







hadoop的安装分为三种模式:
1. 本地模式
2. 伪分布式模式
3. 完全分布式模式
sudo passwd 重置密码
本地模式:
本地模式安装
一 官网下载hadoop安装包 ,选择二进制的。
下载
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.10.0/hadoop-2.10.0.tar.gz
解压 解压到当前目录
tar -zxvf hadoop-2.10.0.tar.gz
设置环境变量
export HADOOP_HOME=/data01/hadoop/hadoop-2.10.0
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
生效
source /etc/profile
验证安装是否成功
执行 hadoop veriosn
如果没有报错, 说明可以启动hadoop了
以下是hadoop各个目录说明:

本地模式运行案例
案例1:Grep官方案例
本地模式运行官方Grep案例
① 在bin文件夹统计目录 新建input文件夹
② 将etc/hadoop文件夹中的xml格式的文件都复制到input文件夹中
cp etc/hadoop/*.xml input 在etc文件夹统计目录执行
③ 执行share文件夹下的mapreduce程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar grep input output “dfs[a-z.]+”
bin/hadoop: 启动命令
jar: java命令
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar: jar包所在的位置
grep:案例名称
input: 是输入位置
output:是输出的位置
“dfs[a-z.]+”: 正则表达式
④输出结果
查看output文件夹中的的输出文件part-r-00000
内容为:
1 dfsadmin
符合了命令中的正则表达式
注意:
1. 命令中的outout文件夹,运行之前是不能存在的;如果存在会报错;
2. 后面运行的必须全部指定输入路径和输出路径;
案例2:WordCount官方案例
-
创建输出文件
① 新建wcinput文件夹
mkdir wcinput
cd wcinput
vi wc.input
写入以下内容:a a1 a b1 ab ac ap d ap d -
执行命令
在bin同级目录执行:bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar wordcount wcinput wcoutput wordcount:案例名称 wcinput:输入文件夹 wcoutput:输出文件夹 -
查看输出结果
mapreduce任务会将wc.input文件中的内容按空格切分,并且统计出每个单词出现的次数。在wcoutput文件夹中查看的结果为:a 2 a1 1 ab 1 ac 1 ap 2 b1 1 d 2
伪分布式模式
伪分布式模式的配置和完全分布式的配置都是一致的,区别在于伪分布式就一台服务器运行。
在配置伪分布式之后, 本地模式是不能用了,因为指定的fs.defaultFS时候(即下面的参数),本地模式默认的是file:/// ,伪分布式使用的是hdfs://
(1) 配置 etc/hadoop/core-site.xml
<configuration>
<!--指定hdfs的NameNode地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<!-- 指定hadoop运行时产生文件的存储目录 ,目录hadoop会自动创建 -->
<name>hadoop.tmp.dir</name>
<value>/data01/hadoop/hadoop-2.10.0/data</value>
</property>
</configuration>
如果不设置hadoop.tmp.dir, 默认会存在系统的/tmp文件夹路径下,但是我设置之后并没有生效。
(2) 配置hdfs-site.xml
<configuration>
<!-- 配置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
(3) 格式化namenode
bin/hadoop namenode -format
在格式化namenode之前, 首先关掉所有的hadoop所有的namenode, datanode等组件, 然后删除namnode相关的logs. data等文件夹,再执行bin/hadoop namenode -format ,对namenode格式化。
启动命令都在sbin文件夹下
jps 命令 查看java启动的相关进程。如果命令无效则是hadoop的环境变量无效,使用source语句。
启动namenode
sbin/hadoop-daemon.sh start namenode
启动datanode
sbin/hadoop-daemon.sh start datanode
全部启动
sh sbin/start-all.sh
全部停止
sh sbin/stop-all.sh
在hdfs上操作:创建文件夹
bin/hdfs dfs -mkdir -p /data01/hadoop/hdfs_files
执行之后,创建的文件在hadoop下才是可以识别的hdfs文件,直接是看不到的。但是可以在web页面看到。
也可以通过dfs的命令查看hdfs文件系统的目录结构。
bin/hdfs dfs -ls /data01/hadoop/hdfs_files
将本地的文件传到hdfs上
bin/hdfs dfs -put ./wcoutput/part-r-00000 /data01/hadoop/hdfs_file
这是因为namenode没有启动导致的
Unrecognized option: -mkdir
Error: Could not create the Java Virtual Machine.
Error: A fatal exception has occurred. Program will exit.
确保namenode启动之后就没问题了。
为什么不能一直格式化namenode, 格式化namenode注意什么?
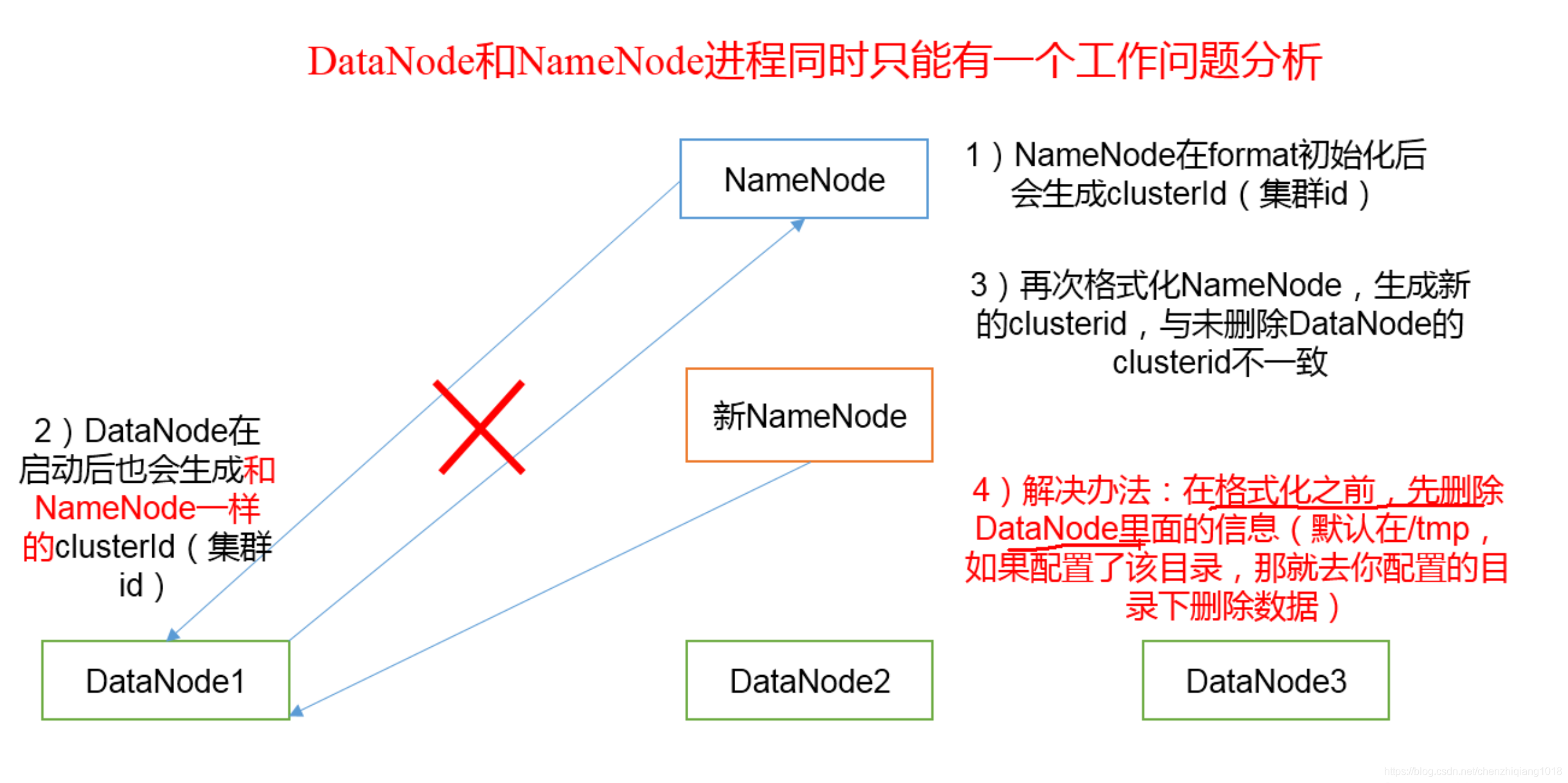
启动yarn并运行mapreduce程序
(1) 配置集群
a1. 配置yarn-env.sh
修改文件中 export JAVA_HOME
a2. 修改host
修改 /etc/hostname中的映射
xxx.xx.xx.xx 主机名
ip 主机名
这里ip要使用ipconfig查询的内网的,不能使用外网的。
a3. 配置yarn-site.xml
<configuration>
<!-- reduces获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定yarn的resourcemanager的地址 这里的resourcemanager 的value填写的是a1.1中写的主机名 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
</configuration>
a4. 修改mapred-env.sh
修改 export JAVA_HOME
a5. 将mapred-site.xml.template 文件名改为mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
并且在其中加上配置
<!-- 指定mr任务运行在yarn上 不指定默认是在local,文档地址 https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(2)启动集群
a 启动之前保证namenode和datanode已经启动
b 分别启动resourcemanager 和nodemanager , 也可以直接start-all.sh全部启动
单独启动yarn
sh sbin/start-yarn.sh
单独停止yarn
sh sbin/stop-yarn.sh
配置文件说明

core-default.xml配置namenode 主机名称, 端口号
副本数
完全分布式模式
(1) scp 安全拷贝
拷贝服务器之间的数据
基本用法
scp -r 源数据路径 目的用户@主机:目标路径
集群配置:

namenode和secondarynamenode占用的内存资源是相同的,所以二者要分开在不同机器;resourcemanager也很耗资源,所以要和namenode以及secondarynamenode错开放置。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









