




前言:在C++的世界里,标准模板库(STL)是每个开发者必须掌握的核心工具之一。而set和map作为关联容器的代表,凭借其高效的查找、插入和删除能力,成为许多高性能场景下的首选数据结构。然而,仅仅知道它们的基本用法还远远不够——深入理解它们的底层实现、性能特性以及最佳实践,才能真正发挥它们的威力

目录

1. 关联式容器简介
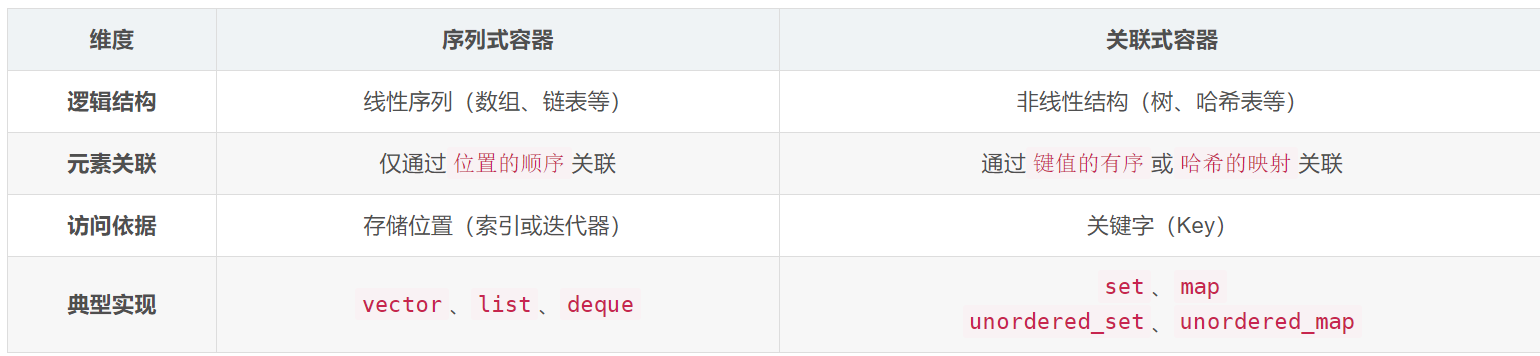
在初阶阶段,我们已经接触过STL中的部分容器,比如:vector、list、deque、
forward_list(C++11)等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身。那什么是关联式容器?它与序列式容器有什么区别?
关联式容器也是用来存储数据的,与序列式容器不同的是,其里面存储的是<key, value>结构的
键值对,在数据检索时比序列式容器效率更高。
比如我们前两篇所学的AVL,RBTree包括后两篇学的哈希表都是关联式容器。
2. 键值对
我们上篇已经展示过了,红黑树的kv结构,但是我们并没详细讲解kv结构的作用以及价值。
KV结构是用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息。
3.Map
3.1介绍
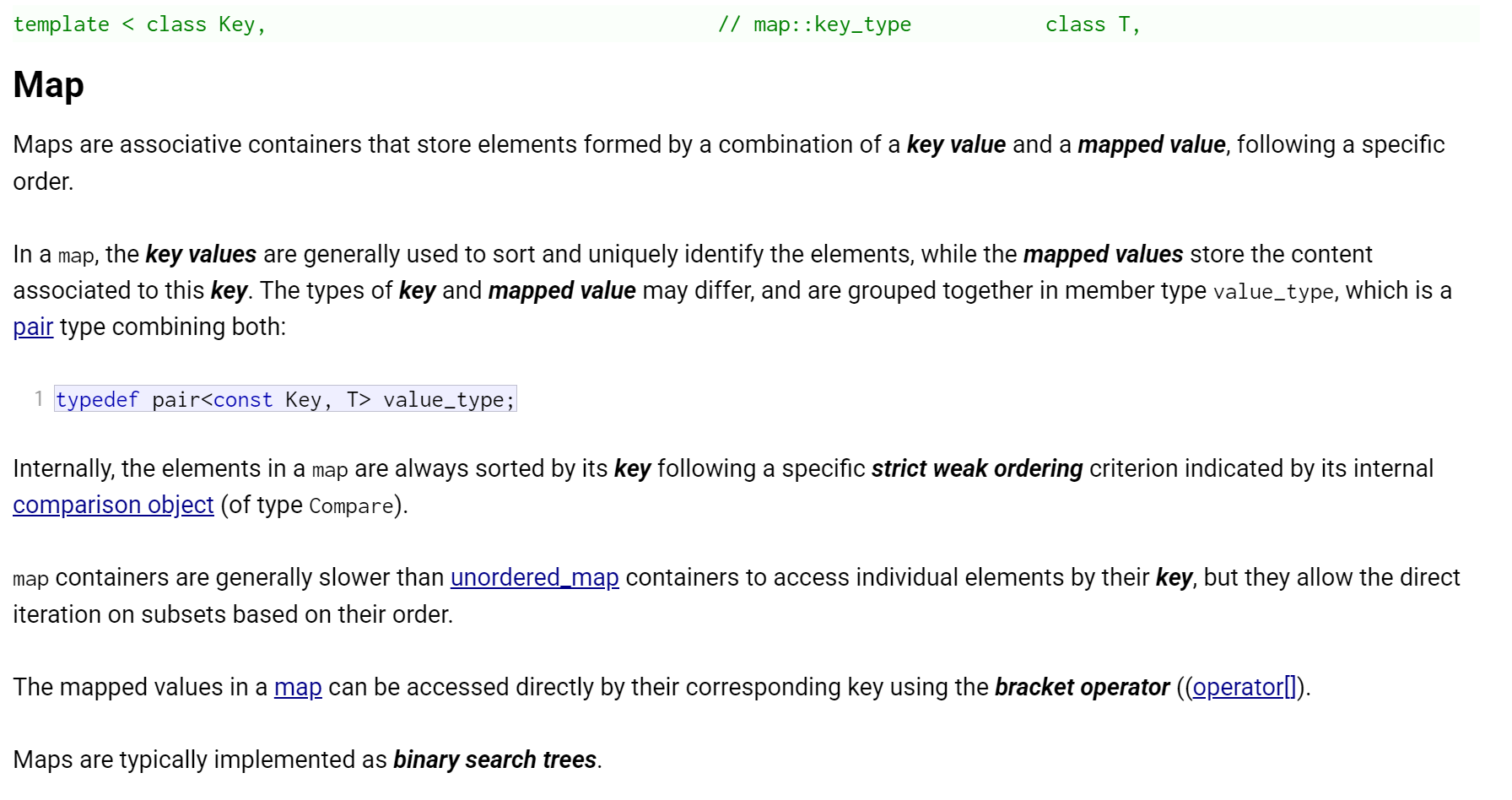
1. map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元素。
2. 在map中,键值key通常用于排序和惟一地标识元素,而值value中存储与此键值key关联的
内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型
value_type绑定在一起,为其取别名称为pair:typedef pair<const key, T> value_type;
3. 在内部,map中的元素总是按照键值key进行比较排序的。
4. map中通过键值访问单个元素的速度通常比unordered_map容器慢,但map允许根据顺序对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)。
5. map支持下标访问符,即在[]中放入key,就可以找到与key对应的value。
6. map通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树))。

template < class Key, // map::key_type
class T, // map::mapped_type
class Compare = less<Key>, // map::key_compare
class Alloc = allocator<pair<const Key, T> > // map::allocator_type
> class map;
解释:
key: 键值对中key的类型
T: 键值对中value的类型
Compare: 比较器的类型,map中的元素是按照key来比较的,缺省情况下按照小于来比
较,一般情况下(内置类型元素)该参数不需要传递,如果无法比较时(自定义类型),需要用户
自己显式传递比较规则(一般情况下按照函数指针或者仿函数来传递)
Alloc:通过空间配置器来申请底层空间,不需要用户传递,除非用户不想使用标准库提供的
空间配置器。通常用来优化内存管理map<Key, T, less<Key>, MyAllocator<pair<const Key, T>>> myMap; // 使用自定义分配器
注意:在使用map时,需要包含头文件。
3.2主要特点总结
一、有序存储
元素始终按键排序,遍历时按顺序输出
例如:插入键为 3、1、2 的元素,遍历输出顺序为 1、2、3
二、键的唯一性
每个键在 map 中是唯一的,如果尝试插入相同的键,会覆盖之前的值
insert 插入相同的键会失败但是operator[ ]会进行覆盖
三、动态大小
自动调整存储空间,无需手动管理
四、迭代器支持
支持双向(正向 反向)迭代器
3.3接口应用
(1)默认构造
只需要两个数据类型(内置类型、容器类型、自定义类型均可)和变量名即可实例化
map<string, string> V1;
map<int, string> V2;
map<int, int> V3;(2)插入
map 的插入不同于以往学习的所有容器的操作:每次插入都涉及到 pair 的使用
原因:这种关联映射型的容器存储,需要 pair(类模板)或者 make_pair(函数模板)提供一种安全、高效的封装方式,可以将 key 和 value合二为一成一个对象!
pair:是存储键值对的类型,需要显式指定类型
make_pair:是创建pair对象的辅助函数,自动推断类型,简化代码
第一个成员(通常命名为 first)键(key),类型为 const Key(键在map中不可改)
第二个成员(通常命名为 second)值(value),类型为 T(值可以修改)
间接创建类模板插入
map<string, string> V1;
//单独创建pair插入
pair<string, string> K1("小明", "大学生");
V1.insert(K1);直接使用类模板插入
//直接使用pair插入
V1.insert(pair<string, string>("小王", "老师"));使用函数模板插入
//使用函数模板插入
V1.insert(make_pair("小白", "对象"));多参构造隐式转换
/多参构造隐式转换
V1.insert({ "小二","服务员" });(3)迭代器访问数据
我们如何打印键值对的数据内容呢?
这里我们就要分别打印。
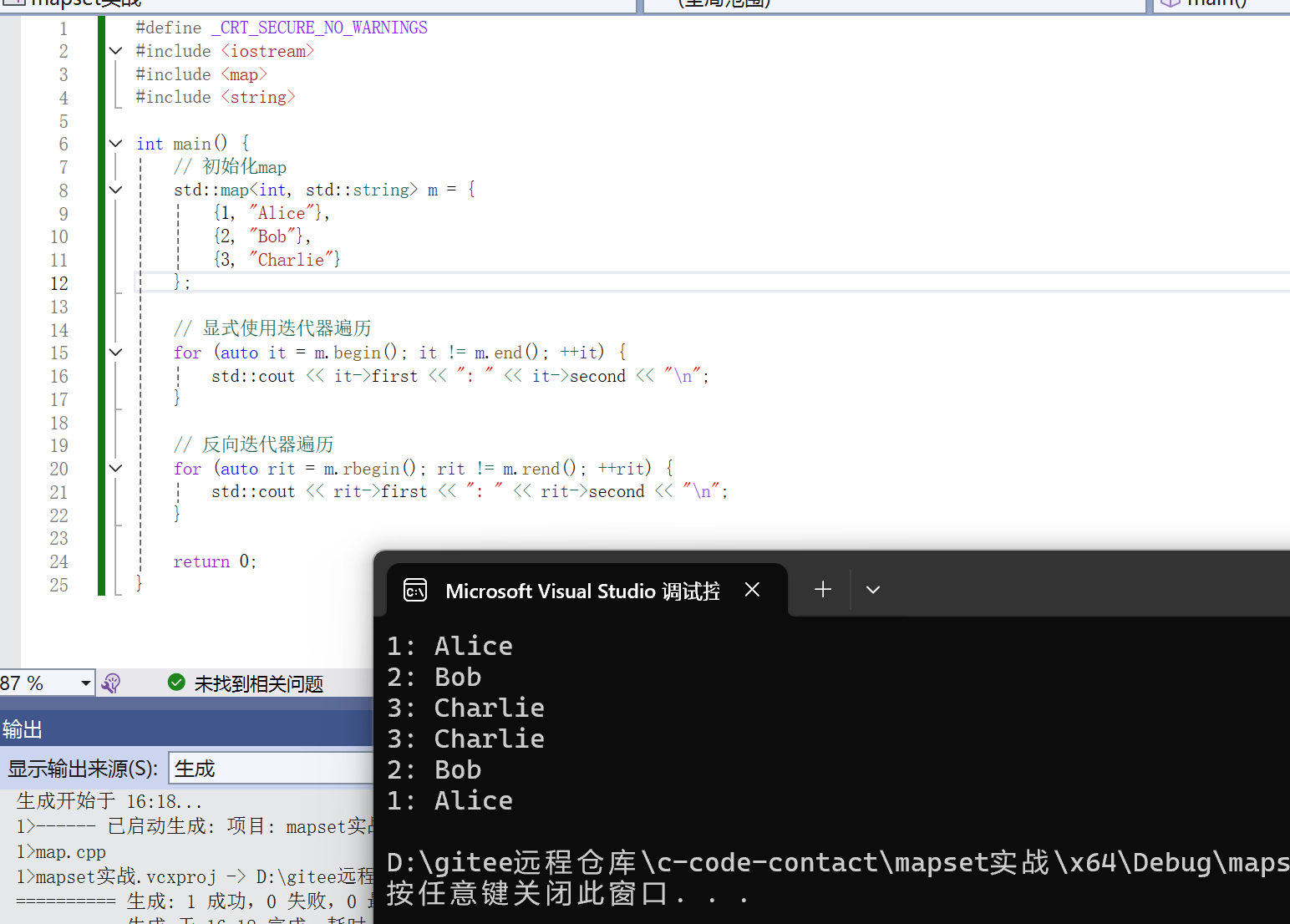
std::map<int, std::string> m = {
{1, "Alice"},
{2, "Bob"},
{3, "Charlie"}
};
// 显式使用迭代器
for (auto it = m.begin(); it != m.end(); ++it) {
std::cout << it->first << ": " << it->second << "\n";
}
}
(4)operator[]
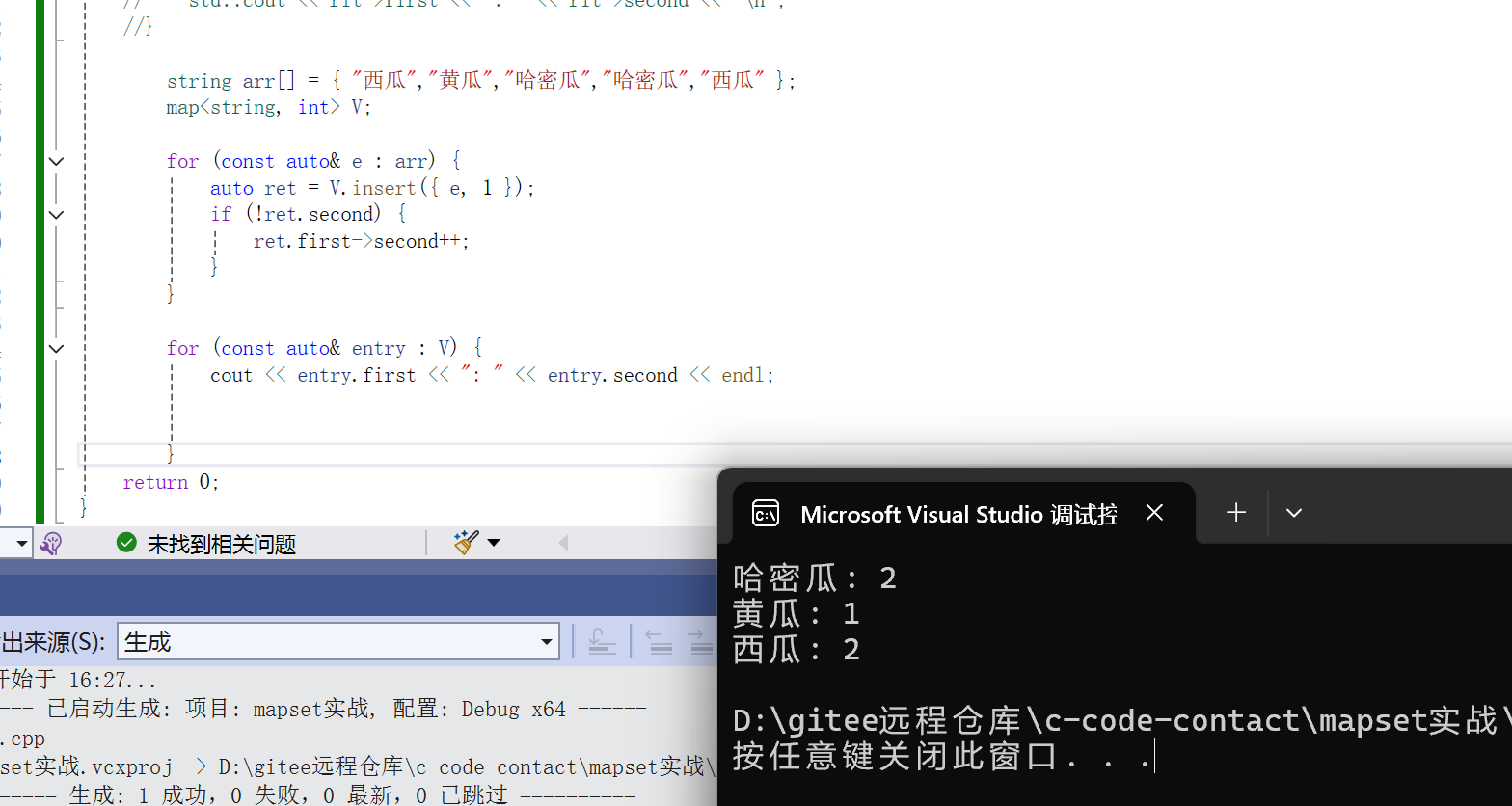
如下假如现在有几个字符串,我们需要统计每种字符串出现的个数:
string arr[] = { "西瓜","黄瓜","哈密瓜","哈密瓜","西瓜" };
for (const auto& e : arr)
{
//先看这个字符串是否已经存在
auto it = V.find(e);
//如果不存在
if (it == V.end())
{
//插入
V.insert(make_pair(e, 1));
}
else
{
it->second++;
}
}
如果我们用operator[]的话就非常简洁:
// 使用operator[]的最简实现
for (const auto& e : arr) {
V[e]++; // 自动处理不存在的情况
}那这里底层又封装了什么呢?
operator[] 的优势就可以自动处理key不存在的情况(初始化value为0后递增)
graph TD A[开始] --> B[遍历数组] B --> C{V[e]存在?} C -->|是| D[递增计数值] C -->|否| E[初始化为0后递增] D --> F[继续循环] E --> F F --> B B -->|遍历结束| G[输出结果] G --> H[结束]如上代码演示,这里还需要注意一点:
当value为自定义类型时,operator[]会进行值初始化(可能产生额外构造开销)
但是在C++11环境下,operator[]和insert的性能差异通常可以忽略
也就是说,有了operator[]我们就可以快速进行下面的操作:
V1.insert(make_pair("小一", "大学生"));
V1.insert(make_pair("小二", "老师"));
//查找+读
cout << V1["小一"] << endl;
//插入
V1["小三"];
//修改
V1["小二"] = "对象";
//插入+修改
V1["小四"] = "兄弟";4.Set
4.1介绍
翻译:
1. set是按照一定次序存储元素的容器
2. 在set中,元素的value也标识它(value就是key,类型为T),并且每个value必须是唯一的。set中的元素不能在容器中修改(元素总是const),但是可以从容器中插入或删除它们。
3. 在内部,set中的元素总是按照其内部比较对象(类型比较)所指示的特定严格弱排序准则进行排序。
4. set容器通过key访问单个元素的速度通常比unordered_set容器慢,但它们允许根据顺序对子集进行直接迭代。
5. set在底层是用二叉搜索树(红黑树)实现的。
4.2主要特点总结
一、自动排序
自动排序简而言之就是当你存入数据到 set 容器时,它会自动把它插入到合适的位置,从而实现自动排序例如插入(1、9、7、6),set 容器里面会存储(1、6、7、9)
二、唯一元素
唯一性体现在数据的独一无二,例如:
插入(1、2、3、3、3、7、7、6),set 容器里面存储(1、2、3、6、7)
三、不支持随机访问
它的结构不是像数组那样的下标访问,元素的位置由树结构决定
注意:
1. 与map/multimap不同,map/multimap中存储的是真正的键值对<key, value>,set中只放
value,但在底层实际存放的是由<value, value>构成的键值对。
2. set中插入元素时,只需要插入value即可,不需要构造键值对。
3. set中的元素不可以重复(因此可以使用set进行去重)。
4. 使用set的迭代器遍历set中的元素,可以得到有序序列
5. set中的元素默认按照小于来比较
6. set中查找某个元素,时间复杂度为:log_2 n
7. set中的元素不允许修改(更改后红黑树结构可能被破坏)
8. set中的底层使用二叉搜索树(红黑树)来实现。
4.3接口应用
(1)构造
set<int> V;(2)插入
V.insert(9);(3)迭代器访问
set<int>::iterator it = V.begin();
while (it != V.end())
{
cout << *it << " ";
it++;
}(4)find 搜索+erase 删除
第一种查找:库里面通用的查找函数,属于暴力查找,时间复杂度为 O(N)
第二种查找:set 容器里面的,根据 set 的结构查找,时间复杂度为 O(logn)
//搜索+删除
auto st = find(V.begin(), V.end(), 5); //第一种
auto st = V.find(8); //第二种
if (st != V.end())
{
V.erase(10);
}(5)lower 与 upper
lower_bound:返回范围内 >= 指定元素的位置,否则返回end
例如:(1,2,3,4,6,7,8)查找4,返回4的位置;查找5,返回6的位置
upper_bound:返回范围内 > 指定元素的位置,否则返回end
例如:(1,2,3,4,6,7,8)查找4,返回6的位置
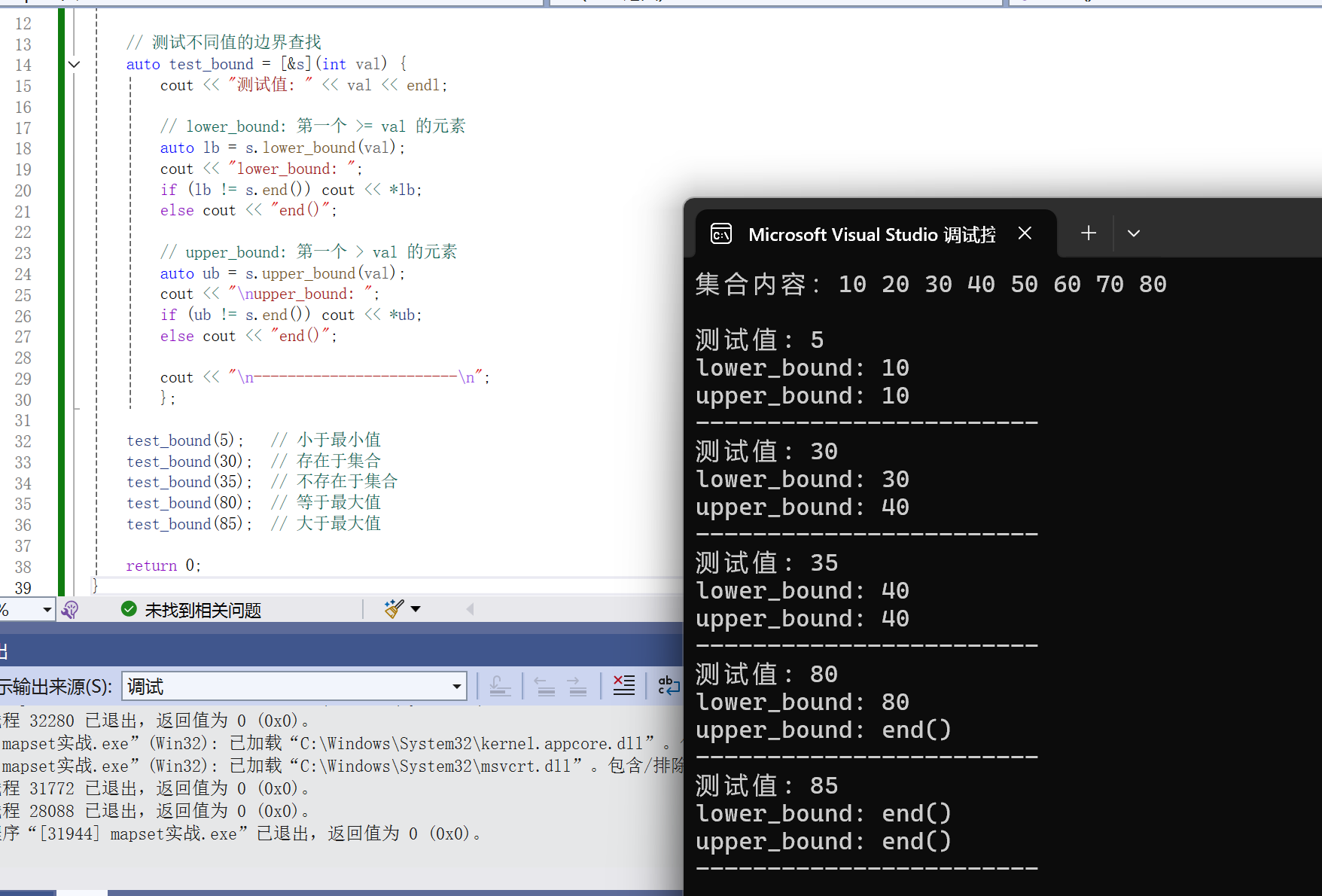
#include <iostream>
#include <set>
using namespace std;
int main() {
set<int> s = {10, 20, 30, 40, 50, 60, 70, 80};
cout << "集合内容:";
for (int num : s) cout << num << " ";
cout << "\n\n";
// 测试不同值的边界查找
auto test_bound = [&s](int val) {
cout << "测试值: " << val << endl;
// lower_bound: 第一个 >= val 的元素
auto lb = s.lower_bound(val);
cout << "lower_bound: ";
if (lb != s.end()) cout << *lb;
else cout << "end()";
// upper_bound: 第一个 > val 的元素
auto ub = s.upper_bound(val);
cout << "\nupper_bound: ";
if (ub != s.end()) cout << *ub;
else cout << "end()";
cout << "\n------------------------\n";
};
test_bound(5); // 小于最小值
test_bound(30); // 存在于集合
test_bound(35); // 不存在于集合
test_bound(80); // 等于最大值
test_bound(85); // 大于最大值
return 0;
}
(6)元素个数
V.size();(7)equal_range
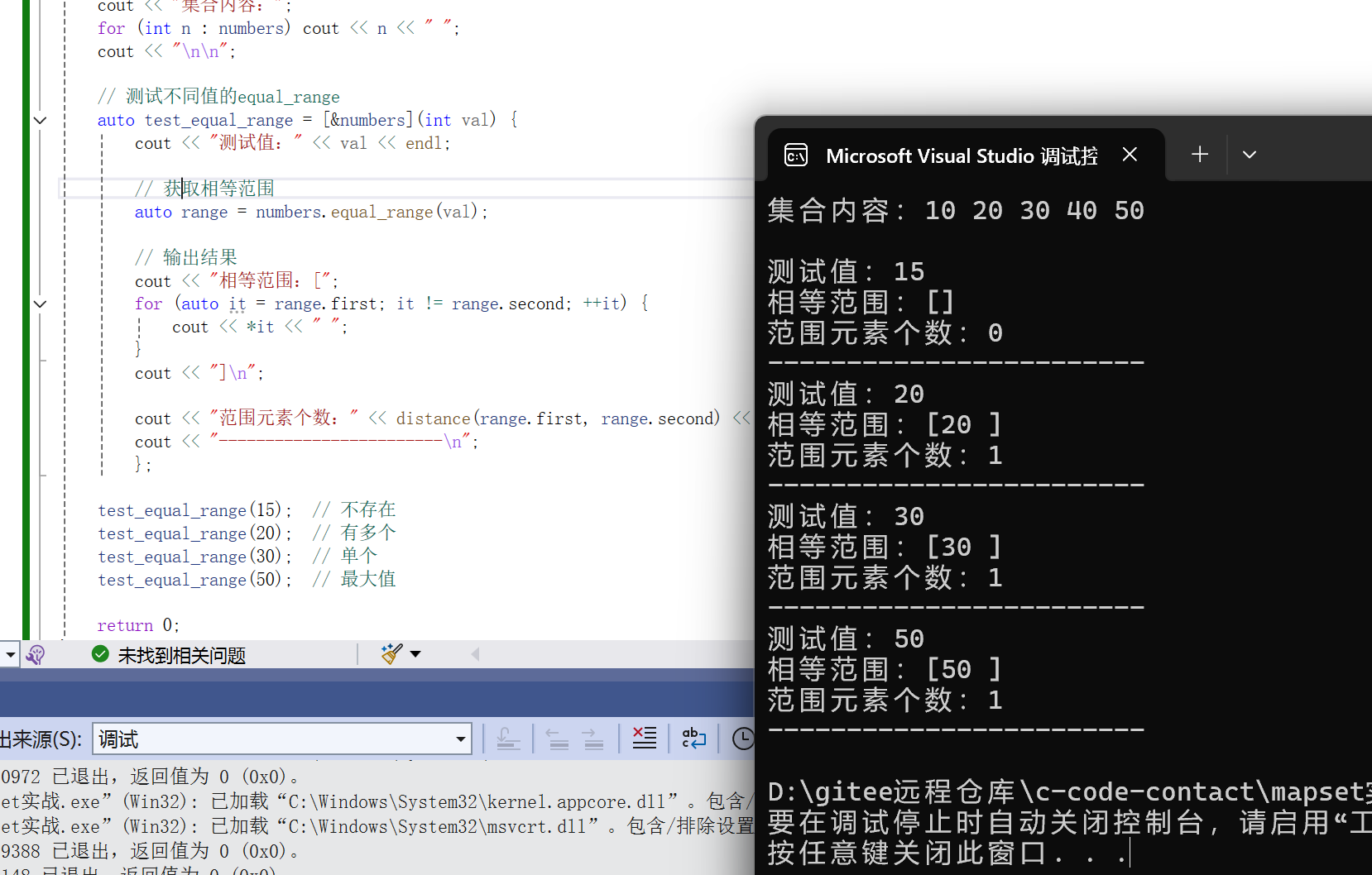
equal_range()返回值:
- 返回
pair<iterator, iterator>first指向第一个 ≥ val 的元素(即lower_bound)second指向第一个 > val 的元素(即upper_bound)
#include <iostream>
#include <set>
using namespace std;
int main() {
set<int> numbers = {10, 20, 20, 20, 30, 40, 50};
cout << "集合内容:";
for (int n : numbers) cout << n << " ";
cout << "\n\n";
// 测试不同值的equal_range
auto test_equal_range = [&numbers](int val) {
cout << "测试值:" << val << endl;
// 获取相等范围
auto range = numbers.equal_range(val);
// 输出结果
cout << "相等范围:[";
for (auto it = range.first; it != range.second; ++it) {
cout << *it << " ";
}
cout << "]\n";
cout << "范围元素个数:" << distance(range.first, range.second) << "\n";
cout << "------------------------\n";
};
test_equal_range(15); // 不存在
test_equal_range(20); // 有多个
test_equal_range(30); // 单个
test_equal_range(50); // 最大值
return 0;
}
multiset和multimap
set 会自动去重,容器中元素唯一,multiset 允许元素重复,侧重按序存储重复数据
multimap和map的唯一不同就是:map中的key是唯一的,而multimap中key是可以
重复的。也就是一对多value,做到一词多义。
接口都是同map和set。完结撒花~


















 59
59





 到【灌水乐园】发言
到【灌水乐园】发言







