









哈希的概念 : https://blog.youkuaiyun.com/chenxiyuehh/article/details/90043229
开散列
1. 开散列概念
开散列法又叫链地址法(开链法)/哈希桶/拉链法,首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
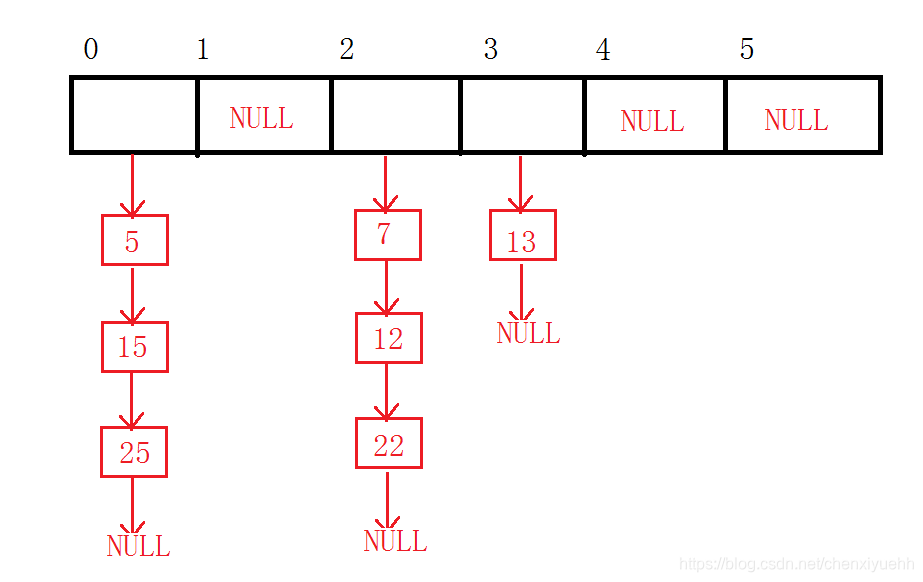
2.开散列的实现
存储的节点定义
- 我们知道开散列的实现其实是一个vector数组,存储的是节点的指针,相当一个指针数组,节点存储的东西应该有两个,一个是节点的值,一个是下一个节点的指针。
- 因为我们要用哈希桶封装unordered_map/set,因此定义节点类型时要注意不能直接给value或是给键值对pair<K,V>,必须给一个模板参数,若是unordered_map调用就存储键值对pair<K,V>,unordered_set调用就存储value。
template<class V>
struct HashNode
{
//由于之后要用哈希桶封装unordered_map/set,因此这里可能存pair<K,V>也可能存value
V _valuefiled;
HashNode<V>* _next;//哈希桶结构是一个vector数组下挂着链表,定义一个指针指向下一个节点的位置
HashNode(const V& v)
:_valuefiled(v)
, _next(nullptr)
{}
};
插入元素
- 插入元素的思想很简单,首先计算元素在表中对应的位置,由于产生哈希冲突的序列不要求有序,找到位置之后可直接进行头插。
对于查找元素和删除元素这里就不赘述了,源码如下:
3.开散列实现完整代码
#pragma once
//开散列解决哈希冲突,哈希桶、拉链法
#include <iostream>
#include <vector>
using namespace std;
template<class V>
struct HashNode
{
//由于之后要用哈希桶封装unordered_map/set,因此这里可能存pair<K,V>也可能存value
V _valuefiled;
HashNode<V>* _next;//哈希桶结构是一个vector数组下挂着链表,定义一个指针指向下一个节点的位置
HashNode(const V& v)
:_valuefiled(v)
, _next(nullptr)
{}
};
//由于之后要用哈希桶封装unordered_map/set,因此这里可能存pair<K,V>也可能存value
//由于pair<K,V>存储比较必须取key才能比较,因此传仿函数取key
template<class K,class V,class KeyOfValue>
class HashTable
{
typedef HashNode<V> Node;
typedef HashTable<K, V, KeyOfValue> HashTable;
public:
HashTable()
:_size(0)
{}
bool insert(const V& v)
{
//考虑增容
CheckCapacity();
KeyOfValue kov;
const K& key = kov(v);
size_t index = key % _table.size();
Node* cur = _table[index];
while (cur)
{
if (kov(cur->_valuefiled) == key)
return false;
cur = cur->_next;
}
//走到这说明没有相同的元素,可以进行插入,
//由于哈希桶不规定产生冲突的序列有序,可以进行头插比较简单
Node* newnode = new Node(v);
newnode->_next = _table[index];
_table[index] = newnode;
++_size;
return true;
}
void CheckCapacity()
{
//当负载因子==1时扩容
if (_table.size() == _size)
{
size_t newsize = _table.size() == 0 ? 10 : _table.size() * 2;
//这里不像之前开散列一样创建一个新的哈希表
//再调用Insert的原因是旧表的节点可以直接拿到新的vector数组中进行插入
vector<Node*> newtable;
newtable.resize(newsize);
//遍历旧表,在新的vector数组中找到对应位置,将旧表节点插入
for (size_t i = 0; i < _table.size(); ++i)
{
Node* cur = _table[index];
//将节点从旧表中拆出来,再重新计算节点在新表中的位置进行插入
while (cur)
{
Node* next = cur->_next;
size_t index = KeyOfValue()(cur->_valuefiled) % newsize;
//头插入新表中
cur->_next = newtable[index];
newtable[index] = cur;
cur = next;
}
//将原来的表置空
_table[i] = nullptr;
}
//交换新旧两标的资源,出作用域后新表自动调用析构函数释放旧表资源
_table.swap(newtable);
}
}
Node* Find(const K& key)
{
size_t index = key % _table.size();
Node* cur = _table[index];
while (cur)
{
if (KeyOfValue()(cur->_valuefiled) == key)
return cur;
cur = cur->_next;
}
return nullptr;
}
bool Erase(const K& key)
{
size_t index = key % _table.size();
Node* cur = _table[index];
Node* prev = nullptr;
while (cur)
{
if (KeyOfValue()(cur->_valuefiled) == key)
{
if (prev == nullptr)//头删
_table[index] = cur->_next;
else
prev->_next = cur->_next;
delete cur;
--_size;
return true;
}
}
return false;
}
private:
vector<Node*> _table;//vector中的size为哈希表的大小
size_t _size;//哈希表中存储的有效元素的个数
};

















 308
308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









