






以下是对计算机视觉“新”范式Transformer的技术详解:
起源与发展
Transformer最初是在2017年的论文《Attention Is All You Need》中提出,用于自然语言处理领域,旨在解决序列到序列任务中的长程依赖问题。其在NLP领域取得巨大成功后,被引入计算机视觉领域,视觉Transformer(ViT)等模型的出现,开启了计算机视觉的新范式。
工作原理
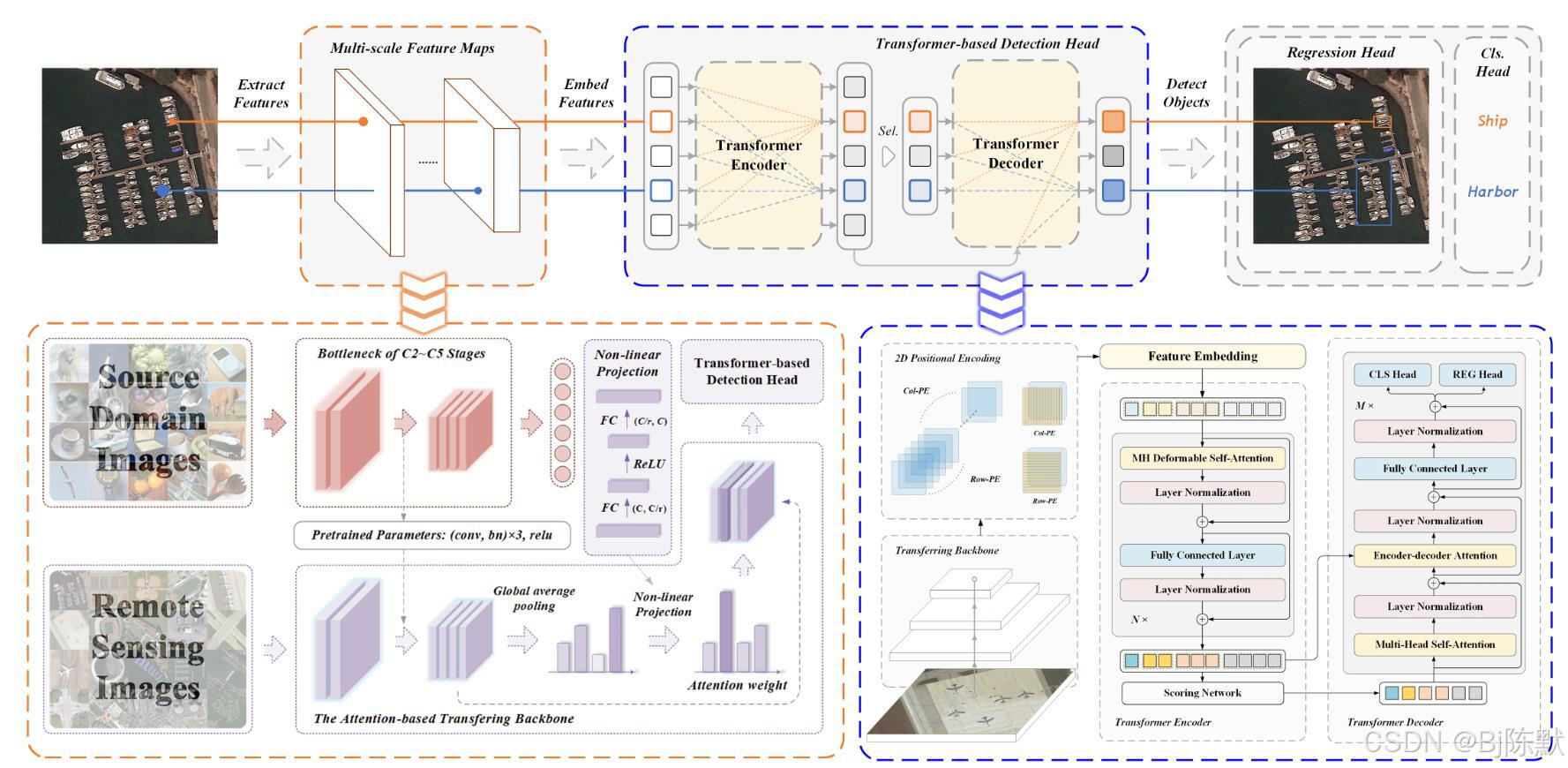
图像分块与嵌入:将输入图像分割成固定大小的小块,然后将这些小块通过线性投影映射为向量,即“token化”,将图像转化为序列数据。例如,将一张224×224的图像分割成16×16的小块,就得到了多个图像块。
位置编码:由于Transformer本身不具有对位置信息的感知能力,所以需要添加位置编码来捕捉图像中各块的空间位置信息。常见的位置编码方式有正弦余弦位置编码、可学习的位置编码等。
自注意力机制:这是Transformer的核心。它允许模型在处理每个位置的信息时,能够同时考虑到其他所有位置的信息,计算每个位置与其他位置之间的关联程度,得到一个加权求和的结果,从而捕捉长距离依赖关系。比如在处理一幅图像时,能确定图像中不同区域之间的相关性。
多头注意力:通过多个头的注意力机制并行计算,捕捉不同方面的信息,每个头关注不同的特征或关系,从而更全面地提取图像的特征。
编码器与解码器:编码器由多个堆叠的自注意力层和前馈神经网络层组成,对输入的图像块序列进行编码,提取高级特征。解码器在一些任务中用于根据编码器的输出生成目标,如在图像生成任务中生成图像像素值。
在计算机视觉中的优势
长程依赖建模能力强:能够有效捕捉图像中相距较远的区域之间的关系,比如在一幅包含多个物体的场景图像中,能很好地理解不同物体之间的空间关系和相互作用,这是传统CNN难以做到的。
强大的特征表示能力:多层的Transformer结构可以学习到非常丰富和复杂的图像特征,无需像CNN那样依赖手工设计的卷积核等组件,从数据中直接学习特征的能力更强。
灵活性高:不依赖于图像的特定结构或先验知识,对输入图像的大小、分辨率等没有严格限制,能够处理各种不同类型和尺寸的图像数据。
并行计算效率高:可以并行计算注意力机制,相比传统的循环神经网络(RNN)等序列处理模型,大大提高了训练和推理的速度,能够更高效地利用硬件资源。
可解释性相对较好:通过注意力可视化等方法,可以直观地看到模型在处理图像时关注的区域,一定程度上提高了模型的可解释性,例如可以通过注意力热图观察到模型在识别某个物体时主要关注的图像部位。
在计算机视觉中的应用
图像分类:将图像分类任务中的图像通过ViT等模型处理,提取特征后进行分类预测,在大规模数据集上取得了优于传统CNN模型的性能。
目标检测:如DETR等模型,利用Transformer的全局建模能力,直接对图像中的目标进行检测和定位,无需像传统方法那样依赖手工设计的anchor等机制,简化了目标检测的流程。
语义分割:通过Transformer对图像中的每个像素进行分类,确定其所属的物体类别或语义区域,能够更好地捕捉图像中的上下文信息,提高分割的准确性。
图像生成:例如在图像超分辨率重建、图像去噪等任务中,Transformer可以学习低分辨率图像与高分辨率图像之间的映射关系,生成高质量的图像。
视频处理:将视频帧序列作为输入,利用Transformer捕捉视频帧之间的时序信息,用于视频分类、动作识别、光流估计等任务。
面临的挑战
计算资源需求大:自注意力机制的计算复杂度与输入序列长度的平方成正比,在处理高分辨率图像或长序列视频时,计算量会急剧增加,需要强大的计算硬件支持,并且训练和推理的时间也会很长。
数据需求大:虽然相比CNN在少数据情况下有一定优势,但要充分发挥Transformer的性能,仍然需要大量的训练数据,否则容易出现过拟合现象。
局部特征捕捉能力相对弱:更关注全局信息,对于一些需要精细捕捉局部纹理、细节等信息的任务,可能不如CNN有效,例如在一些对图像细节要求很高的医学图像分析任务中,可能需要结合CNN等方法来补充局部特征信息。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











