




上篇文章,我们详细地逐字逐句的讲解了顺序表的创建及其使用。想必大家对于顺序表使用的一个内部思路都已经非常清楚了,但是我们也讲过,顺序表存在一些不足这里再给大家贴一下。
1. 中间/头部的插入删除,时间复杂度为O(N)
2. 增容需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗。
3. 增容一般是呈2倍的增长,势必会有一定的空间浪费。例如当前容量为100,满了以后增容到200,我们
再继续插入了5个数据,后面没有数据插入了,那么就浪费了95个数据空间。
那么今天我们就正式进入正题:链表
首先我们还是依旧来问一个很常见的问题:什么是链表?
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
我们在讲顺序表的时候就提到了,顺序表的存储结构是和数组一样顺序存放的,讲到的一个概念就是连续存放,那么链表,就更像是一辆火车,是一节一节的车厢组成的

那么我们这里直接可以来看图片
这里我们就可以看到,链表的数据存储就像我们在火车上走过一个个车厢一样,只有走过了一车厢你才能到达二车厢,以此类推。那么我们由此就很容易得出,链表和顺序表一样,都是线性结构的。
但与顺序表(数组)不同,链表的元素在内存中不是连续存储的。每个元素(称为节点)包含两部分:
数据域:存储实际数据
指针域:存储下一个节点的内存地址
这里的数据就可以理解为真正有用的部分,也就是我们在火车上可能走来走去就为了找到自己的那个座位。而指针域你可以理解为去另外一个车厢的地标。这将会让你对概念有一个非常清晰的认知,从而在后面代码实现的时候做到细节上不出错。
那么链表有三大核心特点:
动态内存分配:不需要预先知道数据规模,内存按需分配
非连续存储:节点通过指针连接,物理上不要求连续
高效增删:插入/删除时间复杂度 O(1)(已知位置时)
体现在哪里呢?
我们具体往下看
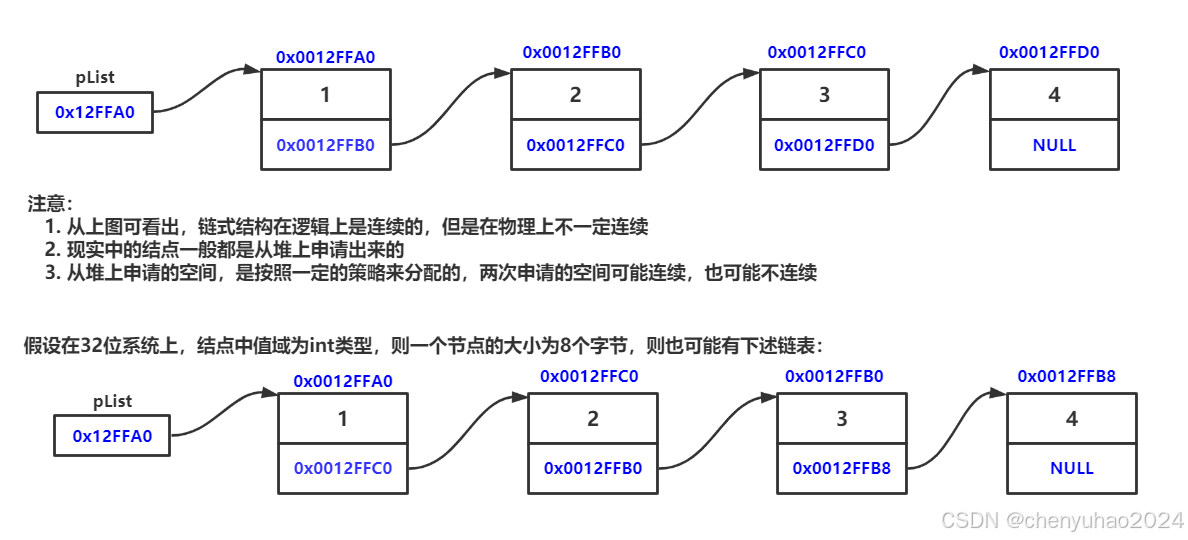
从这里我们就可以得出,链表在内存的管理和分配上相比与顺序表要更加的合理。
当然,这篇文章我们就只对链表讲一个逻辑,并且深入浅出的去了解一下链表,其他的我们放在下一篇文章去讲。
链表的分类
实际中链表的结构非常多样,以下情况组合起来就有8种链表结构:
1. 单向或者双向
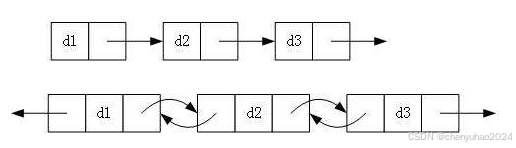
所谓单双向,其本质上就是往哪个方向遍历的问题。
- 在单向链表中,每个节点只有一个指针域,用来指向其直接后继节点。
- 由于只能从头到尾遍历,因此在查找特定元素时可能需要遍历整个列表。
- 所以这里我们就需要用到双向链表。
2. 带头或者不带头
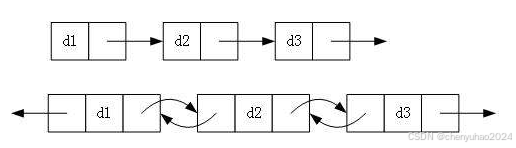
很明显,什么是不带头,也就是没有头节点的链表。那么为什么会有这个链表呢?在处理一些敏感的数据的时候,使用我们的不带头节点能够更加方便,减少我们内存的开销。
推荐带头节点:在大多数工程实践中,尤其是需要频繁操作链表头部(如 LRU 缓存算法)或代码可读性要求高时,带头节点能显著简化逻辑。
使用不带头节点:在内存严格受限的嵌入式系统,或数据结构本身要求直接暴露头指针时(如某些算法题)使用。
3. 循环或者非循环
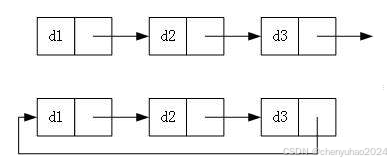
虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:
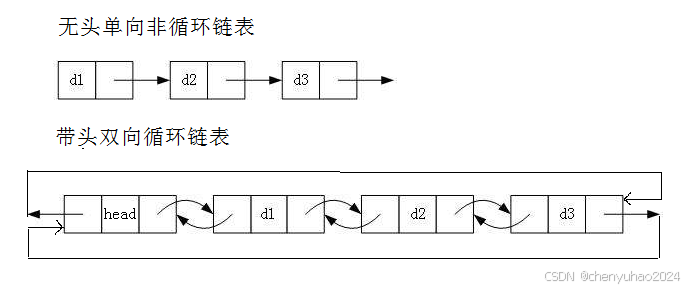
1. 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结 构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
2. 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向 循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而 简单了,后面我们代码实现了就知道了。
好了,关于链表的介绍就到这里,下一篇文章我们就要来讲链表的具体实现。
如果你觉得对你有帮助,可以点赞关注加收藏,感谢您的阅读,我们下一篇文章再见。
一步步来,总会学会的,首先要懂思路,才能有东西写。

















 1万+
1万+




 到【灌水乐园】发言
到【灌水乐园】发言







