random", mock = "自己实现的mock类", timeout =1000, cluster = "failfast")
IHelloService helloService;
动态配置以及规则
动态配置是Dubbo2.7版本引入的一个新的功能,简单来说,就是把dubbo.properties 中的属性进行集中式存储,存储在其他的服务器上。 那么如果需要用到集中式存储,那么还需要一些配置中心的组件来支撑。 目前Dubbo能支持的配置中心有:apollo、nacos、zookeeper 。外部配置的优先级大于本地配置。
原理:默认所有的配置都存储在/dubbo/config节点,具体节点结构图如下namespace,用于不同配置的环境隔离。 config,Dubbo 约定的固定节点,不可更改,所有配置和服务治理规则都存储在此节点下。
dubbo/application:分别用来隔离全局配置;
dubbo:应用级别配置:dubbo是默认group值;
application:对应应用名 dubbo.properties,此节点的node value存储具体配置内容 ;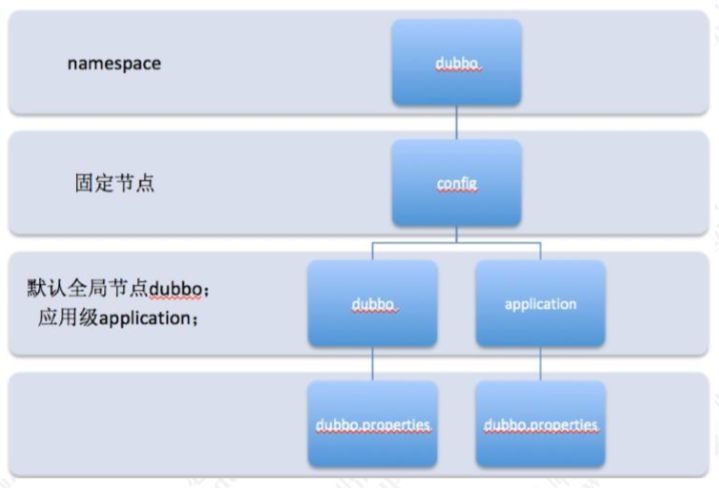
元数据中心
dubbo2.7所有的信息(接口名称、url、版本、负载均衡、容错策略等等),server配置参数有30多个,client配置有25个以上。全部在zookeeper上会造成以下问题:
1.url内容过多,导致数据存储空间增大;
2.url需要涉及到网络传输,数据量过大会造成网络传输慢;
3.网络传输慢造成服务地址感知延迟变大,影响服务正常响应;
元数据中心目前支持redis和zookeeper。官方推荐是采用redis。毕竟redis本身对于 非结构化存储的数据读写性能比较高。当然,也可以使用zookeeper来实现。 在配置文件中添加元数据中心的地址
dubbo.metadata-report.address=zookeeper://192.168.13.106:2181
dubbo.registry.simplified=true //注册到注册中心的URL是否采用精简模式的
分析Dubbo源码之内核—SPI
Dubbo SPI(面试dubbo必问)
java spi的实现
我们如何去实现一个标准的 SPI 发现机制呢?其实很简单,只需要满足以下提交就行了
1. 需要在 classpath 下创建一个目录,该目录命名必须是:META-INF/service
2. 在该目录下创建一个 properties 文件,该文件需要满足以下几个条件
2.1 文件名必须是扩展的接口的全路径名称;
2.2 文件内部描述的是该扩展接口的所有实现类;
2.3 文件的编码格式是 UTF-8;
3. 通过 java.util.ServiceLoader 的加载机制来发现
读取META-INF/services/下的配置文件,获得所有能被实例化的类的名称,值得注意的是,ServiceLoader可以跨越jar包获取META-INF下的配置文件。
通过反射方法Class.forName()加载类对象,并用instance()方法将类实例化。
把实例化后的类缓存到providers对象中,(LinkedHashMap<String,S>类型)然后返回实例对象。
java在jdk加载java.sql.Driver的接口实现类的时候就会得到mysql的Driver,然后根据DriverManager.getConnection方法判断得到正确的数据库连接。
java SPI 的缺点 :
1. JDK 标准的 SPI 会一次性加载实例化扩展点的所有实现—就是如果你在 META-INF/service 下的文件里面加了 N 个实现类,那么 JDK 启动的时候都会一次性全部加载。那么如果有的扩展点实现初始化很耗时或者如果有些实现类并没有用到, 那么会很浪费资源。
2. 如果扩展点加载失败,会导致调用方报错,而且这个错误很难定位到是这个原因。
3.java中是serverLoad上下文加载器加载的,而dubbo中是ExtensionLoader扩展加载器加载的。
dubbo SPI
实现:
1. 需要在 resource 目录下配置 META-INF/dubbo 或者 META-INF/dubbo/internal 或者 META-INF/services,并基于 SPI 接口去 创建一个文件 ,能够被扩展的接口必须要有@SPI("value")注解。value表示当前扩展点的默认实现。
2. 文件名称和接口名称保持一致,文件内容和 SPI 有差异,内容是 KEY 对应 Value ,key随便定义,value名必须是文件名接口自定义实现类。
Dubbo 针对的扩展点非常多,可以针对协议、拦截、集群、路由、负载均衡、序列化、容器… 几乎里面用到的所有功能,都可 以实现自己的扩展,我觉得这个是 dubbo 比较强大的一点。
例如:
1. 创建如下结构,添加 META-INF.dubbo 文件。类名和 Dubbo 提供的协议扩展点接口保持一致:

2.创建 MyProtocol 协议类可以实现自己的协议,我们为了模拟协议产生了作用,修改一个端口 :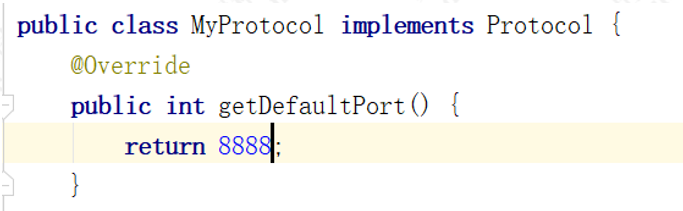
3.调用加载:
Protocol protocol=ExtensionLoader.getExtensionLoader(Protocol.class).getExtension("myProtocol");
System.out.print(protocol.getDefaultPort) ;//可以看到是输出自己的协议端口。
静态扩展点源码实现:
//类得到扩展点加载器
@SuppressWarnings("unchecked")
public static <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) {
if (type == null) {
throw new IllegalArgumentException("Extension type == null");
}
if (!type.isInterface()) {
throw new IllegalArgumentException("Extension type (" + type + ") is not an interface!");
}
if (!withExtensionAnnotation(type)) {
throw new IllegalArgumentException("Extension type (" + type +
") is not an extension, because it is NOT annotated with @" + SPI.class.getSimpleName() + "!");
}
//去缓存ConcurrentMap中找这个类型加载器
ExtensionLoader<T> loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
if (loader == null) {
EXTENSION_LOADERS.putIfAbsent(type, new ExtensionLoader<T>(type));//如果没有new一个放进缓存并且返回
loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
}
return loader;
}
//创建扩展类实例
@SuppressWarnings("unchecked")
public T getExtension(String name) {
if (StringUtils.isEmpty(name)) {
throw new IllegalArgumentException("Extension name == null");
}
if ("true".equals(name)) {
return getDefaultExtension();//获取默认的扩展类实例
}
Holder<Object> holder = getOrCreateHolder(name);//缓存取值
Object instance = holder.get();
if (instance == null) {
synchronized (holder) {
instance = holder.get();
if (instance == null) {
instance = createExtension(name);//创建一个name=key 对应的实例
holder.set(instance);
}
}
}
return (T) instance;
}
//创建扩展类实例继续
@SuppressWarnings("unchecked")
private T createExtension(String name) {
//重点在这里,找指定目录下 META-INF/dubbo 或者 META-INF/dubbo/internal 或者 META-INF/services反射找到所有类class根据name得到class。
Class<?> clazz = getExtensionClasses().get(name);
if (clazz == null) {
throw findException(name);
}
try {
T instance = (T) EXTENSION_INSTANCES.get(clazz);缓存中取
if (instance == null) {
EXTENSION_INSTANCES.putIfAbsent(clazz, clazz.newInstance());//放缓存
instance = (T) EXTENSION_INSTANCES.get(clazz);
}
//依赖注入:向拓展对象中注入依赖,它会获取类的所有方法。判断方法是否以 set 开头,且方法仅有一个参数,且方法访问级别为 public,就通过反射设置属性值。所以说,Dubbo中的IOC仅支持以setter方式注入。
injectExtension(instance);
Set<Class<?>> wrapperClasses = cachedWrapperClasses;
if (CollectionUtils.isNotEmpty(wrapperClasses)) {
for (Class<?> wrapperClass : wrapperClasses) {
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
return instance;
} catch (Throwable t) {
throw new IllegalStateException("Extension instance (name: " + name + ", class: " +
type + ") couldn't be instantiated: " + t.getMessage(), t);
}
}
自适应扩展点源码实现:
在Dubbo中,很多拓展都是通过 SPI 机制进行加载的,比如 Protocol、Cluster、LoadBalance 等。这些扩展并非在框架启动阶段就被加载(jdk是启动就加载所有扩展),而是在扩展方法被调用的时候,根据URL对象参数进行加载。那么,Dubbo就是通过自适应扩展机制来解决这个问题——首先 Dubbo 会为拓展接口生成具有代理功能的代码。然后通过 javassist 或 jdk 编译这段代码,得到 Class 类。最后再通过反射创建代理类,在代理类中,就可以通过URL对象的参数来确定到底调用哪个实现类。自适应注解:@Adaptive
@Adaptive写在类上:当前类是一个确定的自适应扩展点的类,Dubbo 不会为该类生成代理类;
@Adaptive写在方法上:Dubbo 则会为该方法生成代理逻辑,表示当前方法需要根据 参数URL 调用对应的扩展点实现;
//源码实现
public T getAdaptiveExtension() {
// 从缓存中获取自适应拓展
Object instance = cachedAdaptiveInstance.get();
if (instance == null) {
if (createAdaptiveInstanceError == null) {
synchronized (cachedAdaptiveInstance) {
instance = cachedAdaptiveInstance.get();
//未命中缓存,则创建自适应拓展,然后放入缓存
if (instance == null) {
try {
instance = createAdaptiveExtension();
cachedAdaptiveInstance.set(instance);
} catch (Throwable t) {
createAdaptiveInstanceError = t;
throw new IllegalStateException("fail to create
adaptive instance: " + t.toString(), t);
}
}
}
}
}
return (T) instance;
}
//缓存中没有就创建
private T createAdaptiveExtension() {
try {
return injectExtension((T) getAdaptiveExtensionClass().newInstance());
} catch (Exception e) {
throw new IllegalStateException("
Can not create adaptive extension " + type + ", cause: " + e.getMessage(), e);
}
}
private Class<?> getAdaptiveExtensionClass() {
//获取当前接口的所有实现类
//如果某个实现类标注了@Adaptive,此时cachedAdaptiveClass不为空
getExtensionClasses();
if (cachedAdaptiveClass != null) {
return cachedAdaptiveClass;
}
//以上条件不成立,就创建自适应拓展类
return cachedAdaptiveClass = createAdaptiveExtensionClass();
}
//@Adaptive注解在方法上,需要代理一个类,默认用javassist。接口方法上有@Adaptive会有代理实现,没有的则抛出异常
private Class<?> createAdaptiveExtensionClass() {
//构建自适应拓展代码
String code = createAdaptiveExtensionClassCode();
ClassLoader classLoader = findClassLoader();
// 获取编译器实现类 这个Dubbo默认是采用javassist
Compiler compiler =ExtensionLoader.getExtensionLoader(Compiler.class).getAdaptiveExtension();
//编译代码,返回类实例的对象
return compiler.compile(code, classLoader);
}
实现例子:
//我们还是以Protocol接口为例,它的export()和refer()方法,都标注为@Adaptive。destroy和 getDefaultPort未标注 @Adaptive注解。Dubbo 不会为没有标注 Adaptive 注解的方法生成代理逻辑,对于该种类型的方法,仅会生成一句抛出异常的代码。
@SPI("dubbo")
public interface Protocol {
int getDefaultPort();
@Adaptive
<T> Exporter<T> export(Invoker<T> invoker) throws RpcException;
@Adaptive
<T> Invoker<T> refer(Class<T> type, URL url) throws RpcException;
void destroy();
}
//所以说当我们调用这两个方法的时候,会先拿到URL对象中的协议名称,再根据名称找到具体的扩展点实现类,然后去调用。下面是生成自适应扩展类实例的源代码:
public class Protocol$Adaptive implements Protocol {
public void destroy() {
throw new UnsupportedOperationException(
"method public abstract void Protocol.destroy() of interface Protocol is not adaptive method!");
}
public int getDefaultPort() {
throw new UnsupportedOperationException(
"method public abstract int Protocol.getDefaultPort() of interface Protocol is not adaptive method!");
}
public Exporter export(Invoker invoker)throws RpcException {
if (invoker == null) {
throw new IllegalArgumentException("Invoker argument == null");
}
if (invoker.getUrl() == null) {
throw new IllegalArgumentException("Invoker argument getUrl() == null");
}
URL url = invoker.getUrl();
//默认dubbo协议
String extName = (url.getProtocol() == null ? "dubbo" : url.getProtocol());
if (extName == null) {
throw new IllegalStateException("Fail to get extension(Protocol) name from url("
+ url.toString() + ") use keys([protocol])");
}
//默认dubbo协议,也可以自定义协议
Protocol extension = ExtensionLoader.getExtensionLoader(Protocol.class).getExtension(extName);
return extension.export(invoker);
}
public Invoker refer(Class clazz,URL ur)throws RpcException {
if (ur == null) {
throw new IllegalArgumentException("url == null");
}
URL url = ur;
String extName = (url.getProtocol() == null ? "dubbo" : url.getProtocol());
if (extName == null) {
throw new IllegalStateException("Fail to get extension(Protocol) name from url("+ url.toString() + ") use keys([protocol])");
}
Protocol extension = ExtensionLoader.getExtensionLoader(Protocol.class).getExtension(extName);
return extension.refer(clazz, url);
}
}
分析Dubbo源码之服务消费
服务发布(三步:读取配置文件—服务注册到zookeeper—启动netty服务监听)
1.配置文件解析或注释解析
在 spring 中定义了两个接口
NamespaceHandler: 注册一堆 BeanDefinitionParser,利用他们来进行解析
BeanDefinitionParser:用于解析每个 element 的内容
Spring 默认会加载 jar 包下的 META-INF/spring.handlers 文件寻找对应的 NamespaceHandler。 Dubbo-config 模块下的 dubboconfig-spring。Dubbo 中 spring 扩展就是使用 spring 的自定义类型,所以同样也有 NamespaceHandler、BeanDefinitionParser。而 NamespaceHandler 是 DubboNamespaceHandler ,
public class DubboNamespaceHandler extends NamespaceHandlerSupport {
static {
Version.checkDuplicate(DubboNamespaceHandler.class);
}
@Override
public void init() {
registerBeanDefinitionParser("application", new DubboBeanDefinitionParser(ApplicationConfig.class, true));
registerBeanDefinitionParser("module", new DubboBeanDefinitionParser(ModuleConfig.class, true));
registerBeanDefinitionParser("registry", new DubboBeanDefinitionParser(RegistryConfig.class, true));
registerBeanDefinitionParser("config-center", new DubboBeanDefinitionParser(ConfigCenterBean.class, true));
registerBeanDefinitionParser("metadata-report", new DubboBeanDefinitionParser(MetadataReportConfig.class, true));
registerBeanDefinitionParser("monitor", new DubboBeanDefinitionParser(MonitorConfig.class, true));
registerBeanDefinitionParser("metrics", new DubboBeanDefinitionParser(MetricsConfig.class, true));
registerBeanDefinitionParser("provider", new DubboBeanDefinitionParser(ProviderConfig.class, true));
registerBeanDefinitionParser("consumer", new DubboBeanDefinitionParser(ConsumerConfig.class, true));
registerBeanDefinitionParser("protocol", new DubboBeanDefinitionParser(ProtocolConfig.class, true));
registerBeanDefinitionParser("service", new DubboBeanDefinitionParser(ServiceBean.class, true));
registerBeanDefinitionParser("reference", new DubboBeanDefinitionParser(ReferenceBean.class, false));
registerBeanDefinitionParser("annotation", new AnnotationBeanDefinitionParser());
}
}
BeanDefinitionParser 全部都使用了 DubboBeanDefinitionParser,如果我们想看 dubbo:service 的配置,就直接看 DubboBeanDefinitionParser(ServiceBean.class,true) 这个里面主要做了一件事,把不同的配置分别转化成 spring 容器中的 bean 对象 :
application 对应 ApplicationConfig
registry 对应 RegistryConfig
monitor 对应 MonitorConfig
provider 对应 ProviderConfig
consumer 对应 ConsumerConfig
涉及到服务发布和服务调用的两个配置的解析,用的是 ServiceBean 和 referenceBean。并不是 config 结尾 的,这两个类稍微特殊些,当然他同时也继承了 ServiceConfig 和 ReferenceConfig registerBeanDefinitionParser("service", new DubboBeanDefinitionParser(ServiceBean.class, true));
registerBeanDefinitionParser("reference", new DubboBeanDefinitionParser(ReferenceBean.class, false));
DubboBeanDefinitionParser
这里面是实现具体配置文件解析的入口,它重写了 parse 方法,对 spring 的配置进行解析。我们关注一下 ServiceBean 的解析. 实际就是解析 dubbo:service 这个标签中对应的属性 。
else if (ServiceBean.class.equals(beanClass)) {
String className = element.getAttribute("class");
if (className != null && className.length() > 0) {
RootBeanDefinition classDefinition = new RootBeanDefinition();
classDefinition.setBeanClass(ReflectUtils.forName(className));
classDefinition.setLazyInit(false);
parseProperties(element.getChildNodes(), classDefinition);
beanDefinition.getPropertyValues().addPropertyValue("ref", new BeanDefinitionHolder(classDefinition, id + "Impl"));
}
}
ServiceBean
ServiceBean 这个类,分别实现了 InitializingBean, DisposableBean, ApplicationContextAware, ApplicationListener, BeanNameAware, ApplicationEventPublisherAware :
InitializingBean:接口为 bean 提供了初始化方法的方式,它只包括 afterPropertiesSet 方法,凡是继承该接口的类,在初始化 bean 的时候会执行 该方法。被重写的方法为 afterPropertiesSet。
DisposableBean:被重写的方法为 destroy,bean 被销毁的时候,spring 容器会自动执行 destory 方法,比如释放资源。
ApplicationContextAware:实现了这个接口的 bean,当 spring 容器初始化的时候,会自动的将 ApplicationContext 注入进来 。
ApplicationListener:ApplicationEvent 事件监听,spring 容器启动后会发一个事件通知。被重写的方法为:onApplicationEvent,onApplicationEvent 方法传入的对象是 ContextRefreshedEvent。这个对象是当 Spring 的上下文被刷新或者加载完毕的时候触发的。因此服务就是在 Spring 的上下文刷新后进行导出操作的。
BeanNameAware:获得自身初始化时,本身的 bean 的 id 属性,被重写的方法为 setBeanName 。
ApplicationEventPublisherAware:这个是一个异步事件发送器。被重写的方法为 setApplicationEventPublisher,简单来说,在 spring 里面提供了类似于消息队列 的异步事件解耦功能。(典型的观察者模式的应用)。
2.服务注册
在 ServiceBean 中,我们暂且只需要关注两个方法,分别是:
在初始化 bean 的时候会执行该方法 afterPropertiesSet——把 dubbo 中配置的 application、registry、service、protocol 等信息,加载到对应的 config 实体中,便于后续的使用;
spring 容器启动后会发一个事件通知 onApplicationEvent——用调用 export 进行服务发布的流程(这里就是入口) ;
export 方法
serviceBean 中,重写了 export 方法,实现了 一个事件的发布。并且调用了 super.export() ,也就是会调用父类ServiceConfig 的 export 方法 。
public synchronized void export() {
checkAndUpdateSubConfigs(); // 检查并且更新配置信息
if (!shouldExport()) {// 当前的服务是否需要发布 , 通过配置实现: @Service(export = false)
return;
}
if (shouldDelay()) {// 检查是否需要延时发布,通过配置 @Service(delay = 1000) 实现,单位毫秒
delayExportExecutor.schedule(this::doExport, getDelay(), TimeUnit.MILLISECONDS); //定时器延时
} else {
doExport();
}
}
protected synchronized void doExport() {
if (unexported) {
throw new IllegalStateException("The service " + interfaceClass.getName() + " has already unexported!");
}
if (exported) {//服务已经注册
return;
}
exported = true;//设置已经注册状态
if (StringUtils.isEmpty(path)) {//path表示服务路径,默认使用 interfaceName
path = interfaceName;
}
doExportUrls();
}
/**1. 记载所有配置的注册中心地址
*2. 遍历所有配置的协议,protocols
*3. 针对每种协议发布一个对应协议的服务
*/
private void doExportUrls() {
// 加载所有配置的注册中心的地址,组装成一个 URL (registry://ip:port/org.apache.dubbo.registry.RegistryService的东西 )
List<URL> registryURLs = loadRegistries(true);
for (ProtocolConfig protocolConfig : protocols) {
//group跟 version组成一个 pathKey(serviceName)
String pathKey = URL.buildKey(getContextPath(protocolConfig).map(p -> p + "/" + path).orElse(path), group, version);
//applicationModel用来存储 ProviderModel ,发布的服务的元数据,后续会用到
ProviderModel providerModel = new ProviderModel(pathKey, ref, interfaceClass);
ApplicationModel.initProviderModel(pathKey, providerModel);
doExportUrlsFor1Protocol(protocolConfig, registryURLs);
}
}
doExportUrlsFor1Protocol
发布指定协议的服务,我们以 Dubbo 服务为例
1. 前面的一大串 if else 代码,是为了把当前服务下所配置的<dubbo:method>参数进行解析,保存到 map 集合中
2. 获得当前服务需要暴露的 ip 和端口
3. 把解析到的所有数据,组装成一个 URL,大概应该是: dubbo://192.168.13.1:20881/com.yaoxiaojian.dubbo.service.ISayHelloService
private void doExportUrlsFor1Protocol(ProtocolConfig protocolConfig, List<URL> registryURLs) {
...
...
// 获得当前服务要发布的目标 ip 和 port
String host = this.findConfigedHosts(protocolConfig, registryURLs, map);
Integer port = this.findConfigedPorts(protocolConfig, name, map);
// 组装 URL
URL url = new URL(name, host, port, getContextPath(protocolConfig).map(p -> p + "/" + path).orElse(path), map);
// 这里是通过 ConfiguratorFactory 去实现动态改变配置的功能,这里暂时不涉及后续再分析
if (ExtensionLoader.getExtensionLoader(ConfiguratorFactory.class).hasExtension(url.getProtocol())) {
url = ExtensionLoader.getExtensionLoader(ConfiguratorFactory.class).getExtension(url.getProtocol()).getConfigurator(url).configure(url);
}
//上面代码均是对url的解析和组装。
//如果 scope!="none"则发布服务,默认 scope 为 null。如果 scope 不为 none,判断是否为 local 或 remote,从而发布 Local 服务 或 Remote 服务,默认两个都会发布
String scope = url.getParameter(SCOPE_KEY);
if(!SCOPE_NONE.equalsIgnoreCase(scope)) {
//injvm 发布到本地
if (!SCOPE_REMOTE.equalsIgnoreCase(scope)) {
exportLocal(url);
}
// 发布远程服务
if (!SCOPE_LOCAL.equalsIgnoreCase(scope)) {
....
....
Invoker<?> invoker = proxyFactory.getInvoker(ref, (Class) interfaceClass, registryURL.addParameterAndEncoded(EXPORT_KEY, url.toFullString()));
DelegateProviderMetaDataInvoker wrapperInvoker = new DelegateProviderMetaDataInvoker(invoker, this);
//protocol是自适应扩展点,wrapperInvoker是registry:// 所以这边调用得是 registryProtocol.export这个方法
Exporter<?> exporter = protocol.export(wrapperInvoker);
exporters.add(exporter);
}
RegistryProtocol.export 方法
很明显,这个 RegistryProtocol 是用来实现服务注册的,这里面会有很多处理逻辑:
1.实现对应协议的服务发布
2.实现服务注册
3.订阅服务重写
public <T> Exporter<T> export(final Invoker<T> originInvoker) throws RpcException {
//这里获得的是 zookeeper注册中心的 url: zookeeper://ip:port
URL registryUrl = getRegistryUrl(originInvoker);
// 这里是获得服务提供者的 url, dubbo://ip:port...
URL providerUrl = getProviderUrl(originInvoker);
// 订阅 override数据。在 admin控制台可以针对服务进行治理,比如修改权重,修改路由机制等,当注册中心有此服务的覆盖配置 注册进来时,推送消息给提供者,重新暴露服务
final URL overrideSubscribeUrl = getSubscribedOverrideUrl(providerUrl);
final OverrideListener overrideSubscribeListener = new OverrideListener(overrideSubscribeUrl, originInvoker);
overrideListeners.put(overrideSubscribeUrl, overrideSubscribeListener);
providerUrl = overrideUrlWithConfig(providerUrl, overrideSubscribeListener);
//************************** // 这里就交给了具体的协议去暴露服务(很重要),启动一个netty服务
final ExporterChangeableWrapper<T> exporter = doLocalExport(originInvoker, providerUrl);
//*********把dubbo注册到zookeeper上,创建一个zookeeperclient创建dubbo://ip:port/com...这样的节点
final Registry registry = getRegistry(originInvoker);
final URL registeredProviderUrl = getRegisteredProviderUrl(providerUrl, registryUrl);
ProviderInvokerWrapper<T> providerInvokerWrapper = ProviderConsumerRegTable.registerProvider(originInvoker,
registryUrl, registeredProviderUrl);
//to judge if we need to delay publish
boolean register = registeredProviderUrl.getParameter("register", true);
if (register) {
register(registryUrl, registeredProviderUrl);
providerInvokerWrapper.setReg(true);
}
// Deprecated! Subscribe to override rules in 2.6.x or before.
registry.subscribe(overrideSubscribeUrl, overrideSubscribeListener);
exporter.setRegisterUrl(registeredProviderUrl);
exporter.setSubscribeUrl(overrideSubscribeUrl);
//Ensure that a new exporter instance is returned every time export
return new DestroyableExporter<>(exporter);
}
doLocalExport
先通过 doLocalExport 来暴露一个服务,本质上应该是启动一个通信服务,主要的步骤是将本地 ip 和 20880 端口打开,进行监听 :
originInvoker: 应该是 registry://ip:port/com.alibaba.dubbo.registry.RegistryService
key: 从 originInvoker 中获得发布协议的 url: dubbo://ip:port/...
bounds: 一个 prviderUrl 服务 export 之后,缓存到 bounds 中,所以一个 providerUrl 只会对应一个 exporter
private <T> ExporterChangeableWrapper<T> doLocalExport(final Invoker<T> originInvoker, URL providerUrl) {
String key = getCacheKey(originInvoker);
return (ExporterChangeableWrapper<T>) bounds.computeIfAbsent(key, s -> {
// 对原有的 invoker, 委托给了 InvokerDelegate
Invoker<?> invokerDelegate = new InvokerDelegate<>(originInvoker, providerUrl);
// 将 invoker转换为 exporter并启动 netty服务,自适应拓展点 调用的是DubboProtocol.export?其实是在自适应扩展点中包装成了QosProtocolWrapper(ProtocolListenerWrapper(ProtocolFilterWrapper(DubboProtocol)))),为了对原有的invoker进行增强,比如filter——在实现远程调用的时候,会经过这些 filter 进行过滤。
return new ExporterChangeableWrapper<>((Exporter<T>) protocol.export(invokerDelegate), originInvoker);
});
}
DubboProtocol.export
基于动态代理的适配,很自然的就过渡到了 DubboProtocol 这个协议类中,但是实际上是 DubboProtocol 吗?
这里并不是获得一个单纯的 DubboProtocol 扩展点,而是会通过 Wrapper 对 Protocol 进行装饰,装饰器分别为: QosProtocolWrapper/ProtocolListenerWrapper/ProtocolFilterWrapper/DubboProtocol 为什么是这样?我们再来看看 spi 的代码
Wrapper 包装
在 ExtensionLoader.loadClass 这个方法中,有一段这样的判断,如果当前这个类是一个 wrapper 包装类,也就是这个 wrapper 中有构造方法,参数是当前被加载的扩展点的类型,则把这个 wrapper 类加入到 cacheWrapperClass 缓存中。
else if (isWrapperClass(clazz)) {
cacheWrapperClass(clazz);
}
我们可以在 dubbo 的配置文件中找到三个 Wrapper :
qos=org.apache.dubbo.qos.protocol.QosProtocolWrapper
filter=org.apache.dubbo.rpc.protocol.ProtocolFilterWrapper:对 invoker 进行 filter 的包装,实现请求的过滤 ;
listener=org.apache.dubbo.rpc.protocol.ProtocolListenerWrapper
接着,在 调用getExtension->createExtension 方法中,会对 cacheWrapperClass 集合进行判断,如果集合不为空,则进行包装:
Set<Class<?>> wrapperClasses = cachedWrapperClasses;
if (CollectionUtils.isNotEmpty(wrapperClasses)) {
for (Class<?> wrapperClass : wrapperClasses) {
instance = injectExtension((T) wrapperClass.getConstructor(type).newInstance(instance));
}
}
例如:ProtocolFilterWrapper 这个是一个过滤器的包装,使用责任链模式,对 invoker 进行了包装
public <T> Exporter<T> export(Invoker<T> invoker) throws RpcException {
if (Constants.REGISTRY_PROTOCOL.equals(invoker.getUrl().getProtocol())) {
return protocol.export(invoker);
}
return protocol.export(buildInvokerChain(invoker, Constants.SERVICE_FILTER_KEY, Constants.PROVIDER));
}
包装成QosProtocolWrapper(ProtocolListenerWrapper(ProtocolFilterWrapper(DubboProtocol))))过滤完之后开始执行DubboProtocol.export
public <T> Exporter<T> export(Invoker<T> invoker) throws RpcException {
URL url = invoker.getUrl();
// 获取服务标识,理解成服务坐标也行。由服务组名,服务名,服务版本号以及端口组成。比如
//${group}/copm.gupaoedu.practice.dubbo.ISayHelloService:${version}:20880
String key = serviceKey(url);
DubboExporter<T> exporter = new DubboExporter<T>(invoker, key, exporterMap);
exporterMap.put(key, exporter);
//export an stub service for dispatching event
Boolean isStubSupportEvent = url.getParameter(STUB_EVENT_KEY, DEFAULT_STUB_EVENT);
Boolean isCallbackservice = url.getParameter(IS_CALLBACK_SERVICE, false);
if (isStubSupportEvent && !isCallbackservice) {
String stubServiceMethods = url.getParameter(STUB_EVENT_METHODS_KEY);
if (stubServiceMethods == null || stubServiceMethods.length() == 0) {
if (logger.isWarnEnabled()) {
logger.warn(new IllegalStateException("consumer [" + url.getParameter(INTERFACE_KEY) +
"], has set stubproxy support event ,but no stub methods founded."));
}
} else {
stubServiceMethodsMap.put(url.getServiceKey(), stubServiceMethods);
}
}
//开启服务 暴露20880端口
openServer(url);
//优化序列化
optimizeSerialization(url);
return exporter;
}
private void openServer(URL url) {
//获取 host:port ,并将其作为服务器实例的 key ,用于标识当前的服务器实例
String key = url.getAddress();
//client 也可以暴露一个只有 server可以调用的服务
boolean isServer = url.getParameter(IS_SERVER_KEY, true);
if (isServer) {
// 是否在 serverMap中缓存了
ExchangeServer server = serverMap.get(key);
if (server == null) {
synchronized (this) {
server = serverMap.get(key);
if (server == null) {
// 创建服务器实例
serverMap.put(key, createServer(url));
}
}
} else {
//服务器已创建,则根据 url 中的配置重置服务器
server.reset(url);
}
}
}
private ExchangeServer createServer(URL url) {
// 组装 url ,在 url中添加心跳时间、编解码参数
url = URLBuilder.from(url)
// 当服务关闭以后,发送一个只读的事件,默认是开启状态
.addParameterIfAbsent(CHANNEL_READONLYEVENT_SENT_KEY, Boolean.TRUE.toString())
//启动心跳配置
.addParameterIfAbsent(HEARTBEAT_KEY, String.valueOf(DEFAULT_HEARTBEAT))
.addParameter(CODEC_KEY, DubboCodec.NAME)
.build();
String str = url.getParameter(SERVER_KEY, DEFAULT_REMOTING_SERVER);
// 通过 SPI 检测是否存在 server 参数所代表的 Transporter 拓展,不存在则抛出异常
if (str != null && str.length() > 0 && !ExtensionLoader.getExtensionLoader(Transporter.class).hasExtension(str)) {
throw new RpcException("Unsupported server type: " + str + ", url: " + url);
}
ExchangeServer server;
try {
server = Exchangers.bind(url, requestHandler);
} catch (RemotingException e) {
throw new RpcException("Fail to start server(url: " + url + ") " + e.getMessage(), e);
}
str = url.getParameter(CLIENT_KEY);
if (str != null && str.length() > 0) {
Set<String> supportedTypes = ExtensionLoader.getExtensionLoader(Transporter.class).getSupportedExtensions();
if (!supportedTypes.contains(str)) {
throw new RpcException("Unsupported client type: " + str);
}
}
return server;
}
后续代码就不一一写了,写个链流程如下:
Exchangers.bind(url, requestHandler);——>headerExchanger.bind——>Transporters.bind——>getTransporter().bind(url, handler)——>NettyTransporter.bind(URL url, ChannelHandler listener)——> new NettyServer(url, listener)——>NettyServer.doOpen();之后就是netty的监听服务工作了。
3.启动netty服务实现远程监听然后把dubbo注册到zookeeper上,创建一个zookeeperclient创建dubbo://ip:port/com...这样的节点
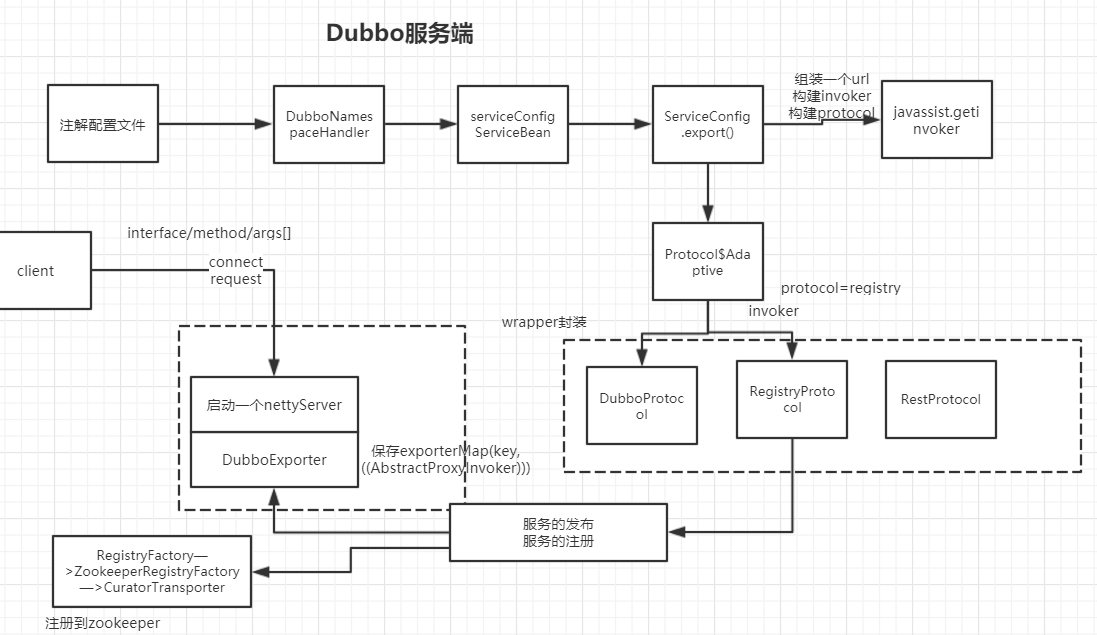
服务消费
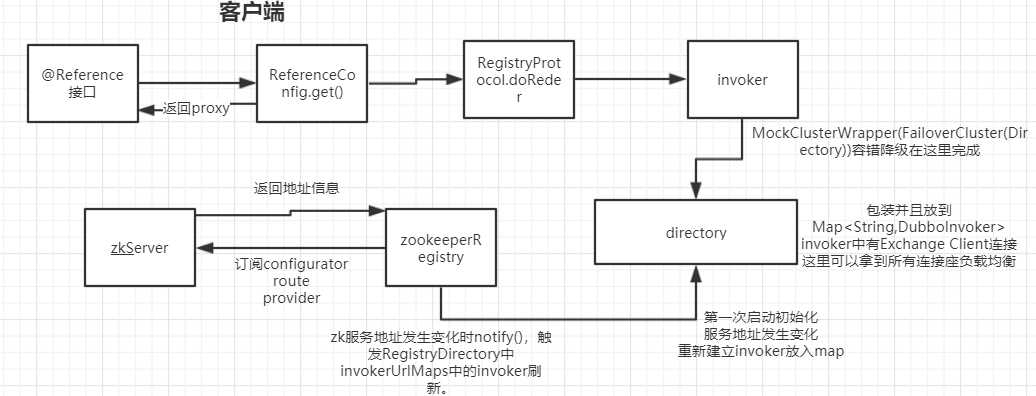
时序图: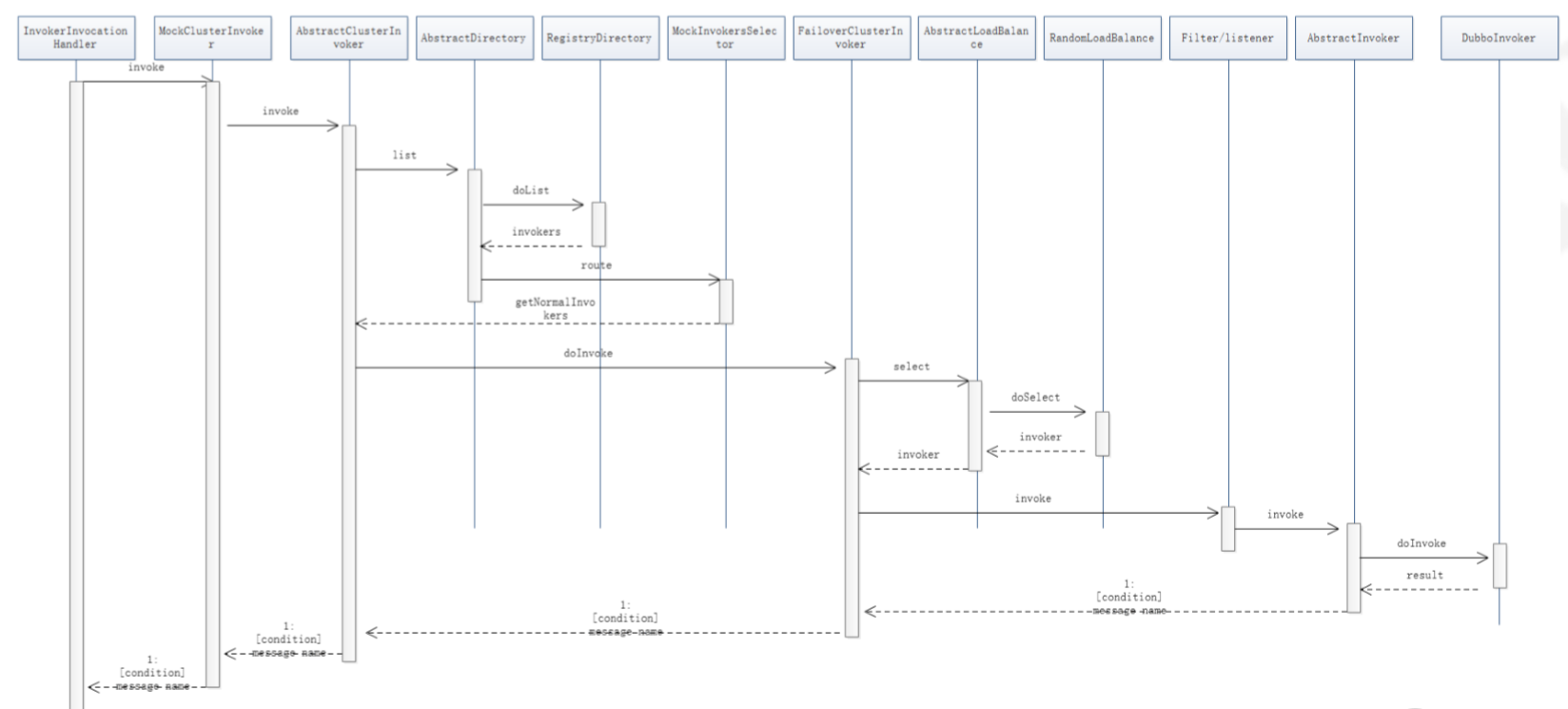
1. 生成远程服务的代理
服务入口ReferenceConfig.get() 获得一个远程代理类;
createProxy
private T createProxy(Map<String, String> map) {
if (shouldJvmRefer(map)) {//判断是否是在同一个jvm进程中调用
URL url = new URL(LOCAL_PROTOCOL, LOCALHOST_VALUE, 0, interfaceClass.getName()).addParameters(map);
invoker = REF_PROTOCOL.refer(interfaceClass, url);
if (logger.isInfoEnabled()) {
logger.info("Using injvm service " + interfaceClass.getName());
}
} else {
urls.clear(); // reference retry init will add url to urls, lead to OOM
//url 如果不为空,说明是点对点通信
if (url != null && url.length() > 0) { // user specified URL, could be peer-to-peer address, or register center's address.
String[] us = SEMICOLON_SPLIT_PATTERN.split(url);
if (us != null && us.length > 0) {
for (String u : us) {
URL url = URL.valueOf(u);
if (StringUtils.isEmpty(url.getPath())) {
url = url.setPath(interfaceName);
}
// 检测 url 协议是否为 registry,若是,表明用户想使用指定的注册 中心
if (REGISTRY_PROTOCOL.equals(url.getProtocol())) {
// 将 map 转换为查询字符串,并作为 refer 参数的值添加到 url 中
urls.add(url.addParameterAndEncoded(REFER_KEY, StringUtils.toQueryString(map)));
} else {
// 合并 url,移除服务提供者的一些配置(这些配置来源于用户配置 的 url 属性),
// 比如线程池相关配置。并保留服务提供者的部分配置,比如版本, group,时间戳等
// 后将合并后的配置设置为 url 查询字符串中。
urls.add(ClusterUtils.mergeUrl(url, map));
}
}
}
} else { // assemble URL from register center's configuration
// if protocols not injvm checkRegistry
if (!LOCAL_PROTOCOL.equalsIgnoreCase(getProtocol())){
checkRegistry();
//校验注册中心的配置以及是否有必要从配置中心组装url
//这里的代码实现和服务端类似,也是根据注册中心配置进行解析得到URL
//这里的URL肯定也是: registry://ip:port/org.apache.dubbo.service.RegsitryService
List<URL> us = loadRegistries(false);
if (CollectionUtils.isNotEmpty(us)) {
for (URL u : us) {
URL monitorUrl = loadMonitor(u);
if (monitorUrl != null) {
map.put(MONITOR_KEY, URL.encode(monitorUrl.toFullString()));
}
urls.add(u.addParameterAndEncoded(REFER_KEY, StringUtils.toQueryString(map)));
}
}
//如果没有配置注册中心,则报错
if (urls.isEmpty()) {
throw new IllegalStateException("No such any registry to reference " + interfaceName + " on the consumer " + NetUtils.getLocalHost() + " use dubbo version " + Version.getVersion() + ", please config <dubbo:registry address=\"...\" /> to your spring config.");
}
}
}
//如果值配置了一个注册中心或者一个服务提供者,直接使用refprotocol.refer
if (urls.size() == 1) {
invoker = REF_PROTOCOL.refer(interfaceClass, urls.get(0));
} else {
List<Invoker<?>> invokers = new ArrayList<Invoker<?>>();
URL registryURL = null;
for (URL url : urls) {
invokers.add(REF_PROTOCOL.refer(interfaceClass, url));
if (REGISTRY_PROTOCOL.equals(url.getProtocol())) {
registryURL = url; // use last registry url
}
}
if (registryURL != null) { // registry url is available
// use RegistryAwareCluster only when register's CLUSTER is available
URL u = registryURL.addParameter(CLUSTER_KEY, RegistryAwareCluster.NAME);
// The invoker wrap relation would be: RegistryAwareClusterInvoker(StaticDirectory) -> FailoverClusterInvoker(RegistryDirectory, will execute route) -> Invoker
invoker = CLUSTER.join(new StaticDirectory(u, invokers));
} else { // not a registry url, must be direct invoke.
invoker = CLUSTER.join(new StaticDirectory(invokers));
}
}
}
if (shouldCheck() && !invoker.isAvailable()) {
throw new IllegalStateException("Failed to check the status of the service " + interfaceName + ". No provider available for the service " + (group == null ? "" : group + "/") + interfaceName + (version == null ? "" : ":" + version) + " from the url " + invoker.getUrl() + " to the consumer " + NetUtils.getLocalHost() + " use dubbo version " + Version.getVersion());
}
if (logger.isInfoEnabled()) {
logger.info("Refer dubbo service " + interfaceClass.getName() + " from url " + invoker.getUrl());
}
/**
* @since 2.7.0
* ServiceData Store
*/
MetadataReportService metadataReportService = null;
if ((metadataReportService = getMetadataReportService()) != null) {
URL consumerURL = new URL(CONSUMER_PROTOCOL, map.remove(REGISTER_IP_KEY), 0, map.get(INTERFACE_KEY), map);
metadataReportService.publishConsumer(consumerURL);
}
// create service proxy
return (T) PROXY_FACTORY.getProxy(invoker);
}
2. 获得目标服务的url地址
RegistryProtocol.refer
这里面的代码逻辑比较简单
组装注册中心协议的url
判断是否配置legroup,如果有,则cluster=getMergeableCluster(),构建invoker
doRefer构建invoker
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
//这段代码也很熟悉,就是根据配置的协议,生成注册中心的url: zookeeper://
url = URLBuilder.from(url)
.setProtocol(url.getParameter(REGISTRY_KEY, DEFAULT_REGISTRY))
.removeParameter(REGISTRY_KEY)
.build();
Registry registry = registryFactory.getRegistry(url);
if (RegistryService.class.equals(type)) {
return proxyFactory.getInvoker((T) registry, type, url);
}
// group="a,b" or group="*"
Map<String, String> qs = StringUtils.parseQueryString(url.getParameterAndDecoded(REFER_KEY));
String group = qs.get(GROUP_KEY);
if (group != null && group.length() > 0) {
if ((COMMA_SPLIT_PATTERN.split(group)).length > 1 || "*".equals(group)) {
return doRefer(getMergeableCluster(), registry, type, url);
}
}
return doRefer(cluster, registry, type, url);
}
doRefer
doRefer里面就稍微复杂一些,涉及到比较多的东西,我们先关注主线
构建一个RegistryDirectory
构建一个consumer://协议的地址注册到注册中心
订阅zookeeper中节点的变化
调用cluster.join方法
private <T> Invoker<T> doRefer(Cluster cluster, Registry registry, Class<T> type, URL url) {
//RegistryDirectory初始化
RegistryDirectory<T> directory = new RegistryDirectory<T>(type, url);
directory.setRegistry(registry);
directory.setProtocol(protocol);
// all attributes of REFER_KEY
Map<String, String> parameters = new HashMap<String, String>(directory.getUrl().getParameters());
//注册consumer://协议的url
URL subscribeUrl = new URL(CONSUMER_PROTOCOL, parameters.remove(REGISTER_IP_KEY), 0, type.getName(), parameters);
if (!ANY_VALUE.equals(url.getServiceInterface()) && url.getParameter(REGISTER_KEY, true)) {
directory.setRegisteredConsumerUrl(getRegisteredConsumerUrl(subscribeUrl, url));
registry.register(directory.getRegisteredConsumerUrl());
}
directory.buildRouterChain(subscribeUrl);
//订阅事件监听
directory.subscribe(subscribeUrl.addParameter(CATEGORY_KEY,
PROVIDERS_CATEGORY + "," + CONFIGURATORS_CATEGORY + "," + ROUTERS_CATEGORY));
//构建invoker
Invoker invoker = cluster.join(directory);
ProviderConsumerRegTable.registerConsumer(invoker, url, subscribeUrl, directory);
return invoker;
}
cluster.join
Invoker invoker = cluster.join(directory); //返回的是一个MockClusterWrapper(FailOverCluster(directory))
接着回到ReferenceConfig.createProxy方法中的最后一行
proxyFactory.getProxy
而这里的proxyFactory又是一个自适应扩展点,所以会进入下面的方法
JavassistProxyFactory.getProxy
public <T> T getProxy(Invoker<T> invoker, Class<?>[] interfaces) {
return (T) Proxy.getProxy(interfaces).newInstance(new InvokerInvocationHandler(invoker));
}
通过dubug调试一下得到ccp这个变量——>mMetthods如下代码。
public java.lang.String sayHello(java.lang.String arg0){ //sayHello是自定义的暴露服务
Object[] args = new Object[1];
args[0] = ($w)$1;
Object ret = handler.invoke(this, methods[0], args);
return (java.lang.String)ret;
}
3. 实现远程网络通信
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
url = URLBuilder.from(url)
.setProtocol(url.getParameter(REGISTRY_KEY, DEFAULT_REGISTRY))
.removeParameter(REGISTRY_KEY)
.build();
Registry registry = registryFactory.getRegistry(url);
if (RegistryService.class.equals(type)) {
return proxyFactory.getInvoker((T) registry, type, url);
}
// group="a,b" or group="*"
Map<String, String> qs = StringUtils.parseQueryString(url.getParameterAndDecoded(REFER_KEY));
String group = qs.get(GROUP_KEY);
if (group != null && group.length() > 0) {
if ((COMMA_SPLIT_PATTERN.split(group)).length > 1 || "*".equals(group)) {
return doRefer(getMergeableCluster(), registry, type, url);
}
}
return doRefer(cluster, registry, type, url);
}
private <T> Invoker<T> doRefer(Cluster cluster, Registry registry, Class<T> type, URL url) {
RegistryDirectory<T> directory = new RegistryDirectory<T>(type, url);
directory.setRegistry(registry);
directory.setProtocol(protocol);
// all attributes of REFER_KEY
Map<String, String> parameters = new HashMap<String, String>(directory.getUrl().getParameters());
URL subscribeUrl = new URL(CONSUMER_PROTOCOL, parameters.remove(REGISTER_IP_KEY), 0, type.getName(), parameters);
if (!ANY_VALUE.equals(url.getServiceInterface()) && url.getParameter(REGISTER_KEY, true)) {
directory.setRegisteredConsumerUrl(getRegisteredConsumerUrl(subscribeUrl, url));
registry.register(directory.getRegisteredConsumerUrl());
}
directory.buildRouterChain(subscribeUrl);
//它是实现服务目标服务订阅的
directory.subscribe(subscribeUrl.addParameter(CATEGORY_KEY,
PROVIDERS_CATEGORY + "," + CONFIGURATORS_CATEGORY + "," + ROUTERS_CATEGORY));
Invoker invoker = cluster.join(directory);
ProviderConsumerRegTable.registerConsumer(invoker, url, subscribeUrl, directory);
return invoker;
}
//订阅注册中心指定节点的变化,如果发生变化,则通知到RegistryDirectory。Directory其实和服务的注 册以及服务的发现有非常大的关联
public void subscribe(URL url) {
setConsumerUrl(url);
//把当前RegistryDirectory作为listener,去监听zk上节点的变化
CONSUMER_CONFIGURATION_LISTENER.addNotifyListener(this);
serviceConfigurationListener = new ReferenceConfigurationListener(this, url);
registry.subscribe(url, this); //订阅 -> 这里的registry是zookeeperRegsitry
}
这里的registry 是ZookeeperRegistry ,会去监听并获取路径下面的节点。监听的路径是:
/dubbo/org.apache.dubbo.demo.DemoService/providers 、
/dubbo/org.apache.dubbo.demo.DemoService/configurators、
/dubbo/org.apache.dubbo.de mo.DemoService/routers 节点下面的子节点变动
后面代码比较多就不一一写了,流程如上流程图:
FailbackRegistry.subscribe→ZookeeperRegistry.doSubscribe →FailbackRegistry.notify →AbstractRegistry.notify →RegistryDirectory.notify→refreshOverrideAndInvoker →refreshInvoker
当zk服务端第一次初始化和地址发生改变时会调用RegistryDirectory.notify方法,根据新的url生成新的invoker,保存在urlInvokerMap 中缓存。
在构建DubboInvoker时,会构建一个ExchangeClient,通过getClients(url)方法,这里基本可以猜到到 是服务的通信建立。
@Override
public <T> Invoker<T> refer(Class<T> serviceType, URL url) throws RpcException {
optimizeSerialization(url);
// create rpc invoker.
DubboInvoker<T> invoker = new DubboInvoker<T>(serviceType, url, getClients(url), invokers);
invokers.add(invoker);
return invoker;
}
这里面是获得客户端连接的方法
1.判断是否为共享连接,默认是共享同一个连接进行通信 ;
2.是否配置了多个连接通道 connections,默认只有一个;
private ExchangeClient[] getClients(URL url) {
// whether to share connection
boolean useShareConnect = false;
int connections = url.getParameter(CONNECTIONS_KEY, 0);
List<ReferenceCountExchangeClient> shareClients = null;
//如果没有配置连接数,则默认为共享连接
if (connections == 0) {
useShareConnect = true;
/**
* The xml configuration should have a higher priority than properties.
*/
String shareConnectionsStr = url.getParameter(SHARE_CONNECTIONS_KEY, (String) null);
connections = Integer.parseInt(StringUtils.isBlank(shareConnectionsStr) ? ConfigUtils.getProperty(SHARE_CONNECTIONS_KEY,
DEFAULT_SHARE_CONNECTIONS) : shareConnectionsStr);
shareClients = getSharedClient(url, connections);
}
ExchangeClient[] clients = new ExchangeClient[connections];
for (int i = 0; i < clients.length; i++) {
if (useShareConnect) {
clients[i] = shareClients.get(i);
} else {
clients[i] = initClient(url);
}
}
return clients;
}
getSharedClient
获得一个共享连接
private List<ReferenceCountExchangeClient> getSharedClient(URL url, int connectNum) {
String key = url.getAddress();
List<ReferenceCountExchangeClient> clients = referenceClientMap.get(key);
//检查当前的key检查连接是否已经创建过并且可用,如果是,则直接返回并且增加连接的个数的统计
if (checkClientCanUse(clients)) {
batchClientRefIncr(clients);
return clients;
}
//如果连接已经关闭或者连接没有创建过
locks.putIfAbsent(key, new Object());
synchronized (locks.get(key)) {
clients = referenceClientMap.get(key);
// 在创建连接之前,在做一次检查,防止连接并发创建
if (checkClientCanUse(clients)) {
batchClientRefIncr(clients);
return clients;
}
// 连接数必须大于等于1
connectNum = Math.max(connectNum, 1);
//如果当前消费者还没有和服务端产生连接,则初始化
if (CollectionUtils.isEmpty(clients)) {
clients = buildReferenceCountExchangeClientList(url, connectNum);
//创建clients之后,保存到map中
referenceClientMap.put(key, clients);
} else {
for (int i = 0; i < clients.size(); i++) {{//如果clients不为空,则从clients数组中进行遍历
ReferenceCountExchangeClient referenceCountExchangeClient = clients.get(i);
// 如果在集合中存在一个连接但是这个连接处于closed状态,则重新构建一个 进行替换
if (referenceCountExchangeClient == null || referenceCountExchangeClient.isClosed()) {
clients.set(i, buildReferenceCountExchangeClient(url));
continue;
}
referenceCountExchangeClient.incrementAndGetCount();
}
}
/**
* I understand that the purpose of the remove operation here is to avoid the expired url key
* always occupying this memory space.
*/
locks.remove(key);
return clients;
}
}
//根据连接数配置,来构建指定个数的链接。默认为1
private List<ReferenceCountExchangeClient> buildReferenceCountExchangeClientList(URL url, int connectNum) {
List<ReferenceCountExchangeClient> clients = new ArrayList<>();
for (int i = 0; i < connectNum; i++) {
clients.add(buildReferenceCountExchangeClient(url));
}
return clients;
}
//初始化
private ExchangeClient initClient(URL url) {
// 获得连接类型
String str = url.getParameter(CLIENT_KEY, url.getParameter(SERVER_KEY, DEFAULT_REMOTING_CLIENT));
//添加默认序列化方式
url = url.addParameter(CODEC_KEY, DubboCodec.NAME);
// 设置心跳时间
url = url.addParameterIfAbsent(HEARTBEAT_KEY, String.valueOf(DEFAULT_HEARTBEAT));
// 判断str是否存在于扩展点中,如果不存在则直接报错
if (str != null && str.length() > 0 && !ExtensionLoader.getExtensionLoader(Transporter.class).hasExtension(str)) {
throw new RpcException("Unsupported client type: " + str + "," +
" supported client type is " + StringUtils.join(ExtensionLoader.getExtensionLoader(Transporter.class).getSupportedExtensions(), " "));
}
ExchangeClient client;
try {
// 是否需要延迟创建连接,注意哦,这里的requestHandler是一个适配器
if (url.getParameter(LAZY_CONNECT_KEY, false)) {
client = new LazyConnectExchangeClient(url, requestHandler);
} else {
client = Exchangers.connect(url, requestHandler);
}
} catch (RemotingException e) {
throw new RpcException("Fail to create remoting client for service(" + url + "): " + e.getMessage(), e);
}
return client;
}
//创建一个客户端连接
public static ExchangeClient connect(URL url, ExchangeHandler handler) throws RemotingException {
if (url == null) {
throw new IllegalArgumentException("url == null");
}
if (handler == null) {
throw new IllegalArgumentException("handler == null");
}
url = url.addParameterIfAbsent(Constants.CODEC_KEY, "exchange");
return getExchanger(url).connect(url, handler);
}
NettyTransport.connec
使用netty构建了一个客户端连接
@Override
public Client connect(URL url, ChannelHandler listener) throws RemotingException {
return new NettyClient(url, listener);
}
性能参数调优

各个参数的作用
1、当consumer发起一个请求时,首先经过active limit(参数actives)进行方法级别的限制,其实现方 式为CHM中存放计数器(AtomicInteger),请求时加1,请求完成(包括异常)减1,如果超过actives则等 待有其他请求完成后重试或者超时后失败;
2、从多个连接(connections)中选择一个连接发送数据,对于默认的netty实现来说,由于可以复用连接,默认一个连接就可以。不过如果你在压测,且只有一个consumer,一个provider,此时适当的加大 connections确实能够增强网络传输能力。但线上业务由于有多个consumer多个provider,因此不建议增加connections参数;
3、连接到达provider时(如dubbo的初次连接),首先会判断总连接数是否超限(acceps),超过限制连接将被拒绝;
4、连接成功后,具体的请求交给io thread处理。io threads虽然是处理数据的读写,但io部分为异步, 更多的消耗的是cpu,因此io threads默认cpu个数+1是比较合理的设置,不建议调整此参数;
5、数据读取并反序列化以后,交给业务线程池处理,默认情况下线程池为fixed,且排队队列为 0(queues),这种情况下,最大并发等于业务线程池大小(threads),如果希望有请求的堆积能力,可以 调整queues参数。如果希望快速失败由其他节点处理(官方推荐方式),则不修改queues,只调整 threads;
6、execute limit(参数executes)是方法级别的并发限制,原理与actives类似,只是少了等待的过 程,即受限后立即失败 ;

















 666
666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









