






这两年,Kubernetes在各个企业中的DevOps、微服务方向取得了出色的成绩,从2017年开始,越来越多的企业也开始探索将Kubernetes应用到HPC、AI等领域。随着公司AI业务的迅猛增长,vivo在2017年9月也开始基于Kubernetes强大的分布式能力,探索与TensorFlow等ML框架深度整合,提高数据中心资源利用率,加快算法迭代速度。
Kubernetes在AI中的应用与在DevOps中部署App相比,最大的差别在于容器的规模以及容器生命周期。在我们的实践中,目前集群服务器规模很小的情况下,每天要调度近10W的容器,有很多容器可能只运行了十几分钟甚至几分钟,而且计划在2018年,集群规模还要翻十倍。在DevOps场景,应用发布频率再高,我相信一年下来能调度10W容器的企业并不多。下面我将聊一下TensorFlow on Kubernetes的架构及在vivo的实践。
分布式TensorFlow

TensorFlow是一个使用数据流图进行数值计算的开源软件库。图中的节点代表数学运算,而图中的边则代表在这些节点之间传递的多维数组(张量)。这种灵活的架构可让您使用一个API将计算工作部署到桌面设备、服务器或者移动设备中的一个或多个CPU或GPU。 关于TensorFlow的基础概念,我就不多介绍了。
单机TensorFlow
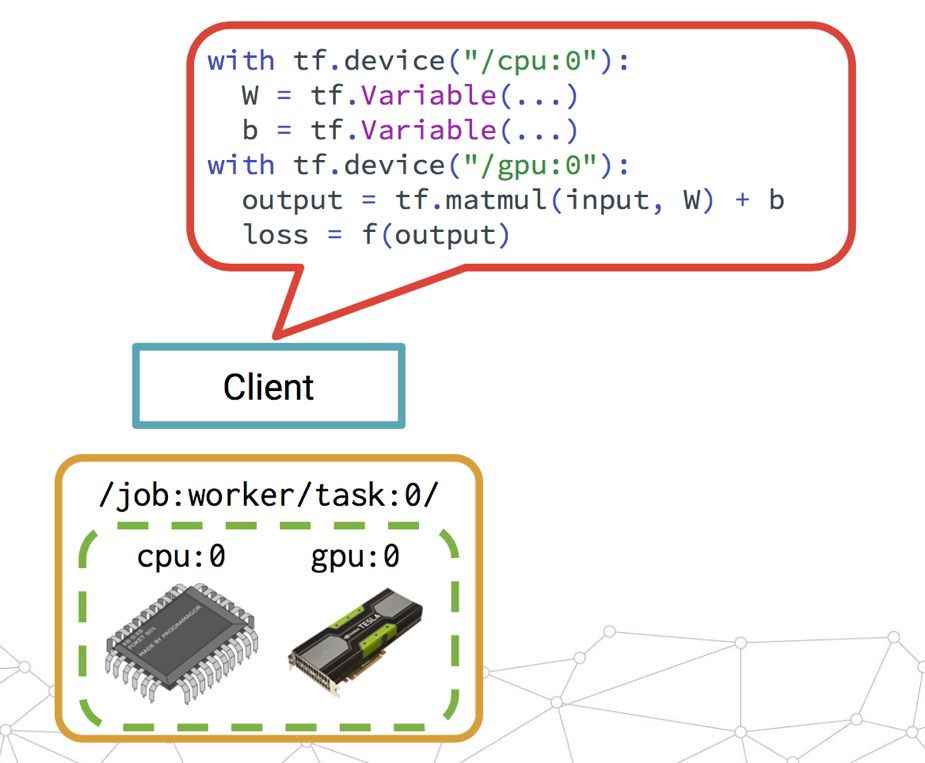
下面是一个单机式TensorFlow训练示意图,通过Client提交Session,定义这个worker要用哪个CPU/GPU做什么事。
分布式TensorFlow
2016年4月TensorFlow发布了0.8版本宣布支持分布式计算,我们称之为Distributed TensorFlow。这是非常重要的一个特性,因为在AI的世界里,训练的数据量和模型参数通常会非常大。比如Google Brain实验室今年发表的论文《Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer》中提到一个680亿个Parameters的模型,如果只能单机训练,那耗时难于接受。通过Distributed TensorFlow,可以利用大量服务器构建分布式TensorFlow集群来提高训练效率,减少训练时间。
通过TensorFlow Replcation机制,用户可以将SubGraph分布到不同的服务器中进行分布式计算。TensorFlow的副本机制又分为两种,In-graph和Between-graph。
In-graph Replication简单来讲,就是通过单个client session定义这个TensorFlow集群的所有task的工作。
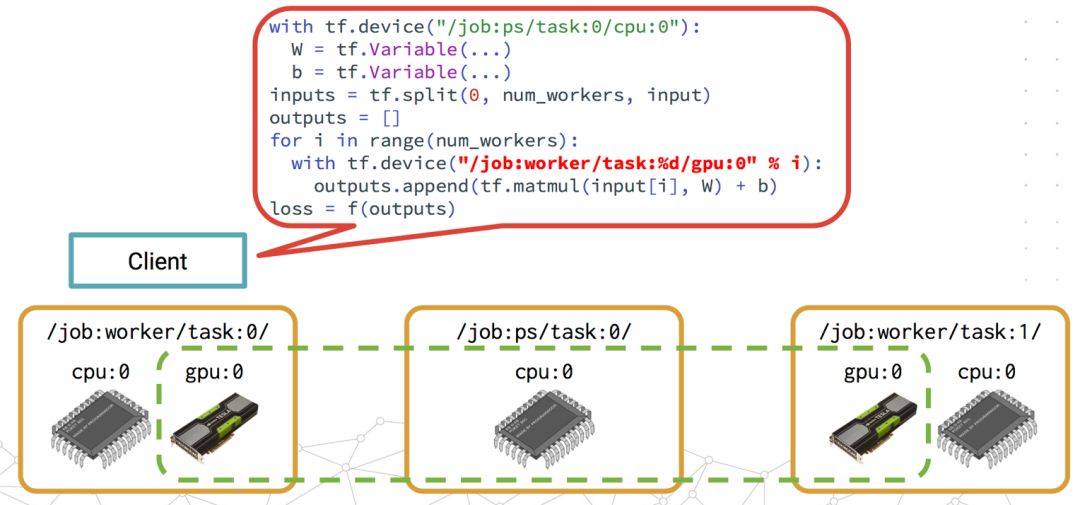
与之相对地,Between-graph Replication就是每个worker都有独立的client来定义自己的工作。
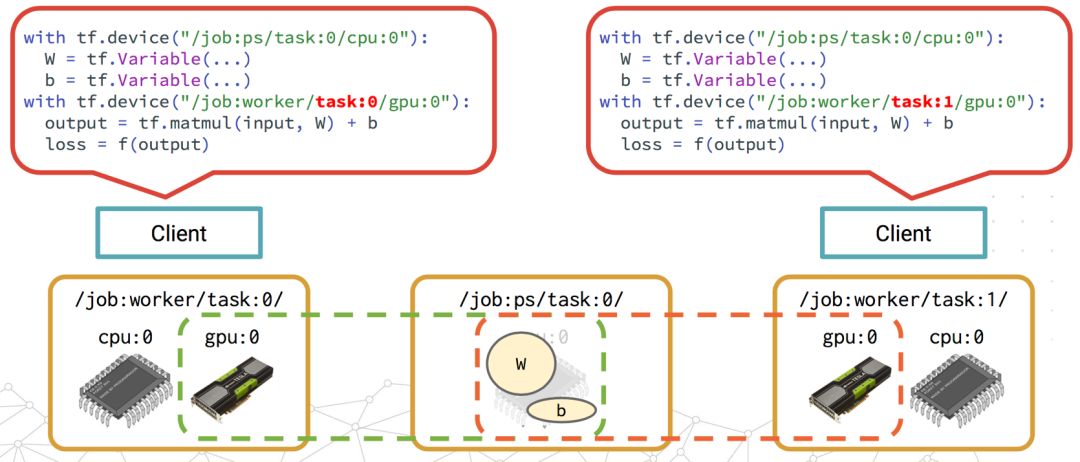
下面是抽象出来的分布式TensorFlow Framework如下:

我们先来了解里面的几个概念:
Cluster
一个TensorFlow Cluster有一个或多个jobs组成,每个job又由一个或多个tasks构成。Cluster的定义是通过tf.train.ClusterSpec来定义的。比如,定义一个由3个worker和2个PS的TensorFlow Cluster的ClusterSpec如下:
tf.train.ClusterSpec({
"worker": [
"worker0.example.com:2222", //主机名也可以使用IP
"worker1.example.com:2222",
"worker2.example.com:2222"
],
"ps": [
"ps0.example.com:2222",
"ps1.example.com:2222"
]})
Client
Client用来build一个TensorFlow Graph,并构建一个tensorflow::Session用来与集群通信。一个Client可以与多个TensorFlow Server交互,一个Server能服务多个Client。
Job
一个Job由tasks list组成,Job分PS和Worker两种类型。PS即parameter server,用来存储和更新variables的,而Worker可以认为是无状态的,用来作为计算任务的。Workers中,一般都会选择一个chief worker(通常是worker0),用来做训练状态的checkpoint,如果有worker故障,那么可以从最新checkpoint中restore。
Task
每个Task对应一个TensorFlow Server,对应一个单独的进程。一个Task属于某个Job,通过一个index来标记它在对应Job的tasks中的位置。每个TensorFlow均实现了Master service和Worker service。Master service用来与集群内的worker services进行gRPC交互。Worker service则是用local device来计算Subgraph。
关于Distributed TensorFlow的更多内容,请参考官方内容:www.tensorflow.org/deplopy/distributed。
分布式TensorFlow的缺陷
分布式TensorFlow能利用数据中心所有服务器构成的资源池,让大量PS和Worker能分布在不同的服务器进行参数存储和训练,这无疑是TensorFlow能否在企业落地的关键点。然而,这还不够,它还存在一下先天不足:
-
训练时TensorFlow各个Task资源无法隔离,很有可能会导致任务间因资源抢占互相影响。
-
缺乏调度能力,需要用户手动配置和管理任务的计算资源。
-
集群规模大时,训练任务的管理很麻烦,要跟踪和管理每个任务的状态,需要在上层做大量开发。
-
用户要查看各个Task的训练日志需要找出对应的服务器,并ssh过去,非常不方便。
-
TensorFlow原生支持的后端文件系统只支持:标准Posix文件系统(比如NFS)、HDFS、GCS、memory-mapped-file。大多数企业中数据都是存在大数据平台,因此以HDFS为主。然而,HDFS的Read性能并不是很好。
-
当你试着去创建一个大规模TensorFlow集群时,发现并不轻松。
TensorFlow on Kubernetes架构与原理
TensorFlow的这些不足,正好是Kubernetes的强项:
-
提供ResourceQuota、LimitRanger等多种资源管理机制,能做到任务之间很好的资源隔离。
-
支持任务的计算资源的配置和调度。
-
训练任务以容器方式运行,Kubernetes提供全套的容器PLEG接口,因此任务状态的管理很方便。
-
轻松对接EFK/ELK等日志方案,用户能方便的查看任务日志。
-
支持Read性能更优秀的分布式存储(GlusterFS),但目前我们也还没对接GlusterFS,有计划但没人力。
-
通过声明式文件实现轻松快捷的创建一个大规模TensorFlow集群。
TensorFlow on Kubernetes架构
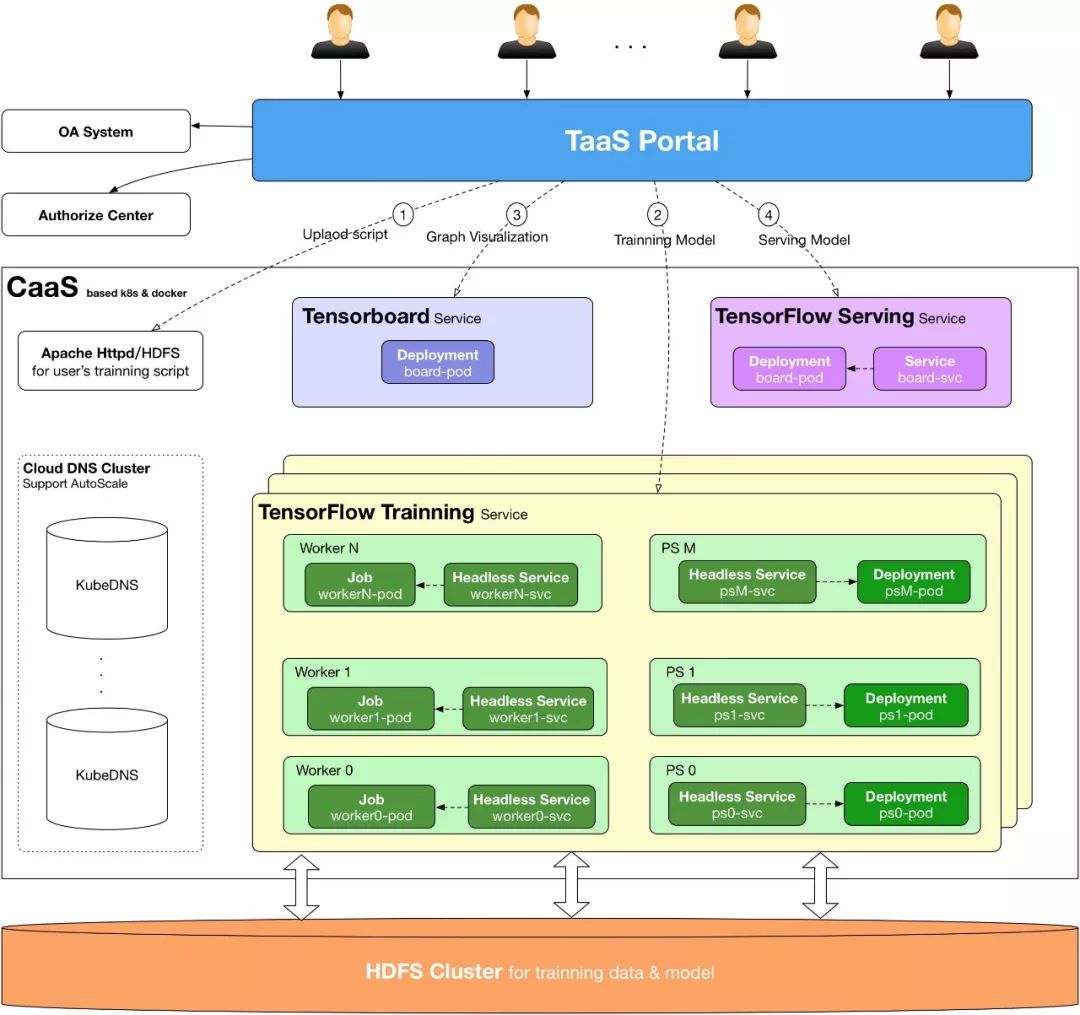
TensorFlow on Kubernetes原理
在我们的TensorFlow on Kubernetes方案中,主要用到以下的Kubernetes对象:
Kubernetes Job
我们用Kubernetes Job来部署TensorFlow Worker,Worker训练正常完成退出,就不会再重启容器了。注意Job中的Pod Template restartPolicy只能为Never或者OnFailure,不能为Always,这里我们设定restartPolicy为OnFailure,worker一旦异常退出,都会自动重启。但是要注意,要保证worker重启后训练能从checkpoint restore,不然worker重启后又从step 0开始,可能跑了几天的训练就白费了。如果你使用TensorFlow高级API写的算法,默认都实现了这点,但是如果你是使用底层Core API,一定要注意自己实现。
kind: Job
apiVersion: batch/v1
metadata:
name: {{ name }}-{{ task_type }}-{{ i }}
namespace: {{ name }}
spec:
template:
metadata:
labels:
name: {{ name }}
job: {{ task_type }}
task: "{{ i }}"
spec:
imagePullSecrets:
- name: harborsecret
containers:
- name: {{ name }}-{{ task_type }}-{{ i }}
image: {{ image }}
resources:
requests:
memory: "4Gi"
cpu: "500m"
ports:
- containerPort: 2222
command: ["/bin/sh", "-c", "export CLASSPATH=.:/usr/lib/jvm/java-1.8.0/lib/tools.jar:$(/usr/lib/hadoop-2.6.1/bin/hadoop classpath --glob); wget -r -nH -np --cut-dir=1 -R 'index.html*,*gif' {{ script }}; cd ./{{ name }}; sh ./run.sh {{ ps_hosts() }} {{ worker_hosts() }} {{ task_type }} {{ i }} {{ ps_replicas }} {{ worker_replicas }}"]
restartPolicy: OnFailure
Kubernetes Deployment
TensorFlow PS用Kubernetes Deployment来部署。为什么不像worker一样,也使用Job来部署呢?其实也未尝不可,但是考虑到PS进程并不会等所有worker训练完成时自动退出(一直挂起),所以使用Job部署没什么意义。
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: {{ name }}-{{ task_type }}-{{ i }}
namespace: {{ name }}
spec:
replicas: 1
template:
metadata:
labels:
name: {{ name }}
job: {{ task_type }}
task: "{{ i }}"
spec:
imagePullSecrets:
- name: harborsecret
containers:
- name: {{ name }}-{{ task_type }}-{{ i }}
image: {{ image }}
resources:
requests:
memory: "4Gi"
cpu: "500m"
ports:
- containerPort: 2222
command: ["/bin/sh", "-c","export CLASSPATH=.:/usr/lib/jvm/java-1.8.0/lib/tools.jar:$(/usr/lib/hadoop-2.6.1/bin/hadoop classpath --glob); wget -r -nH -np --cut-dir=1 -R 'index.html*,*gif' {{ script }}; cd ./{{ name }}; sh ./run.sh {{ ps_hosts() }} {{ worker_hosts() }} {{ task_type }} {{ i }} {{ ps_replicas }} {{ worker_replicas }}"]
restartPolicy: Always
关于TensorFlow PS进程挂起的问题,请参考:https://github.com/tensorflow/tensorflow/issues/4713。我们是这么解决的,开发了一个模块,watch每个TensorFlow集群的所有worker状态,当所有worker对应Job都Completed时,就会自动去删除PS对应的Deployment,从而kill PS进程释放资源。
Kubernetes Headless Service
Headless Service通常用来解决Kubernetes里面部署的应用集群之间的内部通信。在这里,我们也是这么用的,我们会为每个TensorFlow对应的Job和Deployment对象都创建一个Headless Service作为Worker和PS的通信代理。
kind: Service
apiVersion: v1
metadata:
name: {{ name }}-{{ task_type }}-{{ i }}
namespace: {{ name }}
spec:
clusterIP: None
selector:
name: {{ name }}
job: {{ task_type }}
task: "{{ i }}"
ports:
- port: {{ port }}
targetPort: 2222
用Headless Service的好处,就是在KubeDNS中,Service Name的域名解析直接对应到PodIp,而没有service VIP这一层,这就不依赖于kube-proxy去创建iptables规则了。少了kube-proxy的iptables这一层,带来的性能的提升。
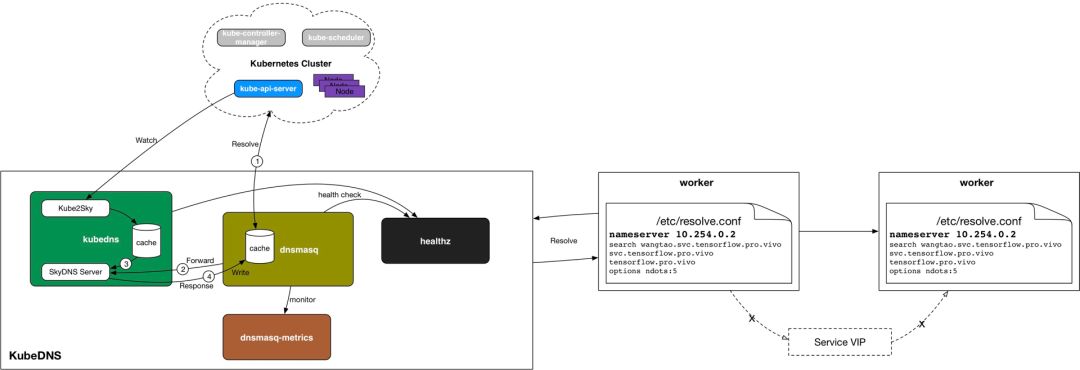
在TensorFlow场景中,这是不可小觑的,因为一个TensorFlow Task都会创建一个service,几万个service是很正常的事,如果使用Normal Service,iptables规则就几十万上百万条了,增删一条iptabels规则耗时几个小时甚至几天,集群早已奔溃。关于kube-proxy iptables模式的性能测试数据,请参考华为PaaS团队的相关分享。
KubeDNS Autoscaler
前面提到,每个TensorFlow Task都会创建一个service,都会在KubeDNS中有一条对应的解析规则,但service数量太多的时候,我们发现有些Worker的域名解析失败概率很大,十几次才能成功解析一次。这样会影响TensorFlow集群内各个task的session建立,可能导致TensorFlow集群起不来。
为了解决这个问题,我们引入了Kubernetes的孵化项目kubernetes-incubator/cluster-proportional-autoscaler来对KubeDNS进行动态伸缩。
TensorFlow on Kubernetes实践
基于上面的方案,我们开发一个TaaS平台,已经实现了基本的功能,包括算法管理、训练集群的创建和管理、模型的管理、模型上线(TensorFlow Serving)、一键创建TensorBoard服务、任务资源监控、集群资源监控、定时训练管理、任务日志在线查看和批量打包下载等等,这部分内容可以参考之前在DockOne上分享的文章《vivo基于Kubernetes构建企业级TaaS平台实践》。
这只是刚开始,我正在做下面的特性:
-
支持基于训练优先级的任务抢占式调度:用户在TaaS上创建TensorFlow训练项目时,可以指定项目的优先级为生产(Production)、迭代(Iteration)、调研(PTR),默认为迭代。优先级从高到低依次为Production --> Iteration --> PTR。但集群资源不足时,按照任务优先级进行抢占式调度。
-
提供像Yarn形式的资源分配视图,让用户对自己的所有训练项目的资源占用情况变得清晰。
-
训练和预测的混合部署,提供数据中心资源利用率。
-
……
经验和坑
整个过程中,遇到了很多坑,有TensorFlow的,也有Kubernetes的,不过问题最多的还是我们用的CNI网络插件Contiv Netplugin,每次大问题基本都是这个网络插件造成的。Kubernetes是问题最少的,它的稳定性比我预期还要好。
-
Contiv Netplugin的问题,在DevOps环境中还是稳定的,在大规模高并发的AI场景,问题就层出不穷了,产生大量垃圾IP和Openflow流表,直接把Node都成NotReady了,具体的不多说,因为据我了解,现在用这个插件的公司已经很少了,想了解的私下找我。
-
在我们的方案中,一个TensorFlow训练集群就对应一个Kubernetes Namespace,项目初期我们并没有对及时清理垃圾Namespace,到后来集群里上万Namespace的时候,整个Kubernetes集群的相关API性能非常差了,导致TaaS的用户体验非常差。
-
TensorFlow gRPC性能差,上千个Worker的训练集群,概率性的出现这样的报错:grpc_chttp2_stream request on server; last grpc_chttp2_stream id=231, new grpc_chttp2_stream id=227,只能尝试通过升级TensorFlow来升级gRPC了。目前我们通过增加单个Worker的计算负载来减少Worker数量的方法,减少gRPC压力。除此之外,规模大一点TensorFlow还有各种问题,甚至还有自己的OOM机制,防不胜防。不过,高速成长的东西,我们要给它足够的容忍。
-
还有TensorFlow OOM的问题等等。
Q&A
Q:Worker为什么不直接用Pod,而用的 Job?
A:Kubernetes中是不建议直接使用Pod的,建议通过一个控制器(RS、RC、Deploy、StatefulSets、Job等)来创建和管理Pod。
Q:我看训练的时候并没有指定数据集和训练参数等,是都放到训练脚本内了吗,还有训练集是放到Gluster,挂载到容器内吗,还是换存到本地?
A:目前训练数据和参数都是在脚本里用户自己搞定,正在把这些放到Portal,提供“命令行参数自定义”的能力。目前我们的训练数据是从HDFS集群直接走网络读取,Kubernetes本身也没有HDFS的Volume Plugin。
Q:请问PS的个数是用户指定还是根据Worker的数量来指派?
A:PS和Worker数都是通过用户指定,但实际上都是用户根据自己的训练数据大小来计算的。
Q:分布式训练的时候,Training data是如何分发到各个Worker节点的?Tensorflow API可以做到按节点数自动分发吗?
A:各个Worker都是从HDFS集群读取训练数据加载到内存的。数据的分配都是用户自己在脚本种实现的。

















 438
438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









