




 本文介绍如何配置高性能深度学习环境,包括安装CUDA、cuDNN及Pytorch,利用RTX3090 GPU的强大算力提升训练效率。
本文介绍如何配置高性能深度学习环境,包括安装CUDA、cuDNN及Pytorch,利用RTX3090 GPU的强大算力提升训练效率。
深度学习平台配置 Pytorch+RTX4090D+Pycharm
用4090D跑深度学习和本地部署大模型
装CUDA
CUDA是什么?
CUDA(ComputeUnified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
命令提示符中输入 nvcc -V,测试是否有CUDA

查看本机的CUDA驱动适配版本
桌面右键打开英伟达控制面板,点击帮助->系统信息->组件
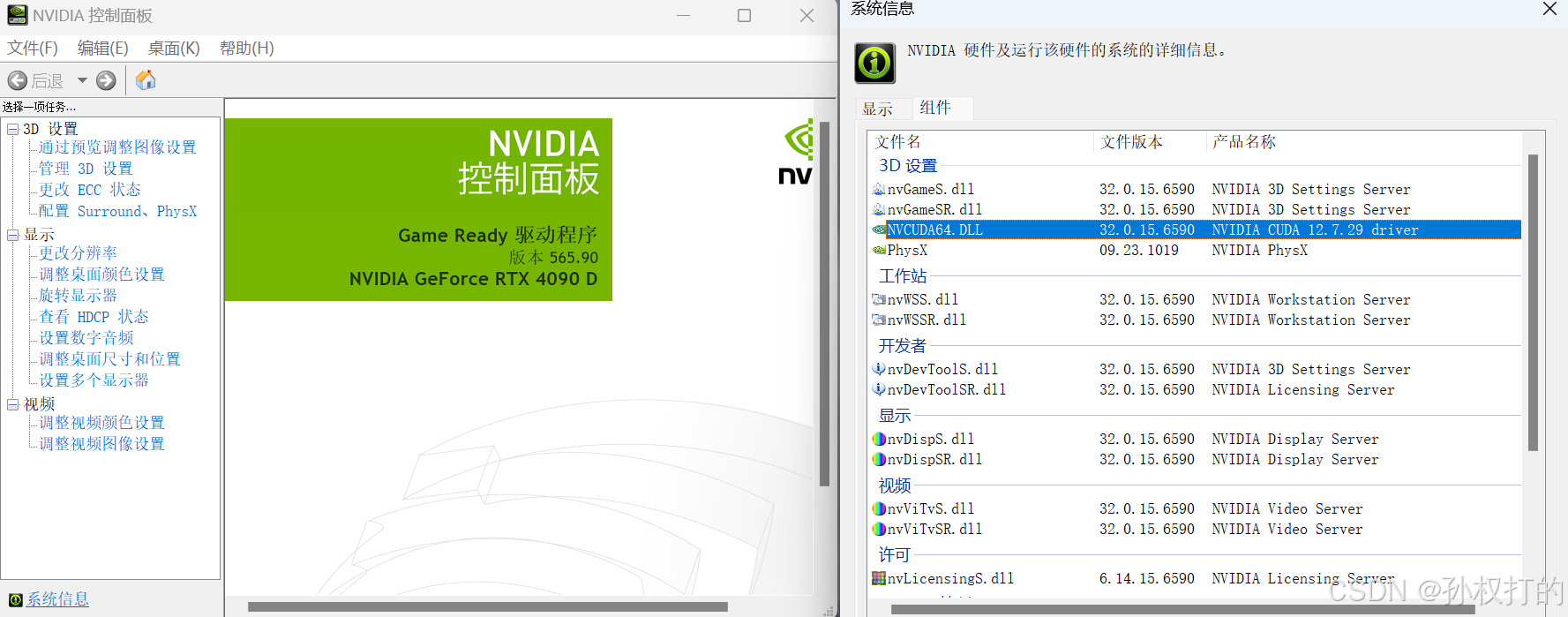
可以看到本机支持的是CUDA 12.7 版本,表示12.7 及以下的版本的cuda都可以。
NVIDIA官网下载
https://developer.nvidia.com/cuda-downloads?target_os=Windows&target_arch=x86_64&target_version=11&target_type=exe_local
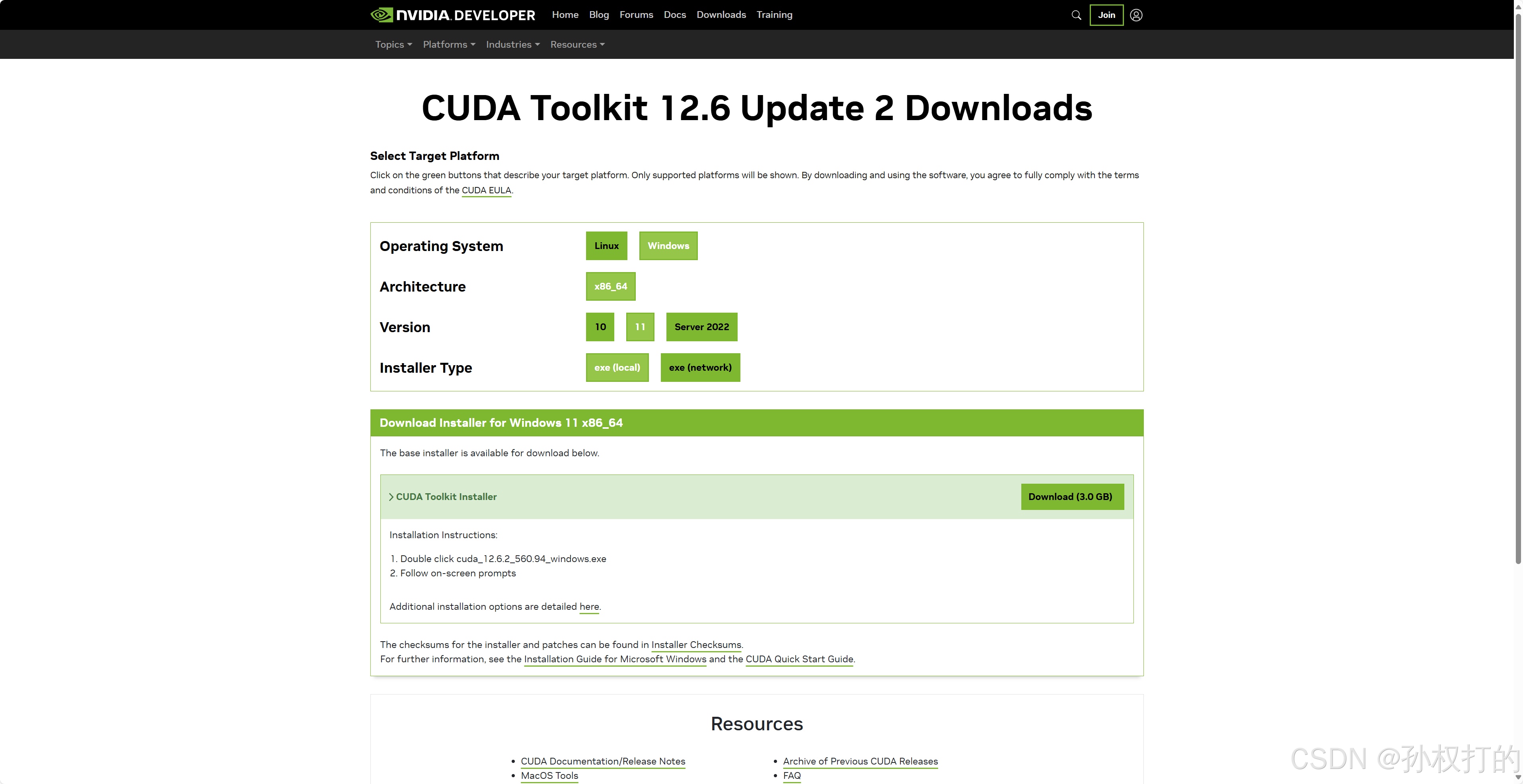
下载完直接一路默认安装,再次输入nvcc -V 检查已经安装成功

安装anaconda
直接下载安装
打开navigator,create新建一个环境,我这里命名为pytorch,
选择uninstalled,即未安装的包。搜索pytorch包,点击安装

点击绿色三角符号,选择open terminal, 在anaconda prompt 中查看已安装情况

测试cuda可用

安装pycharm
选择添加,关联解释器 conda\pytorch\python.exe

在pycharm环境中运行torch程序,我用的是莫烦python-pytorch例程。import torch语句没有报错,大功告成。

测试RTX3090 GPU有没有跑起来
3090小试牛刀,mnist手写集训练,参考莫烦502_GPU代码,GPU利用率才5%,果然强大

cuDNN
什么是CUDNN ?
NVIDIA cuDNN是用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。NVIDIA cuDNN可以集成到更高级别的机器学习框架中,如谷歌的Tensorflow、加州大学伯克利分校的流行caffe软件。简单的插入式设计可以让开发人员专注于设计和实现神经网络模型,而不是简单调整性能,同时还可以在GPU上实现高性能现代并行计算。
CUDA与CUDNN的关系
CUDA看作是一个工作台,上面配有很多工具,如锤子、螺丝刀等。cuDNN是基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算。它就相当于工作的工具,比如它就是个扳手。但是CUDA这个工作台买来的时候,并没有送扳手。想要在CUDA上运行深度神经网络,就要安装cuDNN,就像你想要拧个螺帽就要把扳手买回来。这样才能使GPU进行深度神经网络的工作,工作速度相较CPU快很多。
暂时还用不上cuDNN,等用上了再更新。


















 748
748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









