




本篇文档是NJU C++课程的第三篇文章,主要讲的是函数这一C++编程中的关键问题。 整理这些内容真的很费力……受不了了😴
函数基础
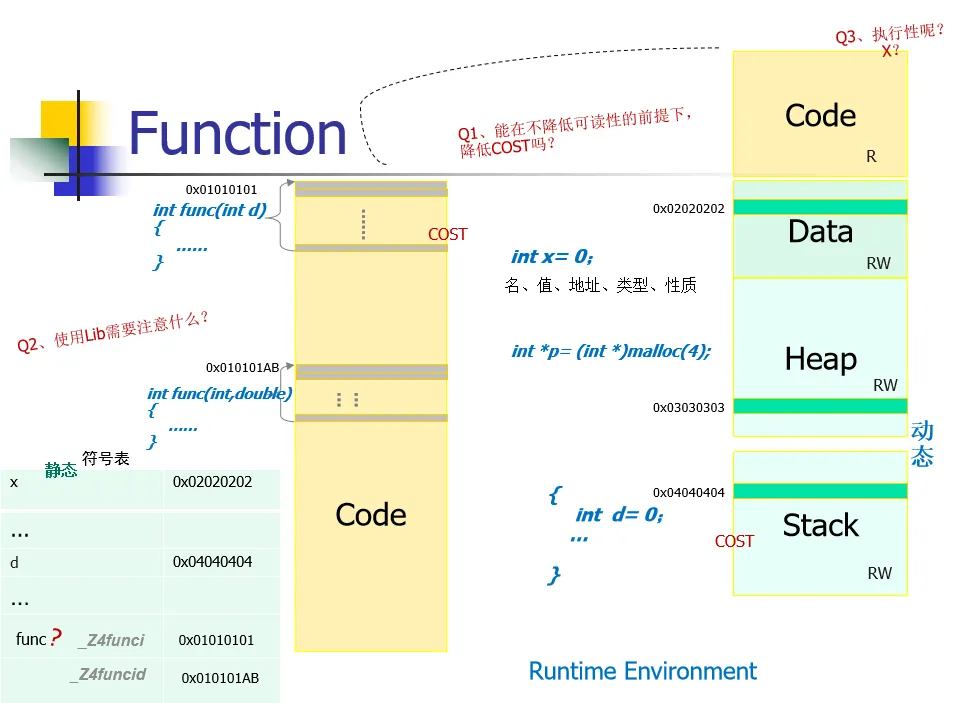 函数的内存分区
函数的内存分区
程序内存一般被分为四个主要的区域,下面的内容也围绕着这个部分而展开
在编译时会产生符号表,这仅存在于编译器的内存中,相当于一个花名册,记录了所有的函数、变量的标识符以及其类型,地址,作用域
- 代码区(Code):存放函数体的二进制指令,是只读的。
- 数据区 (Data): 存放全局变量和静态变量(如
int x = 0;),可读可写。 - 堆区 (Heap): 用于动态内存分配(如 malloc),需要程序员手动管理,可读可写。
- 栈区 (Stack): 用于存放函数的参数、局部变量。每次函数调用都会在栈上自动创建一个新的“栈帧”,函数执行结束后会**自动销毁,**可读可写。
三大核心问题
- Q1 (成本/COST): 函数调用是有开销的(如压栈、跳转等),如何优化?这指向了后续讲解的内联函数等技术。
- Q2 (库/Lib): 使用库函数时需要注意什么?这涉及到链接、符号表等概念。见后面的函数重载以及最后的C++组织方式的内容。
- Q3 (执行性): 代码区为什么是只读的?这关系到程序的安全性,防止代码被意外或恶意篡改。ROP攻击:
- 这种攻击不需要在内存中写入新的可执行代码,而是巧妙地利用程序自身代码区里已有的、零碎的、以 ret 指令结尾的代码片段(gadgets),通过在栈上精心布局这些片段的地址,像放多米诺骨牌一样,将它们串联起来,组合成完整的恶意功能。
底层的传递问题
- 栈帧操作:
- 首先栈指针移动,为了栈对齐或者为了局部变量分配空间。
- 之后参数压栈。
- 之后使用CALL指令跳转到函数代码,RET指令返回调用点,栈指针恢复,释放函数所用的栈空间。
- 参数传递机制
- 按值传递:将实参的值复制一份传递给函数的实参
- 按引用传递:将形参成为实参的一个别名,他们指向同一块内存地址
函数和栈变化(C语言形式cdecl)
按值传递
PPT中使用的例子是一个简单的函数
int r = func(int a, int b) {int r = a + b; return c;}我们尝试理解一下其中的栈空间变化
-
调用准备
- 在main函数的栈帧中,将栈顶指针esp向下移动8个字节,这里是为什么呢?——栈对齐!
- 参数压栈:首先push $0x2,然后push $0x1
- 注意这里面参数是从右向左push入栈
- 发起调用
call _Z4funcii这里做了两件事情:- 首先将返回地址压入栈顶,这个地址是cal指令的下一条指令的地址,告诉函数执行完应该回到哪里
- 之后跳转到_Z4funcii函数的入口地址,开始执行函数代码
-
函数执行
- 建立新的栈帧:
push ebp 和 mov esp, ebp- 保存调用者main函数的栈底指针,以便恢复main栈帧
- 将当前的栈顶设置为新函数的栈底ebp,建立func自己的新栈帧
- 分配空间:sub $0x10, esp
- 为func函数自己的局部变量r分配空间
- 执行函数体:
- 从栈中获取参数,相对于ebp,ebp+8、ebp+12 分别是第一个和第二个参数,分别加载到寄存器中
- 执行加法指令
- 准备返回值:
- 将寄存器的结果存入func为局部变量r分配的栈空间中
- 建立新的栈帧:
-
返回和清理:
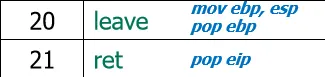
- 销毁func栈帧
- 两个动作,一方面它释放了 func 的局部变量空间,并恢复了调用者 (main) 的栈底指针 ebp(pop ebp)。栈状态“回滚”到了调用 func 之前的样子。
- 返回:
- 执行ret,实质上是pop eip,函数回到了main函数继续执行
- 清理参数栈
- esp上移,彻底清除之前压入栈的1和2
- 获取结果
- 将存入寄存器中的值读取到局部变量中
- 销毁func栈帧
按引用传递
这一部分我也会详细的说明一下,例子是这个:

- 调用准备阶段
- 依旧是为局部变量分配空间,地址作为参数压栈,并发起调用
- 这里的不同点是使用寄存器存储地址参数,将寄存器压入栈中
- 函数执行阶段
- 依旧是建立新的栈帧,执行函数体
- 这里面重点是执行函数体(远程修改)
- 首先依旧是从栈中获取参数,并将1写入寄存器所存地址对应的r中去
- 返回结果
- 依旧是一样的
其余调用约定
在PPT还演示了其他调用约定的相关实例,这里只进行总结
stdcall调用
这里我们用值传递作为例子:int r = func(int a, int b) {int r = a + b; return c;}
- 关键的不同在于我们让被调用者负责退还栈,在ret的时候直接退还栈空间
使用stdcal会导致你无法传递可变的参数了,而对于cdecl调用来说,这些并不是问题,调用者是知道自己调用了多少参数的,所以他不会产生任何问题
fastcall调用
这里我们用值传递作为例子:int r = func(int a, int b) {int r = a + b; return c;}
- 关键的不同在于在这里我们将前几个参数(通常是两个)放入寄存器而不是栈中
使用fastcall会比stdcal更快,剩下的参数压栈,压栈的参数由被调用者负责清理。
thiscall调用
在PPT中没有展示,仅作了解即可
C++ 成员函数的专属约定。
- 规则: 专门用于传递 C++ 类的 this 指针,通常会把它放在 ECX 寄存器中。
C++对函数的增强
普通增强
- 函数原型 (Function Prototype)——这一部分和C差不多
- 核心作用: 它像一个“契约”或“声明”,告诉编译器某个函数存在、它接受什么类型的参数以及返回什么类型的值。
- 带来的好处:
- 先使用后定义: 只要在使用前有函数原型声明,函数的具体实现(定义)可以放在文件的任何位置,甚至在其他文件中。
- 编译器检查: 编译器会根据原型来检查你的函数调用是否正确(参数个数、类型是否匹配),极大地增强了代码的类型安全。
- 函数重载 (Overloading)——这一部分就是C++的特色了
- 核心理念: 允许在同一个作用域内定义多个同名函数,只要它们的参数列表不同(参数的个数、类型或顺序不同)。这是多态 (Polymorphism) 在编译期的一种体现。
- 底层原理: 编译器通过一种叫做名字修饰 (Name Mangling) 的技术,为每个重载版本生成一个唯一的内部名称(如_Z4funci),从而在链接时能够区分它们。extern "C" 的作用就是告诉编译器不要进行名字修饰。
- 重要规则:
- 返回值类型不能作为区分重载的依据。
- 调用重载函数时,编译器会根据传入的实参类型进行匹配。如果匹配不唯一(例如 f(10) 对于 f(long) 和 f(double) 都是合法的隐式转换),就会产生二义性 (ambiguous) 编译错误。
- 默认参数 (Default Parameters)
- 核心功能: 允许在函数原型中为参数指定一个默认值。如果在调用时没有提供该参数,编译器会自动使用这个默认值。
- 重要规则:
- 默认参数必须从右至左依次指定(可以联想到前面参数是从右向左依次压栈的)。
- 默认参数的声明通常放在函数原型中。
- 它也可能与函数重载产生二义性。例如,void f(int); 和 void f(int, int=2); 这两个重载函数,在调用 f(10) 时编译器无法确定该调用哪一个。
回答Q1:追求极致性能的内联函数 (inline)
-
动机:函数调用的成本 (COST)
- 每一次函数调用都有开销:保存现场、参数压栈、跳转、返回、恢复现场等。对于非常简单且调用频繁的函数,这些开销甚至可能超过函数体本身的执行时间。——见前面调用约定讲述的内容
-
解决方案:内联函数 (inline)
-
目的: 既保留函数封装带来的可读性,又通过消除调用开销来提高效率。
-
实现方法: inline 关键字建议编译器不要生成一个真正的函数调用(即没有 call 指令),而是直接将函数体内的代码嵌入 (inline) 到调用点。
inline int add(int a, int b) { return a + b; } int main() { int result = add(3, 5); // 编译器将其展开为 int result = 3 + 5; return 0; }
-
-
使用原则与智慧
- inline 仅仅是请求: inline 只是对编译器的一个建议,而不是强制命令。编译器会根据自己的优化策略来决定是否采纳这个建议。如果函数过于复杂(如包含循环、递归),编译器通常会忽略 inline 请求。
- 适用场景: 最适合代码量小、逻辑简单、调用频率高的函数。
- 明智地运用 (缺点与权衡):
- 代码膨胀 (Code Bloat): 如果滥用 inline 于大函数,会导致最终生成的可执行文件体积急剧增大。
- 性能下降: 过大的代码体积会降低指令缓存 (instruction cache) 的命中率。CPU需要频繁地从慢速内存中加载新的指令,反而会降低程序性能,这破坏了程序的空间局部性。
C++中的函数式编程
这里我们只讲述FP中最常用、最核心的三个高阶函数:filter、transform、accumulate函数 下面我仅仅举例子,你肯定可以理解
filter
筛选你想要的元素
-
前面的实践:copy_if
std::copy_if(InputIt first, InputIt last, OutputIt d_first, UnaryPredicate pred); std::copy_if(src.begin(), src.end(), // 遍历源向量 src std::back_inserter(target), // 使用 back_inserter 在 target 末尾插入元素 [](int n) { return n % 2 == 0; }); // Lambda 作为谓词,筛选偶数 -
前面的实践:remove_if
ForwardIt remove_if(ForwardIt first, ForwardIt last, UnaryPredicate pred); // 1. remove_if 将所有奇数移动到前面,并返回 new_end 指向第一个偶数 auto new_end = std::remove_if(src.begin(), src.end(), isEven); // 2. src.erase 从 new_end 到物理末尾,真正删除所有偶数 src.erase(new_end, src.end()); -
新的实践
-
核心思想: 创建一个“视图 (View)”,它本身不存储数据,而是对源数据的一个懒惰的、可组合的引用。
-
语法 (管道操作符 |):codeC++
auto target = source_range | std::views::filter(predicate);- source_range: 源数据容器,如 src。
- |: 管道操作符,将左侧的数据“流向”右侧的操作。
- std::views::filter(predicate): 创建一个只包含满足 predicate 的元素的视图。
-
例子:
auto target = src | std::views::filter(isEven);
-
transform
语法:
auto new_view = source_range | std::views::transform(unary_op);
-
实例
auto squares = numbers | std::views::transform([](int n) { return n * n; }); // 将 numbers 中的每个数平方。 auto strings = numbers | std::views::transform(...); // 将每个整数转换为字符串。 auto upper_words = words | std::views::transform(...); // 将每个字符串单词转换为大写。 -
编译器优化
- 由于 transform 只是构建了一个视图,整个数据处理链(例如 filter | transform)对编译器是完全可见的。
- 编译器可以将多个操作融合 (fuse) 成一个单一的循环,避免了中间数据结构的创建和多次遍历,从而生成极为高效的代码。
-
惰性求值
-
Ranges 方式 (lazy_view):
auto lazy_view = numbers | std::views::transform(expensive_operation); for (int n : lazy_view) { ... }执行流程: for 循环请求第一个元素 -> lazy_view 从 numbers 取出 1 -> 将 1 送入 expensive_operation (打印 "computing: 1") -> 返回结果 1 -> for 循环打印 "result: 1"。然后请求第二个元素,重复此过程。
结果: "computing" 和 "result" 是交替打印的。计算只在绝对必要时才发生。
-
传统 STL 方式 (std::transform):
std::transform(numbers.begin(), numbers.end(), std::back_inserter(instant), expensive_operation); for (int n : instant) { ... }执行流程: std::transform 立即遍历 numbers 的所有元素,对每个元素调用 expensive_operation,并将结果存入 instant。这个过程会先打印出所有的 "computing: 1", "computing: 2", "computing: 3"。然后,for 循环才开始遍历已经填满的 instant 容器,打印所有的 "rerult: 1", "rerult: 4", "rerult: 9"。
结果: "computing" 和 "rerult" 是分块打印的。这是立即求值 (Eager Evaluation)。
-
accumulate
语法
T accumulate(InputIt first, InputIt last, T init, BinaryOperation op);
-
实例
auto sum = std::accumulate(nums.begin(), nums.end(), 0); // 初始值为0,默认操作为加法。 auto sentence = std::accumulate(words.begin(), words.end(), std::string("")); // 初始值是一个空字符串 "",操作为字符串加法,将所有单词拼接起来。 auto product = std::accumulate(..., 1.0, [](double a, double b) { return a * b; }); // 初始值必须是乘法单位元 1.0,并提供一个自定义的 lambda 作为乘法操作。
C++中的实践
一个具体问题——“统计一个字符串列表中的所有大写字母数量”
-
第一步:转换 (Transform)
auto capitalCounts = strings | std::views::transform([](const std::string& str) { return std::ranges::count_if(str, [](char c) { return std::isupper(c); }); });- strings | std::views::transform(...): 这创建了一个惰性视图 capitalCounts。
- transform 的操作是:对于 strings 中的每个字符串 str,应用 std::ranges::count_if 来计算其中大写字母的数量。
- std::ranges::count_if 是 count_if 的 Ranges 版本,可以直接作用于一个 range (str)。
- 结果: capitalCounts 是一个“承诺”,它承诺当你需要时,它可以为你生成一个包含每个字符串大写字母计数的数字序列。此时没有任何计算发生。
-
**第二步:累加 (Accumulate)**codeC++
return std::accumulate(capitalCounts.begin(), capitalCounts.end(), 0);- 将 capitalCounts 这个视图送入 std::accumulate。
- 执行: std::accumulate 开始向 capitalCounts 请求第一个元素 -> capitalCounts 执行 transform 操作计算出第一个字符串的大写数并返回 -> accumulate 累加... 这个过程一直持续到 capitalCounts 结束。
C++的回调函数的增强
C风格的回调函数(Callback)
- 实现方式:
- 通用数据类型 (void)*: 函数的第一个参数 void *base 可以接收任何类型的数组指针。这是一种非常 C 风格的做法,它放弃了类型安全,需要程序员自己通过 memcpy 和指针算术来处理内存。
- 通用比较逻辑 (函数指针):
- int (*compare)(const void *elem1, const void *elem2)
- 这是 MySort 函数的核心。它是一个函数指针,要求调用者必须传入一个符合这个“签名”(接受两个 const void* 参数,返回 int)的函数。
- 这个被传入的函数就是 回调函数 (CALLBACK)。MySort 的主逻辑(冒泡排序的循环)是固定的,但在需要比较两个元素大小时,它会**“回调”** 用户提供的 compare 函数来完成这个特定任务。
Lambda表达式
-
语法:
[capture list] (parameter list) specifiers -> return type { function body }- [capture list] (捕获列表): 这是 Lambda 的超能力。它允许 Lambda “捕获”其所在作用域的变量,以便在函数体内部使用。
- []: 不捕获任何变量。
- (parameter list): 和普通函数的参数列表一样。
- specifiers: 可选的说明符,如 mutable (允许在Lambda内部修改按值捕获的变量)。
- → return type: 可选的返回类型。如果编译器能推断出来,可以省略。
- { function body }: 函数体。
- [capture list] (捕获列表): 这是 Lambda 的超能力。它允许 Lambda “捕获”其所在作用域的变量,以便在函数体内部使用。
更加抽象——function
将函数作为一个对象封装起来了
-
std::function
- 语法:
std::function<ReturnType(Arg1Type, Arg2Type, ...)> - 例如,std::function<int(int, int)> 表示“一个可以接受两个 int 参数并返回一个 int 的可调用对象”。
- 语法:
-
示例 (opmap):

- 这个例子堪称完美。它创建了一个 map,其值类型是
std::function<int(int, int)>。 - 我们向这个 map 中存入了四种完全不同类型的可调用对象:
- 普通函数指针: add
- 函数对象: ADD()
- Lambda 表达式: [](int a, int b){...}
- std::bind 的结果: NewAdd ( bind 是一个用于适配函数参数的工具,bind(Add3, placeholders::_1, 0, placeholders::_2) 的意思是创建一个新函数,它调用 Add3,第一个参数用新函数的第一个参数,第二个参数固定为0,第三个参数用新函数的第二个参数)。
- 神奇之处: 尽管它们的底层类型各不相同,但 std::function 将它们全部“抹平”,统一了接口。因此,后面可以通过 opmap["..."](x, y) 的方式以完全相同的语法来调用它们。
- 这个例子堪称完美。它创建了一个 map,其值类型是
加餐:C++的组织方式
这一部分肝不动了,看AI吧
好的,这一整部分内容讲述了一个非常核心的 C++ 编程主题:代码组织与作用域管理。它循序渐进地展示了从 C 语言到现代 C++,管理变量和函数可见性的技术演进,最终落脚到 C++ 最重要的组织工具 —— 命名空间 (namespace),并与传统的 C 预处理器 (Cpp) 进行了对比。
可以把这部分内容分为三个层次:
第一层:C 风格的代码组织与作用域 (第一张图)
- 程序组织 (Program Organization):
- 头文件 (Header file,
.h): 用于声明 (declaration)。它们是模块的“接口”,通过extern关键字声明全局变量和函数,告诉其他文件“这些东西存在,你们可以用”。 - 源文件 (Source file,
.cpp): 用于定义 (definition)。它们是模块的“实现”,提供变量的存储空间和函数的具体代码。 #include: 预处理器指令,作用就是把头文件的内容原封不动地“复制粘贴”到源文件中。
- 头文件 (Header file,
- 作用域 (Scope):
- 这张图用不同颜色和标签清晰地展示了 C 的四级作用域:
- 程序级: 通过
extern在整个程序(所有链接的文件)中都可见。 - 文件级 (File Scope): 使用
static关键字修饰的全局变量或函数,其可见性被限制在当前文件内。这是一种避免链接错误 (linking errors) 的重要手段。 - 函数级: 函数内部声明的变量,只在该函数内有效。
- 块级: 在
{}代码块(如for循环)内声明的变量,只在该块内有效。
- 程序级: 通过
- 这张图用不同颜色和标签清晰地展示了 C 的四级作用域:
第二层:现代 C++ 的解决方案 —— namespace
namespace 是 C++ 为了解决 C 语言中“全局命名空间污染”问题而引入的强大工具。在大型项目中,不同模块可能会定义同名变量或函数,static 只能解决文件内部的隔离,但无法解决更复杂的库与库之间的冲突。
-
核心思想: 创建一个具名的“容器”或“区域”,将代码实体(变量、函数、类等)包裹起来,避免它们与外部的名称冲突。
-
两种使用形式 (Forms):
using声明 (using-declaration):using L::k;- 作用: 精确地将命名空间中的某一个成员引入到当前作用域。
- 优点: 精确、安全。只引入你需要的,不会带来意外的名称。这是被优先推荐的方式。
using指示 (using-directive):using namespace L;- 作用: 将命名空间中的所有成员一次性全部引入到当前作用域。
- 缺点: 危险。它可能会引入大量你不需要甚至不知道的名称,极易重新引发命名冲突。应避免在头文件中使用。
-
丰富的特性 (Details):
- 别名 (Alias): 可以为很长的命名空间创建一个简短的别名 (
namespace ATT = ...)。 - 开放性 (Open): 可以分多次、在不同文件中对同一个命名空间进行补充和扩展。
- 可嵌套 (Nestable): 命名空间可以层层嵌套,形成有层次的结构 (
L1::L2::f())。 - 支持重载 (Overloading): 可以在不同命名空间中定义同名函数,通过
using指令可以将它们引入同一作用域并实现重载。
- 别名 (Alias): 可以为很长的命名空间创建一个简短的别名 (
-
替代
static: 幻灯片中提到“在约束作用域方面,替代static”。意思是,对于限制全局变量/函数在文件内可见这个需求,更好的现代C++做法是使用匿名命名空间 (anonymous namespace),而不是static。namespace { // 这里的变量和函数都只在当前文件可见 int file_local_var = 0; }
第三层:回顾与对比 —— C 预处理器 (Cpp) 的功与过 (第五至八张图)
这部分内容回顾了 C 语言的“上古神器”—— C 预处理器 (Cpp),并将其与 C++ 的现代特性进行对比,阐述了为什么我们应该尽量使用现代特性来替代它。
- 预处理器的“原罪” (与现代概念格格不入):
- 预处理器进行的是简单的文本替换,它发生在编译之前,完全不理解 C++ 的作用域、类型、接口等语法概念。
- 穿透作用域: 它的影响是全局性的,
#define定义的宏会无视所有的namespace和class边界。 - 危险的例子:
gcc -Dsqrt=rand这个命令在预处理阶段将代码中所有的sqrt替换为rand,导致程序逻辑被完全篡改,这展示了宏的脆弱性和危险性。
- 宏的“历史功绩”与现代“替代品”:
#include: 组织代码 -> 模块 (Modules, C++20)#define定义常量:const/constexpr#define定义函数宏:inline函数 /template#define定义类型:typedef/using(类型别名)#ifdef/#ifndef: 版本控制、条件编译 -> IDE配置 /if constexpr(C++17)
- 宏的现状: 尽管有诸多缺点和替代品,宏在某些场景(如头文件保护符、条件编译、字符串化、连接符号等)下仍然是不可或缺的工具。但总的原则是:如果一个功能可以用 C++ 语言本身的特性(
const,inline,template,namespace等)来实现,就绝对不要使用宏。
总结: 这一整部分内容的核心是**“进化”**。它展示了 C++ 如何通过引入 namespace 解决了 C 语言在大型项目中的代码组织和命名冲突问题,并强调了应该用类型安全、尊重作用域的现代 C++ 特性去逐步取代功能强大但又“无法无天”的 C 预处理器宏。

















 675
675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









