




本系列文章为郑铁然《语音信号处理》(第三版)、赵力《语音信号处理》(第二版)阅读笔记,仅为整理,不做任何商业传播用途。若有雷同,不是偶然。
- 语音信号处理是语音学与数字信号处理技术相结合的交叉学科
-
语音识别技术的根本目的是研究一种具有听觉功能的机器,能接收人类的语音,理解人类的意图
-
技术发展部分见微信读书郑铁然《语音识别技术》P71
-
语音信号处理的应用:
- 语音识别技术:将输入语音转化为相应的文本或命令
- 说话人识别技术
- 语音合成技术语音编码技术:使语音通信数字化
- 语音训练与与校正技术:计算机辅助语言学习(computer-aided language learning, CALL)
- 语种识别:分析处理一个语音片段以判别其所属的语言种类
- 基于语音的情感处理研究
-
语音信号处理的总体框架图:
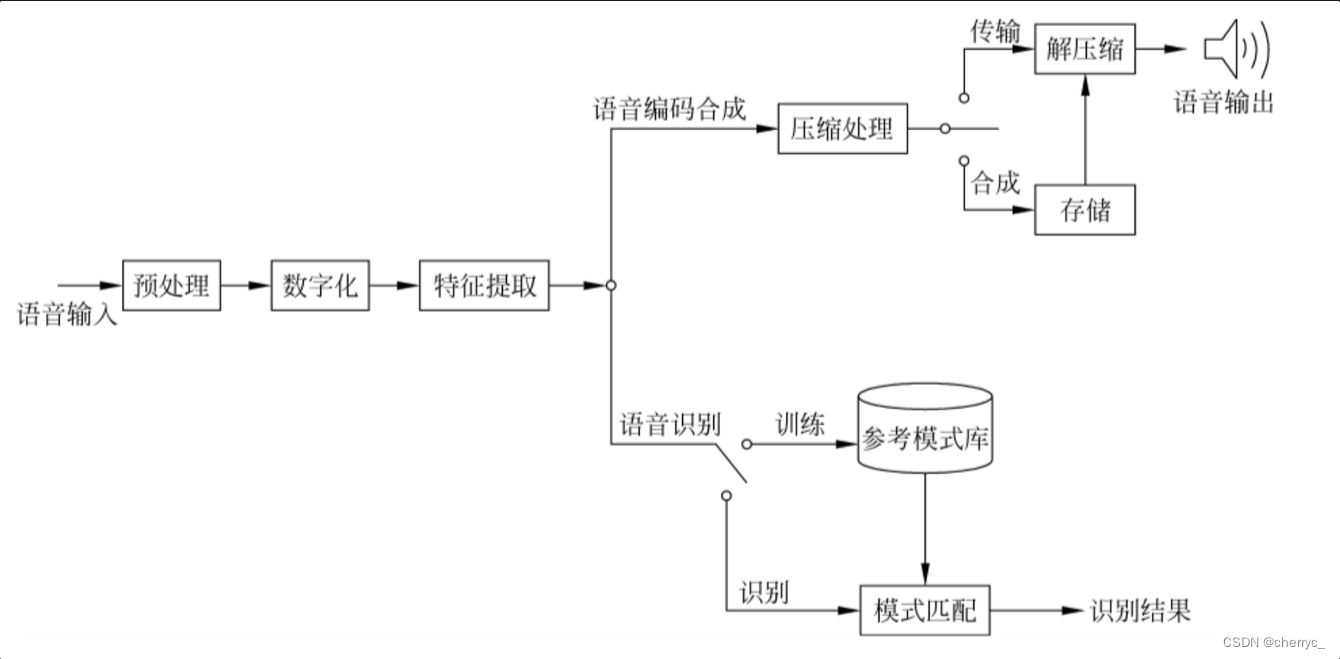
从这个总体结构可以看出:无论是语音识别,还是语音编码与合成,输入的语音信号首先要进行预处理,对信号进行适当放大和增益控制,并进行反混叠滤波来消除工频信号的干扰;然后进行数字化,将模拟信号转化为数字信号,便于用计算机来处理;接着进行特征提取,用反映语音信号特点的若干参数来代表语音。在此之后,根据任务的不同,采取不同的处理办法:
- 语音识别技术,分为两个阶段:Ⅰ训练阶段,将用特征参数形式表示的语音信号进行相应的处理,获得表示识别基本单元共性特点的标准数据,以此构成参考模板,将所有能识别的基本单元的参考模板结合在一起形成参考模式库;Ⅱ识别阶段,将待识别的语音经特征提取后逐一与参考模式库中的各个模板按某种原则进行比较,找出最相像的参考模板所对应的发音,即为识别结果。
- 语音编码与合成技术:都是将语音信号进行某种压缩处理
- 语音编码:对编码后的语音信号进行传输,在接收端进行解压缩回放播出
- 语音合成:对编码后的语音信号进行存储,待需要的时候进行解压缩回放播出。

















 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









