







《C++ Primer》第10章 泛型算法
10.3节定制操作 习题答案
练习10.11:编写程序,使用stable_sort和isShorter将传递给你的elimDups版本的vector排序。打印vector的内容,验证你的程序的正确性。
【出题思路】
练习向算法传递谓词来定制操作,理解稳定排序的概念。
【解答】
按书中所述实现即可。
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <algorithm>
using namespace std;
inline void output_words(vector<string> &words)
{
for(auto iter = words.begin(); iter != words.end(); ++iter)
{
cout << *iter << " ";
}
cout << endl << endl;
}
bool isShorter(const string &s1, const string &s2)
{
return s1.size() < s2.size();
}
void elimDups(vector<string> &words)
{
output_words(words);//原始数据
sort(words.begin(), words.end());//排序
output_words(words);//排序后输出
//http://www.cplusplus.com/reference/algorithm/unique/
auto end_unique = unique(words.begin(), words.end());//把重复元素移动到最后,并没有真的删除,它只是覆盖相邻的元素
output_words(words);//输入unique的元素
words.erase(end_unique, words.end());//删除相关的元素
output_words(words);//输出数据
stable_sort(words.begin(), words.end(), isShorter);//按单词长度排序
output_words(words);//输出数据
}
int main(int argc, const char *argv[])
{
ifstream in(argv[1]);
if(!in)
{
cout << "打开输入文件失败!" << endl;
exit(1);
}
vector<string> words;
string word;
while(in >> word)
{
words.push_back(word);
}
elimDups(words);
return 0;
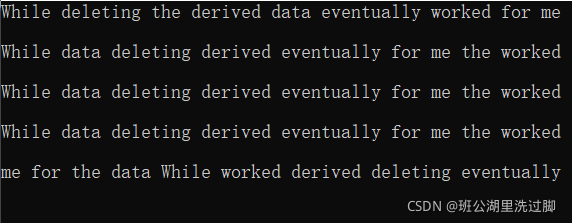
}data10_11.txt文件内容如下:
While deleting the derived data eventually worked for me
设置命令行参数,运行结果如下:
练习10.12:编写名为compareIsbn的函数,比较两个Sales_data对象的isbn()成员。使用这个函数排序一个保存Sales_data对象的vector。
【出题思路】
练习定义和使用谓词。
【解答】
我们将compareIsbn定义为一个二元谓词,接受两个Sales_data对象,通过isbn成员函数获取ISBN编号,若前者小于后者返回真,否则返回假。
inline bool compareIsbn(const Sales_data &lhs, const Sales_data &rhs)
{
return lhs.isbn() < rhs.isbn();
}在主程序中,将compareIsbn作为第三个参数传递给sort,即可实现销售数据按ISBN号排序(注,此程序的主程序12.cpp要与Sales_data.cpp一起编译,即,要将Sales_data.cpp添加到开发环境的项目中)。
//Sales_data.h
#ifndef PROGRAM10_12_H
#define PROGRAM10_12_H
#include <iostream>
#include <string>
class Sales_data
{
friend std::istream& operator >> (std::istream&, Sales_data&);
friend std::ostream& operator << (std::ostream&, const Sales_data&);
friend bool operator < (const Sales_data&, const Sales_data&);
friend bool operator == (const Sales_data&, const Sales_data&);
friend Sales_data add(const Sales_data &lhs, const Sales_data &rhs);
friend std::istream &read(std::istream &is, Sales_data &item);
friend std::ostream &print(std::ostream &os, const Sales_data &item);
public:
Sales_data() = default;
Sales_data(const std::string &book): bookNo(book)
{
//std::cout << "call ======Sales_data(const std::string &book): bookNo(book)=============" << std::endl;
}
Sales_data(std::istream &is)
{
//std::cout << "call ======Sales_data(std::istream &is)=============" << std::endl;
is >> *this;
}
//Sales_data(std::istream &is);
Sales_data(const std::string &book, const unsigned num, const double sellp, const double salep);
//定义公有函数成员
public:
// operations on Sales_item objects
// member binary operator: left-hand operand bound to implicit this pointer
Sales_data& operator += (const Sales_data&);
// operations on Sales_item objects
double avg_price() const;
std::string isbn() const { return bookNo; }
//combine函数用于把两个ISBN相同的销售记录合并在一起
Sales_data& combine(const Sales_data &rhs)
{
units_sold += rhs.units_sold; //累加书籍的销售量
saleprice = (rhs.saleprice * rhs.units_sold + saleprice * units_sold)
/ (rhs.units_sold + units_sold); //重新计算实现销售价格
discount = saleprice / sellingprice; //重新计算实际折扣
revenue += rhs.revenue; //总销售额
return *this; //返回合并后的结果
}
// 定义私有数据成员
private:
std::string bookNo; // 书籍编号,隐式初始化为空串
unsigned units_sold = 0; // 销售量,显式初始化为0
double sellingprice = 0.0; // 原始价格,显式初始化为0.0
double saleprice = 0.0; // 实售价格,显式初始化为0.0
double discount = 0.0; // 折扣,显式初始化为0.0
double revenue = 0.0; // 总收入
};
Sales_data::Sales_data(const std::string &book, const unsigned num, const double sellp, const double salep)
{
bookNo = book;
units_sold = num;
sellingprice = sellp;
saleprice = salep;
if(0 != sellingprice)
{
discount = saleprice / sellingprice; //计算实际折扣
}
}
//add
Sales_data add(const Sales_data &lhs, const Sales_data &rhs)
{
Sales_data sum = lhs;
sum.combine(rhs);
return sum;
}
//read
std::istream& read(std::istream &is, Sales_data &item)
{
is >> item.bookNo >> item.units_sold >> item.sellingprice >> item.saleprice;
return is;
}
//print
std::ostream& print(std::ostream &os, const Sales_data &item)
{
os << item.isbn() << " " << item.units_sold << " " << item.sellingprice << " " << item.saleprice
<< " " << item.discount;
return os;
}
// used in chapter 10
inline bool compareIsbn(const Sales_data &lhs, const Sales_data &rhs)
{
return lhs.isbn() < rhs.isbn();
}
// nonmember binary operator: must declare a parameter for each operand
Sales_data operator + (const Sales_data&, const Sales_data&);
inline bool operator == (const Sales_data &lhs, const Sales_data &rhs)
{
// must be made a friend of Sales_item
return lhs.units_sold == rhs.units_sold &&
lhs.revenue == rhs.revenue &&
lhs.isbn() == rhs.isbn();
}
inline bool operator != (const Sales_data &lhs, const Sales_data &rhs)
{
return !(lhs == rhs); // != defined in terms of operator==
}
// assumes that both objects refer to the same ISBN
Sales_data& Sales_data::operator += (const Sales_data& rhs)
{
units_sold += rhs.units_sold;
revenue += rhs.revenue;
return *this;
}
// assumes that both objects refer to the same ISBN
Sales_data operator + (const Sales_data& lhs, const Sales_data& rhs)
{
Sales_data ret(lhs); // copy (|lhs|) into a local object that we'll return
ret += rhs; // add in the contents of (|rhs|)
return ret; // return (|ret|) by value
}
//接收4个参数分别为:ISBN,销售量,原价,实际售价
std::istream& operator >> (std::istream& in, Sales_data& s)
{
in >> s.bookNo >> s.units_sold >> s.sellingprice >> s.saleprice;
// check that the inputs succeeded
if (in)
s.revenue = s.units_sold * s.saleprice;
else
s = Sales_data(); // input failed: reset object to default state
return in;
}
std::ostream& operator << (std::ostream& out, const Sales_data& s)
{
out << s.isbn() << " " << s.units_sold << " "
<< s.revenue << " " << s.avg_price();
return out;
}
double Sales_data::avg_price() const
{
if (units_sold)
return revenue / units_sold;
else
return 0;
}
#endif // PROGRAM10_12_H
#include <iostream>
#include <fstream>
#include <vector>
#include <algorithm>
#include "Sales_data.h"
using namespace std;
int main(int argc, const char *argv[])
{
ifstream in(argv[1]);
if(!in)
{
cout << "打开输入文件失败!" << endl;
exit(1);
}
vector<Sales_data> sds;
Sales_data sd;
while(read(in, sd))
sds.push_back(sd);
sort(sds.begin(), sds.end(), compareIsbn);
for(const auto &s: sds)
{
print(cout, s);
cout << endl;
}
return 0;
}
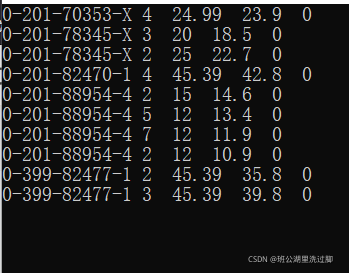
data10_12.txt文件内容如下
0-201-70353-X 4 24.99 23.9
0-201-82470-1 4 45.39 42.8
0-201-88954-4 2 15.00 14.6
0-201-88954-4 5 12.00 13.4
0-201-88954-4 7 12.00 11.9
0-201-88954-4 2 12.00 10.9
0-399-82477-1 2 45.39 35.8
0-399-82477-1 3 45.39 39.8
0-201-78345-X 3 20.00 18.5
0-201-78345-X 2 25.00 22.7
设置命令行参数,运行结果如下:
练习10.13:标准库定义了名为partition的算法,它接受一个谓词,对容器内容进行划分,使得谓词为true的值会排在容器的前半部分,而使谓词为false的值会排在后半部分。算法返回一个迭代器,指向最后一个使谓词为true的元素之后的位置。编写函数,接受一个string,返回一个bool值,指出string是否有5个或更多字符。使用此函数划分words。打印出长度大于等于5的元素。
【出题思路】
练习定义和使用一元谓词。
【解答】
本题要求谓词判断一个string对象的长度是否大于等于5,而不是比较两个string对象,因此它应是一个一元谓词。其他与上一题基本类似。但需要注意,我们应该保存partition返回的迭代器iter,打印范围[words.begin(), iter)中的字符串。
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <algorithm>
using namespace std;
inline void output_words(vector<string>::iterator beg, vector<string>::iterator end)
{
for(auto iter = beg; iter != end; ++iter)
{
cout << *iter << " ";
}
cout << endl;
}
bool five_or_more(const string &s1)
{
return s1.size() >= 5;
}
int main(int argc, const char *argv[])
{
ifstream in(argv[1]);
if(!in)
{
cout << "打开输入文件失败!" << endl;
exit(1);
}
vector<string> words;
string word;
while(in >> word)
words.push_back(word);
output_words(words.begin(), words.end());
auto iter = partition(words.begin(), words.end(), five_or_more);
output_words(words.begin(), iter);
return 0;
}
运行结果:

练习10.14:编写一个lambda,接受两个int,返回它们的和。
【出题思路】
练习定义和使用简单的lambda。
【解答】
由于此lambda无须使用所在函数中定义的局部变量,所以捕获列表为空。参数列表为两个整型。返回类型由函数体唯一的语句——返回语句推断即可。
#include <iostream>
using namespace std;
int main()
{
auto sum = [](int a, int b) { return a + b; };
cout << "sum(12,31) = " << sum(12,31) << endl;
return 0;
}
运行结果:![]()
练习10.15:编写一个lambda,捕获它所在函数的int,并接受一个int参数。lambda应该返回捕获的int和int参数的和。
【出题思路】
练习定义和使用简单的lambda。
【解答】
由于需要计算所在函数的局部int和自己的int参数的和,该lambda需捕获所在函数的局部int。参数列表为一个整型列表。返回类型仍由返回语句推断。
#include <iostream>
using namespace std;
void add(int a)
{
auto sum = [a](int b) { return a + b; };
cout << "sum(1) = " << sum(1) << endl;
}
int main()
{
add(1);
add(2);
return 0;
}运行结果:
![]()
练习10.16:使用lambda编写你自己版本的biggies。
【出题思路】
继续练习lambda。
【解答】
按书中代码片段完成整个程序即可。注意,要用到第6章的make_plural。
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <algorithm>
using namespace std;
inline void output_words(vector<string> &words)
{
for(auto iter = words.begin(); iter != words.end(); ++iter)
cout << *iter << " ";
cout << endl;
}
inline string make_plural(size_t ctr, const string &word, const string &ending)
{
return (ctr > 1) ? word + ending : word;
}
void elimDups(vector<string> &words)
{
sort(words.begin(), words.end());
auto end_unique = unique(words.begin(), words.end());
cout << "words.size==========" << words.size() <<endl;
output_words(words);
cout << "*end_unique==========" << *end_unique <<endl;
words.erase(end_unique, words.end());
}
void biggies(vector<string> &words, vector<string>::size_type sz)
{
elimDups(words);//将words按字典序排序,删除重复单词
//按长度排序,长度相同的单词维持字典序
stable_sort(words.begin(), words.end(), [](const string &a, const string &b) {return a.size() < b.size(); });
//获取一个迭代器,指向第一个满足size() >= sz的元素
auto wc = find_if(words.begin(), words.end(), [sz](const string &a) {return a.size() >= sz; });
//计算满足size >= sz的元素的数目
auto count = words.end() - wc;
cout << count << " " << make_plural(count, "word", "s") << " of length " << sz << " or longer" << endl;
//打印长度大于等于给定值的单词,每个单词后面接一个空格
for_each(wc, words.end(), [](const string &s) { cout << s << " ";});
cout << endl;
}
int main(int argc, const char *argv[])
{
ifstream in(argv[1]);
if(!in)
{
cout << "打开输入文件失几败!" << endl;
exit(1);
}
vector<string> words;
string word;
while(in >> word)
words.push_back(word);
cout << "words.size==" << words.size() << endl;
biggies(words, 4);
return 0;
}
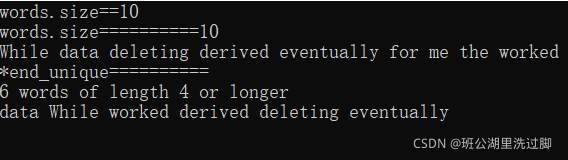
data10_16.txt文件内容为
While deleting the derived data the eventually worked for me
设置命令行参数,运行结果如下:
练习10.17:重写10.3.1节练习10.12(第345页)的程序,在对sort的调用中使用lambda来代替函数compareIsbn。
【出题思路】
继续练习lambda,体会其与谓词的区别。
【解答】
此lambda比较两个给定的Sales_data对象,因此捕获列表为空,有两个Sales_data对象引用的参数。函数体则与compareIsbn相同。
#include <iostream>
#include <fstream>
#include <vector>
#include <algorithm>
#include "Sales_data.h"
using namespace std;
int main(int argc, const char *argv[])
{
ifstream in(argv[1]);
if(!in)
{
cout << "打开输入文件失败!" << endl;
exit(1);
}
vector<Sales_data> sds;
Sales_data sd;
while(read(in, sd))
sds.push_back(sd);
sort(sds.begin(), sds.end(), [](const Sales_data &lhs, const Sales_data &rhs) { return lhs.isbn() < rhs.isbn();});
for(const auto &s: sds)
{
print(cout, s);
cout << endl;
}
return 0;
}
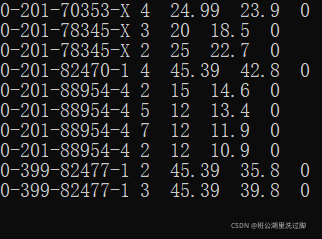
data10_17.txt文件内容为:
0-201-70353-X 4 24.99 23.9
0-201-82470-1 4 45.39 42.8
0-201-88954-4 2 15.00 14.6
0-201-88954-4 5 12.00 13.4
0-201-88954-4 7 12.00 11.9
0-201-88954-4 2 12.00 10.9
0-399-82477-1 2 45.39 35.8
0-399-82477-1 3 45.39 39.8
0-201-78345-X 3 20.00 18.5
0-201-78345-X 2 25.00 22.7
设置命令行参数,运行结果为:
练习10.18:重写biggies,用partition代替find_if。我们在10.3.1节练习10.13(第345页)中介绍了partition算法。
【出题思路】
理解find_if和partition的不同。
【解答】
对于本题而言,若使用find_if,要求序列已按字符串长度递增顺序排好序。find_if返回第一个长度>=sz的字符串的位置wc,则所有满足长度>=sz的字符串位于范围[wc, end)之间。
而partition不要求序列已排序,它对所有字符串检查长度是否>=sz,将满足条件的字符串移动到序列前端,不满足条件的字符串都移动到满足条件的字符串之后,返回满足条件的范围的尾后迭代器。因此满足条件的字符串位于范围[begin, wc)之间。
因此,在partition之前不再需要stable_sort,计数语句和打印语句也都要进行相应修改。
#include <cstddef>
using std::size_t;
#include <string>
using std::string;
#include <iostream>
using std::cout;
using std::endl;
#ifndef MAKE_PLURAL_H
#define MAKE_PLURAL_H
// return the plural version of word if ctr is greater than 1
inline
string make_plural(size_t ctr, const string &word,
const string &ending)
{
return (ctr > 1) ? word + ending : word;
}
#endif // MAKE_PLURAL_H#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <algorithm>
#include "make_plural.h"
using namespace std;
void elimDups(vector<string> &words)
{
sort(words.begin(), words.end());
auto end_unique = unique(words.begin(), words.end());
words.erase(end_unique, words.end());
}
void biggies(vector<string> &words, vector<string>::size_type sz)
{
elimDups(words);//将words按字典序排序,删除重复单词
for_each(words.begin(), words.end(), [](const string &s) { cout << s << " "; });
cout << endl;
//获取一个迭代器,指向最后一个满足size()>=sz的元素之后的位置
auto wc = partition(words.begin(), words.end(), [sz](const string &a) {return a.size() >= sz; });
//计算满足size>=sz的元素的数目
auto count = wc - words.begin();
cout << count << " " << make_plural(count, "word", "s") << " of length " << sz << " or longer " << endl;
//打印长度大于等于给定值的单词,每个单词后面接一个空格
for_each(words.begin(),wc, [](const string &s) { cout << s << " ";});
cout << endl;
}
int main(int argc, const char *argv[])
{
ifstream in(argv[1]);
if(!in)
{
cout << "打开输入文件失败!" << endl;
exit(1);
}
vector<string> words;
string word;
while(in >> word)
words.push_back(word);
biggies(words, 4);
return 0;
}data10_18.txt文件内容如下:
While deleting the derived data the eventually worked for me
设置命令行参数,运行结果如下:

练习10.19:用stable_partition重写前一题的程序,与stable_sort类似,在划分后的序列中维持原有元素的顺序。
【出题思路】
理解stable_partition和partition的不同。
【解答】
将上一题程序中的partition换为stable_partition即可。在输入文件上观察两个程序输出的不同。
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <algorithm>
#include "make_plural.h"
using namespace std;
void elimDups(vector<string> &words)
{
sort(words.begin(), words.end());
auto end_unique = unique(words.begin(), words.end());
words.erase(end_unique, words.end());
}
void biggies(vector<string> &words, vector<string>::size_type sz)
{
elimDups(words);//将words按字典序排序,删除重复单词
for_each(words.begin(), words.end(), [](const string &s) { cout << s << " "; });
cout << endl;
//获取一个迭代器,指向最后一个满足size()>=sz的元素之后的位置, 排好序的
auto wc = stable_partition(words.begin(), words.end(), [sz](const string &a) {return a.size() >= sz; });
//计算满足size>=sz的元素的数目
auto count = wc - words.begin();
cout << count << " " << make_plural(count, "word", "s") << " of length " << sz << " or longer " << endl;
//打印长度大于等于给定值的单词,每个单词后面接一个空格
for_each(words.begin(),wc, [](const string &s) { cout << s << " ";});
cout << endl;
}
int main(int argc, const char *argv[])
{
ifstream in(argv[1]);
if(!in)
{
cout << "打开输入文件失败!" << endl;
exit(1);
}
vector<string> words;
string word;
while(in >> word)
words.push_back(word);
biggies(words, 4);
return 0;
}
data10_19.txt文件内容如下:
the quick red fox jumps over the the slow over red turtle
设置命令行参数,运行结果如下:

练习10.20:标准库定义了一个名为count_if的算法。类似find_if,此函数接受一对迭代器,表示一个输入范围,还接受一个谓词,会对输入范围中每个元素执行。count_if返回一个计数值,表示谓词有多少次为真。使用count_if重写我们程序中统计有多少单词长度超过6的部分。
【出题思路】
练习count_if算法的使用。
【解答】
若只统计容器中满足一定条件的元素的个数,而不打印或者获取这些元素的话。直接使用count_if即可,无须进行unique、sort等操作。
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <algorithm>
#include "make_plural.h"
using namespace std;
inline void output_words(vector<string> &words)
{
for(auto iter = words.begin(); iter != words.end(); ++iter)
{
cout << *iter << " ";
}
cout << endl;
}
void biggies(vector<string> &words, vector<string>::size_type sz)
{
output_words(words);
//统计满足size()>=sz的元素的个数
auto bc = count_if(words.begin(), words.end(), [sz](const string &a){ return a.size() >= sz;});
cout << bc << " " << make_plural(bc, "word", "s") << " of length " << sz << " or longer" << endl;
}
int main(int argc, const char *argv[])
{
ifstream in(argv[1]);
if(!in)
{
cout << "打开输入文件失败!" << endl;
exit(1);
}
vector<string> words;
string word;
while(in >> word)
words.push_back(word);
biggies(words, 6);
return 0;
}data10_20.txt的内容如下:
While deleting the derived data eventually worked for me, it didn't help until I rebooted the iPad and OS/X, emptied the trash after using the Finder to delete the derived data, and removed a BLE peripheral connected via a USB port. I don't know which of the steps was required--XCode later compiled with the BLE peripheral attached--but once all of those steps were added to deleting the derived data, the project compiled fine
设置命令行参数,运行结果如下:

练习10.21:编写一个lambda,捕获一个局部int变量,并递减变量值,直至它变为0。一旦变量变为0,再调用lambda应该不再递减变量。lambda应该返回一个bool值,指出捕获的变量是否为0。
【出题思路】练习lambda改变捕获变量值的方法。
【解答】
若lambda需要改变捕获的局部变量的值,需要在参数列表之后、函数体之前使用mutable关键字。对于本题,由于lambda有两个返回语句(i大于0时返回false,等于0时返回true),还需要显式指定lambda的返回类型——使用尾置返回类型,在参数列表后使用->bool。注意,正确的顺序是mutable -> bool。由于i的初始值为5,程序执行后会打印5个0和1个1。
#include <iostream>
#include <algorithm>
using namespace std;
void mutable_lambda(void)
{
int i = 5;
auto f = [i]() mutable->bool { if(i > 0) { i--; return false;} else return true; };
for(int j = 0; j < 6; j++)
{
cout << f() << " ";
}
cout << endl;
}
int main(int argc, const char *argv[])
{
mutable_lambda();
return 0;
} 运行结果:![]()
练习10.22:重写统计长度小于等于6的单词数量的程序,使用函数代替lambda。
【出题思路】本题练习用函数代替lambda的方法。
【解答】
当lambda不捕获局部变量时,用函数代替它是很容易的。但当lambda捕获局部变量时就不那么简单了。因为在这种情况下,通常是算法要求可调用对象(lambda)接受的参数个数少于函数所需的参数个数,lambda通过捕获的局部变量来弥补这个差距,而普通函数是无法办到的。
解决方法是使用标准库中的bind函数在实际工作函数外做一层“包装”——它接受一个可调用对象A,即实际的工作函数,返回一个新的可调用对象B,供算法使用。A后面是一个参数列表,即传递给它的参数列表。其中有一些名字形如_n的参数,表示程序调用B时传递给它的第n个参数。也就是说,算法调用B时传递较少的参数,B再补充其他一些值,形成更长的参数列表,从而解决算法要求的参数个数比实际工作函数所需参数个数少的问题。
注意,_n定义在命名空间std::placeholders中。
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <algorithm>
#include <functional>
#include "make_plural.h"
using namespace std;
using namespace std::placeholders;
inline void output_words(vector<string> &words)
{
for(auto iter = words.begin(); iter != words.end(); ++iter)
cout << *iter << " ";
cout << endl;
}
bool check_size(const string &s, string::size_type sz)
{
return s.size() >= sz;
}
void biggies(vector<string> &words, vector<string>::size_type sz)
{
output_words(words);
//统计满足size() >=sz的元素的个数
auto bc = count_if(words.begin(), words.end(), bind(check_size, _1, sz));
cout << bc << " " << make_plural(bc, "word", "s") << " of length " << sz << " or longer" << endl;
}
int main(int argc, const char *argv[])
{
ifstream in(argv[1]);
if(!in)
{
cout << "打开输入文件失败!" << endl;
exit(1);
}
vector<string> words;
string word;
while(in >> word)
words.push_back(word);
biggies(words, 6);
return 0;
}data10_22.txt文件内容如下
While deleting the derived data eventually worked for me, it didn't help until I rebooted the iPad and OS/X, emptied the trash after using the Finder to delete the derived data, and removed a BLE peripheral connected via a USB port. I don't know which of the steps was required--XCode later compiled with the BLE peripheral attached--but once all of those steps were added to deleting the derived data, the project compiled fine
设置命令行参数,运行结果如下:

练习10.23:bind接受几个参数?
【出题思路】理解bind函数的使用。
【解答】
bind是可变参数的。它接受的第一个参数是一个可调用对象,即实际工作函数A,返回供算法使用的新的可调用对象B。若A接受x个参数,则bind的参数个数应该是x+1,即除了A外,其他参数应一一对应A所接受的参数。这些参数中有一部分来自于B(_n),另外一些来自于所处函数的局部变量。
练习10.24:给定一个string,使用bind和check_size在一个int的vector中查找第一个大于string长度的值。
【出题思路】
本题继续练习bind的使用。
【解答】
解题思路与练习10.22类似。有两点需要注意:
1.本题中check_size应该检查string的长度是否小于等于长度值,而不是大于等于。
2.对于bind返回的可调用对象,其唯一参数是vector中的元素,因此_1应该是bind的第三个参数,即check_size的第二个参数(长度值),而给定string应作为bind的第三个即check_size的第二个参数。
#include <iostream>
#include <vector>
#include <string>
#include <algorithm>
#include <functional>
#include "make_plural.h"
using namespace std;
using namespace std::placeholders;
bool check_size(const string &s, int &sz)
{
return s.size() >= sz;
}
void biggies(vector<int> &vc, const string &s)
{
//查找第一个大于等于s长度的数值
auto p = find_if(vc.begin(), vc.end(), bind(check_size, s, _1));
//打印结果
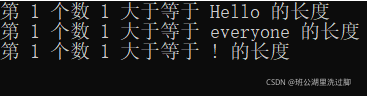
cout << "第 " << p - vc.begin() + 1 << " 个数 " << *p << " 大于等于 " << s << " 的长度 " << endl;
}
int main(int argc, const char *argv[])
{
vector<int> vc = {1, 2, 3, 4, 5, 6, 7, 8, 9};
biggies(vc, "Hello");
biggies(vc, "everyone");
biggies(vc, "!");
return 0;
}
运行结果:
练习10.25:在10.3.2节(第349页)的练习中,编写了一个使用partition的biggies版本。使用check_size和bind重写此函数。
【出题思路】本题继续练习bind的使用。
【解答】
解题思路与练习10.22类似。
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <algorithm>
#include <functional>
#include "make_plural.h"
using namespace std;
using namespace std::placeholders;
void elimDups(vector<string> &words)
{
sort(words.begin(), words.end());
auto end_unique = unique(words.begin(), words.end());
words.erase(end_unique, words.end());
}
inline void output_words(vector<string> &words)
{
for(auto iter = words.begin(); iter != words.end(); ++iter)
cout << *iter << " ";
cout << endl;
}
bool check_size(const string &s, string::size_type sz)
{
return s.size() >= sz;
}
void biggies(vector<string> &words, vector<string>::size_type sz)
{
elimDups(words); //将words按字典序排序,删除重复单词
for_each(words.begin(), words.end(), [](const string &s) {cout << s << " ";});
cout << endl;
//获取一个迭代器,指向最后一个满足size() >= sz的元素之后的位置
auto wc = partition(words.begin(), words.end(), bind(check_size, _1, sz));
//计算满足size >= sz的元素的数目
auto count = wc - words.begin();
cout << endl;
cout << count << " " << make_plural(count, "word", "s") << " of length " << sz << " or longer " << endl;
//打印长度大于等于给定值的单词,每个单词后面接一个空格
for_each(words.begin(), wc, [](const string &s) { cout << s << " ";});
cout << endl;
}
int main(int argc, const char *argv[])
{
ifstream in(argv[1]);
if(!in)
{
cout << "打开输入文件失败!" << endl;
exit(1);
}
vector<string> words;
string word;
while(in >> word)
words.push_back(word);
biggies(words, 6);
return 0;
}
data10_25.txt文件内容为:
While deleting the derived data eventually worked for me, it didn't help until I rebooted the iPad and OS/X, emptied the trash after using the Finder to delete the derived data, and removed a BLE peripheral connected via a USB port. I don't know which of the steps was required--XCode later compiled with the BLE peripheral attached--but once all of those steps were added to deleting the derived data, the project compiled fine
设置命令行参数,运行结果如下:


















 427
427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









