




持续更新中
持续更新中
持续更新中
一、哈希概念
线性查找以及树形查找中,元素的存储位置和其关键码间没有对应关系,因此根据关键码查找某个元素时,必须要经过关键码的多次比较,也就是说,查找效率取决于查找过程中关键码的比较次数
理想的查找方法是构造出一种存储结构,再通过某种函数建立元素的存储位置和其关键码二者间的映射关系,那么在查找时通过该函数就可以不经过任何比较,直接找到该元素
该查找方法即为哈希(散列)方法,其中构造出的存储结构称为哈希表(或称散列表),建立映射关系的函数称为哈希函数(或称散列函数)
二、哈希冲突
K1 != K2 But HashFun(K1) == HashFun(K2),即不同的关键码通过相同的哈希函数计算出同一个哈希地址,称该现象为哈希冲突(或称哈希碰撞),另外,称关键码不同哈希地址相同的元素为 “同义词”
int a[ ] = {180, 750, 600, 430, 541, 900, 460,443};
int HashFunc(int key)
{
return key % 13;
}

三、常见哈希函数
HashFunc(key) == HashFunc(key) == …,即参数 key 相同,哈希函数也相同,无论调用多少次,哈希函数最终的返回值总是相同的
1、直接定址法
HashFunc(key) = a * key + b,其中 a、b 为常数且 a != 0
2、除留余数法
HashFunc(key) = key % p,其中 p 为不大于哈希表长度且最接近或等于表长的质数
3、平方取中法
- 关键码 1234 的平方是 1522756,取中间 3 位,也就是 227 作为哈希地址
- 关键码 4321 的平方是 18671041,取中间 3 位,也就是 671(或710)作为哈希地址
4、折叠法
将关键码从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这几部分叠加求和,并按哈希表长度,取后几位作为哈希地址
5、随机数法
HashFunc(key) = random(key),其中 random 为随机数函数
6、数学分析法
假设有 n 个 d 位数,每一位上都可能有 r 种不同的符号出现,这些符号在各位上出现的频率不一定相同,可能在某些位上分布比较均匀,各符号出现的频率相同,也可能在某些位上分布不均匀,只有某几种符号经常出现,可根据哈希表长度,选择其中各符号分布均匀的若干位作为哈希地址
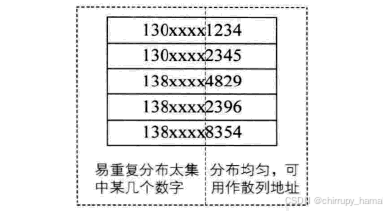
假设要存储某家公司员工登记表,如果用手机号作为关键码,那么极有可能前 7 位都是相同的,如此我们可以选择后 4 位作为哈希地址,如果还是容易发生冲突的话,我们还可以对抽取出来的数字进行如下操作:
- 反转(1234 -> 4321)
- 右环位移(1234 -> 4123)、左环移位
- 前两位数与后两位数相加(1234 -> 12+34=46)
四、位图
五、布隆过滤器
六、如何处理海量数据?
详见海量数据处理方法


















 6964
6964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









