




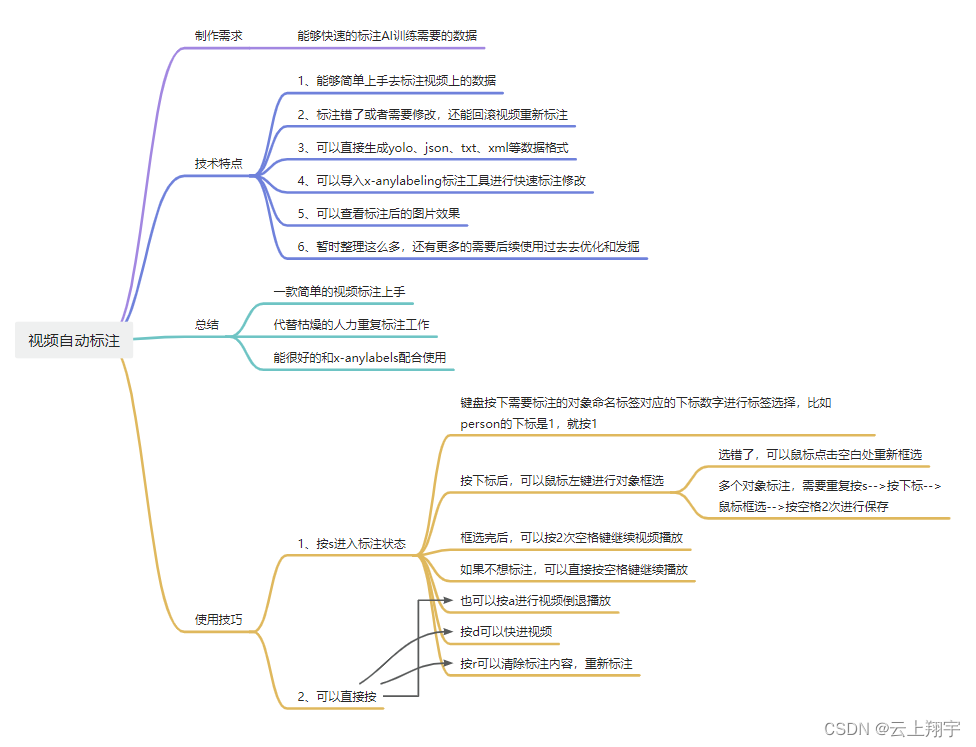
1、软件功能:
AI视频自动标注工具,视频自动追踪标注,并导出视频的图片和标注后的图片以及标注的数据文件,数据文件支持yolov8数据格式生成,生成的数据也支持导入X-AnyLabeling工具进行数据微调。 视频自动标注过程,可以随时暂停,倒退或者快进,还有标注过程需要优化,可以根据需要进行调整。 还支持多标。
2、软件基础介绍:
3、源码分析
配置文件分析:
# 配置信息
# 项目名字 作用:yolov8的训练数据保存在 datatsets/niao
videoname: "niao"
#需要标注的视频 注意用 / 这个反斜杠
video: "F:/下载的视频/1.mp4"
#给出标注类型,注意下标就是 视频里面按了s后 需要输入的数字,最大是9,最小是1,(超过9的,以后再完善,现在够用了),yolov8保存的时候,会默认减去1,变成0到8的数据
Label: {1: "people", 2: "car", 3: "Camera", 4: "bird"}
#导出jpg文件保存地址 注意用 / 这个反斜杠
imgpath: "E:/ai/biaozhu/csxopencv/saveimgcc"
#导出xml 或者yolov8的txt标注信息 文件保存地址 注意用 / 这个反斜杠
labelpath: "E:/ai/biaozhu/csxopencv/saveimgxmlcc"
biaoimgpath: "./savebiaoimgcc"
#视频窗口大小
videowidth: 618
videoheight: 416
# 保存类型,默认是yolov8,也 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 559
559




 到【灌水乐园】发言
到【灌水乐园】发言







